バックエンドのスキーマ変更により、データパイプラインが突然壊れてしまうかもしれない、どのデータチームも、こうした不安を抱えているのではないでしょうか?
私たちの組織でも同じ課題を感じていました。CI/CDを活用した、データパイプラインが壊れない仕組みを認知負荷の少ないシンプルな運用で作れたので、そのアイディアをご紹介したいと思います!
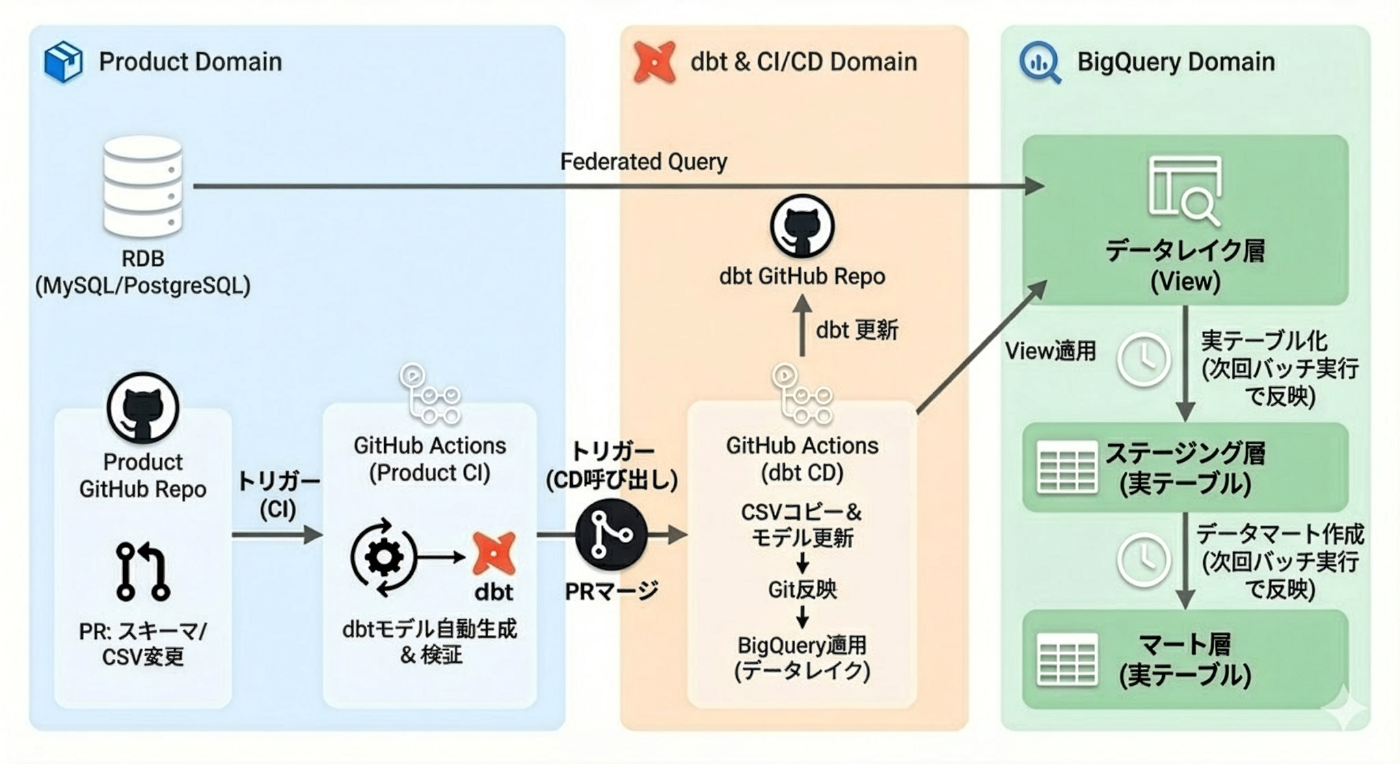
今回お話するデータ基盤の全体的なアーキテクチャ図は、このようになっています
なお、本記事は、以下のアドベントカレンダーの8日目として参加しています 🎄
発生していた問題
バックエンドエンジニアによるスキーマ変更のたびに、以下のような問題が繰り返されていました
本番リリース時に初めて気づく
変更がデータパイプラインに影響するかどうかは、実際にリリースされるまで不透明です
緊急対応が必要になる
日中のリリースで変更を検知してから、データチームが急いで修正し、その夜間処理までにリリースするという対応が必要になるヒヤリハット事例がありました
コミュニケーションコストが高い
スキーマ変更のたびに、どのテーブルが影響を受けるのか、どういった目的や使い方をする列であるかを確認するやり取りが発生していました
安易にリファクタリングできない
「このカラムは重要な分析に使われているのだろうか」という不確実性があり、バックエンドエンジニアが安心してリファクタリングを進められません
また、影響を確認するためにdbt環境を構築する必要があり、セットアップのコストも無視できません
仕組み化による期待できる改善
こうした課題を解決するために、複雑な仕組みを作ってしまうと運用が回りません
その橋渡しとなるインターフェースをシンプルな形式とすることで、長期的に続けられる仕組みを考案しました
影響を事前に検知できる
変更時に自動的に依存関係が検査され、どの分析に影響するかが明確になります
並行してリリース可能になる
修正と変更を同時にリリースでき、緊急対応が不要になります
透明性が高まる
どのテーブルやカラムがどの分析に使われているかが可視化され、スムーズなコミュニケーションが実現します
バックエンドエンジニアによるdbt環境構築不要
データチーム側で検査の仕組みを整備することで、バックエンドエンジニアがdbtの環境を構築する必要がなくなります
変更の影響は自動的に検知され、PRの結果にpass/failという形で確認できます
チーム全体で継続的にデリバリーできる
壊れてしまうかもしれないという不安を取り除き、非同期開発を進められ、QoL向上につながります
特徴
バックエンドエンジニアは、スキーマ変更時にcsvファイルへのメタデータ更新を行うだけで、dbtを用いたデータパイプラインの検証とBigQuery環境への反映が自動的に安全に実行される仕組みです
この裏側では次の図のように、CIとCDの各フェーズでGithub Actionからdbt Coreを実行します
- CIでは、下流データパイプラインへの破壊的変更がないことを事前検証する
- dbt run --empty コマンドで、実データは扱わずに、スキーマのみのテーブルを用いてクエリがすべて通ることをテストする
- クエリが通らない場合は、影響しないように依存を解消しておき、上流テーブルの差し替えができる状態を先に作る
- CDでは、スキーマ変更に伴うメタデータの更新を整合性を保ちながらデプロイする
- csvファイルを元に、pythonスクリプトからdbtモデルを自動生成して、dbt buildコマンドで本番反映を行う
- 本番反映の順序としては、削除系を先に反映して参照されなくしてからRDBの変更を行い、
- その後に、追加したカラムへの参照をBigQuery側のview定義にも適用する

メタデータはdbt seedで取り込めるCSV形式で管理し、dbt snapshotで履歴管理をしています
TypeScriptのDBスキーマ定義を拡張する案も検討しましたが、採用しませんでした。理由は、ライブラリの仕様変更や、将来的にライブラリ自体が変更される可能性があるからです。こうした不確実性に依存することは、数年先にリスクとなる可能性が高いため、独立した形式で管理する方が堅牢です。
なお、pythonスクリプトを用いてcsvファイルからdbtモデルを作る際に、これまで手動で行っていた次の処理を自動実行しています。
- オリジナルのRDBスキーマをfederatedクエリ経由で解析する
- RDB側のデータ型のBigQuery互換の型へ自動変換
- dbtモデルのContractと呼ばれる機能のconstraintsやカラムコメントに自動指定
- PrimaryKey情報
- 外部キーの情報
- ユニーク制約
- not null制約
CSVファイルの役割
どのような形式のメタデータを利用しているか、基本仕様について説明します
新しい列やテーブルが増えた際に、次の要件を満たすメタデータを付与できているか自動的にCIでチェックしています
- テーブルとカラムそれぞれの説明を付与できていること
- 取り込むべきでないテーブルを指定できること
- 列へのフラグ指定で、ステージング層から先の自動生成したいdbtモデルに利用するか指定できること
こうして、データレイク層と、ステージング層、および他プロダクト間のAPI的な連携に利用するカラム用の外部提供モデルをpythonスクリプトで自動生成しています
メタデータ管理
バックエンドエンジニアがスキーマを変更する際、2つのCSVファイルでメタデータを管理します
これらのファイルを更新するだけでデータパイプラインへの反映ができます
ファイル構成
bq_sync_tables.csv :テーブル単位の定義
- テーブル名
- テーブルの説明
- インポート対象から除外するかを指定
bq_sync_column_descriptions.csv :カラム単位の定義
- テーブル名、カラム名
- カラムの説明
- サニタイズ方法(機密情報など、値を置換する場合)
- プロダクト間連携用のフラグ
更新方法
Prisma側でのスキーマ定義更新は従来通り行います
新しいテーブル追加時は両ファイルを更新し、既存テーブルへのカラム追加時はカラム定義ファイルのみを更新します
削除時は、csvの該当行を削除するだけです
整合性の自動チェック
CIのステップで check-db-csv.ts というTypeScriptスクリプトが実行され、DBとCSVファイルの整合性が自動検証されます。
具体的には以下の2方向のチェックが行われます。
- DB → CSV:BigQuery上に存在するすべてのテーブル・カラムがCSVに定義されているか
- CSV → DB:CSVに定義されているテーブル・カラムがBigQuery上に実在するか
定義漏れや不整合があればCIで検出され、PRがマージできない状態になるため、常に同期の取れた状態を保つことができます。
まとめ
次のシンプルな要素を掛け合わせることで、とても強固な仕組みが作れました。
メタデータが整理されて連携されることで、AI活用にも皆の生産性向上に繋がる施策となったと確信しております!
- CSVファイルでメタデータ管理
- CI/CDで抜け漏れ検知、整合性を継続的に担保する
- RDBのスキーマ情報を用いたdbtモデルの自動生成Pythonスクリプト
こちら、Enabling teamと、Data Teamのコラボレーションの取り組みで実現しています!
続編となる12/20の回では、複数レポジトリにまたがるCI連携をどのように行ったか紹介予定です!お楽しみに♪
皆で知の高速道路に乗ることで、2026年も様々なプロダクト開発がスムーズに進捗するよう、データプラットフォーム整備を引き続き頑張っていきます
宣伝
強力な仲間の力で自身の力をブーストさせて自己成長したい方、ジョインしませんか?
コミューンでは、データ系人材も募集しております!

Discussion