こんにちは、Communeでデータエンジニアをしているよしけんです。2024年にトレジャーデータから転職してきました。
データ分析に関わる方なら、過去のある時点から現在までの時系列を軸に集計したことがあると思います。その裏側には、データベースのスナップショットを溜め込んでいるテーブルがあります。
履歴テーブルにはつきものの、何らかの不具合で欠損しているタイミングのデータを使おうとするが存在せず、意図せず集計値がnullになるといったトラブルを引き当てた経験のある方も多いのではないでしょうか?
dbt snapshotとは何か?
dbt snapshotを使うと、変更があった行だけが記録されていくSlowly Changing Dimension Type-2方式が簡単に使えるので、変更差分の記録が無ければその前の状態が継続する、データが欠損することはない世界に移れます。おまけに変更されたレコードが少なければデータサイズが大幅に小さくなる所も良い点です。
SCDの包括的な説明は、下記の記事が大変参考になるのでおすすめです。
新しい物を使いたくても、ほとんどの読者の方は既存のテーブルを持っており、マイグレーションする必要がありますよね。digdagのsession_dateの概念との互換性を保ちたいユースケースもあるでしょう。
SCD Type-2形式へのデータ移行をどのように進めたのか、まずは移行元のデータ構造から説明します。
移行元のテーブル構造
毎日全行を追記しても、ストレージコストを圧縮できて便利なBigQueryのtable snapshot機能を使っていました。
- 毎日取り込んだテーブルをBigQueryのtable snapshot機能を用いて蓄積します
- BigQueryのコンソール画面では一つのテーブルのように見えます
- 下記で定義したview tableを用いて、履歴テーブルとしてアクセスできます
select
date_sub(parse_date('%Y%m%d', _table_suffix), interval 1 day) as PartitionDate,
*,
from salesforce_snapshots.salesfoce_Account_snapshots*
しかし、使っていくうちに、いくつかの問題が明らかになってきました。
dbt snapshotへの切り替えを心に決めた理由
小さなメリットよりも、下記のようなデメリットの方を大きく感じるようになりました。
- BigQuery table snapshot機能は差分だけを保持して圧縮しているので、SELECT性能が遅い
- 日々の運用や、アドホックに見るダッシュボードなどで参照する際に30秒ほど待たされる
- つまり、データ利用者側目線として体験が悪い
- 新しいテーブルを足した時に過去と型が違うと、INSERTに成功はするが、後で参照しようとする時にクエリが失敗する
- embulkの型類推に失敗し、型の非一貫性が生じることでそうなる
- 全てSTRING型にすれば回避できるが、データ元の型をそのまま使いたい
- エラーとならないようなさまざまな工夫をSQLで行う事は運用負荷とコードの負債となる
- 本来意図するテーブルの型に直すには、過去の日次テーブル全てを作り直して洗い替えする必要がある
- 後段のデータ処理が、取り込みに失敗した欠損日があることは想定していない事による不具合が度々起きる
- 欠損日は前の日のデータで自動的に補完して欲しい
- とはいえ、全ての処理でそのケアをするのはコードのクリーンさを害する
- そもそも、不具合が起きないデータ補完を行う書き方を意識させるのは本質的ではない
- そのレコードがいつ変化したかの調査に時間が掛かる
- いつレコードが変更されたか、すぐ追跡できる形式のニーズがある
差分検知方法の選び方
導入すると決まれば、どの差分チェック方式が適しているかの適性チェックを行います。
まずは一番正確なstrategy=check, check_cols=allで検知される行数が入力行に対してどれほどあるかを複数日、計測します。それと同じ行数となるカラムをうまく選択できれば、strategy=timestampが使えるでしょう。
ただ、check_cols=allでチェックしたときに元のレコード数に近ければ、行数の削減はあまり期待しない方が良いでしょう。
salesforceでは、ページにアクセスしただけで更新されるLastViewedDateカラムや、毎日結果が変化する数式を組み込んだカラムを作れます。そういうものがあると全行を差分レコードとして取り込むことになります。
strategy=timestamp
シンプルなstrategy=timestampが合う条件は下記の通りです。
- 1日に1回またはそれ以上の頻度でsnapshotを取る
- 行に変更があれば必ず
updated_atで指定したカラムの更新が保証されるテーブル - 行が削除されたら、
dbt_valid_toがnullから実行時刻に更新される(過去日にはならない)
元データにて、更新日時の変更をトリガーに何かが動く仕組みが連動していることもあると、データ修正のためにカラムの値を更新せずにデータが書き換わることもあります。
その状況でこのdbt snapshotの設定を使うと、updated_atが変わらないために新しい値への変更を検知出来ずに、古い値を保持し続けてしまう挙動となります。むやみに使うと後々困ります。
{{
config(
target_database='my_project', # targetの2つはdbt_project.ymlでの指定を推奨
target_schema='snapshots',
unique_key='Id',
strategy='timestamp',
updated_at='updated_at',
invalidate_hard_deletes=True #削除されたらdbt_valid_toをnullに更新する
)
}}
strategy=check
strategy=checkは1つのカラムだけでなく、複数のカラムで更新を検知します。
大体のケースではこちらの設定が適切なので、最初からこちらを使っておいた方が無難です。
-
updated_atの更新日時ではなく、そのスナップショットを取得した時間を軸にdbt_valid_fromやdbt_valid_toを生成します。
毎日変更される物であれば、下記のような時刻がセットされます。-
dbt_valid_fromが前回の実行時刻 -
dbt_valid_toが今回の実行時刻
-
- check_colsがallとなっていると、全ての行と列で完全一致確認が行われるため、メモリを食うクエリが生成されます
- snapshotと他の重たいクエリが同時に走らない時間帯に実行すると良いでしょう
{{
config(
target_database='my_project', # targetの2つはdbt_project.ymlでの指定を推奨
target_schema='snapshots',
unique_key='Id',
strategy='check',
check_cols=['updated_at']
invalidate_hard_deletes=True #削除されたらdbt_valid_toをnullに更新する
)
}}
このあたりのdbt snapshot処理の挙動の詳細を解き明かす際に、タイミーさんによる記事がとても参考になりました。ありがとうございます!
snapshotテーブルの型に自動変換してスナップショットを取るmacro
気をつけたいのが、スナップショットの取得元テーブルのデータ型が異なると型の不一致エラー「例:Bad int64 value: ***」が発生します。
書き込む先のスナップショットテーブルに既にカラムが存在すればその型に変換するマクロを利用することで、期待するデータ型を維持してスナップショットを取れます。
取得元テーブルとは異なるデータ型でスナップショットを取りたい場合には、あらかじめ書き込み先のテーブルを任意のデータ型で作っておくと良いでしょう。
もちろん、テーブルが存在しなければ、取得元テーブルのデータ型でテーブルが自動作成されます。
{% macro query_with_type_conversion(source_dataset,source_table,snapshot_dataset,snapshot_table) -%}
{% set table_id = source_dataset + '.' + source_table %}
{%- set get_schema_query -%}
SELECT
sf_current.column_name,
sf_current.data_type as data_type_from,
sf_snapshot.data_type as data_type_to,
coalesce(sf_snapshot.data_type, sf_current.data_type) as compatible_data_type
FROM
`{{ target.project }}.{{ source_dataset }}.INFORMATION_SCHEMA.COLUMNS` sf_current
LEFT JOIN `{{ target.project }}.{{ snapshot_dataset }}.INFORMATION_SCHEMA.COLUMNS` sf_snapshot
ON sf_current.column_name = sf_snapshot.column_name AND sf_snapshot.table_name = '{{ snapshot_table }}'
WHERE
sf_current.table_name = '{{ source_table }}'
{%- endset -%}
{%- set results = run_query(get_schema_query) -%}
{%- if execute -%}
{% set columns = results.rows %}
{%- else -%}
{% set columns = [] %}
{%- endif -%}
select
{% for column in columns -%}
{% if column.data_type_from == 'STRING' and column.data_type_to == 'DATE' -%}
CAST(LEFT(CAST({{ column.column_name }} AS STRING), 10) AS DATE) AS {{ column.column_name }}{% if not loop.last %},{% endif %}
{% elif column.data_type_from == 'STRING' and column.data_type_to == 'INT64' -%}
{# Bad int64 value: 30000.0 #}
CAST(CAST({{ column.column_name }} AS FLOAT64) AS INT64) AS {{ column.column_name }}{% if not loop.last %},{% endif %}
{%- else -%}
CAST({{ column.column_name }} AS {{ column.compatible_data_type }}) AS {{ column.column_name }}{% if not loop.last %},{% endif %}
{%- endif -%}
{% endfor %}
from {{ table_id }}
{%- endmacro %}
差分データから時系列データへの変換
差分データのままでは、今日と昨日の比較などができません。
従来と同じように履歴テーブルの形式に展開された状態を差分データから作る必要があります。
下記は、dbt snapshotが作る差分データから、欠損の無い履歴テーブルを作るmacroです。
{% macro transform_snapshot_to_timeseries(table_ref, start_date, primary_key='Id') -%}
with source as (
select * from {{ table_ref }}
), date_spine as (
select date
from unnest(generate_date_array(
(select min(date(dbt_valid_from, 'Asia/Tokyo')) from source),
(select max(coalesce(date(dbt_valid_to, 'Asia/Tokyo'), current_date('Asia/Tokyo'))) from source),
interval 1 day
)) as date
), hist as (
select
*
from
source
qualify
row_number() over (
partition by {{ primary_key }}, date(dbt_valid_from, 'Asia/Tokyo')
order by dbt_valid_from desc
) = 1
)
select
date_spine.date as dim_date_jst,
hist.*
from
date_spine
join hist
on date_spine.date >= date(hist.dbt_valid_from, 'Asia/Tokyo')
and (date_spine.date < date(hist.dbt_valid_to, 'Asia/Tokyo') or hist.dbt_valid_to is null)
where
date_spine.date > '{{ start_date }}'
and date_spine.date < current_date('Asia/Tokyo')
{%- if is_incremental() %}
and date_spine.date >= date_sub(current_date('Asia/Tokyo'), interval 7 day)
{% endif %}
{%- endmacro %}
qualify句を用いて、1日に何度か実行した場合、より後に作られたレコードを優先するようにしています。
ビューテーブルにしても良さそうですが、過去7日分を洗い変えるincremental modelにするとデータ書き込み量を抑えて、読み込みも速くできるのでそうしています。
これらのマクロを用いて作成したサンプルのモデルのリネージュは下記の通りです。
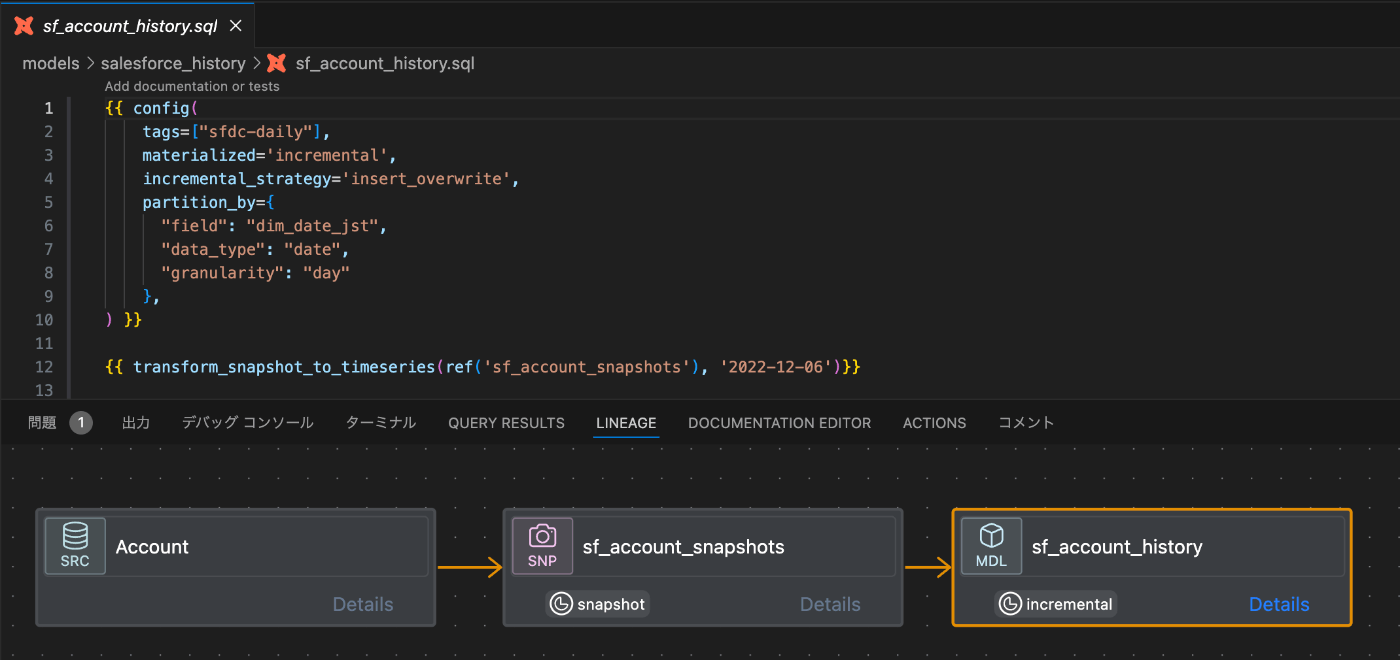
ここまでに説明した方法で、安定性の高いdbt snapshotを取る仕組みが作れました。
次に、既存テーブルのマイグレーションを1コマンドで完了させる方法を紹介します。
既存テーブルからのマイグレーションの流れ
既存のシャーディングテーブルを指定してdbt snapshotを普通に取ると、dbt_valid_fromや dbt_valid_toが実行日時になるため、過去データのbackfillとはなりません。
そこで、digdagを使ったことのある方ならお馴染みのsession_dateを使える仕組みを作りました。
dbt snapshotに--vars引数でsession_dateを渡すと、当時の日時でbackfillできます。これは、dbtのスナップショット取得時刻を取得する処理にsession_dateを注入する方法で実現しています。
数百以上あるテーブル名に日付suffixが付いたシャーディングテーブルを移行する処理を自動化するため、pythonでループ処理を回すマイグレーションスクリプトも用意しました。
これを実行すれば、差分レコードのみを記録するSCD type-2への移行が1コマンドで完了します。
このように呼び出します。
% python scripts/migrate_sharding_to_scd_type2.py --dry-run --input-file migration_files/Accounts.txt
下記のようにdry-runもできるようにしました。
% python scripts/migrate_table_sharding_to_scd_type2.py -h
usage: migrate_table_sharding_to_scd_type2.py [-h] [--dry-run] --input-file INPUT_FILE
Generate and execute DBT commands
optional arguments:
-h, --help show this help message and exit
--dry-run Print commands without executing them
--input-file INPUT_FILE
Path to the input file containing table names
このマイグレーションスクリプトの構成を説明します。
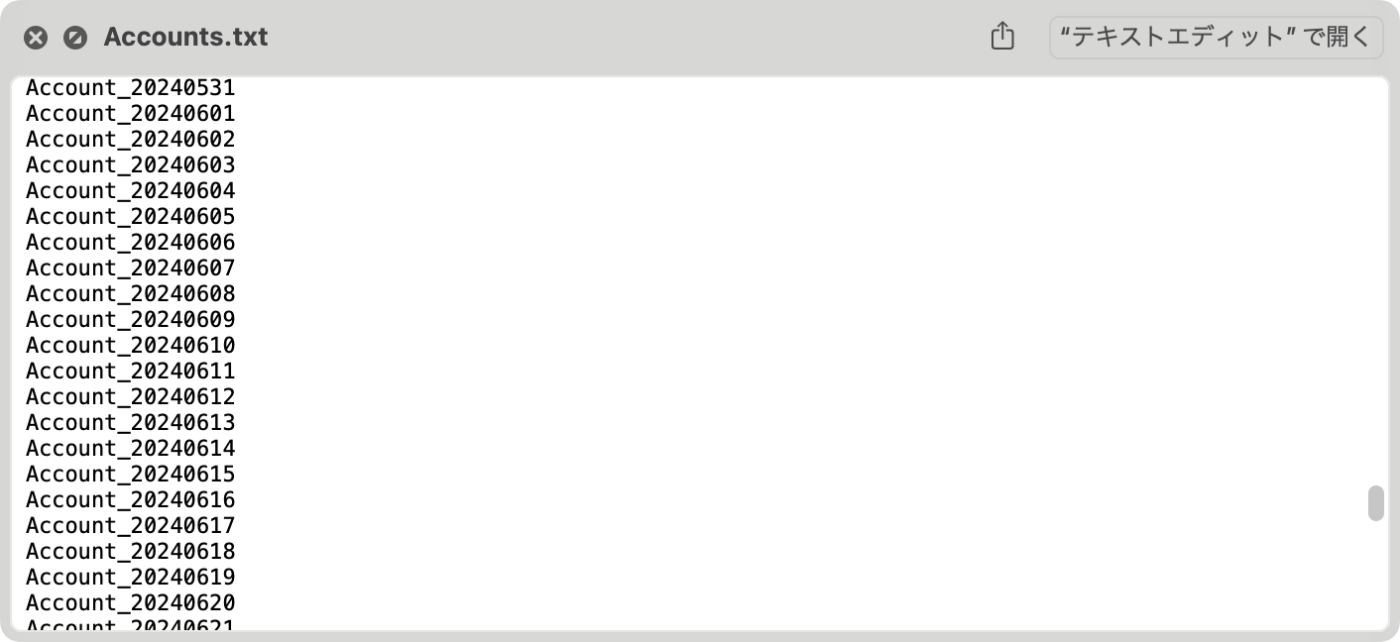
- 移行元となるシャーディングテーブルのリストを抽出し、テキストファイルで用意する。
下記サンプルのmigration_files/Accounts.txtの中身は改行区切りのファイルです。
- pythonスクリプトから、日付ごとに入力パラメータを変えてdbt snapshotコマンドを呼ぶ
python scripts/migrate_sharding_to_scd_type2.py --dry-run --input-file migration_files/Accounts.txt
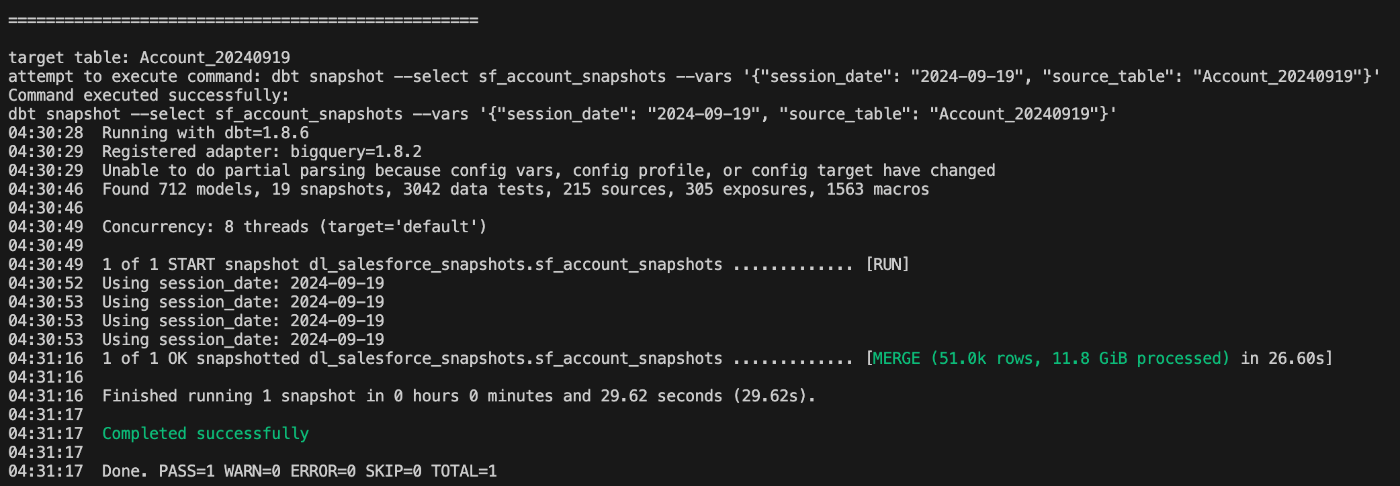
- 下記のようにパラメータを動的生成してdbt snapshotにsession_date引数とシャーディングテーブル名を渡して逐次処理する
dbt snapshot --select sf_account_snapshots --vars '{"session_date": "2024-09-19", "source_table": "Account_20240919"}'
例えば、session_date:2024-06-06だとすると、dbt_valid_to:2024-06-05 00:00:00 UTCのレコードが書き込まれます
このマクロを使うことで、strategyによるdbt_updated_atの挙動が異なる動作をsession_dateに統一できるメリットもあります。
dbt snapshotのstrategyによるdbt_updated_at時刻が変わる挙動の詳細は下記の記事をご覧ください。
今回紹介したプログラム一式、公開します
今回利用したプログラムのコードを納めたレポジトリはこちらです。
ディレクトリ構成は下記の通りです。
お使いのdbtレポジトリにファイルを取り込んでご利用ください。
- dbt_project.yml
session_dateを定義。Python datetime objectを用いたrun_started_atを利用。
dispatchでmacroをoverrideする設定も大事です - macros/dbt-adapters/timestamps.sql
snapshot_get_time()を呼んでいる先の、current_timestamp()を呼ぶmacroをoverrideしています - macros/query_with_type_conversion.sql
snapshotsテーブルで利用しているデータ型に正規化してから取り込むマクロです - macros/transform_snapshot_to_timeseries.sql
差分レコード形式から、履歴テーブル形式に展開するマクロです - migration_files/Account.txt
変換したいシャーディングテーブル名のリストを記載します - models/salesforce_history/sf_account_history.sql
開始日付からの履歴テーブルを動的生成するモデルです - models/salesforce_history/sources.yaml
参考までに大本のsourceを定義しています - scripts/migrate_sharding_to_scd_type2.py
移行するためのdbt snapshotコマンドを動的に発行するpythonスクリプト - snapshots/sf_account_snapshots.sql
スナップショットを取るモデル
まとめ
これまでtableに日付パーティショニングで追記したり、日次のテーブルで履歴テーブルを持っていた構成から、スムーズに差分検知式のsnapshot形式に乗り換え、互換性のある従来の履歴テーブル形式で扱う方法を紹介しました。
PR
コミューンでは一緒に働く仲間を募集中です。
少しでも興味のある方はカジュアル面談フォームよりお気軽にご連絡ください。
▼ポジションごとの募集要項はこちらからご確認いただけます

Discussion