拡散モデル関連のトリビア(随時更新したい)
あんまり役に立たないが、以前気になって調べたことのうち、理由がある程度分かったものを書く。
なぜ最近のLDM(潜在拡散モデル)の圧縮率は8倍なのか
昨今のLDMは、ほぼ必ずと言っていいほど1024x1024の画像を128x128の潜在表現に圧縮する。これはなぜか。
答えはLDMを提案した論文にある。
著者を見ると、Robin RombachがまだStability AI入社前で、Runwayの社員が共著にいる。夜明け前感がすごい
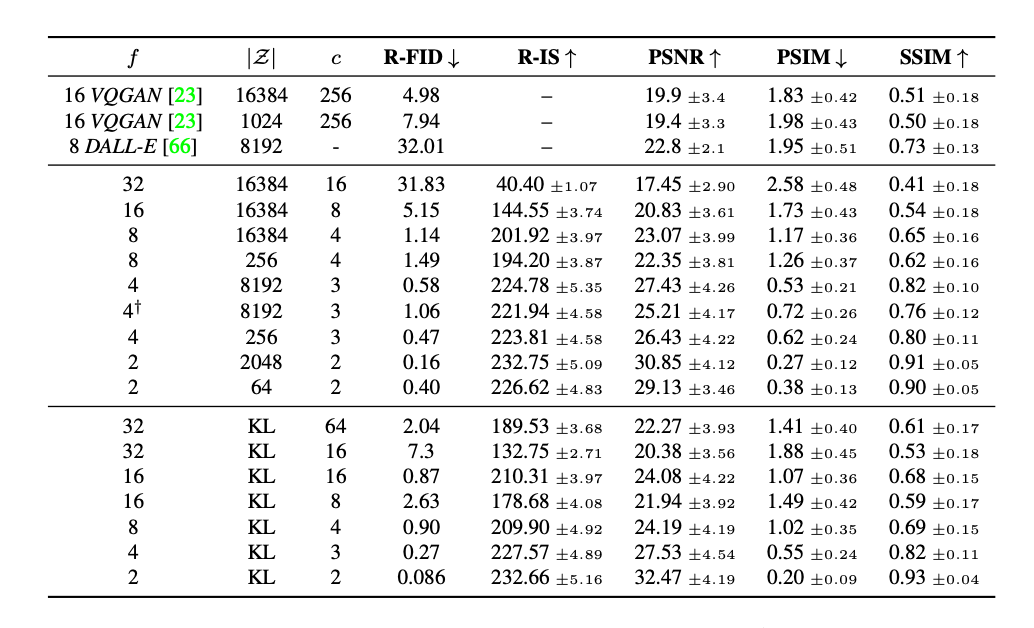
実験では、ImageNetのクラスを条件付けとする画像生成モデルをほぼ同じパラメータ数・ハイパーパラメータ・異なる画像圧縮率(1〜32)で学習してみている。ここで、8倍の圧縮率の場合(LDM-8)が定量評価で最も良い結果を出した。

もっとも、ここで使われたDenoiserのモデリングは古く小さいので、今のモダンで層の深いTransformerをバックボーンとしたDenoiserでも同じようにLDM-8が良い結果を出せるのかは謎。
近頃の画像生成モデルは、LDM-8のスキームを更新するというより、LDM-8のチャンネル数を拡大することで高圧縮率による性能向上の軛を外そうとしている。
なぜStable DiffusionのVAEのチャンネル数は4なのか
上で載せているLDM-8が4chだったから。(それ以外の理由を探しても見つからなかった)
なぜ潜在拡散モデルのAEは基本的にKL-regularizedなのか
LDM論文でVQ-regularizedのものより良い結果が出たから。
というか、SD1もSDXLもSD3もFlux.1もRobin Rombachとその周りの人が考えたアーキテクチャなので、画像生成をする拡散モデルに現れる謎の定数は、Robin Rombachが早期に探索を打ち切ったパラメータというだけで理解しておくのがよい気がしている。
SD1からFlux.1にかけて、分かっていない謎(多分作者の人そこまで考えてない)
- なぜGeLUとSiLUを使い分けているのか
- なぜGeGLUではなくGeLUなのか(コード上ではGeGLUを使うオプションも用意してるのに)
- なぜSD2でv-predictionを試したのに、SDXLで再びε-predictionに戻したのか
なぜT2I-Adapterではなく、ControlNetが流行ったのか
T2I-Adapter
ControlNet
どちらもただヒント画像を与えることで、生成画像を制御することができるという点では同じ。
しかし、モデルの軽量さという観点では大きく異なる。ControlNetはDownブロックをコピーし、しかも毎ステップ推論が走る。一方でT2I-Adapterのモデルサイズは小さく、1度しか推論しないという点で大きく有利。
でも、ControlNetが流行った。これはなぜか。答えは単純。
ControlNetのリリースが3日だけ早く、話題をかっさらってしまったから。
T2I-Adapterのリリース: 2023年2月15日

ControlNetのリリース: 2023年2月12日

正確なリリース日が特定できなかったのでHFの最初のIssueの日時をリリース日と仮定