本当に競争力のある、凡庸ではないAIサービス(特にここではAIエージェントやエージェンティックAIをメインに扱う)を生み出す鍵は、逆説的ですが、LLMが「できないこと」にこそ隠されているのではないでしょうか。
表面的理解だけではなく、LLMのアーキテクチャの理解を深めることで、できることとできないことを整理していくと理性的な限界とやるべきことが見えてきます。
ここでは、LLMが抱える根源的な制約である「外挿(extrapolation)」と「内挿(interpolation)」の壁から、優れたAIサービス設計について考えてみます。

考える切っ掛けになったのは佐藤 竜馬さんの記事です。
LLM のアテンションと外挿 - ジョイジョイジョイ

LLM(大規模言語モデル)の注意機構(attention mechanism)を解剖した解説記事で、「なぜLLMが文脈を理解でき、推論や“外挿”ができるように見えるのか?」を注意機構(attention head)の振る舞いから説明する技術的考察です。
ちなみに、内挿とは、モデルが訓練データとして学習した知識やパターンの「範囲内」で、未知の問いに答えることです。例えば、犬と猫の写真を大量に学習したモデルが、見たことのない犬の写真を「犬」だと認識するのは内挿です。これは、いわば「知っている知識の応用問題」と言えます。
また、外挿とは、学習した知識やパターンの「範囲外」にある、まったく新しい概念や法則に適応することです。料理にたとえるなら、2人分や3人分のレシピから類推して4人分の料理を作るのは内挿ですが、いきなり80人分の料理を作るとなると、調理手順や火加減、使う器具といった根本的な原理から見直す必要が出てきます。この「原理のジャンプ」が外挿に近い感覚です。
LLMの内挿における限界
ではまずは内挿の限界から考えてみます。
内挿の限界は、実は2つの異なる原因に整理できます。1つ目は「資源の制約」によるもの、2つ目は「確率的生成の宿命」によるものです。この2つを理解すると、AIサービスの設計における役割分担が明確に見えてきます。
有限資源が生み出す限界
LLMは固定長のコンテキストウィンドウという「作業台」の上で思考します。どれだけモデルが賢くても、この作業台の大きさには限界があります。
長いカウント作業の困難
10万文字の括弧が正しく対応しているかをチェックしたり、文書内の語数を正確にカウントしたりする作業を想像してみてください。人間でも、脳内だけで何百品もの買い物メモを覚え続けるのは難しいはずです。
LLMも同じで、固定長のコンテキストウィンドウと、近視眼的な注意機構の性質上、入力が長くなればなるほど誤差が蓄積していきます。これは「有限メモリ問題」と呼ばれていて、どれだけ学習データに同種の例があっても、長さの壁を越えられないのです。
長期推論での一貫性崩壊
数十段にわたる形式証明や、複雑な法務条文の整合性チェックのような、推論チェーンが長い作業も苦手です。これは、中間ステップでの小さな誤りが、雪だるま式に拡散していく「誤差拡散」の問題です。会議の議事を録音もメモもなしで完全再現しようとしても、どこかで記憶が曖昧になるのと似ています。
閉じた世界の完全記憶の限界
社内ナレッジベースの最新版や、今日の在庫の正確個数といった、「閉じた世界の最新情報」も、LLMは苦手です。学習時点のスナップショット依存という性質上、見ていない細部は「範囲内」でも欠落しています。昨日のカタログで今日の棚卸しをしようとしても、当たらないのと同じです。
これらの限界は、どれも「作業台が有限である」という同じ根っこから生まれています。たとえば、法務文書の括弧対応チェックや、長大な議事録の完全再現といった業務では、LLMだけに頼るのは危険かもしれません。
ですが、この限界は「外部メモリ」という形で緩和できます。RAG(Retrieval-Augmented Generation)やナレッジベース連携、構造化されたデータベースといった仕組みは、LLMの作業台を事実上無限に拡張する試みだと言えます。
確率的な生成の宿命
LLMは本質的に「確率的な近似装置」です。どれだけ学習を積んでも、この性質は変わりません。そのため、誤差ゼロを要求される作業には構造的に向いていないのです。
大きい桁の演算の不可能性
1000桁の乗算や、RSA署名の厳密検証といった、大きい桁の演算をLLMに任せるのは無理があります。これは、LLMの内部表現が本質的に「近似的」であるためです。暗算で巨大な税務計算を完了しようとするようなもので、いくら四則演算のルールを知っていても(内挿の範囲内でも)、誤差ゼロで実行し続けることができません。
完全に可逆な変換の限界
バイナリデータをBase64に変換して、また元に戻すような「完全可逆」を保証しなければいけない変換も、LLMには向いていません。確率的な生成プロセスである以上、微小なゆらぎが必ず発生します。これは、改札を通るQRコードを口頭で復唱して復元しようとするようなもので、1文字でも違えば通れなくなってしまいます。
この2つの壁は、どちらも「確率的生成の宿命」という共通の原因から生まれています。LLMは判断や要約は得意でも、厳密計算やコンパイラのような厳密変換は、やはり専用ツールに委ねるべきなのです。
このあたりは、AIサービスを設計する際の「計算は外部ツールに委譲する」という基本原則につながります。電卓、ソルバ、専用パーサーといったツールは、LLMの「苦手を補う相棒」として欠かせません。
LLMの外挿における限界
次に、外挿(学習範囲外)での限界を見ていきます。外挿とは、正解関数が存在し、原理的には学習可能だが、訓練分布の外で当てにいく必要がある領域です。内挿との決定的な違いは、「新しい因果メカニズム」や「環境の構造変化」への対応が必要な点にあります。
因果・発明と分布外のロバストネス
新しい自然法則・発明の当て
未観測領域での材料相図や、未知病原体の機序といった、「経験外の因果関係」を当てることは、テキスト統計だけでは不可能です。これは、現地に行かずに新大陸の地図を正確に描こうとするようなもので、実験や観測といった「現実世界との接触」が不可欠です。
AIサービスで真の発明支援を目指すなら、LLMは「仮説生成エンジン」に留め、検証は人間やロボット、シミュレータに委ねる必要がありそうです。ワールドモデルがこれを解決するのかには興味があります。
分布外環境での意思決定
リーマンショックやコロナ禍のような市場でのトレード戦略や、非常時のオペレーションといった、訓練時と相関構造が大きく変わる環境での意思決定も、LLMは苦手です。晴れの日だけ練習した運転で、大雪の峠に挑むようなもので、過去の経験則が通用しなくなります。
このあたりは、AIサービスに「異常検知」と「人間へのエスカレーション」を組み込む重要性を教えてくれます。
敵対環境と新規記号体系
分布外(Out-of-Distribution)への適応は、LLMの学習可能な領域ではあるものの、実装上の大きな壁です。ここでは、内挿と外挿の境界にまたがる2つの課題を見ていきます。
敵対的環境での脆弱性
プロンプト注入や逆例生成など、相手が分布を意図的に外してくる「敵対的環境」でも、LLMは脆弱です。こちらの癖を読まれた心理戦では、定型手が破られるのと同じで、フィッシング文面の無限変種のような攻撃には対応しきれません。
この問題には2つの側面があります。1つは「分布外攻撃への対応」(外挿系)、もう1つは「最悪ケース保証」(形式検証=内挿系の厳密性)です。セキュリティクリティカルなAIサービスでは、LLMの出力を信頼せず、必ず「レッドチーム評価」や「人間によるレビュー」を挟むべきだと思います。
新規記号体系のゼロショット運用
未知言語の文法や意味役割を、マッピング辞書も構文解説もなしに、高精度で即時運用するのも無理があります。取扱説明書なしに新型機械を完璧に運転しようとするようなもので、当て推量では限界があります。
ただし、これには条件分岐があります。仕様が明示されていれば、メタ学習と長期推論の組み合わせで到達可能(内挿的アプローチ)です。一方、仕様なしに「当てる」のは外挿の領域になります。
新しいドメインに適応するAIサービスでは、最初は人間が「教師データ」や「仕様書」を丁寧に作り込む工程が欠かせないのです。
LLMの原理的な限界
ここまで見てきた内挿と外挿の限界は、いずれも「学習で改善できる(または工学的に緩和できる)」領域でした。しかし、LLMには学習の土俵にすら乗らない、原理的な限界も存在します。
これらは「データを増やせば解決する」「アーキテクチャを改善すれば突破できる」という類の問題ではありません。情報理論、計算理論、そして価値判断という、3つの異なる原理が壁を作っています。
情報理論の限界
暗号学的な乱数や秘密の推測
暗号化に使われる複雑なパスワードの解読や、宝くじの次回当選番号といった、情報論的に不可能な問題は、当然ながらLLMには解けません。
金庫を眺めるだけで暗証番号は分からないのと同じで、これは原理的な限界です。未開封のくじの当たり番号を「料理の手順書」だけで当てようとするようなもので、そもそも観測可能な特徴から予測対象が独立しているため、情報が足りないのです。
AIサービス設計への示唆
逆に言えば、AIエージェント系のサービスが「予測不可能なもの」を予測できると謳うなら、ツールを使って何か別の情報源(サイドチャネル攻撃、脆弱な暗号実装など)にアクセスしているはずです。
この限界を「越える」には、情報を増やす(公開鍵暗号の脆弱性を突く、物理的な観測手段を追加する)か、問題の範囲を制限する(特定の弱い暗号に限定する)といった、問題設定自体の変更が必要になります。
計算理論の限界
停止の判定
任意のプログラムが停止するかどうかを、万能に決めることは、計算理論上不可能です。「未来の全て」を今ここで知ることは、原理的に無理なのです。
これは、「あらゆる小説がいつ結末に到達するか」を事前に完全判定しようとするようなもので、チューリングが証明した通り、一般には決定不能な問題です。
これは、AIサービスが「完全な予測」を保証できない根本理由でもあります。ただし、この限界も「越える」ことは可能です。対象を特定のクラスに制限する(プリミティブ再帰関数に限定する、ループ回数に上限を設ける)、あるいは近似や確率的保証に緩和する、といった設計上の工夫で実用的な解決策を作れます。
規範の限界
規範・価値判断の創造
新たな倫理基準の策定や、法の根源的解釈改定といった、「社会的合意形成」を要する価値判断も、LLMだけでは決められません。
価値は分布ではなく、人間の合意形成が決めるものです。家庭のルールは家族で決めるしかないのと同じで、「何が良い・正しいか」の最終判断は、単一の真値が定まらない領域なのです。
情報や計算の問題ではなく、目標関数そのものが未定義だからです。まず「何を最適化すべきか」という価値観・規範を人間が決め、それを明示的に定式化してはじめて、LLMの学習や外挿の土俵に乗ります。
このあたりは、AIサービスの「説明責任」や「透明性」、ガバナンス設計といった、倫理・社会的な設計の話にもつながります。
制約を超えるための3つのアプローチ
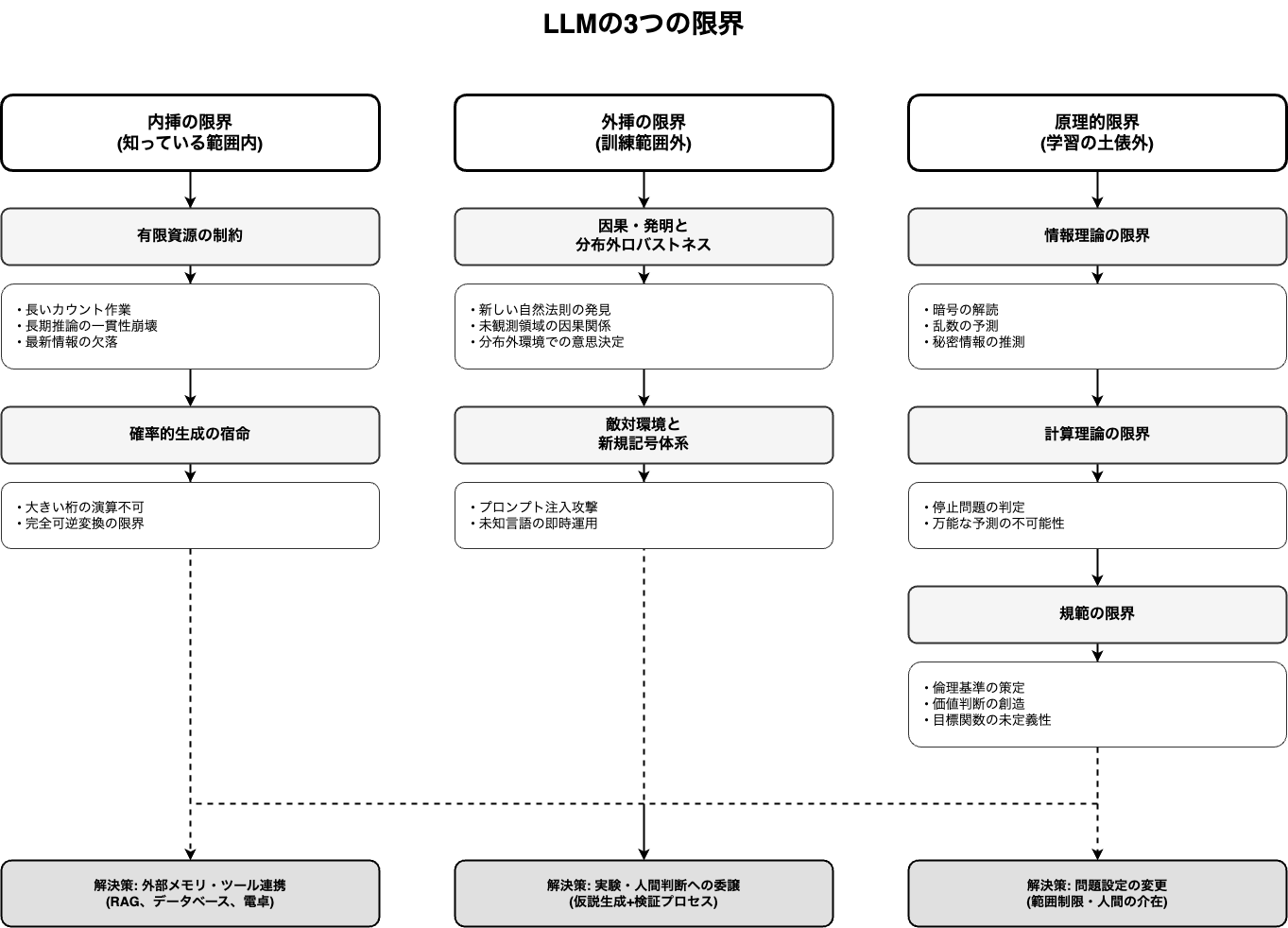
では、これらの限界を踏まえて、どうすれば競争力のあるAIサービスを作れるのでしょうか。以下の3つのアプローチに整理してみました。
アプローチ1:表現の乗り換え
問題を「内挿で回る表現」に変換することです。
例えば、長大な括弧対応チェックは、文字列のままLLMに投げるのではなく、構文木(グラフ)に変換してから検証ツールに渡す。在庫管理は自然言語ではなく、正規化されたデータベーススキーマで扱う。
このように、LLMの苦手な形式を、LLMやツールが得意な形式に「乗り換える」ことで、多くの問題が解決します。インコンテキストラーニングが活躍する分野ですかね。
アプローチ2:ツール接続
計算、検索、実験といった厳密性を要する処理は、外部ツールに委譲することです。
電卓、データベース、ソルバ、ブラウザ、ロボット、シミュレータ。LLMは「どのツールをいつ使うか」を判断する司令塔として機能し、実行は専門ツールに任せる。
この「LLM + ツールチェーン」の設計思想は、いまのAIサービスの標準になっていますね。
アプローチ3:外部メモリと人間の関与
長期記憶や最新情報は、RAG(検索拡張生成)やナレッジベースといった「外部メモリ」に頼る。
そして、価値判断や新規範の策定、異常時の意思決定といった、LLMが原理的に苦手な領域は、ヒューマンインザループによる人間の審議で決める。LLMは案出し補助に限定するのです。
このあたりは、「AIに全てを任せる」のではなく、「人間とAIの役割分担を明確にする」という設計哲学につながります。
イノベーションのアルファは「壁の理解」から生まれる
佐藤さんの整理を見ていて、私が感じたのは、「LLMができないこと」を知ることが、逆説的に「本当に価値のあるAIサービス」を生む鍵になるだろうな、ということです。
多くのAIサービスは、LLMの「できること」にフォーカスしがちですが、実は競争優位性は「できない壁」をどう超えるか、に隠れている気がします。
例えば、以下のような問いは、今後のAIサービス設計において重要になるのではないでしょうか。
- 厳密な計算が必要な場面で、AIエージェントが活躍していない場所はあるか?
- 長期や多変数の推論が必要な業務で、どこまでLLMに任せ、どこから人間が介入するか?
- 敵対的環境(セキュリティ攻撃)に対して、どんな防御機構を組み込むか?
- 価値判断を要する意思決定で、AIはどこまで「案出し」が可能なのか?
- 最新情報や閉じた世界の知識を、どうやって外部メモリから引き出すか?
これらの問いに対する答えが、そのAIサービスの「アーキテクチャの質」を決めると思います。
実務に落とす
より具体的なフローとして、次のような3段階の設計が検討できるのではないでしょうか。
(A)外挿で新原理を掴む → (B)表現を乗り換えて内挿で回す → (C)ツール/メモリで厳密化
この三段跳びは、AIサービス設計のフレームワークとしても使えそうです。
まず、(A)外挿領域で、人間やシミュレータが新しい原理を発見する。次に、(B)その原理を、LLMが得意な内挿可能な表現(グラフ、スキーマ、構造化データ)に変換する。最後に、(C)厳密性を要する部分は、外部ツールや外部メモリ、人間のレビューで補強する。
この、A,B,Cすべての変数において、解決する課題や業界の問題に対して圧倒的な設計を組み立てられるかどうか、ここにAIサービスの質に繋がりそうだと思います。 この三段構えのアーキテクチャを持つAIサービスは、単なる「LLMをAPIで叩くだけ」のサービスよりも、はるかに堅牢で、実用的になるはずです。
LLMの限界を知ることが、次世代AIサービスの競争力を決めるのでは
LLMは「近いところを上手に補間する装置」として非常に強力ですが、3つの層で構造的な壁があります。
内挿の限界(資源と厳密性)
- 長期依存・記憶・一貫性の壁(作業台の有限性)
- 厳密演算・フォーマル変換の壁(確率的生成の宿命) → 外部メモリとツール接続で緩和可能
外挿の限界(分布外への適応)
- 新規因果・発明の壁(現実世界との接触が必要)
- 分布外環境での堅牢性(異常検知とエスカレーション)
- 敵対環境と新規記号体系(跨ぎ案件) → 因果モデリング、シミュレーション、メタ学習で挑戦可能
原理的・規範的限界(学習の土俵外)
- 情報理論の限界(秘密と乱数の不可知)
- 計算理論の限界(停止問題などの不可判定性)
- 規範の限界(目標関数の未定義) → 問題設定の変更、人間の合意形成が必要
この壁を無視して「AIは万能だ」と信じてサービスを作ると、どこかで破綻します。逆に、どの層の壁に直面しているのかを理解し、適切なアプローチでアーキテクチャを組むことが、AIサービスの競争力を決めるのではないでしょうか。
私たちAIサービスの設計者は、LLMが「できること」だけでなく、「できないこと」とその原因にこそ目を向けるべきだと思います。その「できない壁」を超えるために、どんなツールを接続し、どんな外部メモリを用意し、どこで人間が介入するか。そして、何が原理的に不可能で、どう問題を再定義すべきか。
そのアーキテクチャ設計の巧拙が、凡庸なAIサービスと、本当に競争力のあるAIサービスを分ける境界線になるのではないでしょうか。
About me
現在、市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai
ぜひお気軽にチャットしましょう!
お仕事のご相談は以下まで、AIエージェントの開発や研修、調査代行やビジネスコンサルなどの対応も可能です。
生成AIデスクリサーチサービス Deskrex | サービスページ
生成AIデスクリサーチエージェント Deskrex App | アプリケーションサイト
DeskrexAIリサーチ | メディア
株式会社Deskrex | 会社概要
Deskrex | Xページ
- 会社概要:https://www.deskrex.ai/
- Deskrex App:https://app.deskrex.ai/
- サービスページ:https://lp.deskrex.ai/
- メディア:https://media.deskrex.ai/
- X:https://x.com/deskrex

Discussion