AMIによるEC2インスタンスの起動からターゲットグループへの登録までを自動化した
株式会社エアークローゼットにてエンジニアをやらせていただいてる大西です。
この記事は
- エアークローゼット アドベントカレンダー10日目
- AWS アドベントカレンダー10日目
-
AWS LambdaとServerless アドベントカレンダー10日目
の記事になります。
はじめに
今回は、今年の業務の中で特に印象的だったEC2インスタンスの起動からターゲットグループへの登録までをStepFunctionで自動化した話について書きたいと思います。
この記事では、開発の経緯や設計意図をメインに書きます。
ソースコードは別記事で書いていますので、それぞれのリンクを辿ってください!
また、StepFunctionどころかAWSも初めて触った人間が書いているので、初歩的な内容になっています。
背景
まず、なぜこの機能を作ることになったかの背景をお話しします。
弊社のリリース環境
弊社には、元々EC2インスタンスを起動し、ソースコードをビルド、反映を行うコマンドとターゲットグループに紐づけるコマンドが整備されていました。
これらのコマンドは耐障害性の観点から、仮想的な二つのリリース環境に対して、交互にデプロイを行う仕組みとなっています。
デプロイを行う際にはデプロイコマンドにて、本番環境として使用されていない環境に対してデプロイを行い、リリースコマンドで本番として使う環境を切り替えます。
問題点
このリリースコマンドの問題点として、リリース中の環境に対してインスタンス数を増減させる処理に対応していないことがあります。
そのため、サーバーのスケールアウトの際には、デプロイまでコマンドで実行し、ターゲットグループに紐づけるのは手動で行なっていました。
当たり前ですが、手作業が入ると人為的なミスがよく起こるんですよね。。。
デプロイしたけどターゲットグループに紐づけるのを忘れてスケールアウトできていなくて、サーバーが重くなるとか。
最近はサービスの成長により、お知らせ1回出すだけでも、1年前のテレビ露出と同等のサーバー負荷がかかるようになっています。
このことも相まって
- スケールアウトの時間的コストが無視できないものになっていたこと、
- 前述のミスが頻発したこと
で自動化する機能を作ることになりました。
どうせ作るなら汎用性の高いもの作ろうよとなり、スケールアウト用ではなく、AMIからEC2インスタンスの立ち上げとターゲットグループの登録の一連の流れを自動化するという形になりました。
ちなみに、EC2 AutoScalingではお知らせのような瞬間的なアクセス数の増大には対応しきれないので、今回は導入を見送っています。
機能の解説
今回作った機能の処理フローは下記の通りです。
- リリースコマンドを実行時に、対象のインスタンのAMIを作成する
- AMIからEC2インスタンスを起動する
- EC2インスタンスが起動するのを待つ
- ターゲットグループにEC2インスタンスを紐づける
- ターゲットグループのHealthチェックが終わるのを待つ
- 結果を社内Slackに通知する
1はシェルスクリプトにAWS CLIのコマンドを入れただけですので、今回は解説しません。
2から6のフローはStepFunctionで実装しました。
結果通知以外はEC2インスタンス毎に独立した処理のため、Mapタスクを使って並列処理をしています。
フロー図を見て貰えばわかるのですが、絶望的にわかりづらい処理になっています。。。(なぜこうなったかは後ほど解説します)

こだわりポイント
StepFunctionのタスクだけで待ち処理を作る
前述のステートマシンのタスクのほとんどはこの待ち処理のためのものです。すなわち、フロー図を複雑にした張本人です。
とは書いたものの、若干複雑になってでも待ち処理をStepFunctionで書くメリットはいくつかあり、
- Lambdaで待ち処理を実装すると待っている間も課金対象となる
- どこで失敗したかが色でわかるため、どの処理で落ちたか追跡しやすい
1個目のLambdaの課金ですが、使用頻度も高くないし、待つといえども10分程度の話なので、そこまで影響はない気もします。
しかし、塵も積もれば山となるで、できればLambdaで待ちたくはないぐらいの感覚です。
メインは2個目の方で、実はこれぐらいの複雑さであれば、実際に使ってみると意外と処理の追跡ができます。
これはStepFunctionの非常に優れているところで、どこまで処理が進んでいるかをフロー図に色によって表示してくれるので、処理の追跡が容易です。
こればっかりは使ってみないとわからないと思うので、まだ使ったことがない方は実際にStepFunctionを使ってみてください!
あと、タスクが多いと処理進んで色が変わっていくのが見ていておもしろいです(笑)
疲れた時は処理が流れていくのをみて癒されたものです(仕事しろ
実装については下記の記事にて解説しております。
タスク名のヘッダとして処理番号をつけることでフロー図を見やすくする
前節でフロー図が複雑でもなんとかなると書きましたが、処理を終えるのはあくまで処理全体を理解している場合のみです。
作っている段階でこんなん他の人絶対理解できないやろと思ったので、少しでも見やすくするために設計書と共通の処理番号をタスク名のヘッダにつけることにしました。
個人的にはこれでかなり処理を追いやすくなったと思います。
例えば、6-Xと付いているものは終端タスクで、結果生成を行なっています。
ヘッダーがなければ中間タスクか終端タスクかの判別も容易ではありませんでした。(Success/Failタスクは使っていない理由は後述します)
仕様書と番号を共通させているので、処理の理解もかなりやりやすくなっていると思います。
EC2インスタンスの起動処理の仕様書であれば下記のように書いています。
処理2: インスタンスの起動を待つ
処理2-1: retry countの作成
処理2-2: describeInstanceStatusの実行が集中しないように30秒待つ
処理2-3: インスタンスのステータスを取得
処理2-4: インスタンスのステータスが取得できているか確認(ステータス取得ができない場合インスタンスの状態が保留中)
- もし取得できていない場合は空になっている
- 取得できている:処理3へ
- できていない:処理2-5へ
処理2-5: retry countが設定値以下であることを確認
設定値以下:retry countを増やし、intervalを挟んで、ステータス取得(処理2-3)に戻る
設定値より大きい:失敗6-2 -> 結果の生成処理へ
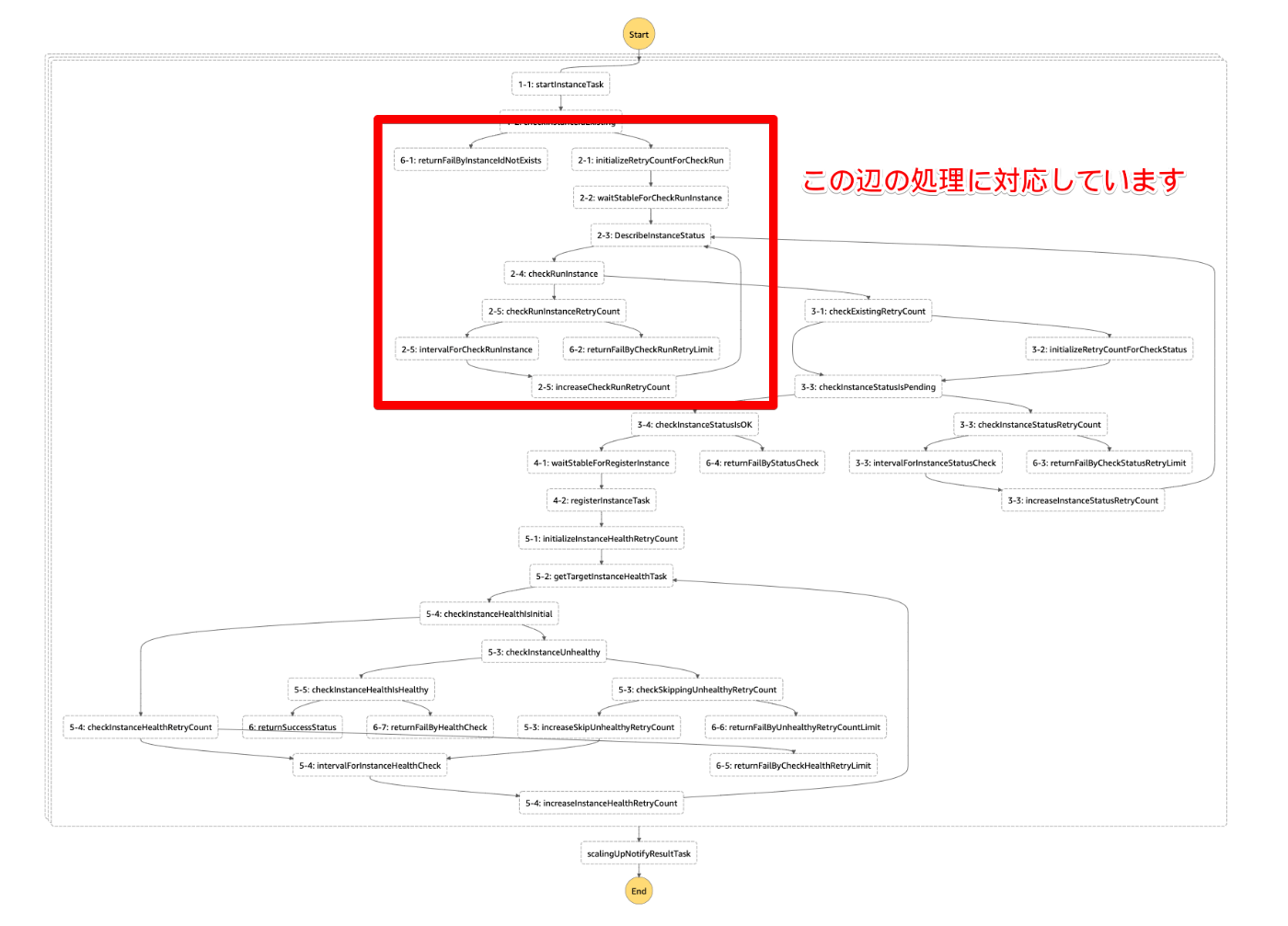
タスク数が多いステートマシンを作る時は、今後も続けていきたいと思っています。
StepFunctionの中でいくつか起動に失敗しても他の処理は継続させる
このステートマシンは、結果の通知以外はMapタスクによって並列で処理をしています。
Mapタスクは実行中の処理が一つでも失敗もしくは'Fail'タスクに入ると全ての処理を中断する仕様となっています。
この案件ではは1、2個処理に失敗しても大部分が最後まで処理されることが要件にありました。
この要件を満たそうと思うと、この仕様はかなり厄介です。
この問題を解決するために二つの処理を入れています。
- Lambda内でのエラーは社内Slackに通知をして、処理は継続する
- Mapタスクの終端状態にSuccess/FailタスクではなくPassタスクを入れて、結果通知処理に結果だけを渡し成功にする
1はjs/tsでは割と一般的な話ですので、ここでは説明を省略します。
面倒だったのは2の方です。
たどり着いた結論だけ見れば単純なことしかやっていないですが、
- Mapタスクでは、終端状態の返り値がMap後のタスクにリストで渡される
- 定数一つを定義するのでも、タスクを一つ置かなければならない
- Passタスクを終端状態に設定できる
といったStapFunctionの仕様を知らなければならなかったので、パッとは思いつきませんでした。
実際に下記の様なタスクを終端状態として定義することで、実現しています。
const returnFailByCheckRunRetryLimit = new sfn.Pass(
stack,
"6-2: returnFailByCheckRunRetryLimit",
{
inputPath: "$",
parameters: {
...returnStatusParametersBase,
status: "failure",
reason: "インスタンス起動リトライ回数の上限に達しました。",
},
resultPath: "$",
}
);
reasonは後ろの通知処理で、なぜ失敗したかを社内Slackに流すために書いています。
つまづきポイント
ターゲットヘルスがhealthyになった後にunhealthyになる場合がある
これに気づいた時は心の底から「なんでやね〜ん」と思いましたね。。。
対処としては、unhealtyになっても3回まではリトライするという処理を追加しました。
もっとAWSの勉強しないといけないと思いました(小並感
LambdaでAWSのAPIを叩くとアクセス数制限に引っかかりエラーが出る
こちらも知らないと防げない話ですね、、、
実はAWSのAPIには同時実行数の制限があり、制限数以上の同時アクセスがあるとエラーを返します。
StepFunctionのタスクでは元々リトライ処理が組み込まれている(ような挙動をしていた)ので、特に問題にはなりませんでした。
一方でAWS-SDKではその様な処理が組み込まれておらず、50並列ぐらいで動かすと半分ぐらいは死ぬみたいな状態でした。
対処としてはリトライ処理を組み込んだだけですが、叩くAPIによってエラーコードが異なるという、これまた初見殺しな問題がありました。
詳しく下記の記事にて紹介しています。
ソースコードも付けていますので、気になった方はご覧ください。
AWSのAPIを叩くStepFunctionタスクの定義
少しStepFunctionを触ったことある方でしたらタスクとしてAWSのAPIを叩くことができることはご存じだと思います。
また、このことは様々な記事で解説されています。
一方で、AWS-SDKでの実装方法は日本語、英語共にドキュメントが少なく、少し苦労しました。
別記事にて解説していますので、詳しくは下記の記事をご参照ください。
おわりに
初めてのインフラ開発でしたが、理解できればかなり面白いなぁと感じました。
また、一度やり方がわかれば初めて触るものでも意外とサクッと開発できなと思えたのはいい収穫でした。
長文&まとまりのない文章をここまで読んでくださりありがとうございました!
次のアドベントカレンダーの担当者は
-
エアークローゼット アドベントカレンダー
- エンジニアの@iduymanhtさん
-
AWS アドベントカレンダー
- @minorun365さん
-
AWS LambdaとServerless アドベントカレンダー
- @tnobeさん
です!
よろしくお願いします!
Discussion