ISUCON13 に @yoto1980yen と @allegrogiken と @daylight55 の同僚3人で参加しました!
私を含め、全員2度目の参加となります。メンバー構成は、昨年同じチームの2名、別チームの1名で計3名の混成チームです。
最終スコアは 9,566 となり、全員が前年より、確かな成果を得ることができました。上位陣の方々とは比になりませんが😅
本記事では、技術的なポイントより、最低限の知識・準備でISUCON参加した時のリアルと、次回に向けての想いを主にまとめていきます。
ISUCON参加を悩まれている方向けに丁寧にまとめてみましたが、細かすぎる所もあると思いますので適度に読み飛ばしていただけますと幸いです🙏
競技中のGithubリポジトリ: https://github.com/vvani06/isucon13
TL;DR
- 事前準備大事
- ボトルネックを分析した上でのDBインデックスは偉大
- 2回目以降参加する方はチームメンバーのミックスもおすすめ
ISUCONとは
ISUCONとは、LINEヤフー株式会社様が主体となって運営されている、Webアプリケーションの性能改善をテーマにしたプログラミングコンテストの一つです。
ご存知ない方はこちらの記事を読むと、内容、雰囲気が掴めると思います。
「なんでもあり」なWebアプリのチューニングバトル『ISUCON』はエンジニアの輪が広がる文化祭? ISUCON12出題者に大人気の秘密を聞いた - QiitaZine
方針
「去年の轍は踏まない。大きな課題に詰まらず、小さなアイデアを試す。」
私たちのチームでは、これを今年のISUCON攻略の大方針としました。
昨年のISUCON初参加では、慣れないこともあり、環境セットアップやDB初期化での失敗や、大きなボトルネックの改善に囚われてしまい、思った成果が上げられなかったことが全員の無念として挙がりました。
今年は去年と同じミスをしないことを念頭に、確実にスコアアップを目指すことを目標にしました。
ツール・利用言語
私たちのチームでは以下のツール・言語を使用しました。
アプリケーション言語は、全員が比較的慣れているRubyを使うことにしました。
| 目的 | ツール |
|---|---|
| コミュニケーション | Discord |
| ドキュメンテーション | Notion・Github Issue |
| エディタ | VSCode |
| アプリケーション言語 | Ruby |
| 構成図 | draw.io |
| ER図 | dbdiagram.io |
事前準備
当日までに以下を行いました。
- 戦略会議
- 当日の計画作成
- AWS環境のIAMユーザー払出し・ログイン確認
-
~/.ssh/configの雛形作成 - 当日のソースコード管理用のGithubプライベートリポジトリの作成・ユーザー招待
- DiscordのISUCON用チャンネルの作成・Github Botのセットアップ
戦略会議では"方針"に従い、ドキュメントの読み合わせを音読で確実に行うことを決めました。
音読にした理由は、全員が速度を落として丁寧に読むためです。
また、Notionにマニュアルを貼る用のページを作成し、読み合わせとともに気になるところはコメントを入れることで、重要なポイントをインデックス的に振り返りやすくすることを決めました。
あとは、3台分の競技サーバーへすぐSSHログインできるよう、~/.ssh/configに3台分の設定を書いておき、当日のIPアドレスを埋めたらすぐにログインできるように各自で準備しておきました。
演習用の過去問環境の構築も行いましたが、取り組み始めたのがギリギリだったのでリハーサルは叶わず、昨年の実績を元に当日に挑みました。
当日のタイムテーブル
9:00 チェックイン
Discordで起床報告です!
準備の出来た人からおもむろにDiscordのボイスチャットに集まりました。
9:30 Youtube Live実況
Discordでチャットを繋ぎながら、ISUCONのYoutube Live視聴です。
今年の課題は、"YouTubeのような動画ストリーミング配信サービス(isupipe)の性能改善"だったのですが、「Live配信開始時の遅延は伏線だったの!?」と盛り上がっていました。
ISUCONで一番楽しい瞬間かもしれません😆
10:00〜10:15 競技開始!
始まりました!
焦らずに、画面共有しながら以下を順番に進めていきます。
- CloudFormationのスタック作成
- 作成したインスタンスのIPアドレス共有
- 各自SSHログインの確認
- インスタンス1台のスナップショット取得 (※ もしもの復元用)
- 動作確認
- 初回ベンチマーク取得
-
/etc/hostsに定義を追加し、ブラウザからアプリケーションに接続
初回ベンチマークはGo言語実装で3,695でした。
10:15〜11:30 ドキュメント読み合わせ・初期セットアップ
ドキュメント読み合わせ
作戦通り当日ドキュメント・課題アプリのマニュアルの2つをNotionに貼り付け、一人が音読し、全員で読み合わせていきます。
音読で注意しながら読んでいたため、少し時間をかけています。
読んでいる中で気になるトピックがあれば下のスクショのようにコメントを入れていきました。

課題アプリのマニュアルは、用語・概念が多いため、ブラウザからアプリケーションに接続して動作イメージを確認しながら読み進めました。
この読み合わせの間にアプリの大まかな仕様、鍵になりそうなポイントに目星を付けていきます。
初期セットアップ
読み合わせの間で時間を取り、以下の初期セットアップも進めました。
(※ 以下の操作は事前にシェルスクリプトやAnsible、Itamaeなどで自動化スクリプトを組んでおくのが理想です。私たちのチームでは手動で行なっています。)
- アプリをRuby実装に切り替え
- マニュアル通りに実施します。
- 1台のサーバーで代表してSSH鍵を作成し、公開鍵を事前作成したGithubリポジトリのデプロイキーに設定。2・3台目のサーバーに秘密鍵を共有する。
- 競技サーバーからGithubリポジトリへのアクセスを許可します。
デプロイキーはSSHキーのみでアクセス許可が可能なため、ユーザーを意識せずにGithubリポジトリへのアクセスを管理したい時に便利です。
事前に作成しておいて、秘密鍵を競技サーバーに設定するのでもOKです。
- 競技サーバーからGithubリポジトリへのアクセスを許可します。
- アプリソースコードをGit管理・Github同期
事前確認していないと意外にこの設定方法でハマるので、メモとして残しておきます。- 1台目のサーバー
git config pull.rebase true git config --global user.name isucon git config --global user.email isucon@isucon.net cd ~/webapp git init . git remote add origin <remote repository url> git branch -M main git add . git commit -m "first commit" git push origin HEAD - 2台目・3台目のサーバー (既存ファイルを残しながら同期)
# (git branch -M mainまで上と同様) git fetch origin git reset origin/main git pull origin main --set-upstream
- 1台目のサーバー
- ミドルウェア(nginx,mysql)の初期設定ファイルをGitリポジトリに追加・Github同期
-
/etc配下にあるミドルウェアの設定ファイルもGit管理下に追加しておきます。
-
-
ミドルウェアの設定ファイルコピー・再起動のシェルスクリプト作成
- Git管理下のミドルウェア定義の反映を楽にするスクリプトです。
Githubからプルした後に、各ミドルウェアの/etc配下のコンフィグディレクトリにコピーしてミドルウェアを再起動するようにしました。
昨年はシンボリックリンクで運用しようとして失敗したので、愚直にコピーする方針にています。
- Git管理下のミドルウェア定義の反映を楽にするスクリプトです。
- 言語切り替え後のベンチマーク試行
- 言語切り替えと上記処理でやらかしていないか確認するため、ベンチマークの結果を確認します。
初期スコアと大きくずれてなかったので問題ないと判断しました。(言語切り替え後の初期スコアを残せていませんでした😭)
- 言語切り替えと上記処理でやらかしていないか確認するため、ベンチマークの結果を確認します。
上記のセットアップ中に発生したトラブル
-
アプリソースのGithub同期方法を決めていなかった
1台目のサーバーでGithubにPushして同期するまでの流れは良かったのですが、2・3台目のサーバーで「既存ファイルがあるディレクトリでGitリポジトリをセットアップし、リモートリポジトリに同期する方法」を決められていませんでした。
根本原因は、演習不足です。
しかし、ここで昨年別々のチームでやっていた混成チームであることが活きます。
設定を主導していたメンバーがどうするか悩んでいる間に、昨年別のチームだったメンバーが、昨年の知見を振り返って共有してくれたため、先述の箇条書きの内容ですぐ対処できました。 -
インスタンスの不調
ベンチマークを実行すると、インスタンスがSSH接続に応答しなくなりました。そこで、インスタンスをAWSから再起動します。
幸い、インスタンス再起動後は問題は再発しませんでした。
また、プロセスを見ると、VSCodeのRemote SSHによる負荷が怪しかったため、Remote SSHは極力使わない方向にしよう、と話し合いました。
11:30〜12:30 お昼休憩
少し早めの昼休憩です。
各自ご飯を食べながら、アプリケーションのソースコードリーディング、改善できそうなポイントを調べてGithubのIssueに上げていきます。
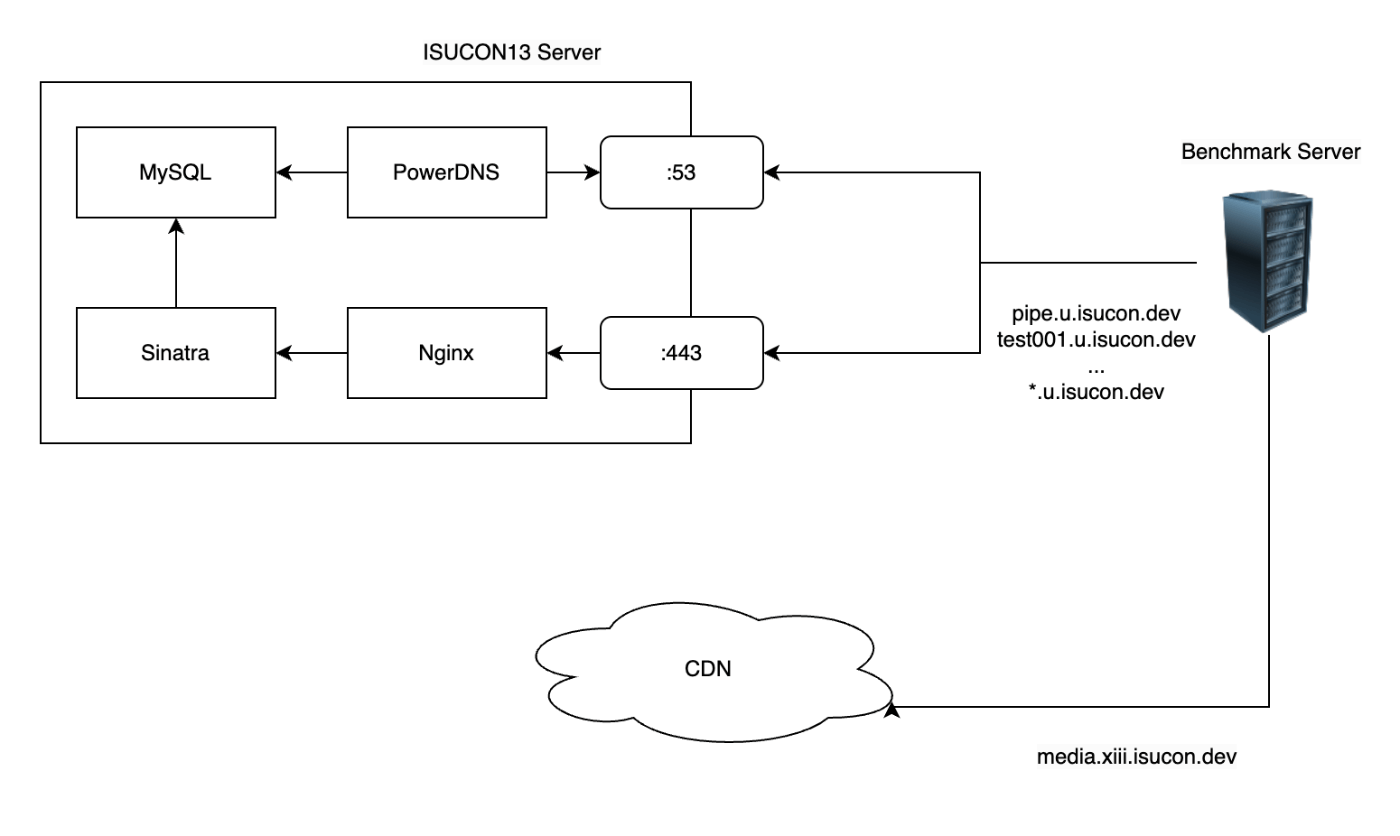
また、この時間中にメンバーの認識を統一するため下のようなサーバーの構成図や、DBスキーマからER図を作成しました。
サーバー構成図作成にはdraw.ioを使っています。
また、ER図はdbdiagram.ioというサービスを使いコードベースで作成しています。
サーバー構成図
ER図

さらに、少しメタな読みですが、マニュアルにあった「DNS水責め攻撃」と「PowerDNS」のワードから、今年の作問者の方が過去に遭遇した問題の記事を把握し、Issueで議論していました。
12:30〜13:30 解析ツールのセットアップ
ベンチマーク実行中に時間のかかっている処理(ボトルネック)を特定するため、ログ解析ツールであるalp, pt-query-digestをインストール・セットアップします。
それぞれの役割・できることは下のようなイメージです。
| ツール | 対象ミドルウェア | 出来ること |
|---|---|---|
| alp | Webサーバー(Nginx等) | アクセスログを解析し、パフォーマンスの要約を提供 |
| pt-query-digest | データベース(MySQL等) | SQLクエリログを解析し、最適化の指示を提供 |
具体的な使い方は通称ISUCON本を読むのがオススメです。
他の参加者の方がまとめている記事も大いに参考になると思います。
インストール方法は去年使っていたインストールスクリプトを思い出し、この手順でインストールしました。
その後、ミドルウェアのログ形式を解析ツールが読める形式に変更し、ベンチマークの実行ごとに解析結果を取得できるよう、ミドルウェアのセットアップスクリプトを改良します。
pt-query-digestは本来slow queryを分析するためのツールですが、ISUCONではslow queryの閾値を0にすることで、全てのクエリを分析できるようにします。
alpはセットアップしたものの上手く使えなかったため、次の計測・改善ではpt-query-digestの結果を中心に進めていきます。
13:30〜17:00 計測・改善
ようやく本命の計測と改善の開始です!
結論から述べると、今年私たちのチームでスコアに効力を発揮した改善は
「pt-query-digestの解析結果でSQL実行時間がかかっているテーブルを対象にDBインデックスを張る」
のみでした。
それ以外にもPowerDNSのチューニングや、見様見真似でカーネルパラメータのチューニングなども試しましたが、思った効果を上げられませんでした。
ここではDBインデックスのチューニングに絞って解説します。
pt-query-digestの結果確認
ベンチマーク実行中のSQLログから実行時間の統計情報をpt-query-digestで確認します。
以下は出力の抜粋例です。レスポンスの合計時間が多いクエリのパターンごとにランキングが表示されます。
pt-query-digestの結果
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============== ===== ====== ===
# 1 0xF7144185D9A142A426A36DC55C1D2623 241.6853 25.0% 5951 0.0406 0.02 SELECT livestream_tags
# 2 0xFD38427AE3D09E3883A680F7BAF95D3A 122.4148 12.6% 90702 0.0013 0.00 SELECT livestreams livecomments
# 3 0xC499D81D570D361DB61FC43A94BB888A 100.2764 10.4% 90702 0.0011 0.00 SELECT livestreams reactions
# 4 0x84B457C910C4A79FC9EBECB8B1065C66 98.3716 10.2% 11187 0.0088 0.02 SELECT icons
# 5 0xF1B8EF06D6CA63B24BFF433E06CCEB22 72.5819 7.5% 6402 0.0113 0.02 SELECT users livestreams livecomments
...
# Query 1: 60.72 QPS, 2.47x concurrency, ID 0xF7144185D9A142A426A36DC55C1D2623 at byte 67959722
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.02
# Time range: 2023-11-25T04:28:11 to 2023-11-25T04:29:49
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 1 5951
# Exec time 24 242s 2ms 182ms 41ms 87ms 29ms 40ms
# Lock time 3 36ms 0 20ms 6us 1us 263us 1us
# Rows sent 5 20.88k 0 11 3.59 4.96 1.84 4.96
# Rows examine 19 63.05M 10.71k 11.00k 10.85k 10.80k 151 10.80k
# Query size 0 336.84k 55 58 57.96 56.92 0.17 56.92
# String:
# Databases isupipe
# Hosts localhost
# Users isucon
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms #####################
# 10ms ################################################################
# 100ms ###
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `isupipe` LIKE 'livestream_tags'\G
# SHOW CREATE TABLE `isupipe`.`livestream_tags`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT * FROM livestream_tags WHERE livestream_id = '7523'\G
...
解析結果は全員が確認できるよう、実行時間ごとにテキストファイルでGitリポジトリに追加していくようにしました。
上記の結果から、SELECT * FROM livestream_tags WHERE livestream_id = 'xxxx'のクエリが実行時間が長く、where句も単純なID検索であることから、livestream_tagsテーブルのlivestream_idにインデックスを張ることが効果的だろうと判断しました。
インデックスを張る
早速、ALTER TABLEでインデックス作成処理を設定します。
ALTER TABLE livestream_tags ADD INDEX livestream_tags_livestream_id (livestream_id);
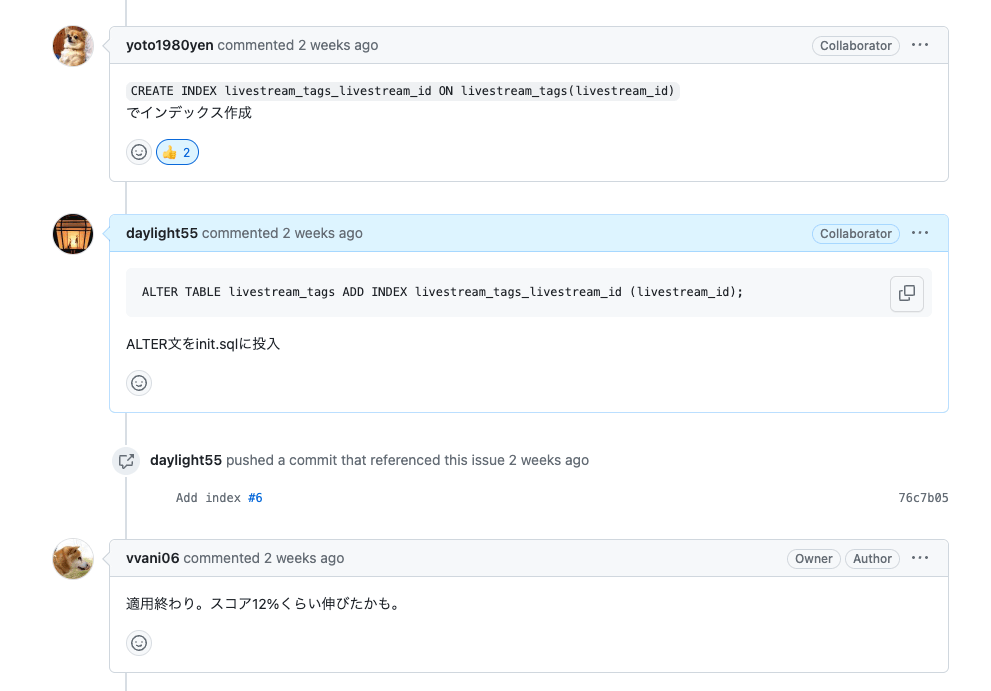
その後ベンチマークを実行します。
誤差かもしれませんがスコアが12%ほど上昇しました!(正確な値は残せていませんでした😭)
再: pt-query-digestの結果確認
もう一度pt-query-digestを実行し変化を確認します。
pt-query-digestの結果
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============== ===== ====== ===
# 1 0xF7144185D9A142A426A36DC55C1D2623 241.6853 25.0% 5951 0.0406 0.02 SELECT livestream_tags
# 2 0xFD38427AE3D09E3883A680F7BAF95D3A 122.4148 12.6% 90702 0.0013 0.00 SELECT livestreams livecomments
# 3 0xC499D81D570D361DB61FC43A94BB888A 100.2764 10.4% 90702 0.0011 0.00 SELECT livestreams reactions
# 4 0x84B457C910C4A79FC9EBECB8B1065C66 98.3716 10.2% 11187 0.0088 0.02 SELECT icons
# 5 0xF1B8EF06D6CA63B24BFF433E06CCEB22 72.5819 7.5% 6402 0.0113 0.02 SELECT users livestreams livecomments
...
pt-query-digestの結果(2回目)
# Profile
# Rank Query ID Response time Calls R/Call V/M
# ==== =================================== ============== ===== ====== ===
# 1 0xF7144185D9A142A426A36DC55C1D2623 267.5680 25.7% 6211 0.0431 0.02 SELECT livestream_tags
# 2 0x84B457C910C4A79FC9EBECB8B1065C66 118.7391 11.4% 11652 0.0102 0.02 SELECT icons
# 3 0xF1B8EF06D6CA63B24BFF433E06CCEB22 111.1679 10.7% 7651 0.0145 0.03 SELECT users livestreams livecomments
# 4 0xDB74D52D39A7090F224C4DEEAF3028C9 109.6591 10.6% 7651 0.0143 0.03 SELECT users livestreams reactions
# 5 0xFD38427AE3D09E3883A680F7BAF95D3A 76.5929 7.4% 60418 0.0013 0.00 SELECT livestreams livecomments
...
ランキングを細かく見ると、2,3,4位に変化があることがわかります。
が、この差であれば恐らく誤差の範囲です。
よって、その他のインデックスも追加で張っていくことを検討します。
インデックスをDB初期化時に張れるようにする
早速追加でインデックスを張りに...と行きたい所ですが、インデックス作成の定義をうまく運用するためには少し工夫が必要でした。
先ほどは飛ばしましたが、課題アプリの実装では、ベンチマークを走らせる際、一番初めにシェルスクリプトを呼び出して、DBのデータを初期化する作りになっています。
DBインデックスを張るのは、mysqlに直接クエリを実行してもいいのですが、やり直しが難しくなることから、なるべくこの初期化処理に含めたいです。
「ALTER TABLEでインデックスを張るのを常に実行で十分では?」と一瞬考えますが、ALTER TABLEはインデックスが既に存在する時に実行するとエラーになります。
かといって、IFステートメントでインデックスの有無をINFORMATION_SCHEMAから判定して、再作成を避けるクエリを書くのは思ったよりヘビーです。
そこで私たちのチームでは、初めのインデックス作成処理は削除し、初期化処理に以下のデータベース作成・スキーマ作成処理を追加し、データベース作成処理でデータベースを常に再作成するようしました。
これで、初期化処理のスキーマ定義時にCREATE INDEXでインデックスを新しく張ります。
参考コミット: https://github.com/vvani06/isucon13/commit/c6410814ab004ae2ec2ebe10e6e713c94b6071bc
インデックスを張る→再計測を繰り返す
ようやくインデックスを問題なく張れるようになりました!
ここから改善→ボトルネックの特定→改善のサイクルを進めていきます。
具体的には以下のイメージです。
- pt-query-digestのランキング上位のキーにインデックス追加
- ベンチマーク実行
- pt-query-digestの結果確認
- 1に戻る
Issueに記録しながらどんどんサイクルを回していきます。
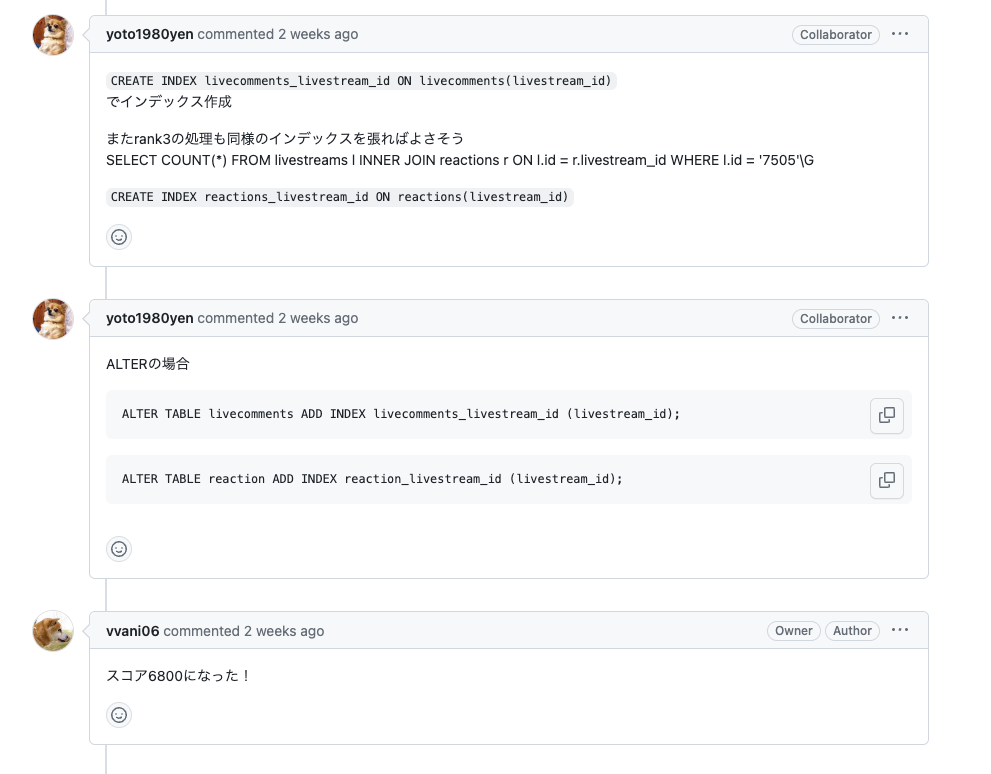

最終的に以下のインデックスを張って、スコアは 約9000点 となりました!
この後もPowerDNSのチューニングや、カーネルパラメータのチューニングを行い、最終スコアは 9,556 となりました。
17:30〜18:00 クロージング
事前の取り決めでも、この最終時点ではリスクを見て、強引な変更は加えないことを決めていました。
また、再試験のために、インスタンスの再起動もしておき、再起動後にベンチマークが叩けることを念の為確認しておきます。
最終的に1台は現状を保護し、2台は自由に検証出来るインスタンスと決めて、試したいことを時間いっぱいまで試し競技終了となりました。
振り返って
昨年に比べ、ボトルネックを把握しながらスコアを上げることが出来たので達成感がありました!
また、インデックスを張るだけでも性能向上が目に見えて分かり楽しめました!
途中アクシデントに遭遇しながらも、去年の知見を活かして大きく詰まることなく進められたのも良かったです。
アクシデントの対処がスムーズに出来たのは昨年違ったチームの混成だからこそだと思いました。
色んな知見が共有出来るので、チームをミックスしながら参加するのも楽しいです!
しかし、以下のように反省点も多かったです。
-
準備・演習不足
- せめてGithubリポジトリへの連携方法、当日の解析ツールのインストール方法は把握しておくべきだった。
- シェルスクリプトやAnsibleを用いて自動化しておくべきだった。
- 肝心のチューニング方法の手数が少なかった。
-
パフォーマンスチューニングに割けた時間が少ない
- ドキュメント読み合わせを丁寧にしすぎた。
- ドキュメントの読み合わせは丁寧に出来たので安心感はあったが、時間ロスは大きかった。
- 各自でさっと目を通し、重要そうなポイントに絞って読み合わせる方が効率的だったかもしれない。
- ドキュメント読み合わせを丁寧にしすぎた。
-
作業分担ができなかった
- 画面共有しながらほぼ同じ改善内容をモブプロで確認していたため、複数人参加の利点を活かせなかった。
次回に向けて
上記の振り返りも踏まえて、今度は以下を頑張りたいね、とメンバーと話し合いました。
- 事前演習・事前準備をしっかり行う
- 作業分担を行う
- 攻めた構成を試す
- 複数台構成
- DBサーバーの分離、アプリケーションサーバーの冗長化。
- 事前検証が重要なので、事前に演習しておく。
- ミドルウェアの追加
- 今回で言えば、PowerDNSの前段にdnsdistを設定するなど。
- 複数台構成
- ベンチマークのシナリオを読み解く
- 今回はDNS水責めのシナリオがポイントとなったため、ゲーム的な読みが出来るようにしたい。
さいごに
エンジニアとしてパフォーマンスチューニングは重要なスキルながらも、関われる機会は意外に少ないです。
アプリケーションエンジニアであればN+1の改善,アルゴリズムの改善、インフラエンジニアではミドルウェアのパラメータチューニング、分散構成etc...と改善手法も状況に応じて多岐に渡ります。
しかし、性能改善においては改善手法も当然ですが、ボトルネックの計測・分析の方法など前段に問われる知識が重要と改めて思いました。
そんな中、ISUCONは計測・分析・改善を自分たちの手で全て実践できるスキルアップにとても有効な場です。
参加して得るものは必ずあるので、ISUCON未参加でもし気になった方は、是非来年参加を目指してみてはいかがでしょうか。
例年参加枠の取り合いが大変ですが、一緒に頑張りましょう💪

より良く、より早く、より安全に、もっとハッピーに。「DevOps 自由と変化を創造する」をミッションとして、DevOps領域に特化したサービスを展開しています。 公式noteはこちら→note.com/devopslead
Discussion