dinii は、飲食店での注文・会計といったミッションクリティカルな業務を行うためのプロダクトを開発・運用しています。こうしたプロダクトで障害が発生してしまうと、飲食店が営業できなくなってしまうほどのインパクトがあるため、プロダクトの信頼性・可用性・保守性を高めるための活動を積極的に行なっています。
そういった活動の中心になっているのが、「インシデント対応」です。dinii が行っているインシデント対応を整理すると、「インシデント発生前」「インシデント発生中」「インシデント発生後」のそれぞれのタイミングにおける運用を洗練するための取り組みを行なっており、大まかに記載すると以下のようになります。
- インシデント発生前: インシデントのリスクを検知・予防するためのアクション
- インシデント発生時: インシデントに迅速に対応するためのアクション
- インシデント発生後: インシデントを振り返り、今後の学びとするためのアクション
この記事では、これらの取り組みの詳細について紹介します。
インシデントのリスクを検知・予防するためのアクション
dinii では、定期的にエンジニアメンバーが集まって各種メトリクスを確認する「パフォーマンスレビュー」という場を設けています。全プロダクトのリリースサイクルが週1回のため、パフォーマンスレビューのサイクルも週1回としており、「リリースによってメトリクスが悪化した箇所、エラーが増えた箇所がないか?」「現在の利用ペースから利用量が増加しても問題ないか?」といった視点で各種メトリクスを確認しています。
一部ではありますが、どのようなメトリクスをどのような観点で確認しているかという点について紹介します。
- HTTPリクエスト: APIサーバ (GraphQLと、一部RESTのエンドポイントも持っています) と、Server Side Rendering を行っているサーバに対するHTTPリクスエストのメトリクスを計測しています。
- エラー数、エラー率: 異常に増えていないか?継続的に増えていないか?
- レイテンシ: 異常に増えていないか?継続的に増えていないか?
- サーバ: Cloud Run を利用しており、CPU使用率や同時接続数に応じて自動的にスケーリングするようになっています。
- メモリ使用率: 100%に近づいているインスタンスはないか?
- 最大同時接続数: 設定上限に長時間達している状態になっていないか?
- インスタンス数: スケール上限に達していないか?
- バッチ処理、非同期処理: Cloud Scheduler, Cloud PubSub, Cloud Tasks を利用し、バッチ処理や非同期処理を実行しています。
- エラー率、エラー数: 異常に増えていないか?継続的に増えていないか?
- エラートラッキング: Sentry を利用しており、Web, iOS, Android の各種プロダクトとバックエンド上で発生した例外情報を収集しています
- 新しく発生したエラーはないか?急増したエラーはないか?
- DB: AlloyDB を利用しており、インスタンスの増減は必要に応じて行っています。また、GCPには Query Insights という機能があり、クエリごとの負荷についても確認できます (さらに最近は Gemini in Databases により、インデックス追加などパフォーマンス改善のヒントも提供されるようになりました)
- DBのCPU使用率: 特にピークタイムにおいて、最大CPU使用率が100%に長時間張り付いていないか?50パーセンタイルのCPU使用率が80%を超えていないか?
- DBの接続数: 異常に増えていないか?
- DBのレイテンシ, ロックタイム: 異常に増えていないか?継続的に増えていないか?
- DBのQuery Insight: 負荷の高いクエリはないか?
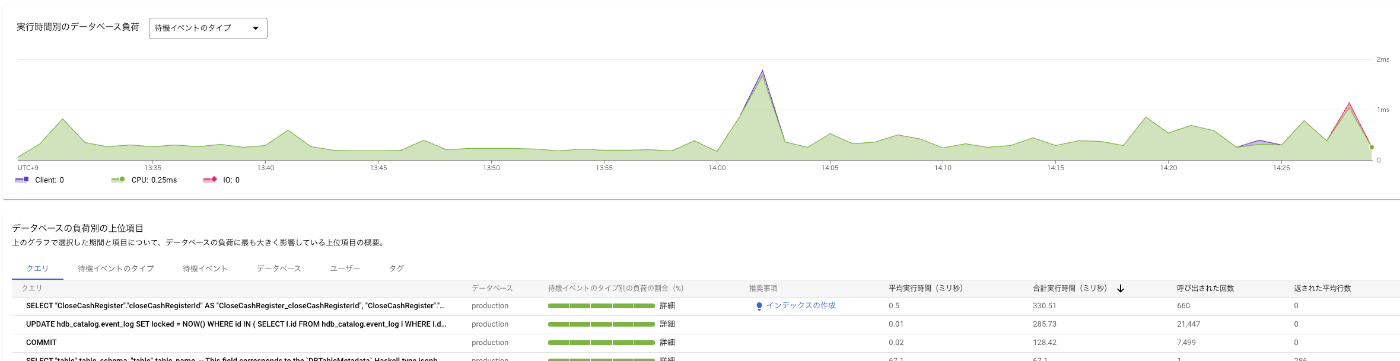
DBのQuery Insightの例
上記のような点を確認したのち、調査が必要と考えられる部分については担当者をアサインし、調査・対応結果を次の回のパフォーマンスモニタリングの場で確認しています。
最近では、システムのリスク情報やその対応過程を “System Risk Records” と読んでいるドキュメントにまとめるという取り組みを新たに始めました。上記の通り、パフォーマンスモニタリングで検知したリスクは担当者をアサインして対応しているのですが、
- 暫定対策のみ行ったが、プロダクトの利用者がさらに増えていくと再度問題が顕在化するリスクがあり、より長期的なスパンで恒久対応の実施が必要なものを管理したい
- 「これは以前対応したかも?」のような問題に対して、以前対応した担当者がいれば以前の対応内容と照らし合わせることができるが、他のメンバーでは難しい
- 特定の問題について、どういった問題に対してどう対処してどう改善されたか、といった情報がまとめることで、対応による学びを担当者だけでなく他のメンバーに波及したい
といった点があり、リスクの認知 ⇒ 原因特定 ⇒ 対策内容 ⇒ 対策の結果 といった対応の流れや、リスクの潜在的なインパクト・対応ステータスを一元管理するために作成したものです。こちらの取り組みの詳細については、また別の機会に紹介したいと思います。

System Risk Records (サンプル)
インシデントに迅速に対応するためのアクション
dinii では、開発チームがインシデント対応などの運用業務も行うという DevOps のプラクティスを用いて、インシデント対応の学びを開発に活かすフィードバックサイクルを作っています。インシデント対応のため、開発メンバー内でオンコールのローテーションサイクルを持っており、1日ごとにオンコール担当者を切り替えます。
オンコールの管理や担当者への通知は Spike.sh というサービスを利用しており、システム上のアラートが発生すると、オンコール担当者が登録した電話番号に通知が入るようになっています。また、オンコール担当者はシステム上のアラートだけでなく、社内から開発チームへの問い合わせやバグ報告の調査も担当します。

モニタリングツールとしては Google Cloud Monitoring を利用しており、Cloud Monitoring 上で設定したアラートの条件に合致すると、アラートがトリガーされます。アラートを作成する際は、必ず対応マニュアルも一緒に作成しており、オンコール対応に入る開発メンバーの認知負荷を軽減しています。

また、緊急性の高い障害が発生したと思われる場合は、全社内で速やかな情報共有を行うために重大インシデントの発令を行います。重大インシデントの発令はSlackのワークフローによって行われ、開発チームだけでなく全社的な通知が行われます。
重大インシデントの発生時は、インシデントの原因解決だけでなく、開発チームからビジネスチームに影響範囲や対応状況を適切に伝えること、ビジネスチームからお客様にプロダクトへの影響や社内の対応状況を適切に伝えることなども重要になります。dinii では緊急事態訓練を定期的に行い、重大インシデント発生時の対応の磨き込みを行なっています。緊急事態訓練の詳細については https://zenn.dev/dinii/articles/619c1484b1416c を参照ください。
インシデントを振り返り、学びとするためのアクション
発生したインシデントやバグについては、定期的にポストモーテムという場を開催し、対応状況を確認するとともに恒久対応や再発防止策について話し合う時間をつくっています。
こうした対策は、少し視点を広く持って「他でも発生しないか?」を考えることが重要です。例えば、
- 特定の店舗でデータの不整合が原因でバグが発生した場合に、他の店舗でもデータの不整合がないかを確認する
- 特定の実装、例えば論理削除の実装に関連するバグが発生した場合、他のテーブルに対する論理削除の実装においても同様の問題がないかを確認する
といったアクションを取れると良いでしょう。こうした確認についてはオンコール担当者の一次対応の際に確認できることがベストではあるものの、定型対応としきれないパターンも多く判断に際しては一定の経験が必要であり、ポストモーテムがダブルチェックの場になっているとともに、知識や経験の伝承の場にもなっていると言えます。

ポストモーテムの際に参照するインシデントレポート一覧
再発防止策は、インシデントやバグがなぜ発生したのか / 事前に抑止・検知できなかったかを考え、同じ問題がもう一度発生しない仕組みを入れられないか検討します。
開発・運用プロセスにおいて、インシデントやバグを事前に検知したり、抑止できるステップは複数あります。ポストモーテムの場にはPMやQAチームのメンバーも参加しており、多面的な角度で再発防止策を考えることができます。

- 設計フェーズ
- 設計レビュー: 新規機能の仕様作成時や、技術仕様作成時はレビューを行なっており、仕様上発生しうるインシデント、バグであればここで検知することができます。
- 実装フェーズ
- 型チェック、静的解析: TypeScriptの型チェックやLintルールのチェックにより、入力値の型の考慮漏れなど、実装上のミスにつながりがちな部分を検知・修正することができます。
- Unit Test: Pull Request のコミットごとにUnit Testを実行しており、テストケースに記載したパターンの動作確認を行うことができます。
- Pull Request のレビュー: 実装時の考慮漏れや不適切なエラーハンドリングなど、問題として認識していなければテストで検知できないような類のバグでも、実装者以外の視点で検知することができます。
- テストフェーズ
- ステージング環境でのUIテスト: リリース前にステージング環境を用いて変更箇所のテストや受け入れテストを手動で実施しています。エンドユーザーの視点で、機能的なバグ以外にもパフォーマンスやユーザビリティの問題など、幅広い範囲の問題をカバーすることができます。
- お触り会: スクラム開発プロセスにおけるスプリントレビューに相当するもので、ステージング環境へのリリースが終わったタイミングで、PM、デザイナー、ビジネスチームのメンバーなどに機能を触ってもらい、フィードバックを受けます。ビジネスチームは飲食業界出身のメンバーも多く、よりお客様に近い視点で利用上の問題を検知することができます。
- リリースフェーズ
- リリース時テスト: リリース時に主要機能と変更箇所に対する必要最小限のテストを実施します。
- モニタリング: 前述したパフォーマンスレビューのほか、何かしら手動対応が必要なエラーが発生した場合に、そのエラーをアラートとして通知することで問題が顕在化する前に抑えるような対応フローを組んでいるケースもあります。また、機能を段階的に開放するCanary Releaseのような仕組みも導入しており、致命的な問題があってもすべてのユーザーに影響する前に検知することができます。
インシデントやバグは、上記のステップのすべてをすり抜けてしまったことで発生します。インシデント・バグの原因によって、どのステップで検知すべきだったかを考慮し、同様のインシデント・バグが発生しないように改善することが再発防止策のプロセスとなります。ただ、以下のようなパターンには注意が必要です。
- UIテストに頼りすぎる: ほとんどのバグはUIテストで検知できます。一方で、手動でのUIテストは実行コストが高くなるため、対処のためにUIテストをどんどん増やしてしまうと、テストの実行時間がどんどん増えてしまいます。Unit Testや静的解析など、実行コストが低い手段で代替できないか考慮しましょう。
- 設計レビュー、Pull Request レビュー、お触り会を再発防止策に組み込む: これらのステップは基本的に属人性のある検知方法であり、チェックリストを用意するなど、何かしら運用フローを変更した上で再発防止策としての意味を持ちます。また、いずれにせよ再発防止策としては弱い対策になるため、他の手段を使えないか検討できると良いでしょう。
- 何にでも再発防止策を作る: 再発防止策を組み込むことは、一定のコストを払って再発を防止するというトレードオフを取っているという意味になります。コストを払って防ぐべき事象であるかどうかは、インシデントのインパクトに応じて考慮したいです。
また、影響範囲の大きいインシデントについては、MTTA (Mean Time To Acknowledge, アラートが発生してから認知するまでの時間) や、MTTR (Mean Time To Resolve, アラートが収束するまでの時間) の改善も重要なアクションになります。問題が発生し、オンコール担当が問題を認知し、一次対応を実施して問題が収束するまでの流れを振り返り、MTTAやMTTRの改善ポイントがないかを振り返ります。時には対応者個人の知識不足やミスによってMTTA, MTTRが上がったと考えられる場合もあるかもしれませんが、それを個人の反省点として受け止めるだけでは組織的な改善は見込めません。いかに組織的に・仕組みとして改善するかを考慮し、オンコール対応のマニュアル修正や自動化といった対策がとれると良いでしょう。
SRE募集中です!
dinii では、これまで紹介してきたようなインシデントの抑止・対応・学びのプロセスを通じて、プロダクトの信頼性向上に向けた対応を日々行っています。
ある程度形になってきたものの、まだまだ改善の余地のある領域は多くあります。思いつくだけでも、以下のような点は今後改善していきたいと考えています。
- 可観測性の向上。クライアントアプリ上で発生しているパフォーマンス上の問題の検知や、Sentry, Cloud Logging, Cloud Trace など複数のモニタリングサービスをまたがったTracingなど
- マルチプロダクト展開において、それぞれのプロダクトチームが独立して運用を回しつつも、他のチームに学びを共有する仕組み
- ユーザーサポートチームと連携し、不具合の原因をサポートチーム側で判別できるような社内ツールを提供したりすることで、お客様からの問い合わせ対応をより効率化する
- より柔軟なロールアウト、ロールバックプロセスの整備
- 大規模インシデント発生時における縮退運転機能の提供・拡張
こうした課題を解決していくため、Site Reliability Engineer を募集しています!
dinii のプロダクトは飲食店のインフラとなることを目指しているため、信頼性の向上はプロダクトの競争力向上に直結します。また、開発チームと運用チームのような垣根もないため、プロダクト組織内のあらゆるプロセスを通じて信頼性向上のための取り組みを実施できます。技術的にも組織的にも面白いチャレンジができるタイミングかと思いますので、興味がある方はぜひカジュアル面談でお話ししましょう!

Discussion