ECS FargateにおけるFluentBitで構造化ログをS3とCloudWatchLogsに送る仕組みと活用法
前提
今の会社に入社した時点で、ECS Fargate + Fluent Bit を使ってログを S3 と CloudWatch Logs に送る仕組みは既に存在していたため、私自身が構築したわけではありません。
既存の Terraform ファイルや資料を参考にして記述しています。
私が担当したのは、Rails アプリへの構造化ログの導入、
Fluent Bit の設定ファイルへのパーサー追加、および CloudWatch Logs でのログ調査です。
もし誤りがあればご容赦ください。
1. ログの保存方法について
ECSにおけるロギングの方法
ECSでは、コンテナが必要に応じてスケールアップ・ダウンすることにより、
コンテナ内にログを溜めていても消えてしまうため、ログの永続化が求められます。
ECSのタスク定義の logDriver に awslogs を指定すると、
コンテナの標準出力 (stdout) および標準エラー (stderr) が、
Amazon CloudWatch Logs に自動的に送信されます。
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/xxx",
"awslogs-region": "ap-northeast-1",
"awslogs-stream-prefix": "ecs"
}
}
ですが以下のようなメリットがあるからか、基本的には awsfirelens が使用されています。
| メリット | awslogs | awsfirelens (Fluent Bit) |
|---|---|---|
| 複数の出力先 | 不可 | 可能 (CloudWatch, S3, Kinesisなど) |
| フィルタリング・整形 | 不可 | 可能 (ログ整形・不要ログの除外) |
| コスト削減 | 難しい | フィルタリングでCloudWatchログ量を削減 |
Firelens(FluentBit)を使い、ログをCloudWatchLogs(CWL)やS3に転送して保存することで、
コンテナが消えてもログはしっかり残ります。
CloudWatchLogsとS3の使い分けについて
基本的には以下のように使い分けています。
-
短期調査用(3 ~ 60日間で削除)
- FluentBit -> CloudWatchLogs
-
長期保管用(削除なし)
- FluentBit -> Firehose -> S3
FluentBit経由でのログ保存
FluentBitを使えば、ログをS3やCloudWatchLogsに簡単に送ることができ、
永続化とリアルタイム可視化を両立できます。
さらに、Firelensを使うことでECS環境でFluentBitの設定がシンプルになります。
FirelensはFluentBitを簡単にコンテナ内で動かせる仕組みで、
ECSタスク定義に少し記述を加えるだけでログルーティングが可能になります。
"logConfiguration": {
"logDriver": "awsfirelens"
}
log_routerのタスク定義では以下のように設定されています。
firelensConfiguration = {
type = "fluentbit"
options = {
config-file-type = "file"
# コンテナイメージ内のConfigファイルパス
config-file-value = "/fluent-bit/etc/extra/web.conf"
enable-ecs-log-metadata = "true"
}
}
log_routerのDockerfileでは以下のようにweb.confを配置するようにして読み込ませます。
FROM public.ecr.aws/aws-observability/aws-for-fluent-bit:2.28.0
RUN adduser fluent && chown fluent -R /fluent-bit
COPY .container/log_router/web.conf /fluent-bit/etc/extra/web.conf
USER fluent
FluentBitのコンテナ構成例
goのアプリの場合
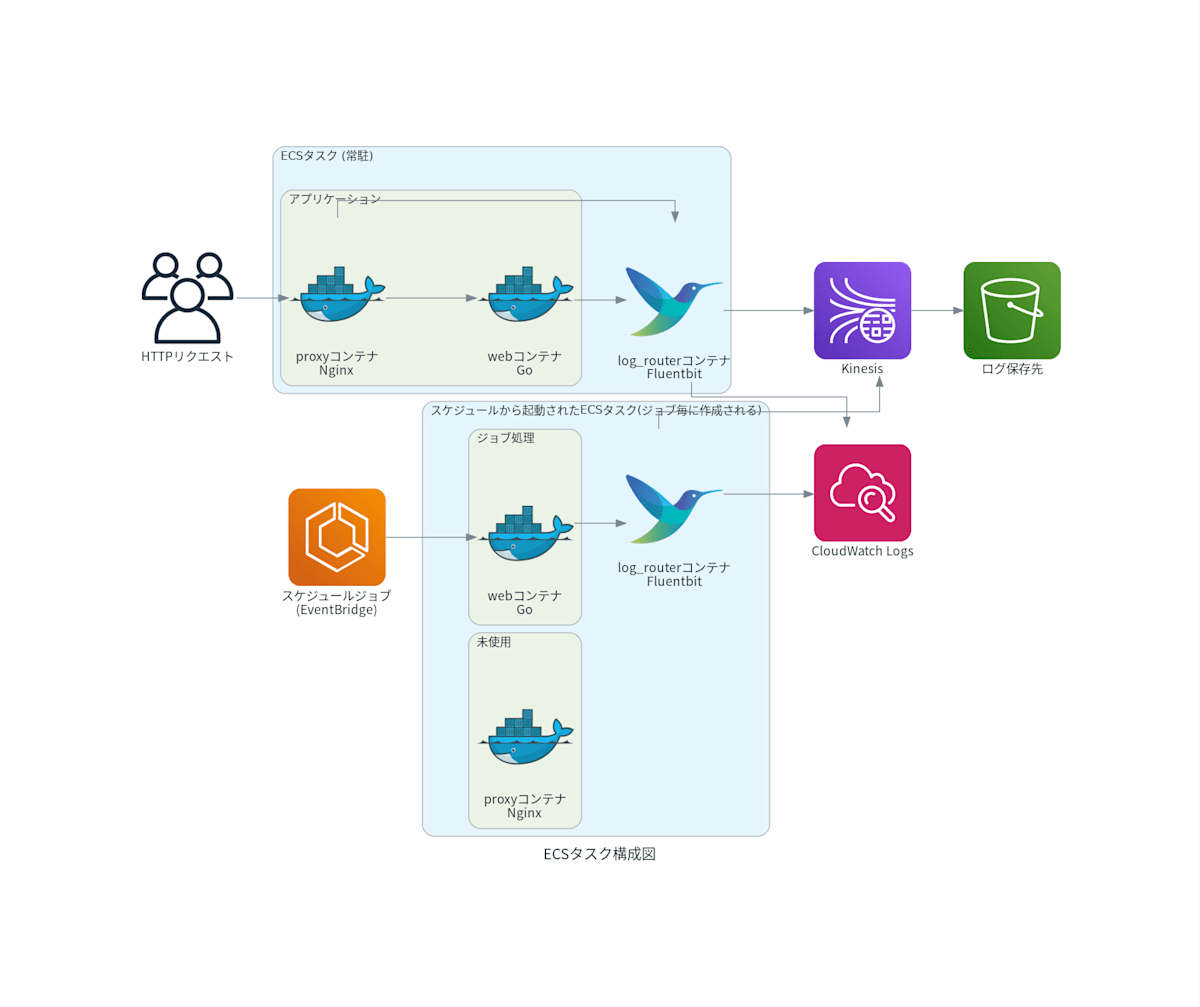
Railsアプリの場合

ここからはRailsアプリの例で各コンテナについて説明します。
各コンテナについて
この構成では、4つのコンテナが協力してログを管理します。
- proxyコンテナ:Nginxが動作し、外部からのHTTPリクエストを受け付けてwebコンテナにリバースプロキシします。ロードバランシングやSSL終端の役割を担うこともあります。
- webコンテナ:Pumaが動作しており、proxyコンテナからのHTTPリクエストにアプリケーションとして応答します。Railsなどのアプリケーションサーバが動いています。
- jobコンテナ:バックグラウンドで非同期ジョブを実行する役割を担い、good_jobを使ってジョブキューを処理します。
- log_routerコンテナ(FireLens利用):Fluent Bitが動作し、各コンテナの標準出力を収集してCloudWatch LogsやS3などに転送します。FireLensはECSでFluent BitやFluentdを使うための仕組みです。
これで、ログがバラバラにならず一元管理できるわけです。
CloudWatchLogsのストリーム構造
CloudWatchLogsでは、コンテナごとにLogStreamが自動作成されます。
ですから、特定のコンテナだけログを確認することが可能です。
2. CloudWatchLogsの保存期間の変更方法について
テスト環境などは「とりあえず3日」と設定してることが多いと思いますが、
個人的にはちょっと短すぎる気がします。
調査を考えると30~90日くらいにしておいた方が安心だと思います。
保存期間の変更方法
保存期間を変えるのはterraformなら簡単です。
resource "aws_cloudwatch_log_group" "xxx" {
name = "/ecs/xxx"
skip_destroy = false
retention_in_days = 60
}
3. 構造化ログのメリット
- 検索性の向上:CloudWatch Logs Insightsで特定の項目を簡単に抽出
- 解析効率の向上:不要なログを除外して必要な情報だけを集計
- シンプルな集計:構造化されたログは統計や集計が簡単
ログ構造化の方法(Rails)
ログを構造化する方法は、各言語、フレームワーク毎に異なります。
例えばRailsでしたらかなり簡単です。
- rails_semantic_logger というgemを入れる
- environments 配下のlog_formatter関係を消して、
config/environments/production.rb か config/application.rbに以下を設定します。
config.semantic_logger.application = "**********"
config.semantic_logger.environment = ENV["STACK_NAME"] || Rails.env
config.log_level = ENV["LOG_LEVEL"] || :info
config.rails_semantic_logger.add_file_appender = false
config.semantic_logger.add_appender(io: $stdout, formatter: :json)
ただし、それだけですとアプリからのログ(標準出力)は、
CloudWatch Logs側の log というキーにjson文字列としてそのまま出てしまいます。
せっかくRails側で構造化ログを出力している意味が無いため、FluentBitのPARSERを設定します。
[FILTER]
Name parser
Match web-firelens*
Key_Name log
Parser json
Preserve_Key true
Reserve_Data true
[FILTER]
Name parser
Match job-firelens*
Key_Name log
Parser json
Preserve_Key true
Reserve_Data true
これによりCloudWatch側には log の中身までも構造体として送られ、
ネストした値に payload.member_key のようにドット繋ぎでアクセスしたり、
行の詳細を開くとツリー構造でキレイに詳細を見ることができるようになります。
4. CloudWatch Logs Insightsの活用
CloudWatch Logs Insightsを活用するにあたって大事だと思うのは
- ログを構造化すること
- request idをログに含むこと
- 便利なクエリは保存すること
です。
ログの構造化について
例えば、こんなログがあったとします。
I, [2024-11-01T18:11:02.610208 #1] INFO -- : [ActiveJob] [XxxJob] [********-****-****-****-************] XxxJob#log_results: Xxx results 12/23: member_key = 12345, result = success, result_json = {"name"=>"projects/*********/messages/************", "token"=>"*********************************", "request.title" = 【お知らせ】ほげほげ"}
ここからmember_keyだけを列に表示したい場合、
CloudWatch Logs Insightsでは以下のようなクエリになります。
fields @timestamp, log, @message, @logStream, @log
| parse @message /member_key\s*=\s*(?<member_key>\d+)/
| display @timestamp, member_key

この程度でしたらまあ簡単な方ですが、
不具合調査のためにクエリを叩きまくっている最中に適宜変えるのは結構面倒です。
また、取り出したい項目が”で囲まれていて更にその中に”とかが含まれていると抽出が難しいです(というか私には無理でした)
でも、例えば以下のようにログが構造化されていたら、
{
"host":"**********.ap-northeast-1.compute.internal",
"application":"****",
"environment":"production",
"timestamp":"2024-11-29T09:29:23.866786Z",
"level":"info",
"level_index":2,
"pid":1,
"thread":"GoodJob::Scheduler(queues=**** max_threads=5)-thread-5",
"tags":["XxxJob","********-****-****-****-************"],
"name":"Rails",
"message":"xxxxx",
"payload":{
"device_token":"*********************************",
"member_key":"12345",
"title":"【キャンペーン】****",
"current_chunk_index":22,
"total_chunk_count":25,
"result":"success",
"response":{
"name":"projects/*********/messages/************"
},
"response_code":200
}
}
CloudWatch Logs Insightsでは以下のようなクエリで取り出せます。
fields @timestamp, payload.member_key
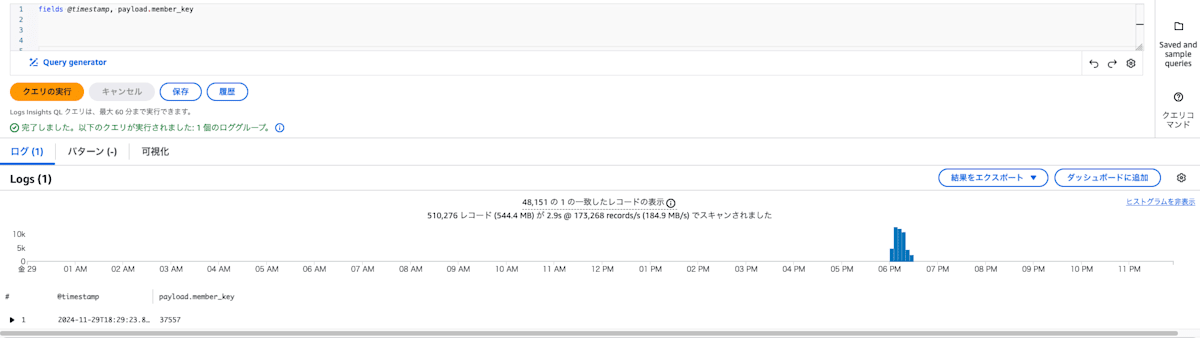
これなら適宜書き換えるのは簡単です。
また、集計する際も構造化されていると簡単です。
Request IDの重要性と実装方法
例えばWebアプリでは、複数のリクエストが同時に処理されるため、
エラーが発生しても該当のエラーログを見つけるだけでは処理の流れを追えず、調査は困難です。
しかし、すべてのログにRequest IDが付与されていれば、エラーからRequest IDを特定し、そのIDを使ってログを検索することで、リクエストの流れを簡単に追跡できます。
{
"host":"**********.ap-northeast-1.compute.internal",
"application":"**********",
"environment":"production",
"timestamp":"2024-11-29T14:59:58.613536Z",
"level":"info",
"level_index":2,
"pid":64,
"thread":"puma srv tp 002",
"duration_ms":6.957342982292175,
"duration":"6.957ms",
"tags":["895947e0-31a3-469c-a2d4-ad59f54bed2o"],
"name":"XxxController",
"message":"Completed #index",
"payload":{
"controller":"XxxController",
"action":"index",
"params":{
"********":"********"
},
"format":"JSON",
"method":"GET",
"path":"/xxx",
"status":200,
"view_runtime":0.29,
"db_runtime":2.14,
"allocations":2143,
"status_message":"OK"
}
}
クエリの保存機能
保存ボタンを押すとクエリの保存をすることができます(グループ分けもできます)
また、右のクエリボタンから保存したクエリを使うことができます。

注意として、上の方にクエリ名が出ている時や、アクションボタンがある時に保存をすると、即上書き保存されるのでご注意ください。
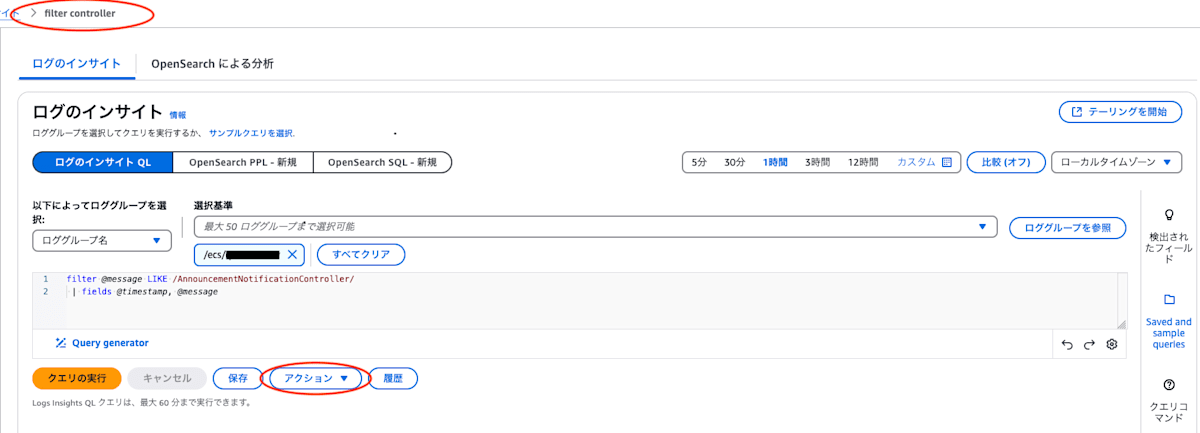
クエリのサンプル集
@logStreamで絞る
@logStream は ecs/proxy-firelens-3fbb92c4e1de4985b6a74a81376259ac
のようにコンテナを絞る要素が含まれているため、以下のようにログを絞り込むことができます。
fields @timestamp, log, @logStream
| filter @logStream not like "proxy"
構造化ログのパラメータによる集計
stats by (SQLで言うgroup byと同等の機能)を使い集計することができます。
fields @log, @timestamp
| stats count() as cnt, sum(ispresent(payload.response.exception)) as cnt_exception by @log, @logStream, message, payload.title as title, payload.current_chunk_index as current, payload.total_chunk_count as total, tags.1 as job_id
| filter @message like "XXX"
| sort title, current
| limit 10000
上記では以下の集計をし as で別名を付けています。
- cnt: 単純な合計
- cnt_exception: payload.response.exception があった合計値
上記の cnt なども filter や sort で使うことができます。
以下のような条件を追加すると重複するログだけを抽出するようなこともできます。
| filter cnt > 1
まとめ
- ECS Fargate に Firelens(Fluent Bit) を導入するのはそう難しくはなさそう(やったことはない)
- 構造化ログじゃないと調査が大変。CloudWatch Logs Insightsのメリットが活かせない
- Railsだったら構造化ログは超簡単
Discussion