こちらの記事は note にも公開しています。
こんにちは!株式会社 ダイニーdinii (ダイニー) / Data team テックリードの kimujun です。
ダイニーのモバイルオーダーは多言語対応機能を提供しています。モバイルオーダーのヘッダーから言語を切り替えると、メニュー名やボタンのラベル等がすべて多言語対応された表示に切り替わります。
現在対応しているのは英語、中国語(簡体)、韓国語の 3 言語です。
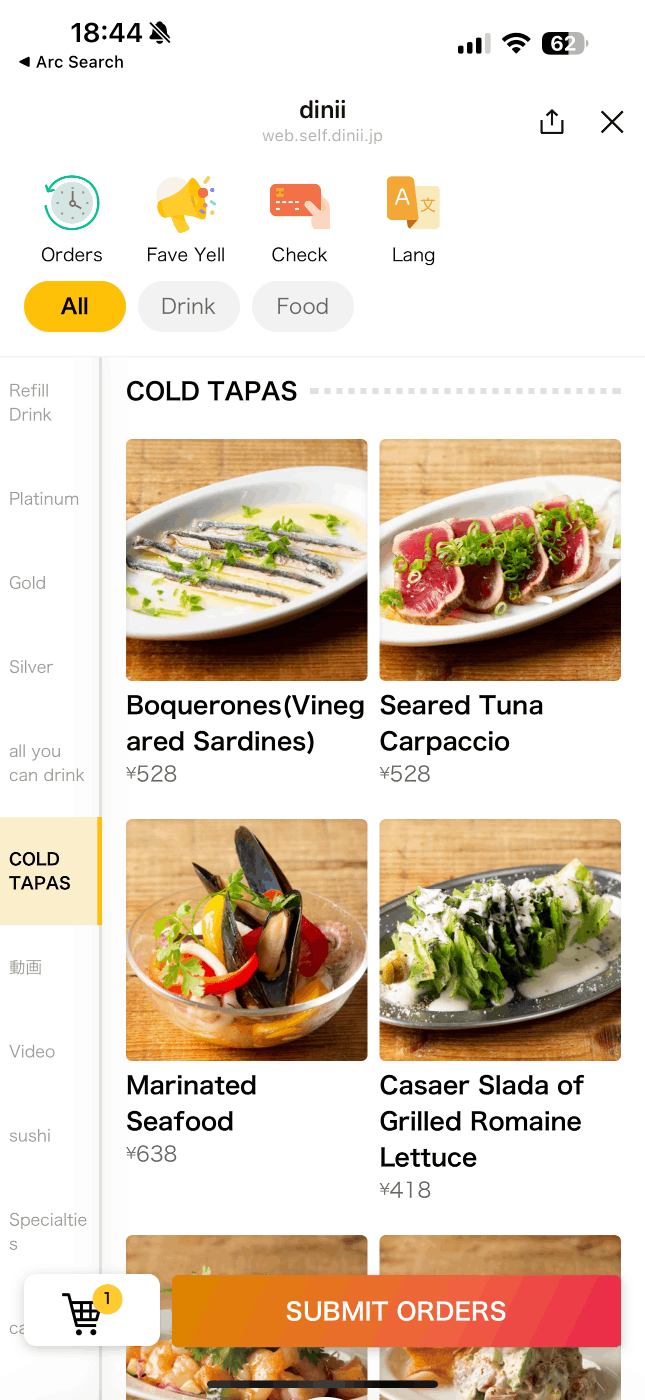
言語を英語に切り替えた際のモバイルオーダーの画面
この記事では主に多言語化されたマスターデータをどのように用意しているのか、またそれらの品質担保の取り組みについて紹介しようと思います。
※マスターデータ = メニューやカテゴリなどのモバイルオーダー上で表示されるデータ
なお、この記事ではクライアントにおける多言語対応の実装は紹介しません。
マスターデータの多言語化
ダイニーでは管理画面からマスターデータを登録し、表示を有効にするとモバイルオーダー上に表示され注文可能になります。マスターデータは一括で登録することも可能なので、1 日で 1 店舗あたり数 100~1000 件のマスターデータが登録されることもあります。

管理画面上の翻訳データの例
マスターデータ登録時に事前に用意した翻訳データを同時に登録することも可能ですが、全言語ですべてのマスターデータの翻訳データを用意するのはコストがかかります。
気軽に多言語対応機能をお使いいただくため、ダイニーでは自動翻訳機能を提供しています。
自動翻訳機能を ON にし、マスターデータを登録するとバッチ処理によって翻訳データが自動で登録されます。
ダイニーでは DeepL API を用いて 1 日に一度バッチ処理を行っています。
日々かなりの量のマスターデータ登録があるため、平均して 1 日に 2000~3000 万文字程度を DeepL API によって翻訳しています。
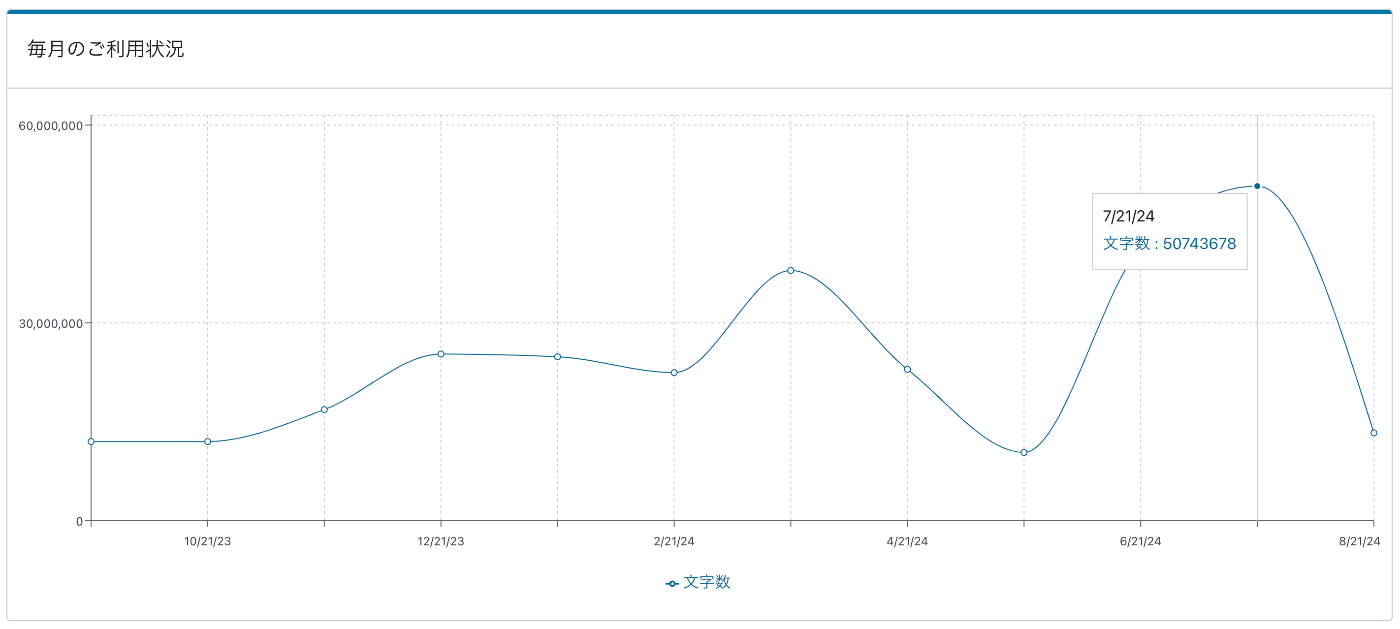
DeepL のコンソールより。多いタイミングでは 5000 万文字にまでなることがある
課題とその対策
このように自動翻訳機能を提供しているダイニーですが、運用開始後に以下のような課題が出てきました。
-
翻訳可能文字数の上限に到達して翻訳できなくなる問題
-
翻訳の精度が低く不適切な文言がデータベースに登録されてしまう問題
1. 翻訳可能文字数の上限に到達して翻訳できなくなる問題
DeepL API では上限課金額次第で翻訳可能な文字数の上限が変化します。
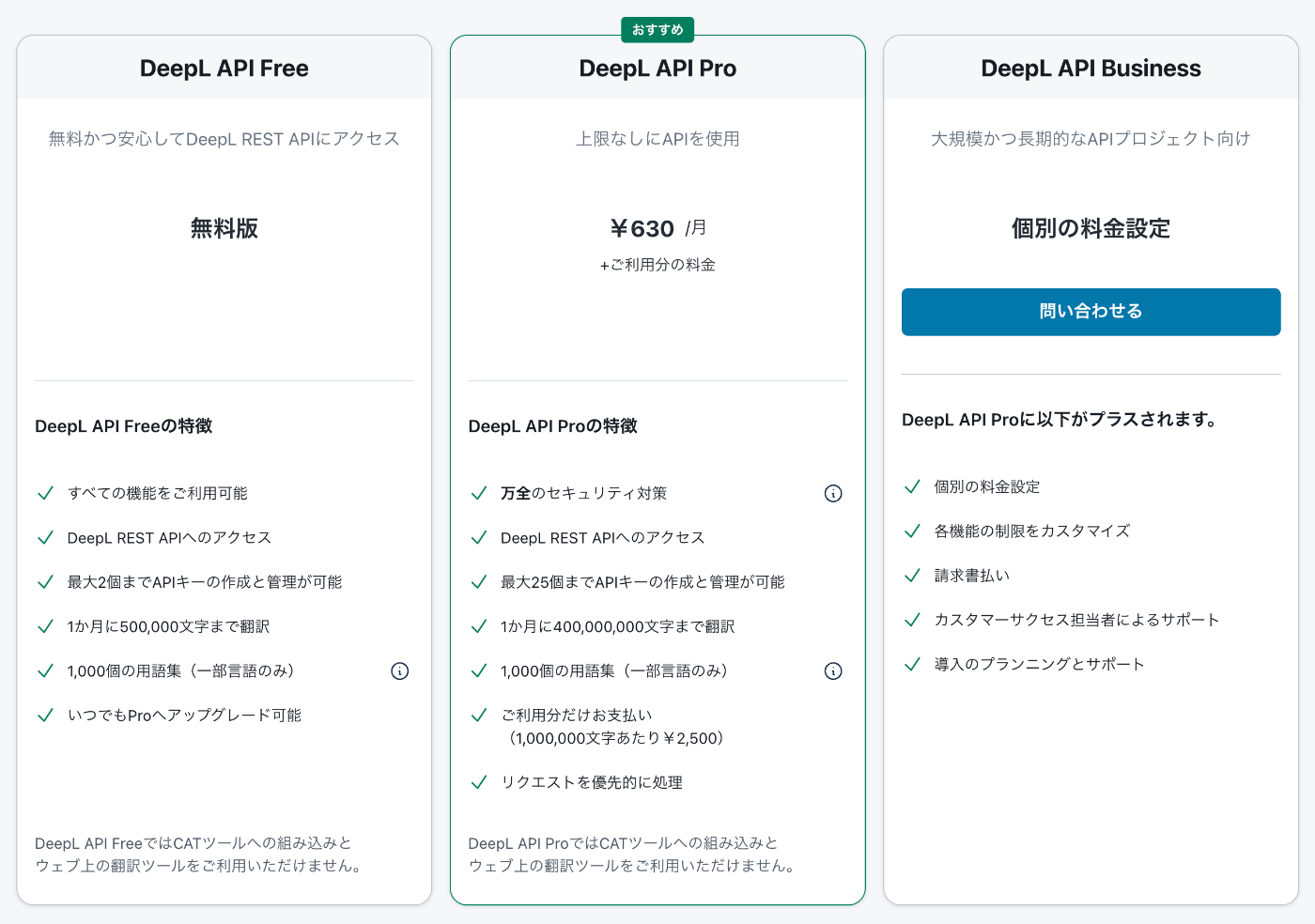
https://www.deepl.com/ja/pro-api
余計なお金を払いたくないので、ある程度のバッファは持たせつつ上限金額を現実的な範囲に設定することが多いと思います。
しかし、タイミングによっては翻訳文字数が予想以上に増加し上限文字数を突破してしまうことがあります。
上限文字数を突破すると DeepL API からエラーが返ります。
ダイニーではこれらの上限突破を事前に検知して手を打てるようにするため、quota を定期的に監視してアラートを上げるようにしています。
DeepL API では現在の使用量と quota を返す API が提供されており、そちらをもとに定期的な監視を実装しています。
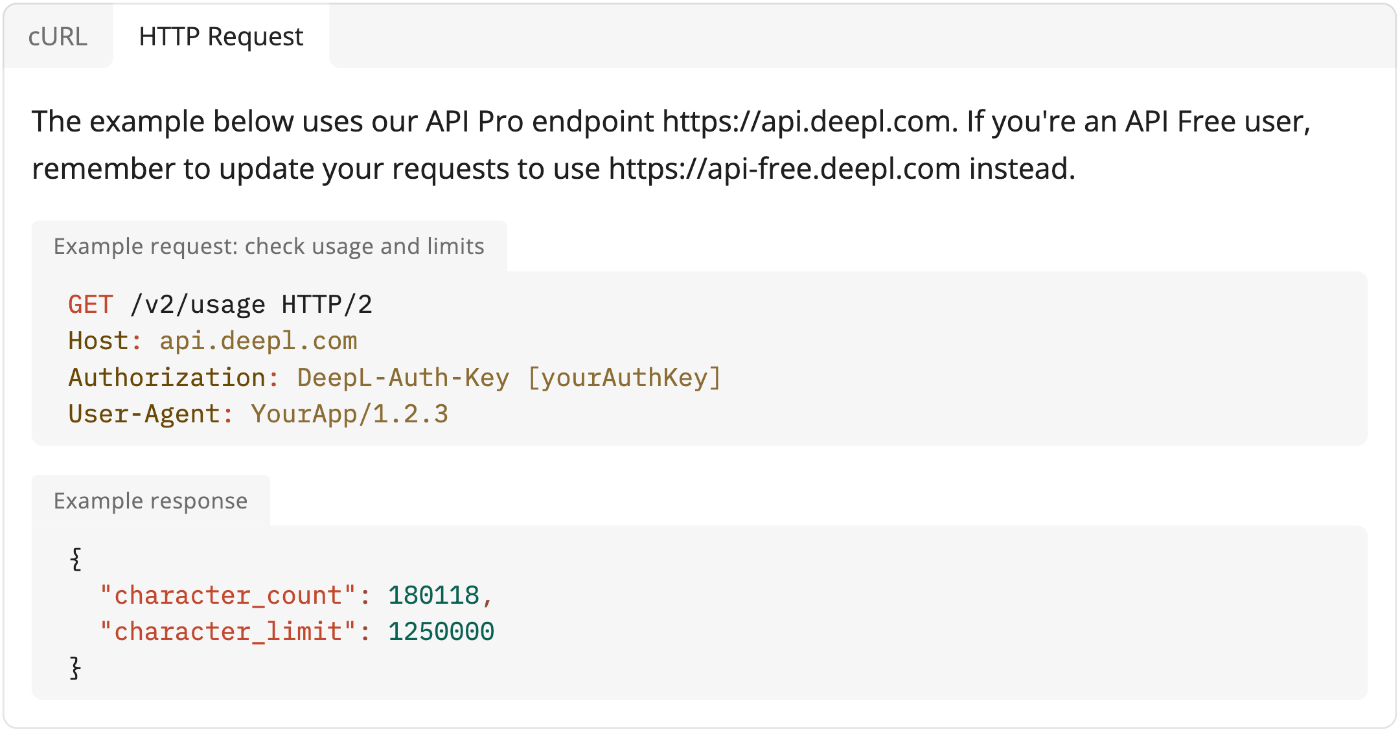
https://developers.deepl.com/docs/api-reference/usage-and-quota

文字数の不足を知らせるアラート。監視とアラートのワーフローは Retool で実装している
2. 翻訳の精度が低く不適切な文言がデータベースに登録されてしまう問題
DeepL API は比較的安価ですが、翻訳対象のデータによっては意味の通らない翻訳が返ってきたり、時にはクライアントに表示するには不適切な文言が返ってくることもあります。
不適切な文言をアプリケーションに表示することについてはコンプライアンス上の問題があるため、これらを検知して修正をする必要があります。
ダイニーではこのような不適切な文言を検出して修正対象とするため、Google Cloud の Natural Language API/moderateText メソッドを利用しています。
テキストの管理では、「有害なカテゴリ」や機密情報とみなされるトピックなど、安全性属性のリストに基づいてドキュメントが分析されます。ドキュメント内のテキストを管理するには、moderateText メソッドを呼び出します。
「暴力的なコンテンツ」「侮辱」「リーガル」など、様々な安全性属性ごとにテキストをスコア化し、信頼性を担保することができます。
以下は moderateText のレスポンス例です。
{
"moderationCategories": [
{
"name": "Toxic",
"confidence": 0.10
},
{
"name": "Insult",
"confidence": 0.12
},
{
"name": "Profanity",
"confidence": 0.07
},
{
"name": "Derogatory",
"confidence": 0.04
},
{
"name": "Sexual",
"confidence": 0.00
},
{
"name": "Death, Harm & Tragedy",
"confidence": 0.00
},
{
"name": "Violent",
"confidence": 0.00
},
{
"name": "Firearms & Weapons",
"confidence": 0.00
},
{
"name": "Public Safety",
"confidence": 0.01
},
{
"name": "Health",
"confidence": 0.01
},
{
"name": "Religion & Belief",
"confidence": 0.00
},
{
"name": "Illicit Drugs",
"confidence": 0.01
},
{
"name": "War & Conflict",
"confidence": 0.02
},
{
"name": "Politics",
"confidence": 0.01
},
{
"name": "Finance",
"confidence": 0.00
},
{
"name": "Legal",
"confidence": 0.00
}
]
}
1.00 に近ければ近いほど信頼性が低く、不適切である可能性が高い文字になります。
例えば Insult の項目が 0.5 を超えているとかなり暴力的な表現が含まれる、といった形で判断することができます。
ダイニーでは新規の翻訳データに対してこの moderateText API を呼び出し、不適切な文言がないかをチェックする取り組みをしています。
moderateText API はそれなりにレスポンスが遅いため、分析対象が多い場合はバックグラウンドで実行するなどの工夫が必要です。また、解析対象のデータ量によって課金される仕組みになるため、そちらにも注意が必要です。
なお、Natural Language API の一部のメソッドは BigQuery 上から直接呼び出せるのですが、moderateText メソッドは現在対応しておらず、REST API を呼び出す形で実装しています (Google Cloud さん、期待しています…!)。
これで基本的な不適切文言は検知できますが、ダイニーの場合は飲食店のマスターデータということもあり、さらに工夫が必要だと考えています。
例えば…「鬼殺し」というお酒を翻訳した場合、それが危険であるかどうかは判断が難しそうですよね?
これらの工夫については、まとまったアウトプットが出た段階でまた紹介したいと思います。
まとめ & We’re Hiring!
今回はダイニーのモバイルオーダーが実装している多言語対応の裏側について紹介しました。ダイニーではなるべく多くの来店客の方々にモバイルオーダーを楽しんでいただくべく、UI/UX の磨き込みにも力をいれているので、お店で見かけた際は色々と触ってみていただけると嬉しいです (X での感想もお待ちしております!)。
ダイニーではモバイルオーダーの UI/UX にこだわってプロダクト開発するメンバーを募集しています!興味ある方は上記の採用ページからカジュアルに面談を申し込んでみてください。
事前にダイニーのカルチャーを知りたい方はこちらも↓

Discussion