AWS Lambdaを利用したお手軽バッチ処理のススメ
この記事について
一般的なクラサバ構成のアプリケーションを対象としています。
AWS初心者の私が、クライアントに対して即座に結果を返せないような機能をAWS Lambdaを利用しお手軽にバッチ処理した話です。
また、具体的なソースコード等はなく、アーキテクチャの説明になります。
ex)
- アップロードされた画像をゴニョゴニョ加工して返す
- Excel等の帳票などを読み込み、データを加工して登録
- 1リクエストでの大量データ処理←業務トランザクションを分けたほうがいいかも
きっかけ
ある外部APIを利用する要件がありました。
但し、以下のような条件があります。
- 外部APIは即座にレスポンスを返す場合もあるが、最大で10分程度かかる可能性もある
- 外部API側が弱く、失敗する可能性もある
- 大量リクエストが発生する可能性がある
- 外部APIには冪等性があり、通常何度呼び出しても結果は変わらない
仮にHttpサーバのタイムアウトを無視しても、ブラウザのタイムアウトはFireFoxは300sらしいし、Chromeは不明、そもそも10分もレスポンスないのは現代のアプリケーションとしてちょっと情けない。。
結果
- Amazon Simple Queue Service
- AWS Lambda
- Amazon DynamoDB
の3つのマネージドサービスを利用して概ね以下のような形で対応しました。
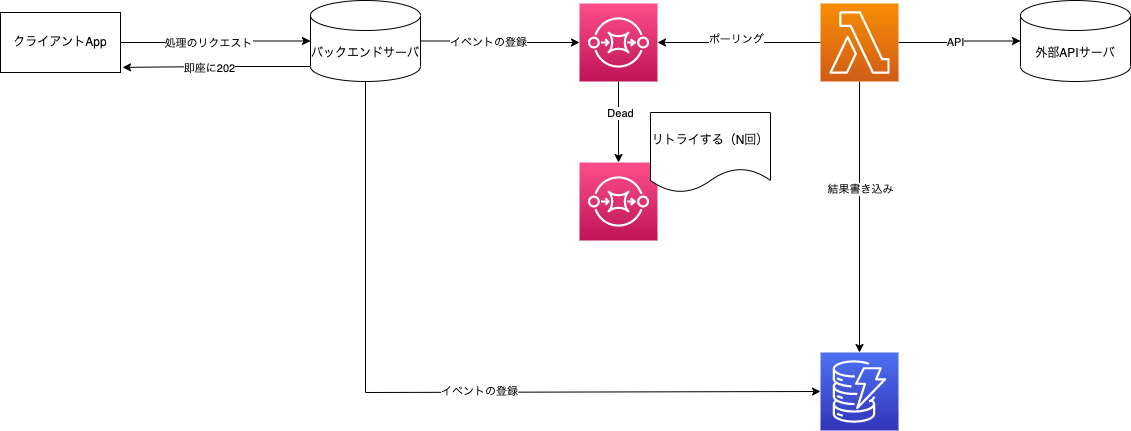
※クライアントへの通知は省いています(処理のオフロードが本記事の目的のため
Amazon Simple Queue Service(SQS)の利用
SQSはAWSが提供する、メッセージキューサービスです。
公式を参照するのが良いですが、自分で利用してみて以下のような特徴があります。
- フルマネージドなので構築が楽
- 標準キューとFIFOキューがあり、順序を意識しない高速な処理、順序を意識した十分高速な処理がある
- Lambda等の他のAWSサービスとの接続が容易
- バッチ処理でやっかいなリトライ処理が容易
- DeadLaterQueueの設定が容易
今回は
- 大量処理の可能性
- 外部APIには冪等性があり、通常何度呼び出しても結果は変わらない
という要件であることと、順序が必要な処理ではなかったため、標準キューを選択しました。
例として以下のようなメッセージを登録して利用します。
"{id: UUID, 'userId': 1}"
実際には256kbまでのテキストを扱えるため、より柔軟なデータの移送が可能で、対応の幅が広いなと思いました。
また、今回の要件として接続先のAPIが弱い等の仕様のため、ネットワークエラーなどの例外が発生する可能性があります。
そのため、失敗したメッセージのリトライ(DeadLaterQueueからのreドライブ=再送)、蓄積(DeadLaterQueue)が設定一つで可能なため非常に楽でした。
AWS Lambdaの利用
バッチサーバを立て、常時キューをポーリングする等も選択肢としては存在しますが今回は以下の点からLambdaを選択しました。
- なんといってもコード書けばいいだけ
- SQSとの相性バツグンで水平スケールが容易
SQSとの連携は標準でサポートされており、イベントソースとして対象のSQSリソースを設定すれば自動でポーリングされます。
注意点
- Lambdaのタイムアウト設定はSQSの可視性タイムアウト以下にする必要があること
- SQSに標準キューを選択した場合、at least onceの仕様により、同一メッセージが複数回処理される可能性があるため、冪等性の確保や排他制御を実装すること
また、キューを利用する場合一般に処理をスケールさせたい要件があると思いますのでいかにも注意です。
- LambdaからRDSへアクセスする要件がある場合、容易にスケールができないためAmazon RDS Proxyの利用や、Amazon DynamoDB等のドキュメントDBを検討すること(リンクは公式です)
Tips
排他制御の実装
例えば、DynamoDBを利用した楽観ロックが比較的容易で以下のようなものが考えられます
- DynamoDBへユニークなイベントのIDとステータスをメッセージ発行時にPut
- Lambdaはイベント処理時にDyanmoDBを見て、処理を実行を制御する
最後に
非同期アーキテクチャを実現するAWSサービスは多くあり、迷う点もおおいです。
今回は、The バッチと言える単純なユースケースであったためこのようなシンプルなパターンが適用できました。
一つのデータが大きくストリームを利用する場合などはもっと適したAmazon Kinesis等があったり、
複雑な依存関係がある処理に適したStepFanctionsなどなどがあります。
要件を見極めることができると解決の幅が広がると感じました。
参考にしたソース等
Discussion