Vertex AIでカスタムモデルをサービングする
はじめに
機械学習を利用する目的は、アルゴリズムに基づいて何らかの予測を得ることだと言えます。予測を提供(サービング)する方法の一つは、モデルをラップする形でAPIサーバーを構築することです。
Google Cloud Platformの統合AIプラットフォームであるVertex AIでは、こうしたサービングをクラウド上でホストすることができます。本記事では学習済みの機械学習モデルをもとに、Vertex AIで予測をサービングするまでを紹介します。

Cloud Console上での予測リクエストのテスト
コードは以下に配置しました。
Vertex AIにおける予測サービング
Vertex AIで予測を提供する手順は、大まかには以下のようになります。
- モデルをアップロード(インポートとも呼ばれる)する
- エンドポイントを作成する
- エンドポイントにモデルをデプロイする
今回はペンギンデータセットを学習したLightGBMのモデルをデプロイします。学習済みモデルはリポジトリに配置(blog/vertex-prediction/app/model.lgb)してあります。学習部分の実装は省略しますが、気になる方は以下の記事を参照してください。
モデルのアップロード
ここでのモデルリソースとは、アルゴリズムを学習して得られたアーティファクト本体と、それを動作させるDockerイメージのセットを指します。Vertex AIでは、学習済みモデルが以下の要件を満たしている場合には、ビルド済みコンテナを利用できます。
- Python3.7以降でトレーニングされている
- TensorFlow、scikit-learn、または XGBoost でトレーニングされている
- ビルド済みの予測コンテナのフレームワーク固有の要件を満たすようにエクスポートされている
一方で自分でカスタムコンテナを用意すれば、任意のMLアルゴリズムを予測に用いることができます。実装する量は増えますが、柔軟で拡張性が高い方法と言えます。今回はこちらの方法を採用し、LightGBMを稼働させるコンテナイメージを作成します。
予測サーバーの作成
カスタムコンテナによってVertex AI上で予測を提供するためには、HTTPサーバーとして一定の要件を満たすように実装を行う必要があります。一般的なWebフレームワークのほかに、TensorFlow ServingやTorchServeなどのML配信ソフトウェアも利用できると記載されています。今回はPythonの軽量ウェブフレームワークであるFastAPIを用いて、HTTPサーバーを構築します。
主な実装要件としては以下があります。
- ヘルスチェックと予測サービングの2つのAPIの実装
- 予測リクエストとレスポンスのフォーマットの実装
ヘルスチェックと予測サービング用のAPIは以下のように実装しました。これらに対応するHTTPパスはVertex AIにモデルをアップロードする際に設定され、プログラムからは環境変数(AIP_HEALTH_ROUTE, AIP_PREDICT_ROUTE)を通じて参照することができます。
import os
from fastapi import FastAPI
AIP_HEALTH_ROUTE = os.environ.get('AIP_HEALTH_ROUTE', '/health')
AIP_PREDICT_ROUTE = os.environ.get('AIP_PREDICT_ROUTE', '/predict')
app = FastAPI()
(中略)
@app.get(AIP_HEALTH_ROUTE, status_code=200)
async def health():
return {'health': 'ok'}
@app.post(AIP_PREDICT_ROUTE)
async def predict(...):
...
Vertex AIから提供されるデフォルトの環境変数としては他にも様々なものが設定されます。例えばモデルアップロード時にアルゴリズムのアーティファクトが存在するCloud Storageの場所を指定すると、AIP_STORAGE_URIを通じてプログラム内から参照することができます。
今回用いるLightGBMは比較的軽量であるためコンテナイメージに同梱しており、AIP_STORAGE_URIは利用していません。一方で深層学習モデルなどファイルサイズが大きい場合や、Dockerイメージとアーティファクトの管理を分けたい場合などはこの変数を利用するのが良いかもしれません。全ての環境変数はドキュメントを参照してください。
二つ目の要件として、予測リクエストとレスポンスの実装フォーマットを実装します。予測リクエストは以下の形式のContent-Type: application/jsonHTTPヘッダーとJSON本文として与えられます。instancesは予測対象のデータ配列であり、parametersはオプションのパラメータです。
{
"instances": INSTANCES,
"parameters": PARAMETERS
}
レスポンスは以下の形式としてサーバーから返却する必要があります。
{
"predictions": PREDICTIONS
}
今回はFastAPIによって以下のように実装しました。
import numpy as np
import pandas as pd
import lightgbm as lgb
from enum import Enum
from typing import List, Optional
from fastapi import FastAPI
from pydantic import BaseModel
(中略)
model = lgb.Booster(model_file='model.lgb')
class Specie(Enum):
ADELIE = 0
CHINSTRAP = 1
GENTOO = 2
class PenguinFeature(BaseModel):
bill_length_mm: float
bill_depth_mm: float
flipper_length_mm: float
body_mass_g: float
class Parameters(BaseModel):
return_confidence: bool
class Prediction(BaseModel):
specie: str
confidence: Optional[float]
class Predictions(BaseModel):
predictions: List[Prediction]
@app.post(AIP_PREDICT_ROUTE,
response_model=Predictions,
response_model_exclude_unset=True)
async def predict(instances: List[PenguinFeature],
parameters: Optional[Parameters] = None):
instances = pd.DataFrame([x.dict() for x in instances])
preds = model.predict(instances)
indices = np.argmax(preds, axis=-1)
confidences = np.max(preds, axis=-1)
if parameters is not None:
return_confidence = parameters.return_confidence
else:
return_confidence = False
outputs = []
for index, confidence in zip(indices, confidences):
specie = Specie(index).name
if return_confidence:
outputs.append(Prediction(specie=specie, confidence=confidence))
else:
outputs.append(Prediction(specie=specie))
return Predictions(predictions=outputs)
BaseModelを継承しているクラスは、FastAPIで各APIのフォーマットを定義するために用います。
-
PenguinFeature: LightGBMの入力となる各特徴量 -
Parameters: 予測時のオプション。return_confidence=Trueの場合、予測確率を合わせて返す。 -
Prediction: 予測結果の分類クラスと確率 -
Predictions: APIに渡された全データ点の予測結果(Prediction)のリスト
予測を行うpredict関数では、入力データであるPenguinFeatureのリストと、オプションとしてParametersを受け取ります。これをLightGBMによって予測し、Predictionsに詰め込む形で返却します。
これに対して、サンプルのJSONリクエストは以下のようになります。
{
"instances": [
{
"bill_length_mm": 39.1,
"bill_depth_mm": 18.7,
"flipper_length_mm": 181,
"body_mass_g": 3750
},
{
"bill_length_mm": 46.5,
"bill_depth_mm": 17.9,
"flipper_length_mm": 192,
"body_mass_g": 3500
},
{
"bill_length_mm": 46.1,
"bill_depth_mm": 13.2,
"flipper_length_mm": 211,
"body_mass_g": 4500
}
],
"parameters": {
"return_confidence": true
}
}
instances, parametersが記載されており、Vertex AIの要件に従っていることがわかります。最終的にこのモデルをデプロイし、予測をリクエストすると、以下のようなレスポンスが得られます。各データ点に対して、予測クラスと確率が得られています。deployedModelIdはVertex AIによって自動的に付与されます。
{
"predictions": [
{
"confidence": 0.99291988380921126,
"specie": "ADELIE"
},
{
"specie": "CHINSTRAP",
"confidence": 0.97967966921123462
},
{
"confidence": 0.98773589814924911,
"specie": "GENTOO"
}
],
"deployedModelId": "8992492187207860224"
}
コンテナイメージの作成
前述のサーバープログラムを稼働させるDockerイメージを作成します。イメージの制限はあまりありませんが、今回はFastAPIの開発者の方が公開しているGunicornとUvicornが組み込まれたベースイメージをもとに作成しました。
FROM tiangolo/uvicorn-gunicorn-fastapi:python3.8-slim
RUN apt-get update -y \
&& apt-get install -y libgomp1 \
&& apt-get -y clean all
RUN pip install poetry
COPY poetry.lock pyproject.toml .
RUN poetry config virtualenvs.create false \
&& poetry install --no-interaction --no-ansi
COPY . /app/
Vertex AI上のモデルリソースとしてアップロードするために、Container Registryにpushしておきます。
PROJECT_ID=`gcloud config list --format 'value(core.project)'`
docker image build ./app -t vertex-prediction
docker tag vertex-prediction gcr.io/${PROJECT_ID}/vertex-prediction:latest
docker image push gcr.io/${PROJECT_ID}/vertex-prediction:latest
コンテナアプリケーションとして、ローカルで検証することもできます。今回用いたベースイメージは、デフォルトで80番ポートが公開されます。また、起動するモジュールはAPP_MODULEを通じて指定する必要があります。
docker container run --rm -p 80:80 -e APP_MODULE=server:app --name vertex-pred vertex-prediction:latest
コンテナを起動した上で、ブラウザ上でlocalhost:80/docsにアクセスすると、各APIの仕様を確認できます。リクエストやレスポンスのフォーマットがカスタムコンテナの要件を満たしているかどうかも、この段階で確認すると良いでしょう。

Vertex AIへのアップロード
今回はCloud Consoleからモデル(学習済みモデル本体とコンテナイメージ)をアップロードします。gcloudコマンドやPython SDKなどからも可能です。アップロードを自動化する際にはコマンドベースの方法が良いでしょう。
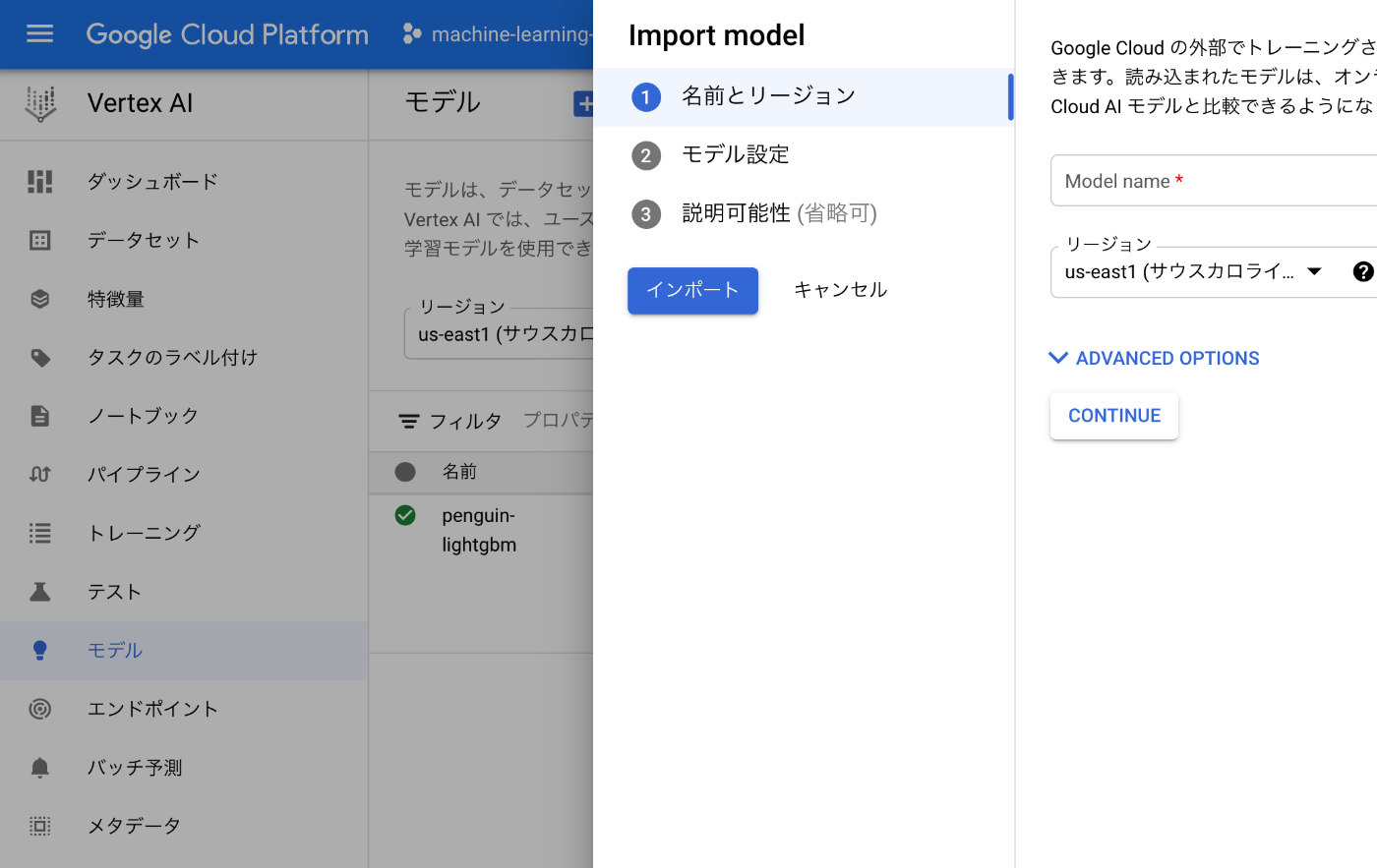
「Vertex AI>モデル>インポート」を選択することで、アップロード内容を設定できます。今回は以下のように設定しました。
- 名前とリージョン
- 名前は任意の値、リージョンはus-east1(関連するストレージバケットなどと同じ場所)
- モデル設定
- 「既存のカスタムコンテナをインポート」
- コンテナイメージ:コンテナレジストリにpushしたイメージ
- 環境変数:
APP_MODULE=server:app - ポート:80
- 説明可能性(省略可)
- なし
Cloud Storage上のモデルアーティファクトの場所や、予測やヘルスチェックのHTTPパスもここで指定できます。これらは前述のAIP_*の環境変数と対応づけられます。他にコンテナ実行時の引数なども指定できます。
最後に「インポート」することで、モデルのアップロードが始まります。完了までは数分かかりました。この段階では、まだ予測をリクエストすることはできません。
エンドポイントの作成とモデルのデプロイ
エンドポイントは「Vertex AI>エンドポイント>エンドポイントの作成」から、または「Vertex AI>モデル>(アップロード済みの対象モデル)>エンドポイントへのデプロイ」から作成・デプロイできます。今回は後者で行います。

デプロイ内容は以下のように設定しました。
- エンドポイントの定義
- 「新しいエンドポイントを作成する」、エンドポイント名を入力
- アクセス:標準
- モデル設定
- コンピューティングノードの最小数:1
- マシンタイプ:n1-standard-2
- ロギング:「このエンドポイントのアクセスロギングを有効にする」
- モデルのモニタリング
- (変更なし)
最後に「デプロイ」を選択することで、エンドポイントの作成とモデルのデプロイが実行されます。完了すると予測をリクエストできるようになります。今回は利用していませんが、稼働マシンへのGPUの付与やオートスケーリングの設定、また単一のエンドポイントに複数のモデルをデプロイしてトラフィックを分割することもできます。
オンライン予測の取得
エンドポイントへのモデルデプロイが完了していれば、予測リクエストを送ることができます。Cloud Consoleの「Vertex AI>モデル>(デプロイしたモデル)」を選択すると、コンソール上でJSONリクエストをテストすることができます。

もちろんAPIとして各種ツールからリクエストすることも可能です。例えばcurlコマンドからは、対象エンドポイントのIDを指定した上で以下のように予測をリクエストできます。
ENDPOINT_ID=<deployed-endpoint-id>
INPUT_DATA_FILE=sample-request.json
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-east1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-east1/endpoints/${ENDPOINT_ID}:predict \
-d "@${INPUT_DATA_FILE}"
{
"predictions": [
{
"confidence": 0.99291988380921126,
"specie": "ADELIE"
},
{
"specie": "CHINSTRAP",
"confidence": 0.97967966921123462
},
{
"confidence": 0.98773589814924911,
"specie": "GENTOO"
}
],
"deployedModelId": "8992492187207860224"
}
デプロイ中はマシンの利用分の料金が発生します。利用を停止する場合はエンドポイントからモデルデプロイを削除し、その後でエンドポイント自体を削除しましょう。
まとめ
LightGBMを用いて、Vertex AI上で予測をサービングするまでを紹介しました。調べた限りカスタムコンテナを用いた実装例などは比較的少なかったのですが、基本的に公式ドキュメントをあたっていけば実装することができました。マシンタイプやGPUの有無も簡単に指定できるため、MLモデルをサービングする際には便利なサービスと言えます。
今回扱わなかった機能の中で個人的に注目している機能として、モデルモニタリングがあります。運用時の入力データや予測結果をモニタリングすることで、予測品質の維持につなげることができます。引き続きキャッチアップしていこうと思います。
参考資料
Discussion