こんにちは、Communeでデータサイエンティストをしているひぐです!
GWを利用して個人開発でGoogle Cloudを活用して検索システム構築に試みました。
まだ完成には至ってないのですが、実装時の学びや失敗、勉強方法などを紹介したいと思います。
実装したもの
自分がほしいと思うものを作る方がモチベーションにもなると考えたので、テックブログを検索できるWebサービスを考案しました。将来的には、LLMでタグを付与し、パーソナライズやファジーな検索ができるようになればいいなと思っています。
画面のイメージ(figma)
今回のブログでは、このWebサービスの検索バックエンドの実装に焦点を当てます。データソースとしては、公開されているテックブログのRSSを利用しました。
検索システムに必要な要件・コンポーネント
検索システムを構築するには、おおよそ以下のコンポーネントが必要です。これらのコンポーネントがあることで、ユーザーの様々なニーズやコンテキストに応じた検索クエリに対して、適切な検索結果を返すことができます。

- クエリプリプロセッサ: クエリの前処理を行うコンポーネント。検索エンジンが適切に検索結果を返せるように、入力クエリを分かち書きしたり、ビジネスロジックで、条件を付与したりします。
- クエリポストプロセッサ: クエリの後処理を行うコンポーネント。機械学習によるランキングの並び替えや、ビジネスロジックによるフィルタ(閲覧権限など)を行います。
-
検索エンジン: 前処理された検索クエリを元に、検索結果を返すコンポーネント。フルマネージドサービスや、プリプロセッサ・ポストプロセッサを内包しているサービスなど、多様な種類があります。
- ex) Elasticsearch, Solar, Aloglia, etc..
- インデクサ: データを検索エンジンに格納する機構。データの取得、変換処理、格納までを責務に持ちます。
他にもユーザに良い検索体験を継続的に提供し改善するには、検索結果をわかりやすく表示し、フィルタリングやソートが出来るUIや、検索結果を評価するためにログ機構等が必要でしょう。
さらに、検索体験を向上させるために、クエリ作成を支援するクエリサジェスチョン機能の導入も効果的です。ユーザーが検索ボックスに入力を始めると、過去の検索履歴や人気のキーワードをリアルタイムで提案することで、ユーザーは最小限の入力で目的の情報にたどり着くことができます。

*クエリサジェスチョンの例: Googleより引用
各コンポーネントの責務や検索システムの改善方針は書籍:検索システム 実務者のための開発改善ガイドブックに詳しく記載されています。
Google Cloud上での実装方針
先の章にあるように検索基盤は多くのコンポーネントによって構成されています。今回のRSS検索サービスはそれらのコンポーネントを図にある通りに配置・実装しました。
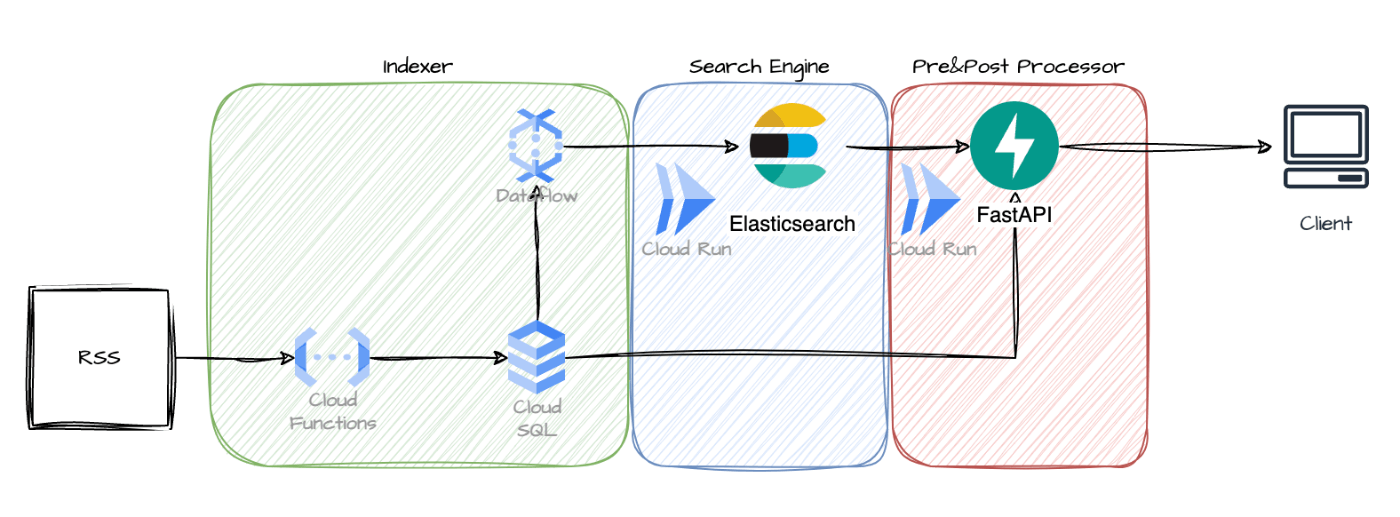
データのフロー↓
- Indexerとして、Cloud FunctionでRSSからデータを取得し、Cloud SQLに格納
- Cloud SQLのリードレプリカからDataflowでデータを読み取り、Elasticsearchに同期
- ElasticsearchをCloud Run上で起動し、別のCloud Run上のFastAPI経由でクライアントに検索結果を返す
a. このAPIでプリ/ポストプロセッサとして、検索エンジンに渡すクエリを処理することができます。
以下の要件を考慮したうえで、この実装構成にしています。
疎結合
RDBのリードレプリカからデータパイプラインでデータを伝搬させることで、バックエンドと検索のコードの共存せずに実装できるので、疎結合に保つことができます。
また、インデクサとプリプロセッサ・ポストプロセッサもアーキテクチャ上疎結合になっています。
開発しやすさ
検索のコンポーネントの単位とコンピューティングリソースの単位をなるべく一致させることで、各コンポーネントごとの改修・改善をしやすくしています。
同期頻度と将来的なスケーラビリティ
RDBとElasticsearchのデータ同期頻度が高いほどユーザー体験として望ましい物になりますが、Dataflowはバッチ処理とストリーミング処理の両方に対応しているため、将来的にリアルタイム更新が必要になった場合でも低コストで移行できます。
また、Dataflowはオートスケールし、高スループット・低レイテンシーを実現できるので、データ量が増えてもデータ不整合なく同期可能です。
※補足: Google Cloudサービスの簡単な説明
- CloudSQL: Google CloudでマネージされているRDBサービス(MySQLを利用)
- Cloud Function: スクリプトと依存パッケージ一覧(main.py + requiremnt.txt)だけで実行できるFaas(Function as a service)
- Cloud Run: Dockerfileで起動するフルマネージドなコンテナコンピューティングサービス
- Dataflow: 高スループット低レイテンシーを実現できるApache beamをベースにしたデータパイプラインツール
各コンポーネントの実装と詰まったこと
各コンポーネントで実装したことをそれぞれ紹介します。
Cloud SQL
RSSのデータを格納するためのデータベースとして利用しています。個人開発で格納するデータも少ないので、安くするために下記の記事を参考に、最小構成で実装しています。
詰まったポイント
Cloud Function第二世代をCloudSQLと接続する場合は、Cloud Runのリビジョンを設定する必要があり、これを見逃してしまっていました。
また、ローカルで接続を検証する場合はProxyを利用して、認証を通す必要があります。このあたりも初手では気づけなかったので苦戦しました。
Cloud Function
RSSのデータをRDBに挿入する処理を実装しました。
feedparserでRSSのデータを取得し、pydanticでRSSのデータをモデル化、SQLAlchemyでRDBにデータを格納するというフローを踏んでおり、スキーマの不整合を防ぐようにしています。
実運用時には、Cloud Schedulerなどを使ってRSSの更新に合わせて定期的に実行する必要があります。
省略...
class ArticleModel(Base):
__tablename__ = "articles"
id = Column(Integer, primary_key=True, index=True)
title = Column(String(255), index=True)
link = Column(String(1024), unique=False, index=True)
published_date = Column(DateTime)
summary = Column(Text)
...
def parse_feed(rss_url: str) -> List[Article]:
response = requests.get(rss_url)
feed = feedparser.parse(response.text)
articles = []
for entry in tqdm(feed.entries):
try:
article = Article(
title=entry.title,
link=entry.link,
published_date=entry.published,
summary=entry.summary,
)
articles.append(article)
except Exception as e:
print(f"Error: {e}")
return articles
def create_articles(rss_url: str, db: Session):
articles = parse_feed(rss_url)...
for article in articles:
db_article = ArticleModel(**article.model_dump())
db.add(db_article)
db.commit()
@functions_framework.http
def main(request):
rss_url = "https://yamadashy.github.io/tech-blog-rss-feed/feeds/rss.xml"
db = next(get_db())
create_articles(rss_url, db)
return "Articles created successfully"
詰まったポイント
CloudSQLと接続できるようにするには、Cloud Funcitonに接続する権限を持ったサービスアカウントを渡す必要があります。
また、初期設定のタイムアウトがかなり短いということを知らなかったため(30s?)、なかなかエラーの原因を気づけなかったです。
Dataflow
RDBに接続してSQLクエリで必要なデータを取得した後、ElasticsearchのPython SDKを使ってデータを挿入しています。
実運用時は、クエリでフィルタリングして差分更新するなどの工夫が必要そうです。また、RDBに直接接続する現在の実装だと、並列化した際にコネクションがロックする可能性があるため、Pub/Subなどを間に挟む必要があるかもしれません。
...
class WriteToElasticsearchFn(beam.DoFn):
def __init__(self, batch_size):
self.batch_size = batch_size
self.buffer = []
def process(self, element):
article = NewsArticle(
...
)
self.buffer.append(article)
if len(self.buffer) >= self.batch_size:
self.flush()
def finish_bundle(self):
self.flush()
def flush(self):
bulk(ed.connections.get_connection(), (d.to_dict(True) for d in self.buffer))
self.buffer = []
...
def run(argv=None):
options = PipelineOptions()
with beam.Pipeline(options=options) as pipeline:
sql_data = pipeline | "ReadFromCloudSQL" >> beam.Create(
read_from_jdbc(table_name)
)
# レコードをJSONに変換する
json_data = sql_data | "ConvertToJson" >> beam.Map(
lambda row: row_to_dict(row, use_cols)
)
# Elasticsearchにデータを書き込む
_ = json_data | "WriteToElasticsearch" >> beam.ParDo(
WriteToElasticsearchFn(batch_size=100)
)
if __name__ == "__main__":
run()
詰まったポイント
DataflowはBigquery to ES等のテンプレートが公開されているため、こちらを使えば容易に実装可能かと思っていたのですが、Javaのテンプレートしかなかったので、利用を断念しました。
(Javaに慣れておらず、手元の検証が難しそうだったため)
Cloud Run
Elasticsearchをホスティングするために利用しています。こちらは、単純にElasticsearchをコンテナで起動し、ポートを開放しているだけです。
#FROM docker.elastic.co/elasticsearch/elasticsearch:8.13.1
FROM elasticsearch:8.13.0
RUN bin/elasticsearch-plugin install analysis-kuromoji
USER root
RUN apt-get update && apt-get install -y procps && rm -rf /var/lib/apt/lists/*
COPY elasticsearch.yml /usr/share/elasticsearch/config/elasticsearch.yml
RUN mkdir -p /usr/share/elasticsearch/data
RUN chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data
USER elasticsearch
EXPOSE 9200
EXPOSE 9300
CMD ["elasticsearch"]
企業で利用する場合は、Elastic Cloudも検討に上がるかと思います。(95ドルからなので検討せず)
詰まったポイント
elasticsearch.yamlでコンテナ外部からHTTPでアクセスできるように設定を書く必要がありました。
node.name: elasticsearch
discovery.type: single-node
cluster.name: es-docker-cluster
xpack.security.enabled: false
http.port: 9200
network.host: 0.0.0.0 # コンテナ外部からアクセスできるように
http.host: 0.0.0.0
また、手元のMacBookでビルドしたDocker imageをArtifact Registry経由で利用しようとすると、アーキテクチャの差異でエラーになったため、Cloud Buildを利用しました。
steps:
- name: "gcr.io/cloud-builders/docker"
args:
[
"build",
"-t",
"us-central1-docker.pkg.dev/.../my-repo/elasticsearch:latest",
".",
]
- name: "gcr.io/cloud-builders/docker"
args:
[
"push",
"us-central1-docker.pkg.dev/.../my-repo/elasticsearch:latest",
]
開発した上での学び
実際に開発することで様々な気づきを得られました。
まず、当たり前ですが、サービスを細かく分割するほど高度な条件での運用が可能になりますが、その分設定すべきオプションが大幅に増加することを改めて実感しました。(ex.ネットワークの設定、ロールの付与、マシンスペック,etc.)
慣れていないと、サービス同士を繋げるのすら苦戦を強いられます。😅
個人開発においては、Google Cloud Virtual Machineなどマネージドなレイヤーが薄いコンピューティングリソース+Docker composeによる構成などで十分かもしれません。
また、各サービスの用途については、他のブログを参考にすることであるレベルの理解は得られますが、実運用に耐える設計を行うには、さらに深い知識が必要だと気づきました。例えば、オートスケールの幅やリトライ機構などを活用した冗長な構成や、料金体系に沿った適切な構成などが求められます。
一方で、様々なGoogle Cloudサービスの特性を理解しておくことで、個人開発したいものが出てきた際に、各コンポーネントをどのように切り分け、どのサービスに落とし込んで作るかのイメージが湧くようになりました。👍
開発プロセスの面では、基本的にローカル環境で完全に動作する状態にしてからデプロイするのが効率的だと学びました。また、今回の実装ではいくつかのサービスを組み合わせましたが、Cloud Runのマルチコンテナ構成を活用することで、よりシンプルなアーキテクチャにできる可能性があります。
Google Cloudの勉強方法
最後にこれらのGoogle Cloudの知識を身につけた手順を記載します。基本的には、Google Cloudの認定資格の公式資料をもとに全体感を掴みました。
ETLの流れやDataflowなどのデータパイプラインツールはData Engineeringの教材から、Cloud Run, Cloud Functionsなどのコンピューティングリソースや、Google Cloudを学ぶ上で前提となるIAMなどはCloud Engineerの教材から学びました。
教材の中でも特にとっかかりやすい動画のパートだけをみています。
実際に動かす際は、各サービスのクイックスタートを見ながら進めました。サービスアカウントに必要な権限の付与など、詰まりやすいポイントが抑えられているので、他のサービスを触る際も必ず参照しようと思います。例↓
さらに、社内の詳しい方に壁打ちしてもらいながら構成を決めました。具体的な構成を決める上では、いくつかの企業のアーキテクチャに関するブログを参考にしました。
まとめ
今回、個人開発で検索システムを実装してみて、Google Cloudの基本的なサービスの使い方や、検索システムを構築する上での考慮点などを学ぶことができました。まだまだ検証不足な部分もありますが、実務での検索システム改修に活かせる知見が得られたと思います。
また、所感として、検索システムを構築する場合、体験としては検索結果を返すだけでなく、クエリ構築のための補助やフィルタ・ファセットの用意などが必要ですし、辞書・アナライザー・マッピング・Dockerfileなど多様な設定を管理しなくてはならず大変だな、、、と改めて感じました。😂
参考資料
他社の検索基盤実装事例
Google Cloudに関する情報

Discussion