はじめに
こんにちは、ダイニーのData Teamでエンジニアをしているmasaです。
ダイニーでは飲食店向けデータ分析プロダクトを開発しています。このプロダクトは、飲食店経営に必須である日々の売上といったデータからアンケート分析のような発展的なデータまで提供しています。
それらのデータをプロダクトとして提供するための手段として、以前はRDB(PostgreSQL)のデータをバックエンドから直接参照して集計していましたが、パフォーマンスの悪化等を理由にBigQueryに集計済みのデータを用意して参照する形式に変更しました。
その変更によりパフォーマンスは大幅に改善しましたが、コスト観点ではいくつかの問題が生じていました。
前提として、BigQueryのデータを参照するようになったため課金形態としてはBigQueryのオンデマンド コンピューティング料金[1]に従う形になります。
その上で具体の課題としては以下のような点がありました。
- プロダクトで利用するデータがBigQueryに保管されたことによってエンジニア問わず多くのメンバーがあまり制限なく自由にクエリを実行できるようになった(特にLooker Studioやスプレッドシートなどから参照すると実行頻度によってはコスト増につながる)
- データストアがRDBからBigQueryになったことでモニタリングの体制が甘くなっていた
その中でも本記事では以下の点について話します。
- 大量のコストを消費していたクエリのデータ生成方法を改良したことでBigQueryのコンピューティング料金を大幅に節約したこと
- 上記の課題解決を通してBigQueryのモニタリング体制を強化したこと
コスト面で発生していた課題
まずコスト面で起きていた事象として、月額換算で40万円強(40TiB)のバイトを消費している非常に負荷の大きいクエリがありました。
当時モニタリングの体制として1日の合計バイト消費量の上限についてアラートを設定し監視している状態でしたが、クエリやサービス単位での消費量は見ておらず事前の検知ができていませんでした。
たまたま他の要因でBigQueryの消費バイト量が多い日があり調査をしていた際、全体の10%弱を消費している非常に負荷の高いクエリがあることを発見しました。
以下サービス別のバイト消費量ですが、該当のクエリ単体でbackendの他全クエリの合計消費量を上回っているような状態です。
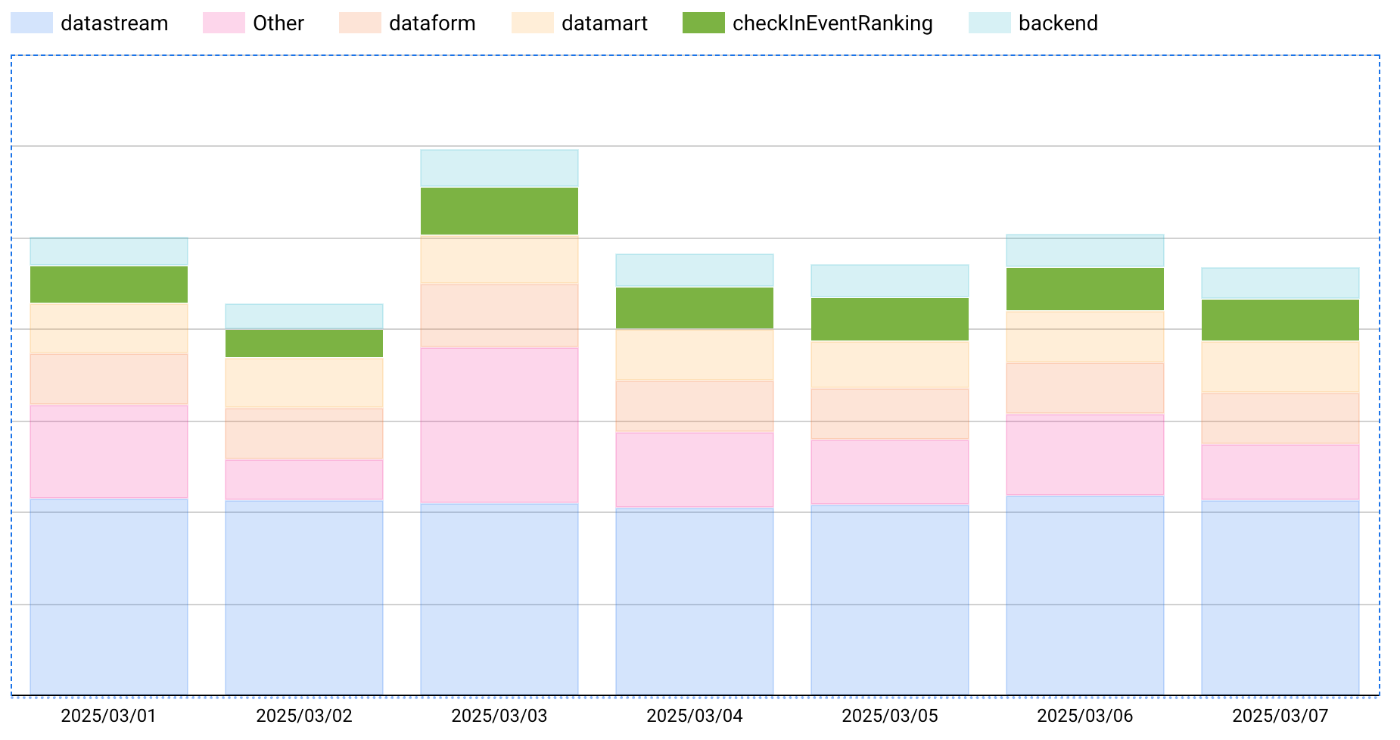
2025年3月1日~3月7日のサービス別 BigQuery消費バイト量
そして問題のクエリはプロダクトのダッシュボード画面のトップページに表示している「リピート数ランキング」[2] というデータを可視化するために使われているものでした。

このクエリは以下の点で非常に負荷の大きいものになっていました。
- ダイニー導入以降の全ユーザーの全来店記録を元に累積の来店回数を集計しており、データ量が大きくクエリ1回あたりのバイト消費量が大きい
- 顧客がアクセスするダッシュボードのトップページに利用されていることから1日に数千~数万単位でのアクセスがありその都度BigQueryにクエリを実行している状態
改善によるインパクト
この事象への対応として、累積の来店回数を集計するロジックをバックエンドからデータ基盤に移行してBigQueryには集計済みのデータを持たせる形にしました。
具体的に、ダイニーではデータ基盤のパイプラインにDataform CLIを採用[3]しており、集計のロジックをDataform上にデータマートとして持たせる形にしました。
そしてバックエンドからは集計済みのデータを参照するだけの形式に変更しました。
結果として、バックエンドでは1日に数千~数万回クエリが実行されるのに対しDataformでは1日に数回程度の実行であるため、累積来店回数を集計するロジックの実行回数を数千分の1程度に減らすことができました。
これはプロダクトで提供しているリピート数ランキングに求められる鮮度がリアルタイムではなく前営業日までのデータで良いためそもそも高頻度な集計が不要という背景があります。
合わせて、集計済みのデータをBigQueryに持たせたことでバックエンドからBigQueryに実行するクエリのバイト消費量が一回あたり1/100 ~ 1/1000程度と非常に小さくなりました。
以下は該当クエリのバイト消費量の推移ですが、元々 10~15TiB/日 で消費していたものが変更後は 0.1TiB/日 以下になっておりバイト消費量を1/100以下に減らすことができました。これは月に換算すると約400Tib、日本円で約40万円/月の節約ができたことになります。

2025年4月1日~4月13日の該当クエリの BigQuery消費バイト量
このように、高い鮮度が求められないデータにおいて集計ロジックをデータマート化することはコスト観点で非常にインパクトの大きい対応となります。
モニタリング体制の強化
今回の事象を踏まえて、データプラットフォームのモニタリング体制を強化すべく以下3点に取りくみました。
-
バックエンドからのクエリ実行時に詳細なログを出力
- BigQueryへのクエリ実行にはNode.js クライアントライブラリ を利用していますが、クエリを呼び出したメソッドの名前などをlabelに追加することでどのバックエンドの処理がどのクエリを呼び出しているかを特定しやすくなりました。
-
詳細な分類でモニタリング可能な社内用ダッシュボードを構築
- 上記の対応によって詳細なログが取得できるようになり、backendのメソッドやクエリ単位など細かい分類で可視化できるようになりました。
- ダッシュボードの詳細な設計等は別記事などでご紹介できればと思います。

-
パフォーマンスレビューの実施
- データプラットフォームとして定めたKPIを見ながら問題の洗い出しやアクションを検討する会を毎週実施することに決めました。
- 例えばプロダクトから参照しているクエリでLatencyが悪化しているものはないか、Looker Studioなど社内分析用途で必要以上にコストがかかっているクエリはないか等をチェックし、問題があれば改善チケットを作成します。
- 初回の実施で必要以上にコストがかかっているLooker Studioのクエリを発見することができ、早速会の意義を感じています。
今後やりたいこと
ここまではモニタリング体制の強化がメインでしたが、今後は直接的に消費量を減らすための試みとしてBigQuery BI Engineの導入を検討しています。BigQuery BI Engineは事前に指定したテーブルをキャッシュに保存してくれるサービスで、データの容量が小さくかつ大量に実行されるクエリと相性がいいです。
ダイニーでは今後もプロダクトで提供するデータの種類を拡充していく予定があるため、コストメリットがあるテーブルがあれば導入を検討していこうと考えています。
最後に
今回はデータエンジニアリングによるコストの大幅な削減とモニタリング体制を強化する実例を紹介いたしました。
ダイニーではデータ基盤をプロダクトと社内分析用途の両方で利用しているためデータエンジニアであってもプロダクトの価値向上に直接関われることが魅力だと感じています。
興味のある方はぜひ一度お話ししましょう!
-
Tokyo RegionのBigQueryコンピューティング料金は $7.5 per TiB ですので、2025年6月10日時点の為替状況(1ドル = 144.5円)においては1083円 / Tibということになります。
BigQuery オンデマンド コンピューティング料金 ↩︎ -
ダイニーでは同じ業態/店舗に複数回来店することを「リピート」と呼んでおり、ユーザーのリピート数ランキングを顧客に提供しています。飲食店にとって関心の強い指標の一つです。 ↩︎
-
ダイニーでは全てのプロダクトをTypeScriptで開発しており、Dataform CLIはTypeScriptで作られたOSSであるためダイニーの技術スタックと相性がいいことがメインの選定理由です。 ↩︎

Discussion