GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか
はじめに
Googleが2025年3月14日に発表したGemini-2.0と、続けてOpenAIが2025年3月26日に発表したGPT-4oの画像生成能力は、これまでの画像生成AIでは到達しえないレベルの制御性・品質での画像生成を実現しました。
ここ1年半ほど画像生成AIいじりを仕事にしてきた者としては、これまで積み上げてきた成果や進捗がすべて無に帰すレベルでの進化が突然起き、巨人にすべてを蹴散らされたという感じです。別のスキルを身につけたほうがいいかな…
しかし一方で、この進化は決して1日にして為されたものではなく、これまでの研究成果が地道に蓄積された結果です。本記事では、その驚異的な画像生成能力、ひいてはAny-to-Anyの生成能力の裏にある技術的な背景を、分かる範囲でサクッと解説していきます。
これまでの画像生成AI
TL;DR: これまで広く利用されてきた画像生成AIは、拡散モデルをベースにしている。
これまでの画像生成AIの世界では、Stable DiffusionやFlux.1、DALL-E 3などが広く利用されてきました。これらのモデルに共通する特徴は、拡散モデル(Diffusion Model)と呼ばれる設計を基盤としていることです。
拡散モデルについてはzennでも説明され尽くしていると思うので簡単に記述しますが、動画像生成などのタスクに用いられる現行のデファクトスタンダード的な手法です。
拡散モデルでは、まず既存の画像に対してノイズを徐々に加え、最終的には完全なランダムノイズ状態にします。これを拡散過程(forward diffusion process)と呼びます。そして、学習中・学習済みのモデルは拡散過程を逆転させ、ノイズから元の画像の持つ特徴(形状や色彩)を段階的に復元していきます。これが逆拡散過程(reverse diffusion process)です。

紙に下書きを重ねながら完成イラストに仕上げていくプロセスのように、タイムステップの初期では低周波な画像の特徴を、後半では高周波な特徴を描き、拡散モデルは画像のディテールを一歩一歩創り出していきます。
これにより、非常に高品質な画像の生成が実現される、というものでした。
自己回帰モデルの画像生成への応用
拡散モデルが動画像生成で幅広く成功を収めた一方で、研究レベルではそれとは全く異なるアプローチが少しずつ進化していました。
Parti
TL;DR: Partiは、言語モデルで成熟しつつある技術を画像生成に応用した。
2022年頃、拡散モデルに比肩するアプローチとして、言語モデルと同様に画像を自己回帰(autoregressive, AR)的に生成するモデリング手法が最先端の性能を記録しました。
Parti(Pathways Autoregressive Text-to-Image model)は、Googleによって開発された自己回帰モデルで、テキストから画像への生成を、機械翻訳のような「配列から配列への変換問題」として扱いました。テキストの入力を受け取り、それを翻訳するかのように画像トークンの配列を生成する仕組みです。
自己回帰モデルを画像生成に応用する研究はこれまでにもいくつか存在していましたが、Partiは言語モデルの研究成果をシンプルにほぼそのまま画像生成に応用したという意味で画期的でした。
なお、PartiはVQGANとTransformerの2つの主要コンポーネントから構成されています。

- VQGAN: Transformer型の画像トークナイザーで、画像を圧縮した離散トークンの配列にエンコード・デコードする
- Transformer: Encoder-Decoder型のTransformerモデルで、テキストから画像トークンへの"翻訳"を行う
(一応その後に256x256から1024x1024へのUpsamplerも付属しているようですが、ここでは省略します。)
Partiは学習過程で、まずVQGANを独立して学習し、画像を離散トークンに変換する能力を獲得します。その後、Transformerモデルがテキスト入力を受け取り、対応する画像トークンを予測するように訓練されます。
Partiの性能は、複雑な構図や世界知識を必要とするプロンプトに対しても優れた結果を示し、MS-COCOデータセットにおいて、当時のGoogleが開発していた最新の拡散モデルの性能を超えるスコアを達成しました。

そして、Partiは言語モデルと同様に、モデルの規模を大きくすることで性能を向上させることができるという性質(≒スケーリング則)を持っていることも確認されたのです。

この発表から、画像生成能力において自己回帰モデルが拡散モデルに劣らず、言語モデルの膨大な知見を画像生成にも流用できるという点においてはむしろ大きく優れていることが分かりました。
一方で、当時のGoogleはまだ生成AIの研究成果を世に公開することのリスクを慎重に捉えていたため、モデル自体は一般には公開されず、アプリ等で提供されることもなかったので、残念ながらその性能が公になることはありませんでした。
CM3leon
TL;DR: CM3leonは、Partiのようなテキストから画像への生成だけでなく、画像からテキストへの生成も同時に可能にしたモデルであり、Gemini-2.0やGPT-4oのようなAny-to-Anyモデルの考え方の先駆けと言える。
GoogleのPartiに続き、Facebook AI Researchは2023年7月にCM3leon(発音は「カメレオン」)というモデルを発表しました。
CM3leonは、LLMの設計によく用いられるDecoder-onlyのTransformerをバックボーンとし、Partiのようなテキストから画像への生成だけでなく、画像からテキストへの生成(例: 画像キャプション生成、視覚的質問応答)も単一のモデルで実現した点で画期的です。

ちなみに、画像のトークン化は、Partiと少し異なるVQVAEというものが用いられましたが、テキストと統一的に扱うために画像を離散トークン配列に変換するという点はPartiと同じです。
CM3leonは複雑なオブジェクト(例:サングラスと帽子をかぶった鉢植えのサボテン)の生成はもちろん、テキスト指示に基づく画像編集、構造(セグメンテーションマスクなど)に基づいた画像編集など、多様なタスクで高い性能を示しました。
単一モデルでテキストと画像を双方向に扱え、多様な指示に応じた生成・編集が可能であるというCM3leonの特性は、のちのGemini 2.0やGPT-4oのような、より汎用的なAny-to-Anyモデルの基盤となる考え方の先駆けとも言えます。
Any-to-Anyの生成AI
PartiでLLMの設計が画像生成に持ち込まれ、CM3leonでテキストと画像を単一のモデルで同じように扱うような発想が生まれると、今度はテキスト、画像、音声など異なる種類のデータを全て離散トークンとして統一的に表現することで、多様なモダリティを入力として受け取り、同時に様々な形式で出力できる「Any-to-Any」モデルという概念が浮かび上がってきます。
Any-to-Anyモデルの核となる考え方は、異なるモダリティを統一された離散表現で処理することで、LLMのアーキテクチャや訓練パラダイムを大きく変えることなく、複数のモダリティを扱えるようにすることです。
CM3leonから半年ほど経った2023年末から2024年にかけて、Any-to-Anyモデルの概念に基づくいくつかの研究が発表されました。
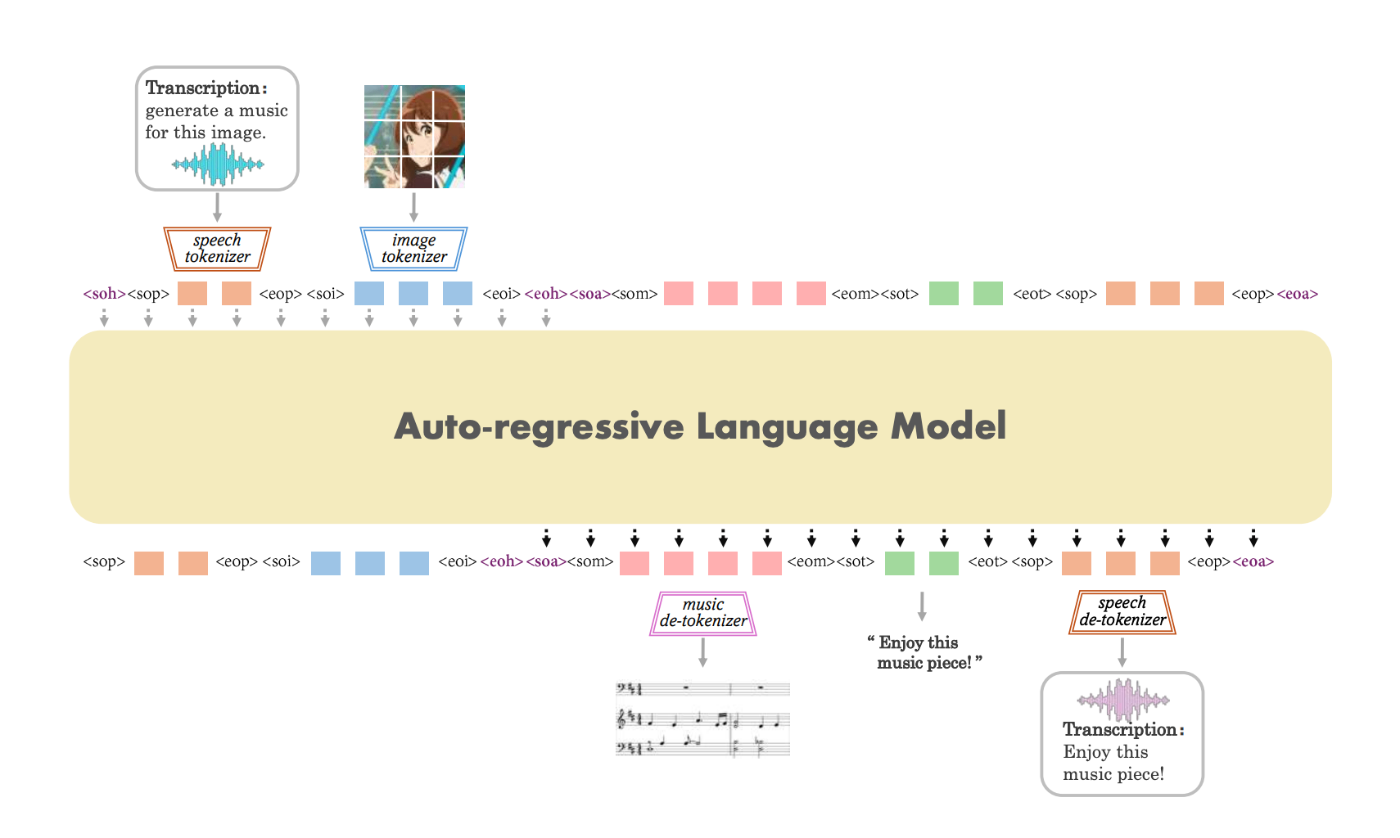

非常に図が分かりやすいので、個別の説明は割愛します。どちらも、すべてをうまくトークナイズして表現として画一化した上で、1つのモデルに放り込み、その後、再び異なるモダリティにデコードするという考え方です。
そして、このような手法は言語モデルと同様、モデルを大規模化することで、より高品質な生成結果を出すことが可能であるということも確認されました。

このことはつまり、自己回帰型のAny-to-Anyモデルが、テキストのみならずあらゆるデータを効率的に処理するためにスケールできることを示唆しています。
そして、このような研究レベルでの仮説検証からしばらく経ち、去年10月頃にはGPT-4oの音声生成が、今年3月頃にはGemini-2.0とGPT-4oの画像生成が、それぞれ発表されたわけです。
Gemini-2.0
Gemini-2.0は、テキスト、画像、動画、音声などの多様なモダリティを入力として受け付け、同時に出力することもできる真のAny-to-Anyモデルです。このようにモダリティの壁を取り払い、様々な形式の情報を統合的に1つのモデルで扱えるというのは、とてもシンプルで分かりやすいですね。

Gemini-2.0の概念図はよいものがなかったので、1.0のものを載せています。今なら音声出力も可能になっているはずです
テキスト・視覚・音声の間でシームレスな相互作用が可能になると、(公開されてませんが理論的には)会話を通じた画像生成や編集などの機能が実現します。
モデルの技術的詳細に移りましょう。Googleの論文(arXiv:2312.11805)によると、Geminiの画像生成については以下のように記述されています。
Gemini models are trained to accommodate textual input interleaved with a wide variety of audio and visual inputs, such as natural images, charts, screenshots, PDFs, and videos, and they can produce text and image outputs. The visual encoding of Gemini models is inspired by our own foundational work on Flamingo, CoCa, and PaLI, with the important distinction that the models are multimodal from the beginning and can natively output images using discrete image tokens.
この記述から分かることは少ないですが、少なくともGeminiが「離散的な画像トークン」を使って画像を出力していることがわかります。Geminiが画像を生成するときは、PartiやCM3leonのように、まず離散的な画像トークンを生成し、それをデコードして最終的な画像にするというプロセスを踏んでいるのです。
また、GeminiはEncoder-Decoderの構造を持ち、Encoderの部分で異なるモダリティを融合させていることも示唆されています。しかし、その詳細なメカニズム(本当に全部突っ込んでいるだけなのか、細かい仕掛けがあるのか)については具体的に説明されていません。
GPT-4o
GPT-4oもGemini-2.0と同様、テキスト、音声、画像を入力とし、同時にそれらを出力することができるAny-to-Anyモデルです。
ただし、GPT-4oはGemini-2.0以上にヒントが少なく、自己回帰的に生成していること以外、画像生成の詳細なメカニズムが全く公開されていません。
しかし、ChatGPT上で画像生成を試してみると、以下のような順番で画像生成が行われていることが分かります。
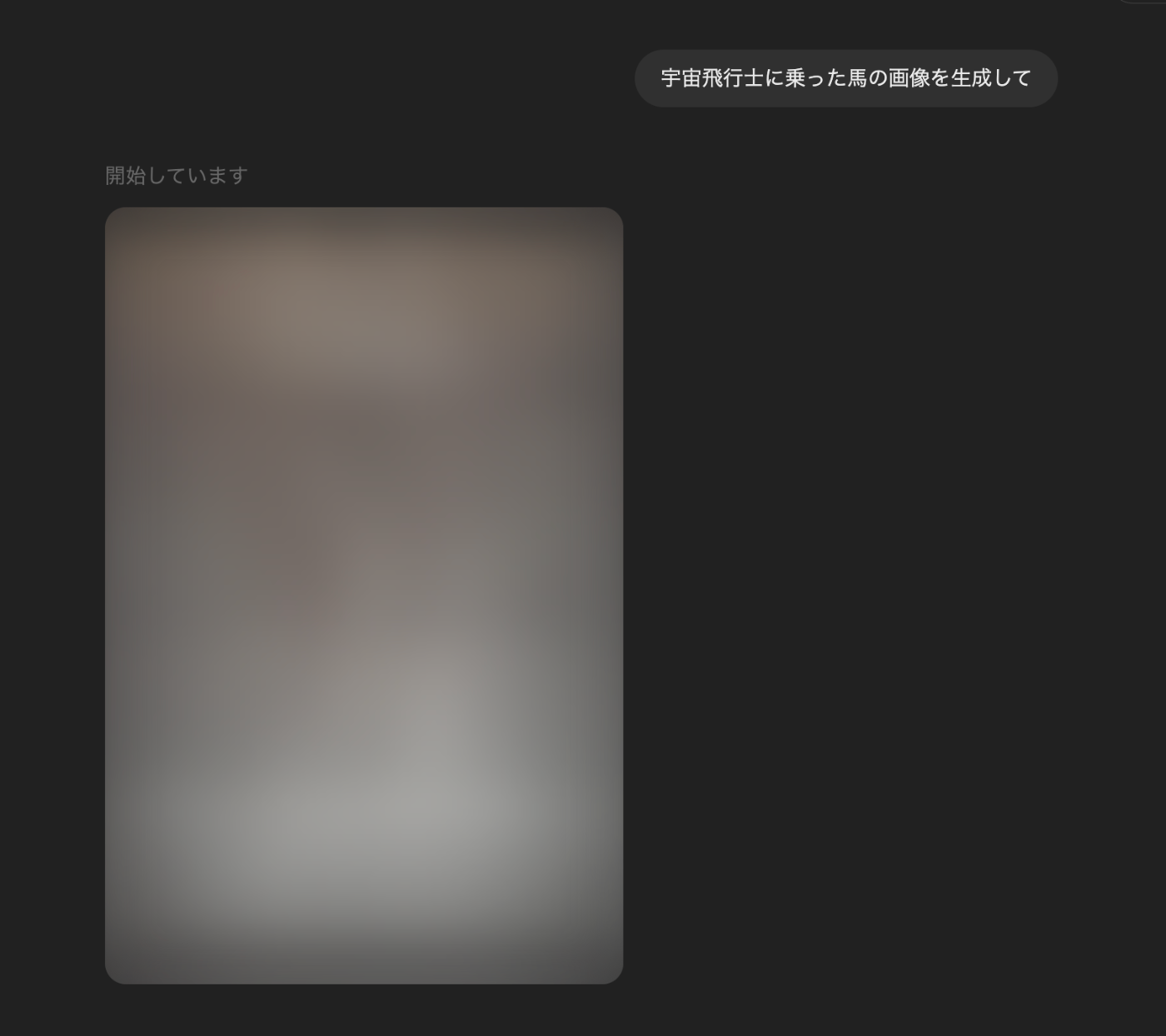
まず全体のアタリをつける
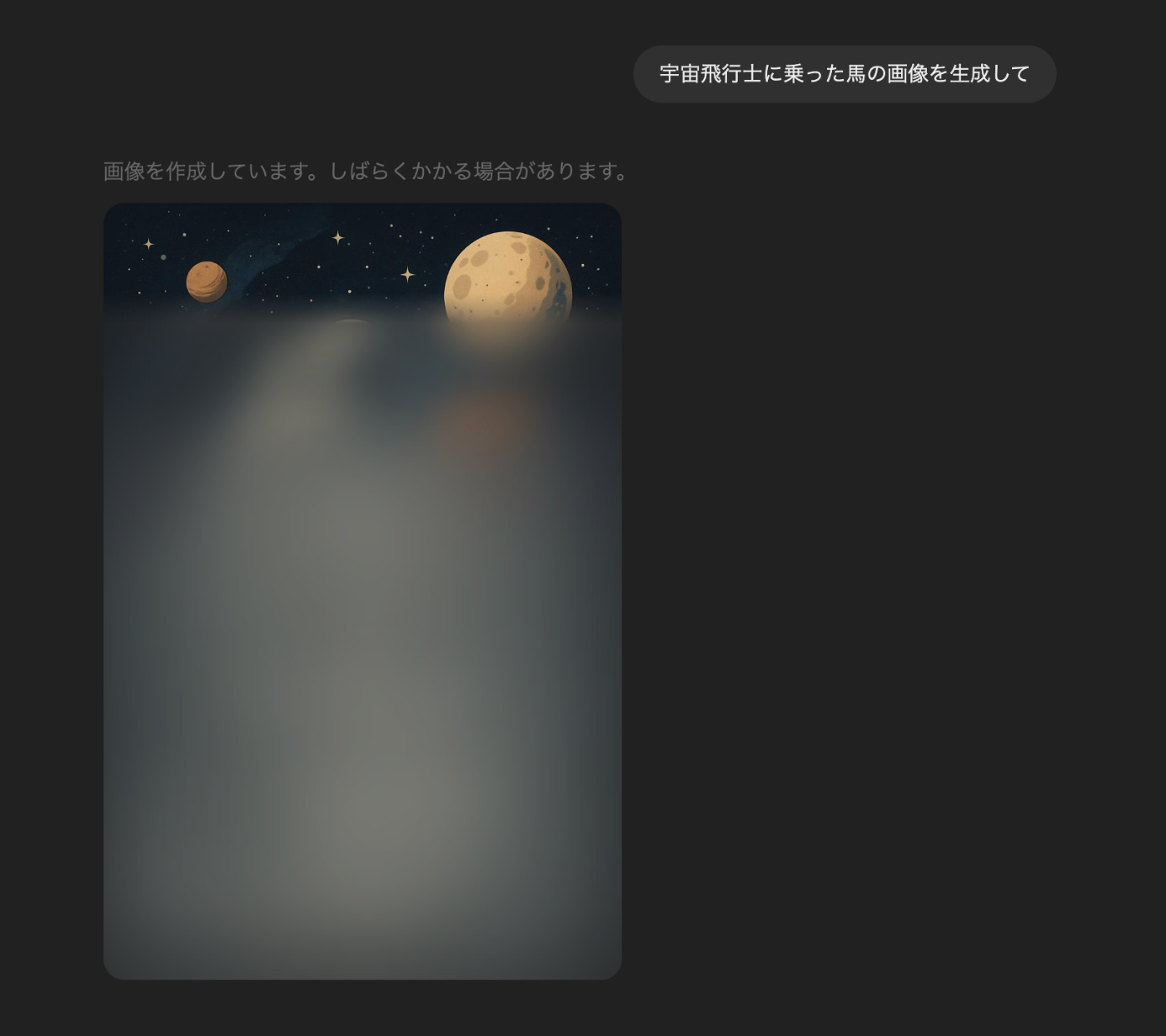
その後、細部を上から追加していく
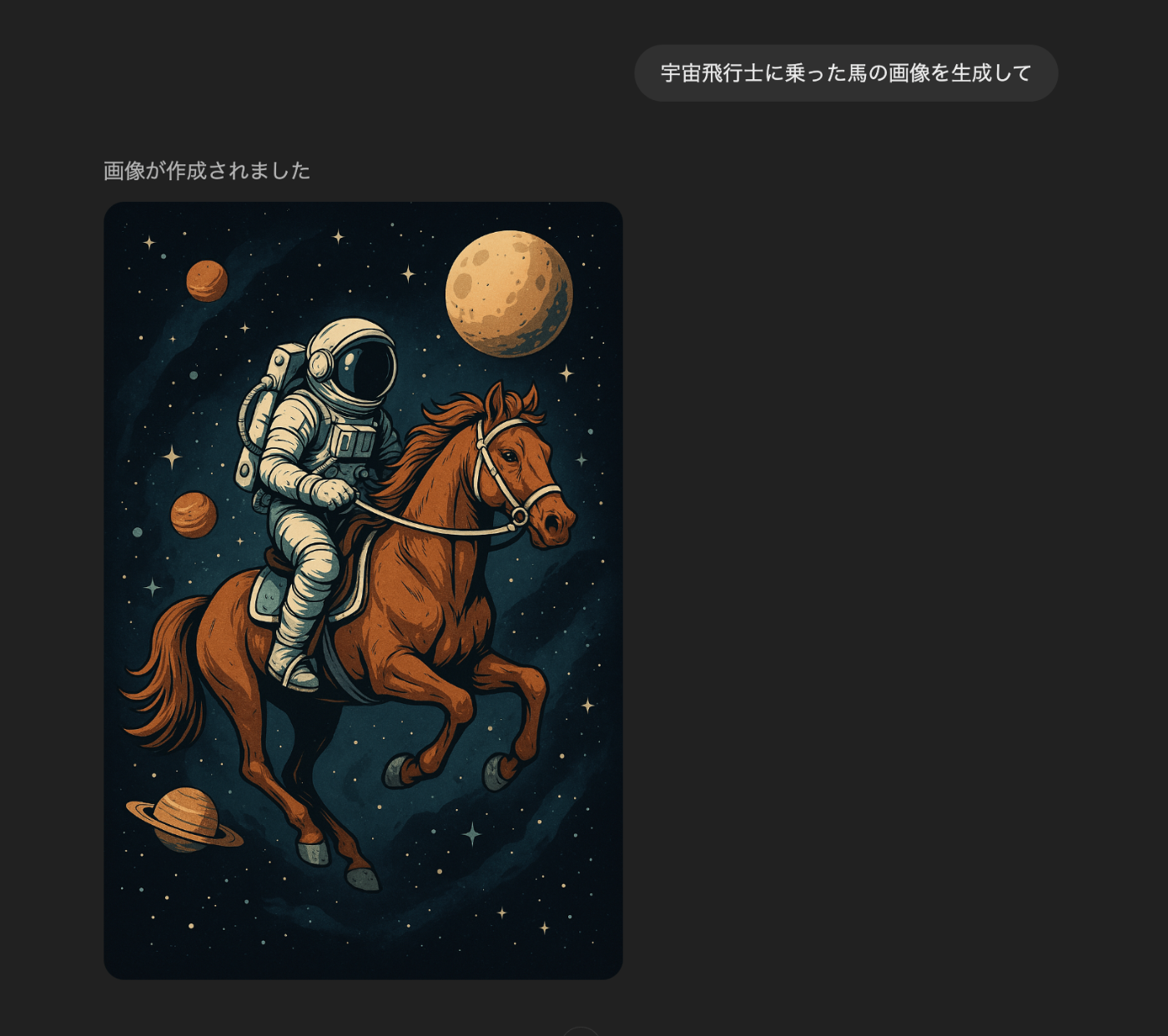
完成(宇宙飛行士"に"乗った馬は生成できなかった様子)
この様子をそのまま受け取れば、まず低解像度で画像トークンを生成し、その後、細部を徐々に追加していくようなやり方をしていると考えられるので、VARのような手法を使っているのかもしれません。
しかし、GPT-4oの画像生成は2024年5月にはすでに内部で実現していたようなので、その後に発表されたVARをそのまま使っているとは考えにくいですし、そもそも、細部を追加していく順番が上から下に向かって自己回帰的に行われているというのも、VARとは異なります。
概念的にVARと類似した手法を使っている可能性はありますが、Any-to-Anyモデルの出力が低解像度で、その後のVAR的なRefinerが画像生成の大部分を担っているとすれば、それは単一モデルにモダリティーを集約しているわけではなくなってしまうので、学習が非常に煩雑なものになってしまいそうです。
なので、初期に出てくるブラーがかった出力は、ユーザー体験を向上させるために先んじて表示しておく近似的なものであり、実際の出力はとても圧縮比率の低い画像トークンの生成を時間をかけて行っているのかも、とか個人的には思っていますが、実際のところは分かりません…。
追記: 強そうな人たちのアーキテクチャ予想がいくつか出てきているので、参考に掲載しておきます。
最近のXの風潮としては、マルチモーダルな自己回帰モデルで生成した画像トークンを、Diffusionモデルを用いて上から下へ、一定のブロック(8x8ピクセル単位?)ごとにデコードしているのではないか、というものが多いです。そんな気がする。
おわりに
この記事では、GPT-4oとGemini-2.0のAny-to-Anyモデルの裏にある技術的な背景を、分かる範囲で解説していきました。
これまで応用面で用いられてきた画像生成AIは、そのほとんどが拡散モデルをベースとしていましたが、研究段階ではPartiのような言語モデル技術を画像生成に応用したアプローチ、CM3leonのような双方向テキスト-画像生成能力を持つモデル、そしてAny-to-Anyモデルへと、進化の道筋が着実に開かれていました。
そして、これらの研究成果が、2024年末から2025年にかけて、ついにGPT-4oとGemini-2.0のような、より汎用的なAny-to-Anyモデルとして姿を表したわけです。
一方で、研究レベルでの技術の進化は現在進行形で進んでおり、近頃は連続的なトークン表現で自己回帰モデルを学習させたり、拡散モデルと自己回帰モデルを統合したりするような手法も登場していて、こちらも今後どうなっていくのか、引き続き目が離せない分野です。
私は職を失ってしまうかもしれませんが、相変わらず面白い領域です。
Discussion
画像自体は上が見えた時点ですでに生成されており、ブラーを剥がす演出中に別のモデル・検索等で著作権対策の類似度や倫理チェックを行っているんじゃないかと見ています。