はじめに
AWS IoT CoreからKinesis Data Streamsにデータを送る際、パーティションキーの設定を誤って同一の文字列にしていた為にホットシャードを発生させてしまったというお話をします。
前提
・mockmockから10万台分の位置情報を1分間隔で30分間、IoT Coreへ送信する負荷テストを行っていた(計300万件のデータ送信)
・IoT Coreで受信した情報をKinesis Data Streams→Lambda→DynamoDBの流れでデータを保存する

【IoT Coreの受信データ例】
{
"list" : [
{
"vin" : "TEST-100001",
"timestamp":"2022-11-01T10:10:00+09:00",
"lat":35.658278,
"lon":139.701611
}
]
}
Jsonの項目名: vinの値は「TEST-100001~TEST-200000」の間の値を時系列で1ずつ増やした値をIoT Coreへ送信します。
lat(緯度)とlon(経度)の値はmockmockの位置ジェネレータで生成して送信します。
パーティションキーとシャードの関係
パーティションキーは、ストリームにデータを送信するアプリケーション側で指定されます。
【IoT Coreの設定画面】

ストリーム先のKinesis Data Streams(以下、Kinesis)では、パーティションキーをハッシュ化してどのシャードに割り当てるかを決めます。そのため、パーティションキーの値が近似値であっても、異なるシャードに均等に分散してくれます。

同じパーティションキーのデータを受信した場合には、同じシャードにデータが送信されることで
- データ処理の順序を保証される
- 同じグループの処理が効率化できる
などのメリットがあります。
一方で、あるパーティションキーに対して大量のデータが集中してしまった場合、そのパーティションが割り当てられたシャードに過剰な負荷がかかり、ホットシャードが発生します。
今回設定していたパーティションキー vin の値は 「TEST-100001,TEST-100002,....TEST-199999,TEST-200000」 のように異なる値にしてIoT Coreへ送信していたため、Kinesis側でハッシュ化されうまくシャードにデータが分散されるものと思っていました。
発生した事象
AWS Management ConsoleのLambda関数の[モニタリング]タブからCloudWatchメトリクスを確認したところ、
「あれれ~?おかしいぞ~?」
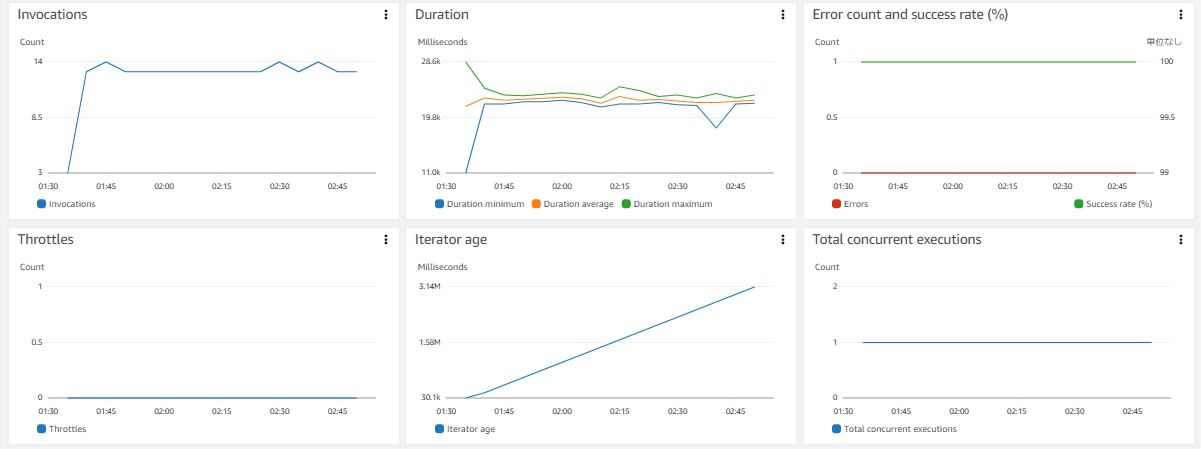
- Kinesisのシャード数を8、Lambdaのシャードあたりの同時バッチは1にしていたが、メトリクス
Total Concurrent executions(Lambda同時起動数)を確認したところ、Lambdaが1つしか起動していなかった。 - Kinesisがデータを受信してから、そのデータをLambdaに送信するまでの時間を表すメトリクス
IteratorAgeの値が増加し続けており、Lambdaの処理がまともに遂行できていないようだった。
CloudWatchの[ロググループ]からLambdaで生成しているログの中身も確認してみると、Lambda→DynamoDBへ書き込み(BatchWriteItem)が失敗した場合の戻り値UnprocessedItems を含むエラーログが大量に出力されていました。

原因
IoT Coreルールアクションのパーティションキーの設定が、JSON要素を参照する ${vin} ではなく vin になっていた。
→全レコードのパーティションキーが同一の文字列 vin になりホットシャードが発生。
対応
パーティションキーをランダムなユニークID ${newuuid()} に変更
newuuid()は、IoT Coreで利用可能な関数で、16バイトのランダムなUUIDを返すものです。
例: newuuid() = 123a4567-b89c-12d3-e456-789012345000
当初想定していた通りの設定にするならば、${vin} に変更するべきでしたが、ホットシャードの発生を体験し、今回構築しているサービスでは同じシャードにデータを送信するメリットよりも、シャードへの振り分けをランダムに行った方がメリットがありそうだ、ということになり ${newuuid()} を採用することにしました。
エビデンス
気になっていた全ての事象が無事解決したことを確認しました。


- メトリクス
Total Concurrent executionsの値が想定通りの値:8になり、シャードごとにLambdaが起動していることを確認。 - メトリクス
IteratorAgeの値が一定になり、順次Lambdaの処理を遂行できていることを確認。 - Lambdaが出力したエラーログが無いことを確認。
各設定値
最終的に採用した設定値を一部抜粋しています。
IoT Core
ルールアクション
| 項目 | 設定値 |
|---|---|
| アクション 1 | Kinesis Stream |
| ストリーム名 | location-stream |
| パーティションキー | ${newuuid()} |
Kinesis Data Streams
データストリーム名
| 項目 | 設定値 |
|---|---|
| データストリーム名 | location-stream |
データストリームの容量
| 項目 | 設定値 |
|---|---|
| 容量モード | プロビジョンド |
| プロビジョニングされたシャード | 8 |
| 書き込み容量 | 最大 8 MiB/秒、8,000 レコード/秒 |
| 書き込み容量 | 最大 8 MiB/秒、8,000 レコード/秒 |
Lambda
基本設定
| 項目 | 設定値 |
|---|---|
| メモリ | 256MB |
| エフェメラルストレージ | 512MB |
| タイムアウト | 1分 |
トリガー
| 項目 | 設定値 |
|---|---|
| ソース | Kinesis |
| ストリーム | location-stream |
| バッチサイズ | 100000 |
| バッチウィンドウ | 15 |
| シャードあたりの同時バッチ | 1 |
※当初バッチウィンドウの値を30にしていましたが、Lambda→DynamoDBへ書き込みが一割ほど失敗していた為に15に変更しました。
参考:変更前の荒ぶるメトリクス

DynamoDB
テーブル
| 項目 | 設定値 |
|---|---|
| テーブルクラス | DynamoDB標準 |
| 読み込み/書き込みキャパシティーの設定 | オンデマンド |
最後に
ホットシャードが発生した事例をなかなかのデータ量で体験できました。
どなたかの参考になれば幸いです。
以上、えみり〜でした|ωΦ)ฅ

Discussion