【基盤モデル:第一弾】OlmoEarthの紹介
はじめに
最近になって基盤モデルの重要性に気付き始め(今更感はありますが)、リモートセンシング分野における基盤モデルの理解を深めようと考えました。
リモセン分野においても既に多数の基盤モデルが登場していますが、すべてを網羅するのは時間的に不可能です。そこで、僕が業務で担当している農業分野に絞って学習を進めることにしました。
農業分野で特に注目されているのが「Galileo」と「Presto」です(他のモデルが優秀でないという意味ではなく、比較的新しいという理由からです)。
さらに、2025年には「OlmoEarth」という新しいモデルが発表され、Galileoとの詳細な性能比較も行われています。
そこで本シリーズでは、これら3つの基盤モデルについて紹介していきます。
今回はその第一弾として、OlmoEarthを取り上げます。
なお、僕はCV分野の専門家ではないため、間違いや不正確な記述があればコメントでご指摘いただけると幸いです。
概要
OlmoEarthは、Allen Institute for AI(Ai2)を中心とした研究チームが2025年に発表した、地球観測に特化した基盤モデルです。
このモデルは、複数の衛星画像(Sentinel-1/2、Landsat-8)とGISデータ(OpenStreetMap等)を組み合わせた自己教師あり学習により、様々な下流タスクに適用可能な汎用的な特徴表現を学習します。
OlmoEarthの最大の特徴は、Latent Masked Image Modeling of Linear, Invariant Token Embeddings(Latent MIM Lite) という新しい学習手法の提案です。教師あり学習と自己教師あり学習を一緒に行うような形です。この手法により、従来の地球観測基盤モデルが抱えていた訓練の不安定性や表現崩壊といった問題を解決しています。
性能面では、12の既存基盤モデルとの包括的な比較評価において優れた結果を示しています。具体的には、kNN/Linear Probingで24タスク中15タスク、Full Fine-tuningで29タスク中19タスクにおいて最高性能を達成しました。
また、Nano(1.4Mパラメータ)からLarge(300Mパラメータ)まで4つのモデルサイズが提供されており、用途や計算リソースに応じた選択が可能です。
コアとなるアプローチ
OlmoEarthの中核となるアプローチは、複数の衛星画像とMapsを統合的に学習しながら、推論時は衛星画像のみで動作するという点にあります。
一般的に、機械学習では学習時と推論時で同じ種類の入力データを使用する必要があります。しかしながら、Mapsは、時間とともに変化し、常に更新されているわけではありません。常に最新のMapsが入手できる状況であれば、衛星画像を使って状況把握・予測する必要はなくなります。つまり、推論時に最新のMapsが利用できる可能性は非常に低いです。
このような実務の文脈において、OlmoEarthが採用する「学習時には衛星画像とMapsの両方を使用し、推論時は衛星画像のみを使用する」というアプローチは、非常に実用的であると言えます。
モデルの特徴
OlmoEarthの全体像は、以下となります。

OlmoEarthの論文より
ざっくり説明すると、入力データをトークン化し、マスキングを適用して、2つの損失関数を使うことで、空間的・時間的・モダリティ的な特徴を獲得する形です。
データ
OlmoEarthの事前学習には、世界各地の285,288サンプルが使用されています。
サンプルの定義
OlmoEarthにおける「1サンプル」とは、特定の地理的位置(2.56km×2.56km)における1年分のデータを指します。
サンプリング方法
サンプリングは、OpenStreetMapの120カテゴリ(道路、建物、農地など)を選定し、各カテゴリを含む2.56km×2.56kmのタイルを候補として、各カテゴリから最大10,000タイルをランダムに抽出する形で行われています。各サンプルの時間範囲(1年間)は、2016年1月から2024年12月の間で設定されています。
サンプルの構造
各サンプルは、衛星画像とMapsで構成されています。
衛星画像
以下の衛星画像が使用されています:
- Sentinel-1:SAR(合成開口レーダー)
- Sentinel-2:光学マルチスペクトル画像(13バンド)
- Landsat-8:光学マルチスペクトル画像
全てのデータは、10m解像度に統一的にリサンプリングされます。
Maps
以下のGISデータが使用されています:
- WorldCereal:グローバル作物マップ
- WorldCover:土地被覆分類
- OpenStreetMap:地理的特徴(道路、建物等)
- Cropland Data Layer(CDL):作物タイプ
- SRTM:標高データ
- Canopy Height Map:樹冠高
Bandsetの概念
サンプル内の衛星画像(Sentinel-2とLandsat-8)は、さらに 「Bandset」 という単位でグループ化されます。Bandsetとは、同じ衛星の異なる元解像度のバンドをまとめたグループです。
- Sentinel-2:3 Bandsets(解像度が10m、20m、60mのバンドをそれぞれグループ化)
- Landsat-8:2 Bandsets(解像度別にグループ化)
全てのバンドは最終的に10m解像度にリサンプリングされますが、元の解像度ごとにBandsetとして分類されます。
明記されていませんが、Sentinel-1とGISデータにはBandsetがなく、1つのサンプルが1つのデータとしてみなされます。
トークン化と埋め込み
OlmoEarthはViTと同様に、入力データをパッチに分割してトークンに変換します。
トークン化
各サンプルの衛星画像とMapsは、まず小さなパッチに分割されます。その後、各パッチは線形投影を通じてトークンに変換されます。
OlmoEarthでは、Flexible Patch-Embedding Layerを採用しています。これにより、パッチサイズを可変にできます。訓練時にパッチサイズをランダムに変化させることで、様々なスケールの特徴を学習します。
3種類の埋め込み
トークン化された各パッチには、以下の3種類のEmbeddingが追加されます:
- 2D Sincos Positional Embedding(空間位置)
- Sinusoidal Temporal Embedding(時刻情報)
- Learnable Modality Embedding(モダリティ識別)
これにより、各トークンは「どこで・いつ・何のデータか」という情報を持つことになります。
2D Sincos Positional Embedding(空間位置)
パッチの2次元空間的な位置(x, y座標)を、正弦・余弦関数による固定パターンで表現します。2次元での位置埋め込みなのは、衛星画像・Mapsともに2次元の画像データだからですね。
Sinusoidal Temporal Embedding(時刻情報)
各パッチがどの時刻(月)のデータかを、正弦波パターンで表現します。最大12タイムステップ(月次)に対応しています。季節性などの周期的パターンや、時刻間の関係性の把握を可能にするためです。
Learnable Modality Embedding(モダリティ識別)
各パッチがどのデータ(Sentinel-1/2、Landsat-8、各Maps等)から来たかを識別するための埋め込みです。モダリティごとの特性やモダリティ間の関係性の把握を可能にするためです。
マスキング戦略
上記トークンに対して、マスキング戦略が適用されます。ただし、個々のトークンに対してランダムにマスキングするのではなく、Bandset/Maps単位でマスキング戦略を決定し、そのBandset/Mapsに属する全トークンに適用します。
マスキングのカテゴリ
各Bandsetは、以下の4つのカテゴリのいずれかに分類されます:
- Not selected:このサンプルでは使用しない
- Encode only:Bandset内のトークンをランダムマスク。マスクされていないトークンをエンコーダーへ入力
- Decode only:Bandset内の全トークンをマスク。デコーダーの予測目標として利用
- Encode and decode:Bandset内のトークンをランダムマスク。マスクされていないトークンはエンコーダー入力、マスクされたトークンはデコーダーの予測目標として利用
Mapsの扱い
Mapsは、常に以下のいずれかに分類されます:
- Not selected:使用しない
- Decode only:予測目標のみ
Mapsは絶対にエンコーダーへの入力には使用されません。これは、推論時にはMapsを使わず衛星画像のみで推論できるようにするためです。
損失関数
OlmoEarthは、2つの異なる損失関数を組み合わせて学習を行います。これにより、局所的特徴と大局的特徴の両方を効果的に学習します。
Patch Contrastive Loss
デコーダーが予測したトークンを、予測目標のトークンと比較学習します。具体的には、予測トークンを予測目標トークンに似せつつ、他のパッチの目標トークンとは異なるようにする、という分類問題として学習します。
マスキング戦略と同様に、この比較学習も同じBandset内のみで行われます。
なぜなら、異なるBandset間ではデータの特徴が大きく異なるため、トークンの区別が容易になってしまいます。一方、同じBandset内では特徴が類似しており、その中で学習を行うことは本当に学習すべき特徴を学ぶことに繋がります。
Instance Contrastive Loss
Instance Contrastive Lossは、サンプル全体の大局的な特徴の獲得を目指したものです。
同じサンプルに異なるマスキングを2回適用し、それぞれをエンコーダーで処理した後、出力された全トークンを平均プーリングし、互いの大局的特徴に対して比較学習を行います。
そうすることで、全モダリティ・全タイムステップ・全位置の情報が集約された大局的な特徴を学習することができます。
実験(性能検証)
以下の2つの方法で性能検証を行っています。
- kNN/Linear Probe(固定エンコーダー)
- Full Fine-tuning
比較した基盤モデル
2つの検証方法それぞれで比較した基盤モデルが異なりますが、使用された基盤モデルの一覧は以下となります。
- Anysat
- Clay
- CopernicusFM
- CROMA
- DINOv3
- DINOv3 Sat
- Galileo
- Panopticon
- Presto
- Prithvi v2
- Satlas
- TerraMind
- TESSERA
使用したデータセット(ベンチマーク)
以下のベンチマークを使用し、合計で24のkNN/Linear Probeタスクと29のFull Fine-tuningタスクとなっています。
包括的なタスク
- m-bigearthhmnet: マルチラベル土地被覆分類
- m-so2sat: 都市土地利用分類
- m-brick-kiln: レンガ窯の検出
- m-forestnet: 森林タイプ分類
- m-eurosat: 欧州の土地利用分類
- m-cashew-plant: カシューナッツ農園の検出
- m-SA-crop-type: 南アフリカの作物タイプ分類
分類タスク
- BreizhCrops: フランスの作物タイプ分類(時系列)
- CropHarvest: グローバルな作物/非作物分類(時系列)
セグメンテーションタスク
- PASTIS: パーセル単位の作物セグメンテーション
- MADOS: オイル流出と海洋ごみのセグメンテーション
- Sen1Floods11: 洪水検出セグメンテーション
結果
総じてOlmoEarthが良いという結果になりました。具体的には、kNN/Linear Probingで24タスク中15タスク、Full Fine-tuningで29タスク中19タスクにおいて最高性能を達成しました。ただし、サイズが異なる4つのモデルの組み合わせでの達成という点には留意が必要です。
【kNN/Linear Probeでの結果】
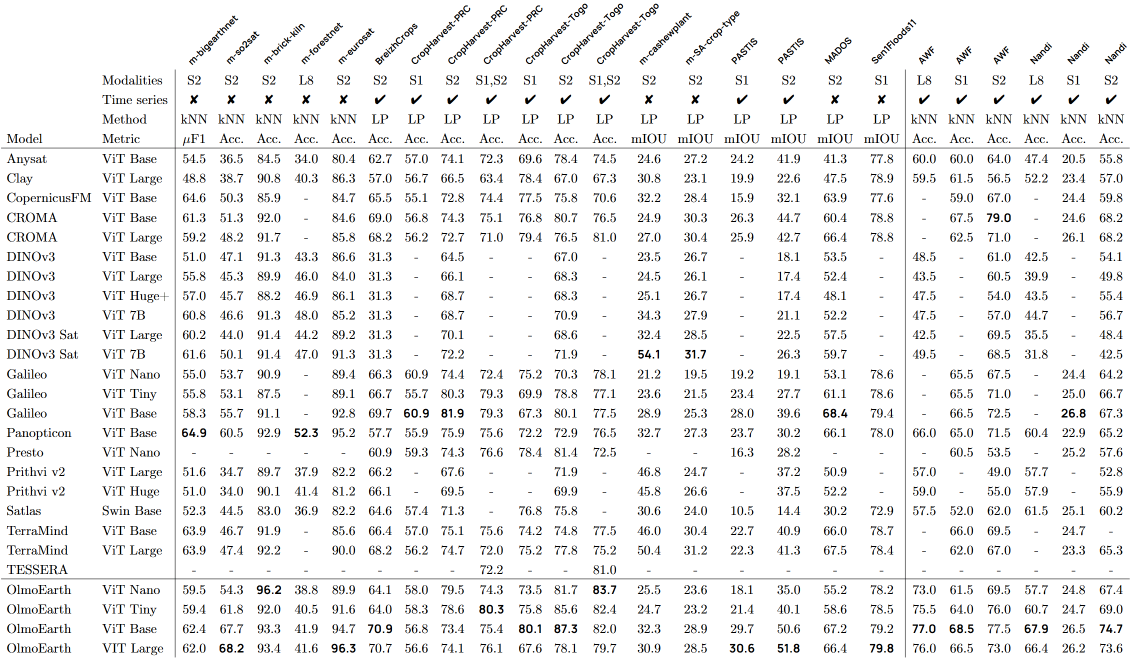
OlmoEarthの論文より
【Full Fine-tuningでの結果】

OlmoEarthの論文より
今後
今後は、気候・気象データや非GISデータを追加していく予定とのことです。
まとめ
他の基盤モデルのアーキテクチャを知らないため、OlmoEarthの独自性がどの程度のものなのかは判断できませんでしたが、面白いアーキテクチャだと感じました。今後は、GalileoとPrestoとの詳細な比較を行っていきたいと思います。
また、最近登場した「DINOv3」「DINOv3 Sat」との性能比較されており、多くのタスクでOlmoEarthが上回っていた点は興味深かったです。
全体性能としては、データセットにかなり左右されるなぁという印象を受けました。Full Fine-tuningであっても、例えば同じ土地被覆分類というタスクであっても、m-bigearthhmnetが72.4%、m-so2satでは68.6%、m-eurosatでは98.7%と、データセット間で大きな差が見られます。また、タスクによって得意・不得意があり、特に作物分類では課題感が残る印象を受けました。
始めて基盤モデルを読み解くことをしたんですが、知らない手法が出てきたりしたので理解するのが大変でした。また、それを記事という形で整理するのも苦労しました(論文読む~記事作成まで約1日半)。ただ、記事を執筆していると、「あれ?ここどうなってたっけ?」と理解できているようでできてなかった点が見えてきたりして、より深ぼって理解できたので良かったです。
皆さんの参考になれば幸いです。
参考文献
Herzog, Henry, Favyen Bastani, Yawen Zhang, Gabriel Tseng, Joseph Redmon, Hadrien Sablon, Ryan Park, et al. 2025. “OlmoEarth: StableLatentImageModeling for Multimodal Earth Observation Team OlmoEarth.”
Discussion