9/11,12のDroidKaigi 2025に参加してきました!! 今年は特にLLM関連のセッションが印象に残りました。
全然キャッチアップができておらず初めて学ぶことばかりでしたので、実際に自分でも触ってみようと思います。
私と同じように「LLMの情報追えてなかった」「なんか難しそうだな」という方を想定して書いています。カスタマイズや最適化については書いていません。
基本知識
LLM(Large Language Model)
膨大なテキストデータで事前学習された深層学習モデル。自然言語の理解と生成において高い性能を発揮し、質問応答、文章生成、翻訳、要約など幅広いタスクに活用できる。代表的なLLMには、GPT、Gemini、Claudeなどがある。
推論(Inference)
学習済みのモデルを使って新しい入力データに対する予測や回答を生成するプロセス。LLMの推論では、入力されたプロンプト(質問や指示)に基づいて、モデルが確率的に次の単語を予測し、逐次的に文章を生成する。推論時にはモデルのパラメータは更新されず、学習済みの知識を活用して応答を生成する。
オンデバイスLLM
クラウドサーバーではなく、個人の端末上で直接動作する大規模言語モデル。プライバシー保護、高速レスポンス、オフライン動作、コスト削減等のメリットが挙げられる。代表例としては、Gemini Nano、Apple Intelligenceなどがある。
推論エンジン
LLMを実際に動作させて、入力に対して予測や応答を生成するためのソフトウェア。モデルの読み込み、最適化、実行を担い、ハードウェアの特性に応じた高速化を行う。代表例としては、Ollama、llama.cpp、TensorRT、vLLM、MediaPipeなどがある。
1. プロンプト入力
"東京の人口は?"
↓
2. LLM読み込み + トークン化
ファイル読み込み: model.bin → メモリ
トークン化: "東京の人口は?" → ["東京", "の", "人口", "は", "?"]
↓
3. プロンプト処理
ID変換: ["東京", "の", "人口", "は", "?"] → [1234, 56, 789, 12, 45]
埋め込み: [1234, 56, 789, 12, 45] → [[0.1,0.5,...], [0.2,0.8,...], ...]
↓
4. LLM計算実行
自己注意: 各単語間の関係性を計算
Transformer: 文脈を理解し次単語を予測
確率計算: {"東京":0.05, "都":0.85, "市":0.08, ...}
↓
5. 結果出力
単語選択: 0.85の確率で"都"を選択
文字列化: [東京, 都, の, 人口, は, 約, 1400, 万人, です] → "東京都の人口は約1400万人です。"
AI開発プラットフォーム上で動かす
Google AI Studio
Googleが提供するAI開発プラットフォーム。ブラウザ上でGeminiモデルを直接試せるWebベースのツールで、プロンプトエンジニアリングやモデルの動作確認ができます。
MediaPipe Studio
GoogleのMediaPipeフレームワークを使ったAI/MLソリューションを試せるWebベースのプラットフォーム。ローカル推論に特化したツールで、実際にデバイス上で動作するモデルの動作を事前に確認できます。
Google AI Edge Gallery
エッジデバイス(スマートフォンやタブレット)で動作する生成AIモデルを体験できる実験的なアプリ。2025年9月時点ではAndroidでのみ利用可能でGoogle Playからインストールできます。完全にオフラインで動作し、様々なLLMの性能を実際のデバイス上で比較検証できます。
Androidアプリに組み込む
必要なもの
- Android Studio(Hedgehogバージョンで動作確認済み)
- 物理Androidデバイス(Android 7.0/SDK 24以上、開発者モード有効)
モデルのダウンロード
Hugging Faceから使用したいモデルをダウンロードします。
今回わたしは以下のモデルで試してみました。「Files and versions」タブからダウンロードできます。
基本的なファイル命名構成は次の通り。
[モデル名]-[サイズ]-[調整タイプ]-[量子化]-[プラットフォーム]-[その他パラメータ].[拡張子]
| 項目 | 内容例 | 意味・用途 |
|---|---|---|
| モデル名 | Gemma3, Gemma2, Phi2, Falcon, StableLM | モデルファミリーを識別。大文字・小文字は提供元により異なる |
| サイズ | 270m, 1b, 2B, 7b, E2B, E4B | パラメータ数。m:million, b=billion。Gemma 3nのE2B/E4Bは実効パラメータ数 |
| 調整タイプ | it, IT, chat, pt, base | it/IT:指示調整済み、chat:対話最適化、pt:事前学習のみ、base:ベースモデル |
| 量子化方式 | int4, int8, q4, q8, fp16, dynamic_int4, a16w4 | f32:高精度(大きいサイズ)、q4/q8/int4/int8:圧縮(小さいサイズ・高速) |
| シーケンス長 | seq32, seq128, seq512, seq1280 | 推論時の入力トークン数やバッチ処理の違い |
| プラットフォーム | web, android, ios, gpu, cpu | 特定のチップやデバイス向けに最適化 |
| 拡張子 | .task, .litertlm | task:MediaPipe Bundle、.litertlm:.task形式の進化版 |
.taskと.litertlmは、MediaPipe互換形式に変換済みのモデルのため、今回はそのまま利用することができますが、PyTorchモデルの場合はそのままの利用ができないため、AI Edge Torch Generative APIを使用してこちらの手順で変換が必要です。
セットアップ手順
1. モデルを配置
ダウンロードしたモデルをadbコマンドで端末にPushします。
$ adb shell rm -r /data/local/tmp/llm/ # 以前のモデルを削除
$ adb shell mkdir -p /data/local/tmp/llm/
$ adb push output_path /data/local/tmp/llm/model_version.task # or .litertlm
2. 依存関係を追加
app/build.gradle(Module: app)に以下を追加します。
dependencies {
implementation 'com.google.mediapipe:tasks-genai:0.10.27'
}
3. Taskを初期化
端末に追加したモデルパスをセットして、Taskを初期化します。
val modelPath = "/data/local/tmp/llm/model_version.task" # or .litertlm
val taskOptions = LlmInferenceOptions.builder()
.setModelPath(modelPath)
.setMaxTokens(1024)
.setMaxTopK(64)
.build()
llmInference = LlmInference.createFromOptions(context, taskOptions)
LLM推論APIのオプション詳細については、llmInferenceのAPIリファレンスを参照してください。
4. Taskを実行
任意のプロンプトを渡してTaskを実行します。
val result = llmInference.generateResponse(inputPrompt)
レスポンスをストリーミングすることも可能です。
llmInference.generateResponseAsync(inputPrompt)
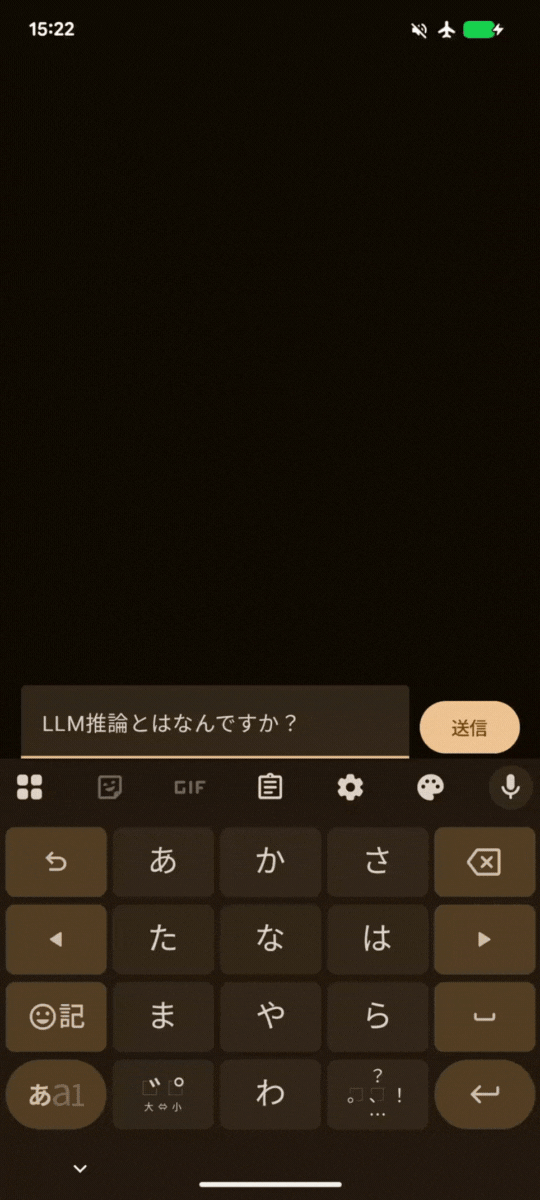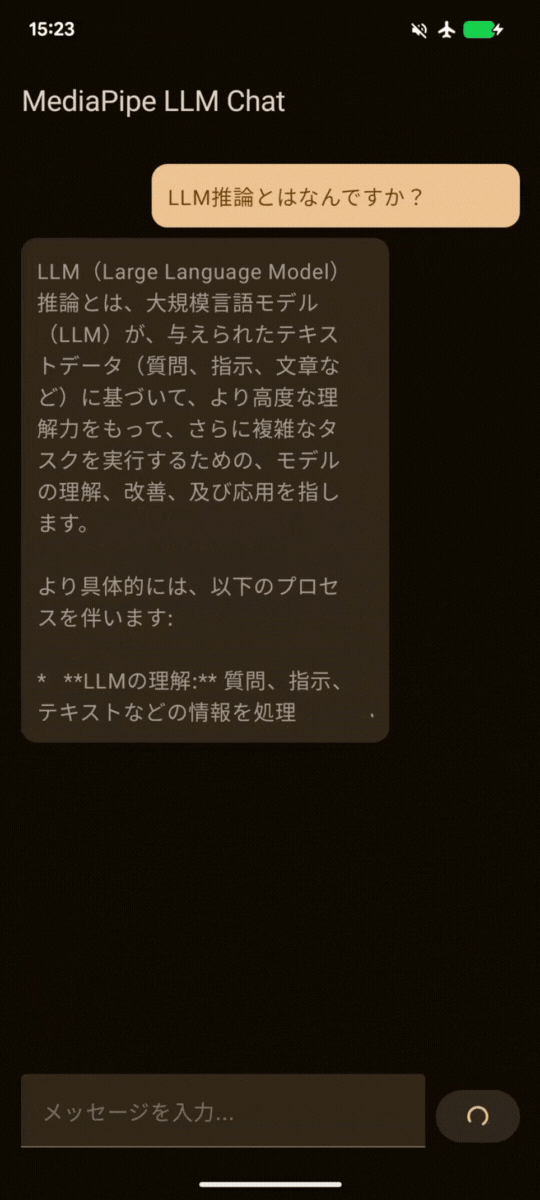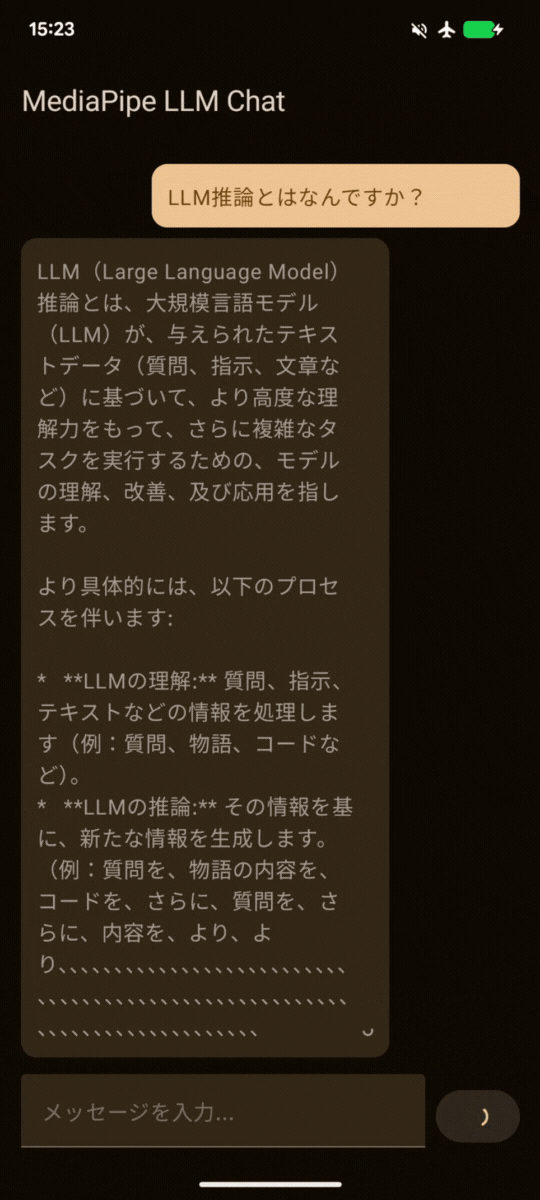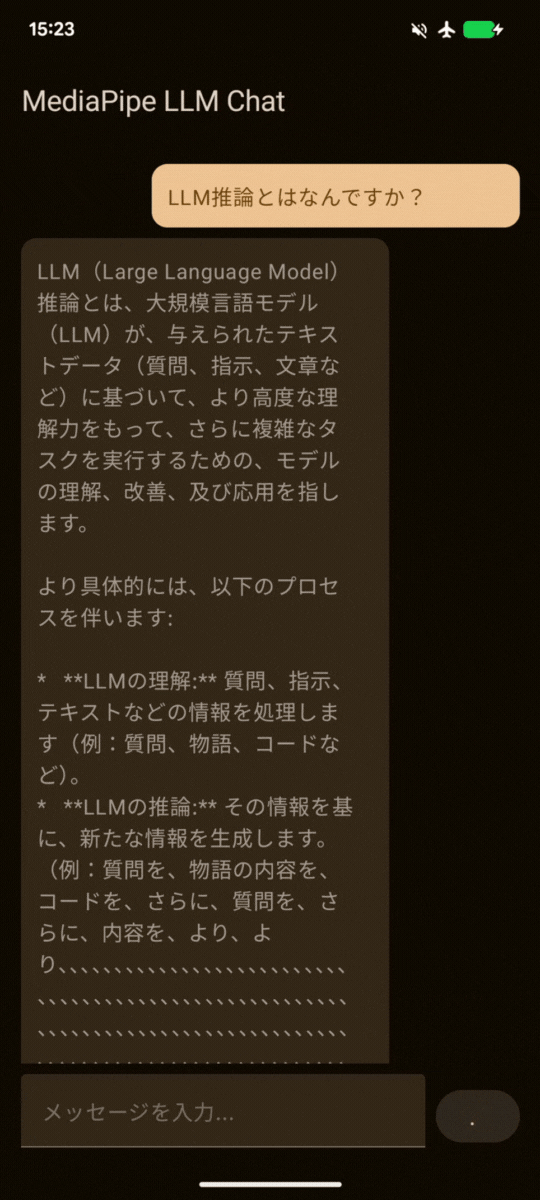
| gemma3-1b-it-int4.task | gemma-3n-E2B-it-int4.litertlm |
|---|---|
 |
 |
質問に合った回答がちゃんと返ってきました!🎉🎉
gemma3-1b-it-int4の方は序盤いい走り出しでしたが、途中から暴走してしまっていますね、、
この辺りはオプションを調整することで改善するのでしょうか🤔(もう少し試してみます)
どちらも機内モードで実行しているので、オフラインでの動作については確認ができました。
まとめ
ちゃんと実用するには適切なLLMや推論エンジンの選定、オプション最適化など色々とやることはあると思いますが、とりあえず動かしてみるだけであればすぐに使えてしまって驚きでした。
プライバシー保護や高速レスポンスなどオンデバイスLLMの特徴は、プロダクトによってはかなり活きてくる技術だと感じました。
来月には状況が変わっている進展の早い分野だと思うので、継続的に情報収集がんばります!
(Zenn初投稿でした!これからよろしくお願いします!)

Discussion