とうとう現れたSDXLの後継?CogView4-6Bを解説する
はじめに
こんにちは。
最近、というかFlux.1以降、画像生成AIって大きな進化がない印象を受けませんか?
というのも画像生成AIは、Stability AIが規模を縮小し、Vision系の生成AIの主戦場が動画生成AIに変わってからというもの、大量の資金が投下されることが少なくなってきています。
とはいえ、進歩がゼロというわけではなく、緩く進化を続けていて、NVIDIAのSanaや、Stability AIがSD3から大幅な改善を施したStable Diffusion 3.5シリーズなどは、Flux.1以降に登場してきていますし、研究レベルではVARやMARといった、拡散モデルと自己回帰モデルの融合のような新しい枠組みも生まれてきています。
しかし、研究レベルのものは実用に足りませんし、Flux.1以降の高性能なモデルには商用利用性に難があったり、そもそも追加学習をしにくい仕組みになっていたりと、実用的な選択肢が限られていました。
そんな中、清華大学 (THUDM)から突如として公開されたのがCogView4-6Bです。
このモデルはApache-2.0ライセンスという寛容なライセンスを採用し、かつ技術的には最新の研究成果を取り入れた正統派の画像生成モデルとなっています。Apache-2.0ライセンスで提供される今風な画像生成モデルが登場したことは、SDXL以来の大きな転換点と言えるのではないか?と思います。
そこでこの記事では、このCogView4-6Bの特徴と技術的な詳細を深掘りしていこうと思います。
概要
CogView4-6Bは、清華大学 (THUDM) が開発した最新の画像生成AIモデルです。
特徴:
- ライセンス: Apache-2.0(すごい)
- モデルサイズ: 6Bパラメータ (Diffusion Transformer部分)
- テキストエンコーダー: GLM-4-9B
- 画像生成品質: ベンチマーク上ではSD3.5、Flux.1、DALL-E 3と同等
- アーキテクチャ: UNetではなくTransformerベース (DiT)
従来のSDXLは、一部Transformerを含みつつも、全体としてはUNetというCNN (畳み込みニューラルネットワーク) ベースのアーキテクチャを採用していたのに対し、CogView4はSD3と同様の特殊なTransformerベースの構造であるMM-DiTアーキテクチャを採用しています。
また、SD3以降デファクトになりつつある定式化であるRectified Flowはもちろん、SDXL/SD3に導入されなかったRoPE (Rotary Position Embedding) などの技術も積極的に取り入れられています。技術的な詳細は後のセクションで説明します。
生成品質
まずはCogView4-6Bの生成品質について見ていきます。
最初に、公式がショーケースとして挙げていた画像はこちら。

続いて、アニメ風イラストの生成も試してみましょう。以下のプロンプトはすべて日本語訳後のもので、画像生成に使ったのは英語です。
プロンプト例1: "静かな屋外で、長い黒髪を高い位置でポニーテールにして赤いヘアピンで飾った少女。白いブラウスに赤い蝶ネクタイの制服姿で、明るく無邪気な雰囲気を醸し出している。背景には、白い花が点在する緑豊かな野原が描かれ、平和で楽しい雰囲気を高めている。アーティスティックなスタイルは生き生きと細部まで描かれており、のんびりとした晴れた日のエッセンスを表現している。アートワークはアニメ風。"

プロンプト例2: "花見を楽しむ高校生たちを描いた活気あふれるアニメシーン。満開の桜の木の下でブルーシートの上に座り、弁当を分け合って笑い合う。柔らかなピンクの花びらが宙を舞い、木漏れ日が暖かくノスタルジックな雰囲気を醸し出している。アートワークは、現代のアニメ作品によく見られる、すっきりとしたラインと柔らかな色使いが特徴だ。"

プロンプト例3: "サイバーパンクな大都市の雰囲気のある夜景。ネオンブルーの髪に近未来的な衣装をまとったひとりの女性キャラクターが、街を見下ろす屋上に立っている。ホログラフィック広告が雨の街を照らし、水たまりに反射している。街並みには、さまざまな言語で書かれた光る看板で飾られた高層ビルがそびえ立っている。細部まで作り込まれた建築要素と、様式化されたアニメのキャラクターデザインを組み合わせたアートスタイル。"

プロンプト例4: "雲に囲まれた浮島の城が描かれた気まぐれなファンタジー風景画。虹の橋で結ばれた遠くの浮島を眺めながら、茶髪の乱れた髪に特大のローブを羽織った若い魔法使いの見習いが端に立っている。小さなドラゴンや精霊の家族といった魔法の生き物が近くを漂っている。夢見るようなパステルカラーと柔らかな照明が、古典的なアニメ・ファンタジーのスタイルで、魅惑的な別世界の雰囲気を作り出している。"

プロンプト例5: "日本の伝統的なカフェの中の居心地の良い日常風景。赤茶色のショートヘアの少女が窓際に座り本を読んでいる。雨がガラスを叩いている。ホットチョコレートのカップからは湯気が立ち昇り、窓辺では猫がすやすやと眠っている。インテリアには木製の家具、植物、柔らかな照明が使われている。温かみのある色調と細かなテクスチャーを強調したイラストレーション・スタイルで、快適で親密な雰囲気を醸し出している。"

プロンプト例6: "山寺の中庭で繰り広げられる2人のライバル武術家のアクション満載のバトルシーン。一人は青いエネルギーを拳に注ぎ、もう一人は赤いオーラを放つ伝統的な剣を振るう。桜の花びらと葉っぱが二人の周りをドラマチックに渦巻きながらぶつかり合う。背景には古代の石造建築と霧に包まれた遠くの山々が描かれている。ダイナミックな構図と大胆な色のコントラストが、古典的な少年アニメのスタイルで瞬間の激しさを際立たせている。"

SDXLと比較すると、CogView4-6Bは全体的な画面構成や遠近感の表現が自然ですし、何よりeps-predictionから脱却しただけあって発色の良さがとてもいい気がしています。
複数人物が登場するシーンでは依然として手や足などの崩れが見られる場合もありますが、このあたりはイラスト風のドメインを十分に理解していない面もありそうなので、ファインチューニングを施すことで改善される気がしています。現段階でこの品質が出ているのは、ベースモデルとしてのポテンシャルを感じます。
そして、Flux.1やSD3.5にない特徴として、1536x1536での生成も安定しています。下の画像は同じプロンプトで1536x1536の生成を試してみた結果。

なかなかいいですね。
ベンチマーク
一応CogView4-6Bのベンチマークと、それをClade-3.7-Sonnetに見せて評価させたものも載せておきます。
もっとも画像生成界隈のベンチマーク、かなり大本営発表感ありますが。
...
DPG-Bench
| Model | Overall | Global | Entity | Attribute | Relation | Other |
|---|---|---|---|---|---|---|
| SDXL | 74.65 | 83.27 | 82.43 | 80.91 | 86.76 | 80.41 |
| PixArt-alpha | 71.11 | 74.97 | 79.32 | 78.60 | 82.57 | 76.96 |
| SD3-Medium | 84.08 | 87.90 | 91.01 | 88.83 | 80.70 | 88.68 |
| DALL-E 3 | 83.50 | 90.97 | 89.61 | 88.39 | 90.58 | 89.83 |
| Flux.1-dev | 83.79 | 85.80 | 86.79 | 89.98 | 90.04 | 89.90 |
| Janus-Pro-7B | 84.19 | 86.90 | 88.90 | 89.40 | 89.32 | 89.48 |
| CogView4-6B | 85.13 | 83.85 | 90.35 | 91.17 | 91.14 | 87.29 |
GenEval
| Model | Overall | Single Obj. | Two Obj. | Counting | Colors | Position | Color attribution |
|---|---|---|---|---|---|---|---|
| SDXL | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
| PixArt-alpha | 0.48 | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 |
| SD3-Medium | 0.74 | 0.99 | 0.94 | 0.72 | 0.89 | 0.33 | 0.60 |
| DALL-E 3 | 0.67 | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 |
| Flux.1-dev | 0.66 | 0.98 | 0.79 | 0.73 | 0.77 | 0.22 | 0.45 |
| Janus-Pro-7B | 0.80 | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 |
| CogView4-6B | 0.73 | 0.99 | 0.86 | 0.66 | 0.79 | 0.48 | 0.58 |
T2I-CompBench
| Model | Color | Shape | Texture | 2D-Spatial | 3D-Spatial | Numeracy | Non-spatial Clip | Complex 3-in-1 |
|---|---|---|---|---|---|---|---|---|
| SDXL | 0.5879 | 0.4687 | 0.5299 | 0.2133 | 0.3566 | 0.4988 | 0.3119 | 0.3237 |
| PixArt-alpha | 0.6690 | 0.4927 | 0.6477 | 0.2064 | 0.3901 | 0.5058 | 0.3197 | 0.3433 |
| SD3-Medium | 0.8132 | 0.5885 | 0.7334 | 0.3200 | 0.4084 | 0.6174 | 0.3140 | 0.3771 |
| DALL-E 3 | 0.7785 | 0.6205 | 0.7036 | 0.2865 | 0.3744 | 0.5880 | 0.3003 | 0.3773 |
| Flux.1-dev | 0.7572 | 0.5066 | 0.6300 | 0.2700 | 0.3992 | 0.6165 | 0.3065 | 0.3628 |
| Janus-Pro-7B | 0.5145 | 0.3323 | 0.4069 | 0.1566 | 0.2753 | 0.4406 | 0.3137 | 0.3806 |
| CogView4-6B | 0.7786 | 0.5880 | 0.6983 | 0.3075 | 0.3708 | 0.6626 | 0.3056 | 0.3869 |
ベンチマーク総評
3つのベンチマークを総合的に見ると、CogView4-6Bの強みは以下の点にあります:
- 高い数値理解能力: 数や量に関する指示を正確に反映する能力
- 物体間の関係性理解: 複数の物体間の関係性を適切に表現できる
- 属性の正確な表現: 物体の色や質感などの属性を正確に反映できる
- 複雑な指示への対応: 複合的な指示や詳細な条件を満たす生成能力
一方で、改善の余地がある点としては:
- 全体構図の把握: グローバルな構図や雰囲気の表現では他のトップモデルにやや劣る
- 特定のジャンル向け最適化: 特化型モデルと比べると特定ドメインでの表現力に差がある
...
384x384の画像しか生成できないJanus-Pro-7Bや、性能がユーザーの期待よりも低かったことから軽く炎上騒ぎになったSD3-mediumがベンチマーク上でなかなか高いことからも、なんとなく実際の品質を反映していない雰囲気があります。参考程度に見ておきましょう。
使用VRAM
実際に使用する際に気になるのがVRAM使用量です。以下の表は公式リポジトリから引用した、各解像度におけるVRAM使用量の目安です。
| Resolution | enable_model_cpu_offload OFF | enable_model_cpu_offload ON | enable_model_cpu_offload ON Text Encoder 4bit |
|---|---|---|---|
| 512 * 512 | 33GB | 20GB | 13GB |
| 1280 * 720 | 35GB | 20GB | 13GB |
| 1024 * 1024 | 35GB | 20GB | 13GB |
| 1920 * 1280 | 39GB | 20GB | 14GB |
| 2048 * 2048 | 43GB | 21GB | 14GB |
テキストエンコーダーのサイズがかなりデカいため、すべてをVRAMに載せたままの推論だとRTX5090でも足りず、L40S等が必要になってくるのが扱いづらいポイントですが、4bit量子化やCPU offloadを駆使すれば、一般的なハイエンドGPUでも十分動作させることができそうです。
また、Flux.1と同様に拡散モデルの精度をfp8まで下げても精度が維持できれば、普通のGPUでも動きそう。
技術的な解説
ここからはCogView4-6Bの技術的な解説をしていきます。なにか間違っていたら教えて下さい。
CogView4-6Bは、結論から言うと先行研究の知見を全部統合したような画像生成モデルで、具体的には以下のような点を取り入れています。
- MMDiT : UNetではなくTransformerベースのアーキテクチャで、Flux.1よりもSD3に近い構造
- AdaLN-Zero: 効果的な条件付け入力の手法
- 16ch VAE: より圧縮率の低いVAE
- Rectified Flow: シンプルで効率的な定式化
- GLM-4-9B: T5-XXLよりもモダンなテキストエンコーダー
- RoPE: 位置情報を上手に符号化する回転位置埋め込み
これらの技術を順に解説します。
DiTとAdaLN-Zeroについて
この項目では、Scalable Diffusion Models with Transformersでの結果が主に参照されています。
Diffusion Transformer (DiT)
DiT (Diffusion Transformer) は、従来の拡散モデルのバックボーンとして使われてきたUNetアーキテクチャを、Transformerに置き換えるアプローチです。
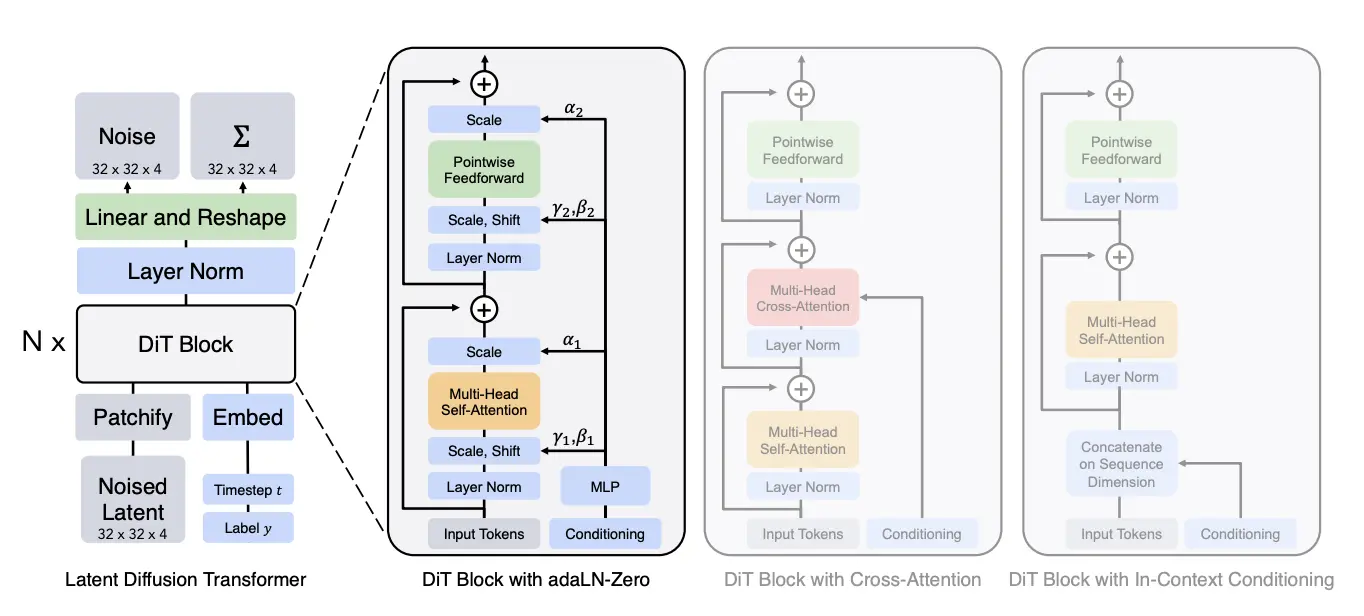
UNetは画像処理において長年使われてきた畳み込みニューラルネットワーク (CNN) ベースのアーキテクチャですが、DiTはこれをTransformerベースに置き換えることで、大規模言語モデル (LLM) で観測されているスケーリング則を画像生成の分野にも適用できるようにしました。
そして、Flux.1以降のDiTでは、ほとんどのケースにおいて、以下のような見るからに面倒くさそうな形状のMM-DiT Blockと呼ばれるTransformer Blockと、一般的なDiT Blockが併用されているのですが、CogView4-6BではSD3のやり方を踏襲し、すべてのDiT BlockがMM-DiT Blockになっています(ただしFFのMLPは2つのモダリティで共有)。
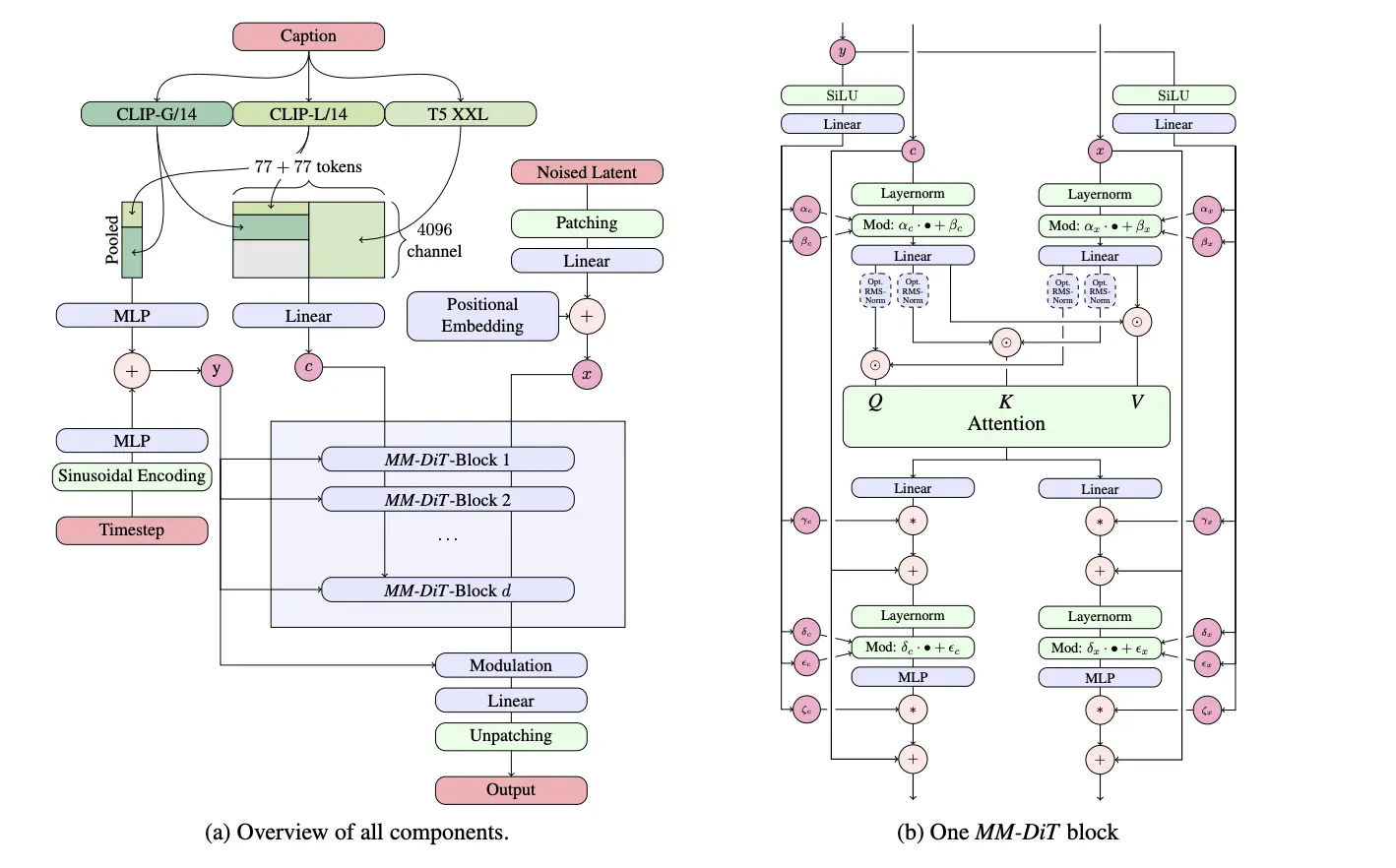
そしてそれは、SD3提案論文でこのMM-DiTを使用したDiTが標準的なDiTより優れているという結果が出てきたためでした。
MM-DiT Blockでは、テキストと画像の2つのモダリティーに由来する特徴をAdaLN-Zero/Feed Forwardでそれぞれ独立して通すことで別個に扱いつつ、Attentionの際のみ結合させて計算を行うような仕組みになっていて、Cross Attentionより無理矢理感なくテキスト情報を画像に反映させることができますし、浅い層と深い層でテキストが画像に与える影響を柔軟に変化させられることが期待できます。
個人的にはシンプルなDiTのほうが好きですが。。。
DiTのPatch Size
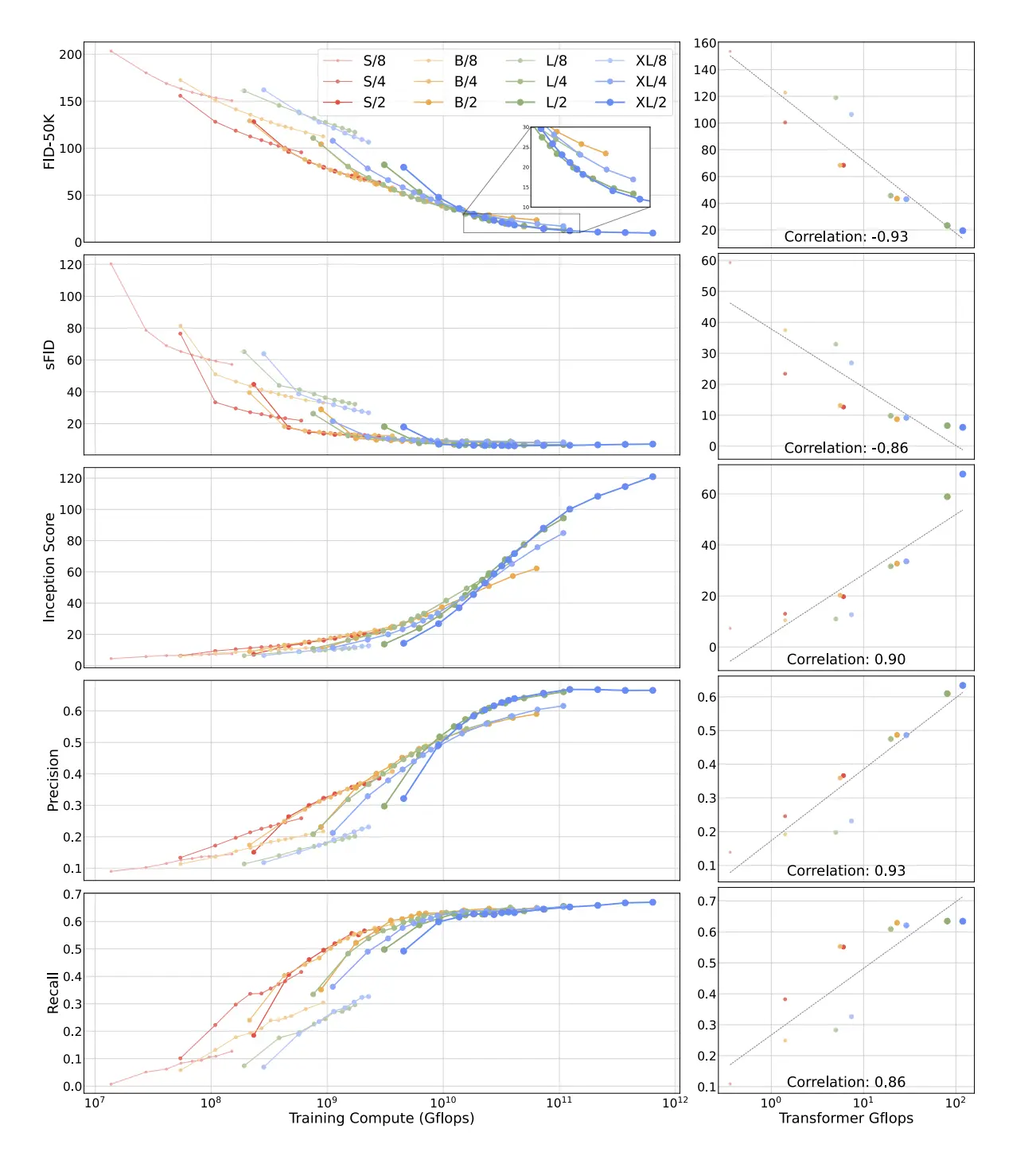
「Scalable Diffusion Models with Transformers」に話を戻すと、当研究では、パッチサイズという重要なハイパーパラメータが性能に大きく影響することが示されました。パッチサイズとは、画像を小さなタイル状の領域に分割する際のサイズのことで、Transformerが画像を処理するときの基本単位となります。
上のグラフは、異なるパッチサイズ (2×2、4×4、8×8) でのモデルサイズと性能の関係を示しています。パッチサイズ2×2の場合が一貫して最も優れた性能を示していますね。小さなパッチサイズを使うことで、モデルはより細かい粒度で画像を処理できて、詳細な情報をより多く保持できるので当然と言えば当然です。
CogView4-6Bはこの知見に従い、パッチサイズ2×2を採用しています。
AdaLN-Zero (Adaptive Layer Normalization Zero)
画像生成を行うモデルを作る場合、条件付けの情報をどのように画像生成プロセスに組み込むかはとても重要な課題です。そこで、CogView4-6Bではテキストによる条件付けをMMDiTによって行い、テキスト以外の情報は「AdaLN-Zero」と呼ばれる手法を採用して行っています。
AdaLN-Zeroは、条件付けを直接Transformerブロックに注入するのではなく、LayerNormalization層のスケール (γ) とシフト (β) パラメータ、そして残差ブロックのゲートパラメータ (α) を介して条件付け情報を導入します。具体的には、
- 時間埋め込み (拡散過程のタイムステップ情報) と画像のサイズや比率に関する情報 (SDXLに用いられていたものとほぼ同様) を結合
- MLPを通して3種類のパラメータ
(γ, β, α)を生成 - これらのパラメータをLayerNorm層と残差ブロックに適用
というプロセスを経ます。実際にはDiTでは各Transformerブロック内で2セットのパラメータ (γ1, β1, α1) と (γ2, β2, α2) を使用しますし、今回のCogView4-6BはMMDiTなので、更にもう2セットのパラメータをテキスト情報への条件付けとして用意します。
adaLN-Zeroは、「Scalable Diffusion Models with Transformers」の中で、Cross Attentionや通常のadaLNと比べ、最も性能が高いことが示された条件付け手法です。
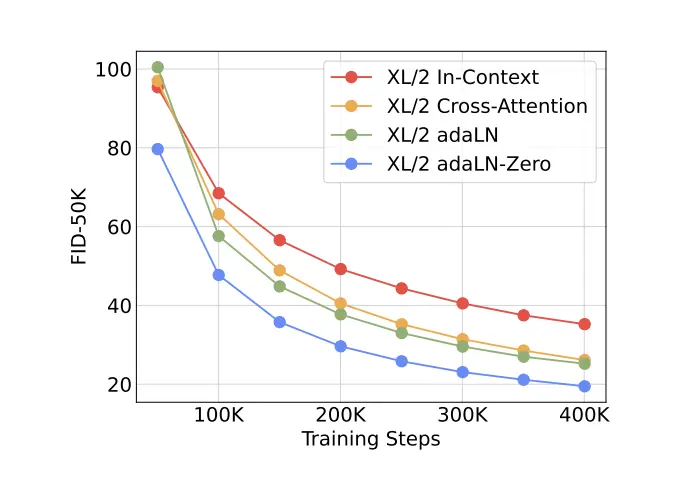
なお、「Zero」という名前の由来は、初期化方法にあります。AdaLN-Zeroは、通常のAdaLNと異なり、パラメータ (γ, β, α) の初期値をゼロに設定するという特徴があります。これによって、
- 学習初期段階では無条件生成に近い挙動をする (
α = 0により残差接続がブロックされるため) - 徐々に条件の重要性を学習していく
という風に、モデルが好きなタイミングで、徐々にタイムステップや画像サイズの情報を加味して画像生成するようになっていきます。この「ゼロ初期化」アプローチによって、トレーニングの安定性を大幅に向上させることができ、最終的なモデルの品質も向上させることができたようです。
ちなみに、比較的最近のICLR2025採択論文であるUnveiling the Secret of AdaLN-Zero in Diffusion Transformerでも、このゼロ初期化がAdaLN-Zeroのパフォーマンスに大きな影響を与えている要素であることが示されています(同時にもっと良いAdaLNも提案されています)。
16ch-VAE, Flow Matchingについて
この項目では、SD3の提案論文でもあるScaling Rectified Flow Transformers for High-Resolution Image Synthesisでの結果が主に参照されています。
16ch VAE(Variational AutoEncoder)
VAEは、画像を圧縮された潜在空間に変換し、再び画像に戻す役割を担います。拡散モデルは通常、この潜在空間上で動作することで計算効率を高めていて、Stable Diffusionが登場する少し前から伝統的にこの手法が用いられています。
当論文では、Stable Diffusion 1/2・SDXLに用いられてきた従来の4ch VAE、または8ch VAEよりも16chのVAEが画像品質の劣化を最小限に抑えることが示されています。

まあこれは圧縮比率が下がっているので当然と言えば当然ですね。ではなぜSDXL以前では16ch VAEを使わなかったかというと、チャネル数が多いことがトレードオフをもたらすからです。
具体的には、チャネル数が増えると拡散モデルは、
- より多くの情報を処理する必要があり、
- 層を深くする (表現力を高める) 必要があり、
- 計算コストやメモリ使用量が増加する
ようになります。
「Scaling Rectified Flow Transformers for High-Resolution Image Synthesis」では4/8/16ch VAEを使った場合のDiffusion Transformerの層数と性能の関係を確認しています。
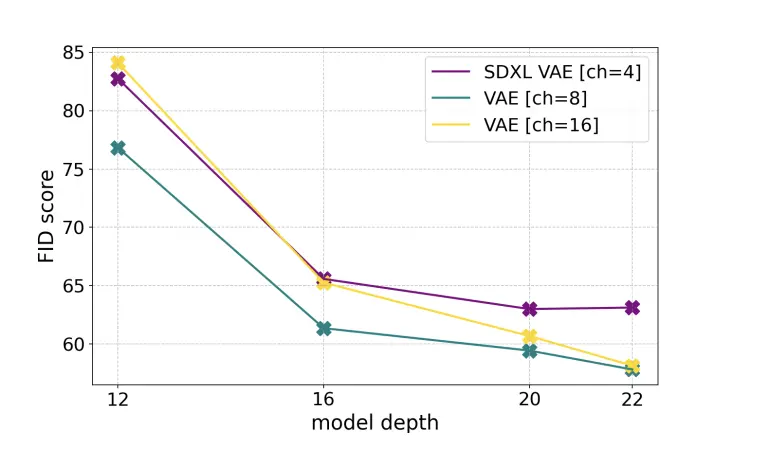
グラフを見る限り、層がかなり深くなってくるまでは16ch VAEの性能が劣っていることが分かりますし、逆に層を深くしていけばこの先もグングン性能が伸びていきそうなカーブが見えます。4ch VAEはかなり早い段階で性能が頭打ちになっていますね。
そして、CogView4-6Bはこの16ch VAEを採用しています。Transformer Blockも28層と、相応に深いモデルになっているため、入力される情報量を扱いきるだけの表現力があると言えるはずです。
Rectified Flow
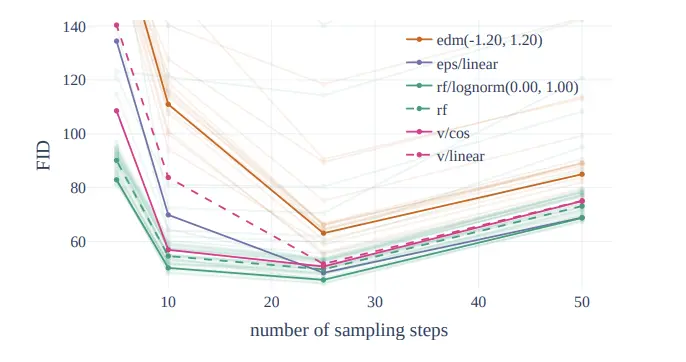
拡散モデルの定式化には様々な方法がありますが、CogView4-6BではRectified Flowという、拡散モデルの特殊形態とも言えるシンプルなFlowベースの手法を採用しています。
これはSD3以前の画像生成モデルに用いられてきた定式化であるEDMやeps-prediction、v-predictionなどよりも生成品質で優れていることが「Scaling Rectified Flow Transformers for High-Resolution Image Synthesis」で示されています。
Text Encoderについて
Flux.1やSD3のようなSDXL以後の画像生成モデルでは、テキストプロンプトをうまく画像生成モデルに与えるためのテキストエンコーダーとして、CLIPに加えてT5-XXLという比較的巨大なEncoder-Decoder型の言語モデルのEncoder部分を用いるようになっていました。
一方で、SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformersという研究はFlux.1やSD3よりも後発の研究であるにも関わらず、T5-XXLのEncoderを採用せず、よりサイズの小さい、モダンなDecoder-onlyモデルであるGemma2-2b-itをテキストエンコーダーとして採用し、T5-XXLを用いるよりも効率的で、かつ高い性能を出すことができたようです。
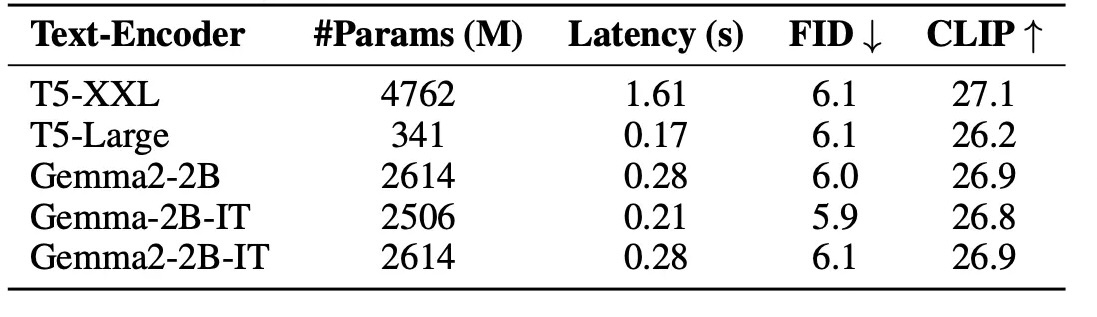
これはDecoder-onlyモデルがEncoderモデルやEncoder-Decoderモデルよりテキスト表現を捉えるのがうまいというよりも、テキスト生成に向いたアーキテクチャであるDecoder-onlyモデルにより多く資金が投入され、モデルとして洗練されているために、テキスト理解力もおのずと上がってきていると考えたほうが正しいでしょう。
そして、Sanaからの流れに倣ってなのかは分かりませんが、CogView4-6Bでは同大学のDecoder-only LLMであるGLM-4-9Bを採用しています。見たところ、複雑なテキスト指示も解釈できますし、またT5-XXLでは扱えない中国語のテキストプロンプトにも対応しているため、モダンなLLMを採用しただけの意味があると言えそうです。
細かいですが、テキスト特徴は太古のNovelAIの提案手法と同じPenultimate Layerの出力をとっているようです。
RoPEについて
Rotary Position Embedding (RoPE) は昨今のLLMで広く採用されている位置埋め込み手法で、トークンの相対位置を上手に表現してAttention機構に伝える役割を担います。
SDXLや、先に挙げたSanaでは位置埋め込みが採用されていなかったほか、SD3では位置埋め込みの手法が少し古いものだったため、構造理解や学習時と異なる解像度での生成に弱い面がありました。
RoPEの主な特徴と利点は以下です。
- 相対位置の明示的なエンコード: 要素間の相対的な位置関係を自然に表現できる
- 解像度の一般化能力: 学習時とは異なる解像度やシーケンス長にも対応できる
- 空間的関係の保持: 複数の物体間の空間的関係をより正確に表現できる
これを日常の例で説明すると、「絶対的な住所」よりも「相対的な位置関係」 (駅から西に200m) 」の方が状況に応じて柔軟に解釈できるのと似ています。
RoPEの導入により、CogView4-6Bは「AはBの上にある」といった空間関係の指示をより正確に反映できるようになりました。GenEvalベンチマークの「Position」カテゴリでのスコア向上にもRoPEの貢献が見られます。
トレンド技術の統合
CogView4-6Bの優れた性能は、上記のすべての今風の技術要素が相互に補完し合うことで達成されていそうです。
- UNetからの脱却と、MMDiTの採用
- AdaLN-Zero
- 16ch VAEと深いTransformer層
- T5-XXLやCLIPより良いText Encoder
- Rectified Flow
- RoPEの採用
おわりに
「おわりに」を書くのが苦手なので、Claude-3.7-Sonnetに締めてもらいます。
...
CogView4-6Bは、画像生成AIの分野において重要な転換点となる可能性を秘めたモデルです。Apache-2.0ライセンスというオープンな枠組みで提供されながらも、最先端の技術を惜しみなく取り入れた正統派のアプローチは、SDXL以降の画像生成AIの新たな潮流を作り出すかもしれません。
特筆すべきは、このモデルが単に技術的に優れているだけでなく、実用性も兼ね備えていることです。テキストエンコーダーの量子化やCPUオフロードを活用すれば家庭用GPUでも動作可能であり、商用利用の制限がないことから、個人開発者からエンタープライズまで幅広い用途に活用できます。
また、DiTアーキテクチャの採用により、UNetからTransformerへという大きなパラダイムシフトを体現している点も見逃せません。これによって画像生成AIも言語モデルと同様のスケーリング則を享受できる可能性が広がり、今後のモデル改良やパラメータ拡大によるさらなる性能向上が期待できます。
RoPEやRectified Flowといった最新技術の統合も、空間関係の理解や生成プロセスの改善に大きく貢献しています。ベンチマーク結果が示すように、商用の高性能モデルに匹敵する生成能力を持ちながら、オープンな形で提供されているという点は革新的です。
オープンソースの画像生成AIコミュニティは、SDXLから相当な時間が経過しても、商用制限のないモデルではなかなか大きな進展がありませんでした。CogView4-6Bはその停滞を打ち破る存在となり得るでしょう。
基盤モデルとしてのポテンシャルを活かしたファインチューニングにより、さまざまな特化型モデルが派生していくことも想像に難くありません。
画像生成AIの民主化と技術革新を同時に進める試みとして、CogView4-6Bの今後の発展と活用例に注目していきたいと思います。
参考文献
- CogView4-6B - Hugging Face: https://huggingface.co/THUDM/cogview4-6b
- Scalable Diffusion Models with Transformers. Peebles et al., 2023
- Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. Esser et al., 2024
- SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers. Yu et al., 2024
- Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow. Liu et al., 2023
- RoFormer: Enhanced Transformer with Rotary Position Embedding. Su et al., 2021
- Rotary Position Embedding for Vision Transformer. Heo et al., 2024
- Unveiling the Secret of AdaLN-Zero in Diffusion Transformer. Jie et al., 2025
Discussion