OpenSearch の Agentic Memory をちょっとだけDiveDeep
本記事は情報検索・検索技術 Advent Calendar 2025の14日目の記事です。
LLMを利用したエージェントがかなり普及してきましたが、いわゆる Context や知識を保持するためのメモリーに注目が集まっているかと思います。
個人的に Layer X の Nakamuraさんの記事の冒頭にあるように、サービスとしてエージェントを提供していく際にとくに重要になるような要素だと思っています。
メモリーの実装としてはベクトルベースが多く、最近はグラフベースのものが注目されているように思いますが、今回は OpenSearch を使ってメモリーの実装を簡単にしてくれる Agentic Memoryという機能の仕組みを見ていこうと思います。
機能自体の紹介以外にも、メモリーの実装例として参考になればと思います。
OpenSearch Agentic Memory とは
名前の通りですが、OpenSearch 上でエージェントのメモリーを構築するさいに利用できる機能になります。3.2 から登場した比較的新しい機能です。working memory, long-term memoryといったように用途別に複数のストアを用意して自動的にそれらに情報を保管していくような機能になります。
こちらのブログやその翻訳記事で大枠の説明がされているので、全体感を把握されたい場合はこれらを先にご参照ください。
Agentic Memory のコンポーネント
それでは、Agentic Memory に登場するコンポーネントについてみていこうと思います。

図のようなコンポーネントが Agentic Memory の機能に関連するものになりますが、Memory Container の内部の各種 index や pipeline は Memory Container に紐づいて自動で作成されるものになります。
1つずつ手順に登場する順番に紹介してみます。
最初にAgentic Memoryの機能をクラスタで有効化するのを忘れないようにしてください。
まず、Agentic Memoryの機能を有効化します。
# request
PUT _cluster/settings
{
"persistent": {
"plugins.ml_commons.agentic_memory_enabled": true
}
}
LLM Model と Embedding モデル
まずは図の左下の LLM モデルと Embedding モデルです。OpenSearch にはもともと ML モデルを登録しておいて各種機能から呼び出す仕組みがあります。
Agenti Memory で登録しておく必要があるモデルは、
- Embedding model
- LLM model
の2つです。
Embedding modelは名前の通りテキストのベクトル埋め込みに利用します。KNN のためのEmbedding modelを指定する以外にSPLADE などのようなSparse encodingのモデルを指定することも可能です。その場合は、"embedding_model_type": "SPARSE_ENCODING"のように指定します。
Embedding Model として登録されたモデルは Ingest Pipelineを通して利用され、後段のindexにEmbeddingされたベクトルが元のメッセージと一緒にindexingされます。
LLM モデルは、ユーザーとのやり取りの内容からユーザーの趣味や重要な部分を抽出したり情報の加工に使われます。以下のように LLMモデルから register します。
POST /_plugins/_ml/models/_register?deploy=true
{
"name": "Bedrock infer model",
"function_name": "remote",
"description": "LLM model for memory processing",
"connector": {
"name": "Amazon Bedrock Connector: LLM",
"description": "The connector to bedrock Claude Opus 4.5 model",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "us-west-2",
"service_name": "bedrock",
"max_tokens": 8000,
"temperature": 1,
"anthropic_version": "bedrock-2023-05-31",
"model": "global.anthropic.claude-opus-4-5-20251101-v1:0"
},
"credential": {
"roleArn": "arn:aws:iam::xxxxxx:role/opensearch-invoke-bedrock-role" //<- 適宜変更してください
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"headers": {
"content-type": "application/json"
},
"url": "https://bedrock-runtime.${parameters.region}.amazonaws.com/model/${parameters.model}/converse",
"request_body": "{ \"anthropic_version\": \"${parameters.anthropic_version}\", \"max_tokens\": ${parameters.max_tokens}, \"temperature\": ${parameters.temperature}, \"system\": [{\"text\": \"${parameters.system_prompt}\"}], \"messages\": [ { \"role\": \"user\", \"content\": [ {\"text\": \"${parameters.user_prompt}\" }] }]}"
}
]
}
}
ここで登録するLLMモデルは後ほど紹介する "Memory processing strategy" のパラメータによってことなるプロンプトをもとに処理を行います。
次に Embedding Moderlも登録します。
POST /_plugins/_ml/models/_register?deploy=true
{
"name": "Bedrock embedding model for Agentic Memory",
"function_name": "remote",
"description": "Embedding model for memory",
"connector": {
"name": "embedding",
"description": "The connector to bedrock Titan embedding model",
"version": 1,
"protocol": "aws_sigv4",
"parameters": {
"region": "ap-northeast-1",
"service_name": "bedrock",
"model": "amazon.titan-embed-text-v2:0",
"dimensions": 1024,
"normalize": true,
"embeddingTypes": [
"float"
]
},
"credential": {
"roleArn": "arn:aws:iam::xxxxxx:role/opensearch-invoke-bedrock-role"
},
"actions": [
{
"action_type": "predict",
"method": "POST",
"url": "https://bedrock-runtime.ap-northeast-1.amazonaws.com/model/amazon.titan-embed-text-v2:0/invoke",
"headers": {
"content-type": "application/json",
"x-amz-content-sha256": "required"
},
"request_body": "{ \"inputText\": \"${parameters.inputText}\", \"dimensions\": ${parameters.dimensions}, \"normalize\": ${parameters.normalize}, \"embeddingTypes\": ${parameters.embeddingTypes} }",
"pre_process_function": "connector.pre_process.bedrock.embedding",
"post_process_function": "connector.post_process.bedrock.embedding"
}
]
}
}
Memory Container
ここからが新しい Agentic Memory で利用されるコンポーネントになります。
Memory Container は名前の通りユーザーとエージェントのやり取りを保存しておく箱になります。この箱にデータを出し入れするときの設定を紐づけて定義しておくような使い方になります。
Memory Container には以下のパラメータが設定できます。
- Text embedding model: 上述のもの。やりとりを保管する時にベクトルエンベディングを実施するモデルを指定します。
- LLM: 上述のもの。やり取りの中から重要な内容やポイントをstrategiesにもとづいてとりだして保存する形に加工するのに利用します。
- Memory processing strategies: どのようにやり取りを保管していくかの戦略を設定します。後ほど説明します。
- Namespace: メモリー上に保管するデータをどんな単位でわけて保管しておくかを決めるための設定です。後ほど説明します。
Memory processing strategy
まず、Memory processing strategy についてみていきます。
翻訳ブログの表現をそのまま借りてしまいますが3つの戦略を指定することができます。
-
SEMANTIC: 将来の参照のために会話で言及された事実と知識を保存します。例: 「顧客はサーバーレス処理に AWS Lambda を使用し、開発には Node.js を好むと述べました。」
-
USER_PREFERENCE: ユーザーの設定、選択、コミュニケーションスタイルを保存します。例: 「ユーザーは高レベルの要約よりも詳細な技術的説明を好みます」または「ユーザーは SMS アラートよりもメール通知を好みます。」
-
SUMMARY: 会話の要約を作成し、セッションにスコープされた主要なポイントと決定を記録します。例: 「ユーザーは OpenSearch の価格について問い合わせ、クラスターサイジング要件について議論し、実装タイムラインを要求しました。」
この3つの戦略によって長期記憶(Long-term Memory)の保存の際のLLMへのプロンプトが異なり、それによってメモリーへ保存するデータの抽出の仕方が変わってきます。 逆に検索時の仕組みなどは現時点では特に変わりはありません。
今回は深くは説明しませんが、興味がある方はこのあたりをみていただけるとそれぞれどのようなプロンプトが利用されるか確認できます。
デフォルトの状態では、個人識別情報 (PII) を除くような処理も含まれています。逆に PII を入れ込みたい場合は注意が必要です。
Namespace
Namespace は比較的わかりやすい概念ですが、OpenSearchに渡されるメッセージ中の任意のキーをもとにメモリ自体を分けることができます。実態としては指定されたキーを indexing されるさいにfieldとして追加して、拾ってくる際にはそのフィールドの値で boolean query でフィルタリングされて取得されるといった仕組みになります。Namespaceの設定は Strategy 設定ごとに行う形になります。
...
"strategies": [
{
"enabled": true,
"type": "USER_PREFERENC",
"namespace": ["user_id"]
},
{
"enabled": true,
"type": "SUMMARY",
"namespace": ["user_id", "session_id"]
}
],
...
(マルチテナントなユースケースでの簡易なテナント分離でも使うことができますが、よりセキュアにするためにOpenSearch の Security Plugin による制御などを適切に設定していただくことをお勧めします。)
メモリータイプ
Memory Container には4つのメモリータイプがあります。これもOpenSearch Blog からそのまま借りてしましますが、
- session: 会話セッションとそのメタデータを管理します。各セッションは、開始時間、参加者、セッション状態などのセッション固有の情報を含む、ユーザーとエージェント間の個別のインタラクションコンテキストを表します。
- working: エージェントが進行中のインタラクション中に使用するアクティブな会話データと構造化情報を保存します。これには、最近のメッセージ、現在のコンテキスト、エージェント状態、実行トレース、即時処理に必要な一時データが含まれます。
- long-term: 時間の経過とともにワーキングメモリから抽出された処理済みの知識と事実を含みます。推論が有効な場合、LLM はワーキングメモリの内容を分析して重要な洞察、ユーザー設定、重要な情報を抽出し、セッションを超えて存続する永続的な知識として保存します。
- history: メモリコンテナ全体のすべてのメモリ操作 (追加、更新、削除) の監査証跡を維持し、メモリがどのように進化したかの包括的なログを提供します。
Memory Container の実態は OpenSearch の index の集合とそこにデータをいれこむ際の ingest pipeline の設定です。Agentic Memory API はこのMemory Container をベースにエージェントからコンテキストを保存する仕組みを提供するといった機能になります。
Memory Containerを作成するとOpenSearchにいくつかの index とそこに紐づくpipeline が作成されます。
作成される index とそれぞれの名前は以下の4つです。
- Memory Container Metadata Index(System Index): ".plugins-ml-am-memory-container"
- Session Index: ".plugins-ml-am-{index_prefix}_session"
- Working Memory Index (Short-term Memory) : ".plugins-ml-am-{index_prefix}_working"
- Long-term Memory Index : ".plugins-ml-am-{index_prefix}_long_term"
- Long-term Memory History Index: ".plugins-ml-am-{index_prefix}_long_term_history"
先ほどメモリータイプが 4 つあると言いましたが、その 4 つとメモリコンテナ全体のメタデータ用の index の合計 5 つが作成できます。Metadata Index はクラスタに1つつくられてそれぞれの Memory Container のメタデータを保持するような使われ方になり、ユーザーが触れることはほぼないかと思います。(ちなみに、一部は作成させないことも可能です)
それぞれの index のシャード数をはじめとして index の設定を指定したうえで Memory Container を作成することができます。以下のような感じです。
POST /_plugins/_ml/memory_containers/_create
{
"name": "Agentic chatbot memory container",
"description": "my memory container",
"configuration": {
"index_prefix": "agentic-chat-semantic",
"embedding_model_type": "TEXT_EMBEDDING",
"embedding_model_id": "embedding_model_id",
"embedding_dimension": 1024,
"llm_id": "llm_id",
"use_system_index": false,
"disable_session": false,
"strategies": [
{
"enabled": true,
"type": "SEMANTIC",
"namespace": [
"user_id"
]
}
],
"index_settings": {
"session_index": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-all"
}
},
"working_memory_index": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-all"
}
},
"long_term_memory_index": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-all"
}
},
"long_term_memory_history_index": {
"index": {
"number_of_shards": "1",
"auto_expand_replicas": "0-all"
}
}
}
}
}
さて実際に Memory Container を作るとどのようなコンポーネントが作成されているか確認してみます。
GET _cat/indices/agentic-chat-semantic*?v
# response
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open agentic-chat-semantic-memory-long-term VuZ3MzNfSQKmdWfaamwgrQ 1 4 0 0 64.1kb 12.8kb
green open agentic-chat-semantic-memory-sessions wY4i_rgTRMyXl61DqNx4EQ 1 4 0 0 1kb 208b
green open agentic-chat-semantic-memory-working xoIwlBitQd61hRkv42_60w 1 4 0 0 62.9kb 12.5kb
green open agentic-chat-semantic-memory-history 0nGP0oxMSomqGI3s-r1ocQ 1 4 0 0 43.5kb 8.7kb
上述した4つのメモリータイプの index が作成されていることが確認できました。メタデータ管理用の index 以外にはまだ doc は登録されていません。
ingest pipeline も同様に確認してみます。
GET _ingest/pipeline/agentic-chat-semanti*
# response
{
"agentic-chat-semantic-memory-long-term-embedding": {
"description": "Agentic Memory Text embedding pipeline",
"processors": [
{
"text_embedding": {
"model_id": "66ygCJsBJXvullgAogHJ",
"field_map": {
"memory": "memory_embedding"
}
}
}
]
}
}
text embedding のためのingest pipelineが作成されていました。Embedding 用の model が設定されている場合には、Memory Container にメモリーを登録する際にはこのingest pipelineを利用して vector embedding された形で indexing されます。
Memory Container へのメモリーの保管の仕組み
作成した Memory Container を指定してユーザーとのやり取りを投入して保管していきます。
Memory Container へ 投入(indexing) する際には、data type と. conversational type の2種類のデータタイプがあるのでそれぞれ見ていきます。Mermory Containerへデータを投入する際にはこれらを指定する"payload_type"フィールドが必須になります。
まず、data typeです。structured_data というフィールド名で登録します。こちらはエージェントのステートやチェックポイント、参照情報などの構造化された会話以外のデータを投入する時に使います。data type のペイロードについては、embeddingや抽出などの処理もされません。
# data type
{
"structured_data": {
"agent_state": "researching",
"current_task": "analyze customer feedback",
"progress": 0.75
},
"namespace": {
"agent_id": "research-agent-1",
"session_id": "session456"
},
"payload_type": "data",
"infer": false
}
data type の場合はLLMでの処理を行わないため
次に、Memory 機能のメインになる. conversational タイプです。
ユーザーとLLMが行なった会話形式のデータを投入する際に利用します。
# conversation
{
"messages": [
{
"role": "user",
"content": [
{
"text": "I prefer email notifications over SMS",
"type": "text"
}
]
},
{
"role": "assistant",
"content": [
{
"text": "I've noted your preference for email notifications",
"type": "text"
}
]
}
],
"namespace": {
"user_id": "user123",
"session_id": "session456"
},
"payload_type": "conversational",
"infer": true
}
"infer": true というパラメータが StrategyにしたがったLLMでの処理を行うかのフラグになっています。このときに、Memory Contianer を作成した時に 設定したnamespace と同じnamespace のフィールドを渡す必要があります。
working memory へはどちらのタイプのデータも投入されますが、long-term memoryに登録されるのはこの "payload_type": "conversational" のデータのみになります。
long-term memoryへのデータの投入の流れは以下の図のようなものです。
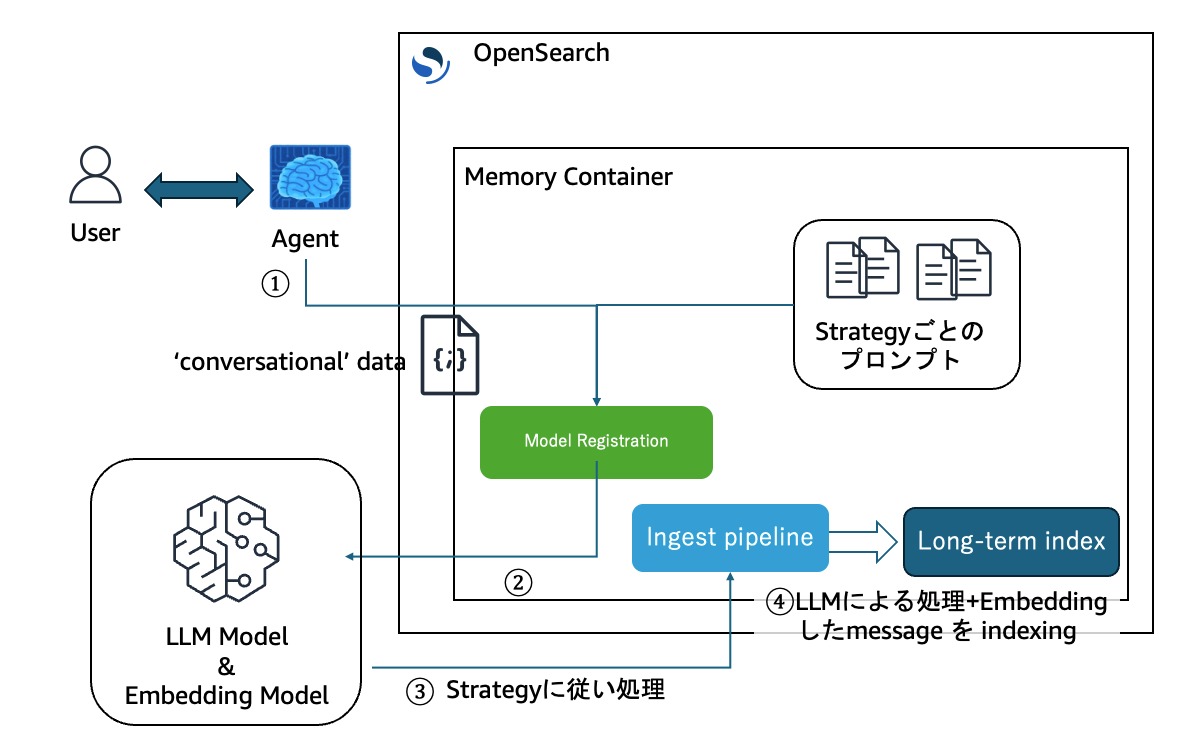
conversational タイプのデータ(message)が投入されると、Strategyごとに用意されたプロンプトをシステムプロンプトとして付与した形で、登録されたLLMモデルに投げられます。LLMモデルがシステムプロンプトの指示に従った形で処理し
たデータが返却されそれをlong-term memory に投入するといった流れです。
データのメモリコンテナへの投入は以下のように行いますが、どのmemoryに入れるといった指定はできず、ある Memory Conteiner にむけてメッセージをなげるといった使い方になります。
POST /_plugins/_ml/memory_containers/4WNJHZsBCZldK7l7ArDm/memories
{
"namespace": {
"session_id": "session456",
"agent_id": "session789",
"user_id": "user-1"
},
"infer": true,
"memory_type": "conversational",
"messages": [
{
"role": "user",
"content": [
{
"text": "I prefer soccer than basketball",
"type": "text"
}
]
}
],
"message_id": 0,
"metadata": {
"created_at": "2025-09-21T01:14:25.897323+00:00",
"updated_at": "2025-09-21T01:14:25.897325+00:00"
}
}
long-term memoryについては、投入される際に関連する情報がすでにlong-term memory内にある場合にはそれを更新したりする仕組みも入っています。
注意が必要そうなのは、working memory の内容をもとにそれをサマリーして遷移させるような仕組みではなく、直接 long-term メモリーに集約するために処理が動くところでした。そのため、Memory Container へのエージェントからのデータの投入が逐次的にされていく形になります。
Memory Container に保管された情報の利用の仕方
実際に入れられたメッセージがどのような形で入れられているかみてみましょう。
メモリーを取り出す際には以下のように Agentic Memory のAPIを利用します。
Memory typeを指定した形でリクエストする使い方になっています。
まず、working memoryの中身を見てみましょう。
POST /_plugins/_ml/memory_containers/{memory container id}/memories/working/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"namespace.user_id": "user-1"
}
}
]
}
}
}
//response
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "agentic-chat-semantic-memory-working",
"_id": "THNXHZsBgEAJFIASpupw",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"_score": 1,
"_source": {
"payload_type": "conversational",
"created_time": 1765723842159,
"metadata": {
"updated_at": "2025-09-21T01:14:25.897325+00:00",
"created_at": "2025-09-21T01:14:25.897323+00:00"
},
"last_updated_time": 1765723842159,
"infer": true,
"namespace_size": 3,
"owner_id": "fshuhe",
"namespace": {
"agent_id": "session789",
"user_id": "user-1",
"session_id": "session456"
},
"messages": [
{
"role": "user",
"content": [
{
"text": "I prefer soccer than basketball",
"type": "text"
}
]
}
],
"message_id": 0,
"memory_container_id": "4WNJHZsBCZldK7l7ArDm"
}
}
]
}
}```
(直接indexを指定して取り出すこともできたりします。使い分けは、、、index名を直接指定しなくていいのはありますが、ちょっと悩み中です、、、)
次に long-term memoryです。
```json
GET /_plugins/_ml/memory_containers/4WNJHZsBCZldK7l7ArDm/memories/long-term/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"namespace.user_id": "user-1"
}
}
]
}
}
}
//response
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "agentic-chat-semantic-memory-long-term",
"_id": "TXNXHZsBgEAJFIASteqs",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"_score": 1,
"_source": {
"created_time": 1765723845737,
"memory": "Soccer is preferred over basketball.",
"last_updated_time": 1765723845737,
"memory_embedding": [
-0.054394837,
...
-0.029751873
],
"namespace_size": 1,
"owner_id": "fshuhe",
"namespace": {
"user_id": "user-1"
},
"strategy_id": "semantic_9832d9d5",
"strategy_type": "SEMANTIC",
"memory_container_id": "4WNJHZsBCZldK7l7ArDm"
}
}
]
}
}
memory フィールド がLLMによって処理された内容、memory_embeddingがベクトル埋め込みさらたベクトルデータになります。
History メモリもみてみましょう。
GET /_plugins/_ml/memory_containers/4WNJHZsBCZldK7l7ArDm/memories/history/_search
{
"query": {
"match_all": {}
}
}
//response
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "agentic-chat-semantic-memory-history",
"_id": "TnNXHZsBgEAJFIAStuqq",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"_score": 1,
"_source": {
"created_time": 1765723846313,
"memory_id": "TXNXHZsBgEAJFIASteqs",
"owner_id": "fshuhe",
"namespace_size": 1,
"namespace": {
"user_id": "user-1"
},
"action": "ADD",
"memory_container_id": "4WNJHZsBCZldK7l7ArDm",
"after": {
"memory": "Soccer is preferred over basketball."
}
}
}
]
}
}
このように、memory にたいして ADDやUPDATEといった処理の履歴が残ります。ちなみに、モデルとのメッセージの受け渡しがうまくいかなかった場合などは、INTERNAL SERVER ERROR が入っていたりします。
エージェントフレームワークからの利用の仕方
こちらのページにある Strands Agent のメモリとして利用している例を見てみると Tool use として、各種操作を登録するような形で利用しています。サンプル上では、add_memory, search_memory, update_memory, delete_memoryの4つの関数を作成しています。
他のエージェントでも同じような使い方になるかと思いますが、かなり自由度が高く使うことができる一方で、設計の検討余地はかなり広くあるように思います。
まとめ
OpenSearch の Agentic Memory の機能は、エージェントのメモリとしてOpenSearchを利用するために必要なコンポーネントのセットとともに、非構造データを処理して投入する仕組みを簡単に利用することができる機能でした。
また、1つのエージェントにおけるメモリストアの実装例としても参考になる部分があるように思います。
もともとのRFCを読んでみると、Pruning and aging policies
やVersion trackingといった構想もあるように見えます。まさにここにあるような長期的に使っていく際に必要になりそうなPruningなど情報をまとめたり遷移させたりする機能ができてくると今後もっと使いやすくなっていくように思っており、個人的にも非常に期待しております。
(余談、というかただのつぶやき) エージェントにおけるメモリーでのlexical search(全文検索)の扱い
OpenSearch をエージェントのメモリーとして利用することを考えた時のprosはどんなものがあるでしょうか? 個人的にはスケール性やK-NNまわりの機能群などいくつかあるかと思うんですが、1つの要素としてlexical search が非常にmatureであることがあるかと思います。またlexical searchをより一般的にベクトルサーチと比べた時の差別化要素としては新語や造語、専門用語(いわゆるjargon)などの扱いが簡単な点だと思います。
ただ、エージェントのメモリとして lexical search を利用する話は、ネット界隈でも学術的な舞台でもあんまり聞いたことがありませんでした。(もし結構あるよとかあれば教えていただけると嬉しいです。)
これにも色々な理由があるのだと思うのですが、今回のようにメモリストアとしての実装を見てみた時に、一般的な単語以外をうまく扱うためにlexical searchを利用するための辞書の整備を誰がやっていくのかという点があるように思います。そのときには辞書への登録だけでは足りず、その単語の意味がどんなものものなのかをLLMが解る必要があります。
こういった辞書整備の仕組みの一部をエージェントにやらせながら進む仕組みがあると、単語レベルでの”メモリー”についてもよりシンプルに行なっていけることが期待できるのではと考えています。
自分自身はまだこの辺りを試せてはいないので今後取り組んでみたいなと思っていますが、この辺りが整理されてくると検索エンジンのメモリーとしての利用の仕方も広がってくるのかなと考えています。
Discussion