0. はじめに
先日、「AI駆動開発勉強会臨時回【Devin Meetup Japan #1】」で登壇する機会がありました。前回の続きとして、「Devinのメモリ活用の学びを自社サービスにどう組み込むか?」という発表を共有しました。
多くの開発者がDevinのような最新AIコーディングエージェントに関心を持つ中、私はプロダクト開発しているところもあり、特にメモリシステムの設計について関心を寄せています。
この記事では、発表内容をさらに深堀りし、Devinのメモリシステムから得られた知見を実際の開発現場やサービス構築にどう活かせるかを探っていきます。AIエージェントの記憶機能は単なる技術的要素ではなく、エージェントの自律性と効果的な問題解決能力を支える基盤だと言えるでしょう。
Devinの核となる強みは、「これをやったらこうやってくれる」という手順や知識をデータベースに効率的に格納し、必要なときに適切に取り出せる点にあります。この検索とインデックスの仕組みが非常に重要で、メモリの分類方法によって検索精度が大きく変わる可能性があります。
実際にDevinを開発プロジェクトで活用してきた経験から、AIエージェントにとってのメモリは、人間の記憶と同様に複数のタイプが存在し、それぞれが異なる役割を担っていることがわかりました。その構造を理解し、適切に設計することで、AIエージェントの能力を飛躍的に向上させることができるかもしれません。
それでは、前回発表のおさらいをしつつ、AIエージェントのメモリシステムの基本から、Devinの具体的な実装、そして自社サービスへの応用まで、段階的に見ていきましょう。
1. AIエージェントのメモリの種類
最新のAIエージェント開発において、メモリシステムの設計はその性能と使い勝手を大きく左右する重要な要素です。特にDevinのようなコーディングに特化したAIエージェントでは、単なる情報の保存ではなく、適切なタイミングで必要な知識を呼び出す能力が成功の鍵を握ります。

出典:Langchain(academy.langchain.com/courses/take/intro-to-langgraph/texts/59971041-module-5-resources)
AIエージェントのメモリシステムは、人間の記憶構造を模倣し、大きく3つのタイプに分類できます。それぞれが異なる役割を担い、連携することで包括的な知識基盤を形成しています。
1. 意味記憶(Semantic Memory)
意味記憶は、事実や概念に関する知識を格納するメモリです。プログラミングAIにとって、これはコードの構文やライブラリの使い方など、体系化された知識を表します。
意味記憶の特徴
- 体系化された事実知識:プログラミング言語の文法、API仕様、アーキテクチャパターンなど
- コンテキストから独立:特定の経験や出来事に紐づかない普遍的な知識
- 再利用性が高い:様々な状況で繰り返し活用できる
意味記憶は、大量の情報を詰め込みすぎず、必要な情報にすばやくアクセスできるように、適切なチャンクサイズの設計を行う必要があります。
2. エピソード記憶(Episodic Memory)
エピソード記憶は、特定の経験や出来事に関する記録を保持するメモリです。これは過去の問題解決の履歴や、特定のプロジェクトでの経験が含まれます。
エピソード記憶の特徴
- 文脈依存の具体的な記憶:「いつ」「どこで」「何が起きたか」の情報を含む
- 時間的な順序性:出来事の順番や因果関係を保持
- 感情や価値判断を含む:成功体験や失敗体験の教訓を記録
エピソード記憶は特に、バグ修正やリファクタリングの履歴を記録することで、同様の問題に直面したときに効率的な解決策を提供できます。これは人間のエンジニアが「前にも似たようなエラーを見たことがある」と思い出す過程に似ています。エピソード記憶は特に具体的なコンテキストでの解決策を見つける際に強力であるとされています。
3. 手続き記憶(Procedural Memory)
手続き記憶は、特定のタスクを実行するための手順や方法に関するメモリです。これはプログラミングにおける「どうやって行うか」の知識を表します。
手続き記憶の特徴
- 方法論的知識:特定のタスクの実行方法
- 自動化されやすい:反復によって改善・効率化される
- 暗黙知を含む:明示的に表現しにくい技術やコツを含む
手続き記憶の具体例としては、デバッグプロセスメモリー(問題の特定・修正の体系的手順)やリファクタリングメモリー(コード改善の判断基準と手法)などがあります。これらは繰り返し実行することで洗練され、より効率的になっていきます。
メモリ間の相互作用
これらのメモリタイプは独立して機能するのではなく、複雑に相互作用しながら問題解決を行います。例えば:
- 意味記憶が基本的な知識(言語仕様など)を提供
- 手続き記憶が実装方法の選択肢を提示
- エピソード記憶が類似した過去の経験から注意点を想起
この相互作用により、AIエージェントは単なる情報の検索エンジンを超えて、人間のエンジニアに近い思考プロセスを実現することができます。
これらの基本的なメモリ構造を理解したところで、次は現在のAI開発ツール市場でこれらのメモリシステムがどのように実装されているのかを見ていきましょう。Cline、Devin、Windsurfなど、最新のAIツールはそれぞれ独自のメモリ管理アプローチを採用しており、その比較から多くの学びを得ることができます。各ツールの特徴的なメモリシステムを理解することで、自社サービスに最適なメモリ設計の方向性が見えてくるはずです。
2. 最新ツールにおけるメモリシステム比較
AIエージェントの能力を大きく左右する要素として、メモリシステムの設計が注目されています。特に開発支援ツールにおいては、コードベースの理解や過去の対話履歴の活用など、効率的なメモリ管理が不可欠です。ここでは、主要なAIツールのメモリシステムを比較し、それぞれの特徴と活用法を探ります。
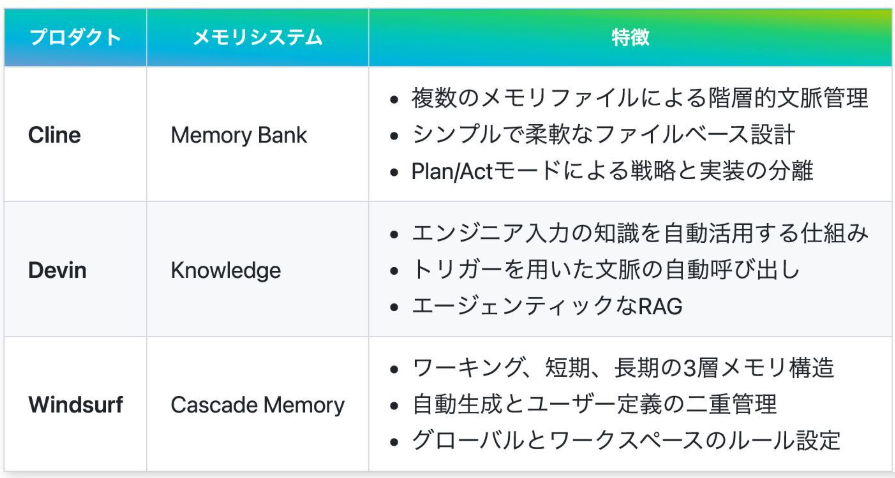
Clineのメモリ管理
Clineは、複数のセッションにまたがるプロジェクト文脈を一元管理するために、Memory Bankと呼ばれる仕組みを中核に据えています。
Memory Bankによる階層的文脈管理
- 複数のメモリファイルによる構造化: projectbrief.md、productContext.md、systemPatterns.md、techContext.mdなど複数のファイルを利用
- セッション間の継続性確保: 初回設定時に記録した情報を以降のセッションで自動的に読み込み
- 文脈の自動更新: 作業中の変更をリアルタイムで反映
Memory Bankの最も重要な特徴は、プロジェクト全体の情報を階層的に保持し、セッション間の継続性を確保する点です。これにより、長期間にわたるプロジェクトでも一貫性のある支援が可能になります。
ユースケースと運用例
Clineの Memory Bankは特に以下のような場面で効果を発揮します:
- 長期プロジェクト管理: 複数のセッションにまたがるプロジェクト情報の一元化
- チーム間の情報共有: 標準化されたファイル構造による知識の共有
- プロジェクト固有知識の蓄積: 技術的背景や決定事項の継続的な記録
Devinのメモリ管理
Devinは、完全自律型のAIソフトウェアエンジニアとして、エンジニアが提供する知識や過去のタスク履歴を「Knowledge」として蓄積し、タスク実行時に最新の文脈を自動的に反映する仕組みを重視しています。
Knowledgeによる自律型メモリ管理
- オンボーディング時の知識追加: エンジニアが初期に指示やヒントを登録し、知識項目として蓄積
- トリガー説明による自動呼び出し: タスク実行前後に、状況に合わせて必要な知識や履歴情報を自動で呼び出し
- 継続的な学習と再更新: エンジニアとのインタラクションを通じて知識を再評価・再構築
このナレッジシステムにより、エンジニアが入力した知識やタスク履歴の自動更新によるリアルタイムでの文脈反映が実現しています。このエージェンティックなRAG(検索拡張生成)機能により、単なる情報検索ではなく文脈に応じた適切な判断が可能になっています。
実際に使ってみると、when working in repo {レポジトリ名}などのトリガーにより、特定のコードベースに関する深い理解を示してくれることが実感できます。これは従来のAIコーディングアシスタントと一線を画す特徴です。
Windsurfのメモリ管理
Windsurfは、もともとVS Codeのフォークとして開発され、高速かつ軽量な動作と最適化されたメモリ使用を可能にしています。特に、Cascade Memoryシステムを中心に、複数層でのコンテキスト管理を実現しています。
多層構造によるコンテキスト管理
Windsurfは主にCascade Memoryシステムを持っていますが、このメモリシステムは3つの層に分けて考えることができます。:
- ワーキングメモリ: 現在のタスクやファイルの状態
- 短期メモリ: 直近のセッションのタスク履歴や決定事項
- 長期メモリ: プロジェクト全体の永続的な情報(Cascade Memory, windsurfrules)
この3層構造により、異なる時間軸での情報管理が可能となり、即時的な作業から長期的なプロジェクト管理まで一貫した支援を提供できます。例えば、このWindsurfのRulesでは、この設計がヒューマンメモリの構造を模倣できる可能性を示唆しています。
自動更新とカスタマイズ
Windsurfでは以下のような仕組みでメモリ管理を行っています:
- グローバルルールとワークスペースルール: ユーザー定義の情報と自動生成情報の統合
- リアルタイム状態反映: 作業状況に応じた動的なコンテキスト更新
- ユーザー定義による管理: 柔軟かつ統一的な情報管理の実現
このアプローチにより、ユーザー定義により、複数層でのコンテキスト保持が実現され、大規模なプロジェクトでも文脈の断絶なく作業が進められます。Devinのようにメモリを保存できる他方で、ユーザーが指示することで記憶する柔軟なシステムです。
メモリシステムの比較と選択基準
これらのAIツールのメモリシステムを比較すると、それぞれに異なる強みと適用領域があることがわかります:
| プロダクト | メモリシステム | 主要な特徴 | 適したユースケース |
|---|---|---|---|
| Cline | Memory Bank | 複数のメモリファイル、Plan/Actモードによる戦略と実装の分離 | 長期プロジェクト、チーム間情報共有 |
| Devin | Knowledge | エンジニア入力の知識自動活用、トリガーによる文脈呼び出し | 大規模コード移行、自動化が必要な繰り返しタスク |
| Windsurf | Cascade Memory | ワーキング・短期・長期の3層メモリ、グローバルとワークスペースのルール設定 | 複雑なプロジェクト構造、長期開発 |
適切なメモリシステムを選択する際には、以下の点を考慮することが重要です:
- プロジェクトの特性: 規模、複雑さ、継続期間
- 作業スタイル: 個人作業か共同作業か、作業の連続性
- 情報の性質: 構造化された知識か経験的知識か、更新頻度
- 自動化の程度: どの程度の自動処理が望ましいか
- カスタマイズの必要性: 標準的な使用か特殊な要件があるか
次世代メモリシステムの方向性
現在のAIツールのメモリシステムを分析すると、Devinが先行する中で今後の発展方向として以下のようなトレンドが見えてきます:
- マルチモーダルメモリ: コード、ドキュメント、図表など異なる形式の情報を統合的に管理
- 分散協調メモリ: チームメンバー間で共有されるメモリ空間の構築
- 自己組織化メモリ: ユーザーの作業パターンから自動的に最適な構造を学習
これらの発展により、AIアシスタントはより人間に近い理解力と長期的な文脈把握能力を獲得していくことが期待されます。
次章では、この中でも特にDevinのメモリシステムに焦点を当て、その詳細な構造と活用方法について深掘りしていきます。メモリシステムを単なる技術的要素ではなく、AIエージェントの思考プロセスの基盤として捉え直すことで、より効果的な活用法が見えてくるでしょう。
3. Devinのメモリシステム詳細分析
前章で様々なAIツールのメモリシステムを比較しましたが、ここではDevinのメモリシステムの特徴をより詳しく掘り下げていきます。Devinが他のAIコーディングエージェントと一線を画す理由の一つは、その洗練されたメモリ設計にあります。
Devinのメモリシステムは大きく分けて「ナレッジシステム」と「プレイブック」という2つの柱で構成されています。この2軸構造により、事実的知識と手続き的知識を効果的に分離し、それぞれに最適化された形で管理できるようになっています。

1. ナレッジシステム
Devinのナレッジシステムは、プロジェクトに関する重要情報を効率的に格納・検索するためのシステムです。単なる情報の蓄積ではなく、必要なときに必要な情報にアクセスできることを重視した設計になっています。
プロジェクトの重要情報を効率的に管理
私のDevinのKnowledgeでは、リポジトリに関する様々な情報が格納されています。
- リポジトリ構造の把握: ディレクトリ構造、主要コンポーネント、アーキテクチャなどの情報
- コーディング規約の理解: 命名規則、設計パターン、ファイル構造に関するガイドライン
- 依存関係の管理: ライブラリやモジュール間の関係性に関する情報
特に「when working in repo {レポジトリ名}」というトリガーにより、特定のリポジトリでの作業時に関連知識が呼び出される仕組みは非常に効果的です。これにより、コンテキストに応じた適切な情報のみを参照することができます。
シーンごとに整理されたKnowledge
DevinのKnowledgeの優れた点は、使用シーン(トリガー)に基づいて知識が整理されていることです。これにより、特定のコンテキストで必要な情報にすばやくアクセスできます。
主なシーンの分類例:
-
特定の作業タイプに基づく分類
- 「When designing React hooks in deskrexai/app」
- 「When refactoring interfaces in the deskrexai/app repository」
- 「When working with database-related features in the deskrexai/app repo」
-
エラー対応シーン
- 「When encountering TypeScript errors in deskrexai/app」
- 「When encountering persistent TypeScript errors in deskrexai/app」
-
実装シーン
- 「When implementing new LLM providers in deskrexai/app」
- 「When implementing scroll functionality in deskrexai/app」
この「シーン」という概念が、Devinがコンテキストを理解し、適切なアドバイスを提供できる理由の一つです。分類は細かすぎず、かつ適切な粒度で行われており、メモリへのアクセス効率を高めています。
検索による効率的なアクセス
Devinのナレッジシステムは、おそらくベクターデータベースを活用して知識の検索を行っています。これにより、単純なキーワードマッチングではなく、意味的な関連性に基づいた検索が可能になっていると思われます。
ベクター検索の最適化のために重要なポイント:
-
コンパクトな知識表現:
情報は適切な長さに設計されています。これは大量の情報を詰め込みすぎると検索精度が落ちるためで、チャンク化された適切な情報量が効率的な検索を可能にしています。 -
コンテキスト特異性の包摂的な活用:
より具体的なコンテキストに関連する記憶も包含されるよう設計されています。例えば「When designing React hooks in deskrexai/app」は「when working in repo deskrexai/app」と同時に呼び出されます。

ナレッジデータベースを効果的に活用することで、Devinは膨大なKnowledgeから状況に最も適した情報を瞬時に取り出すことができます。
2. プレイブック機能
プレイブックは、Devinのメモリシステムにおけるもう一つの重要な柱です。ナレッジシステムが「何を知っているか」を担当するのに対し、プレイブックは「どうやって行うか」に焦点を当てています。
繰り返し作業の効率化
プレイブックは、頻繁に発生する定型的なタスクを効率化するためのテンプレート的な機能です。
- 標準的な開発フロー: 機能実装から単体テスト、デプロイまでの一連の流れ
- コーディングパターン: 特定の機能実装に関する定型的なアプローチ
- デバッグ手順: 特定の種類のエラーに対する体系的な対処法
プレイブックを活用することで、同じような作業を何度も説明する必要がなくなり、開発効率が向上します。特に、チーム内で共有されるプレイブックは、知識の伝達と標準化に大きく貢献します。
テンプレート的な機能の活用
プレイブックは本質的にはテンプレートのコレクションとしても機能します。
- 再利用可能なコードスニペット: 共通パターンの実装例
- 設定ファイルテンプレート: 各種設定ファイルの標準フォーマット
- ドキュメントテンプレート: API仕様や設計ドキュメントの雛形
これらのテンプレートは単なるコードの切れ端ではなく、ベストプラクティスが組み込まれた知的資産です。
3. ナレッジシステムのトリガー構造
Devinのナレッジシステムにおける「トリガー構造」は、適切なタイミングで必要な知識を呼び出す重要なメカニズムです。
トリガーパターンの例と効果的な設計
Devinのナレッジシステムにおけるトリガーはシーン(使用コンテキスト)に基づいて設計されており、以下のようなパターン例になっています。
-
when working in repo {レポジトリ名}- リポジトリ全体の構造や基本情報を呼び出すための基本トリガー
- 例:
when working in repo deskrexai/app
-
When designing React hooks in {レポジトリ名}- 特定の作業タイプに関する専門知識を呼び出すためのトリガー
- 例:
When designing React hooks in deskrexai/app
-
When encountering TypeScript errors in {レポジトリ名}- エラー対応に特化した知識を呼び出すためのトリガー
- 例:
When encountering TypeScript errors in deskrexai/app
Devinによる自律的なトリガー設計のポイント
トリガーのシーンはDevinが勝手に考えてくれるので、特にこちら側から検討する必要はありません(意図的に教え込むのを除く)が、以下の観点の設計は参考になります。
-
シーンに基づく分類
- 作業のコンテキストに基づいて知識を分類することで、必要な情報にすばやくアクセスできます
- 細かすぎず、かつ適切な粒度での分類がメモリへのアクセス効率を向上させます
-
包摂的な知識アクセス
- 汎用トリガーと特化トリガーを連携させ、より具体的なコンテキストを優先する設計
- 例えば「When designing React hooks in deskrexai/app」は「when working in repo deskrexai/app」と同時に呼び出されて判断
-
知識と手続きの二重活性化
- 事実知識と実行手順を同時に呼び出す設計
- 「何を知っているか」と「どう実行するか」を効果的に結合
4. Devinの包括的ナレッジアクセスの仕組み
Devinの強みの一つに、複数ナレッジの統合的活用があります。これは、単一のナレッジエントリだけでなく、関連する複数のナレッジを同時に参照・統合する能力です。
複数ナレッジの統合的活用の特徴
-
関連するすべてのナレッジを自動検出
- コンテキストに応じた多角的な知識検索
- 複数の知識を同時に参照・統合する能力
-
階層的なナレッジの組み合わせ
- 一般的なリポジトリ情報と具体的な作業知識を連携
- 抽象レベルの異なる知識の適切な融合
-
コンテキスト理解の深化
- 類似状況の過去経験を踏まえた判断
- 多様な知識源からの包括的な問題理解
この包括的なナレッジアクセスは、人間のエンジニアが複数の経験や知識を組み合わせて判断するプロセスを模倣しています。これにより、より自然で包括的な問題解決アプローチが可能になります。
5. Devinのナレッジ形成のチップス

Devinのナレッジシステムを最大限に活用するためには、効果的なナレッジ形成が不可欠です。運営に聞いて共有してもらったチップスに基づき、ナレッジ形成の重要なポイントをまとめます。
-
ナレッジから自動で優先度を判断
- Devinは関連性に基づいて知識の優先度を自動的に判断します
- 同じトリガーを持つコンテキストでも、内容の関連性によって表示優先度が変わります
-
トリガーの分割は小さい方が効果的
- 大きな包括的なトリガーよりも、小さく特定のコンテキストに特化したトリガーの方が効果的
- 例:「すべての開発関連」より「React開発」「TypeScript開発」のように分割
-
レポジトリに紐づけて効率的に取得
- 特定のレポジトリに紐づけることで、コンテキストが明確になり効率的なナレッジ検索が可能
- 例:
when working in repo {レポジトリ名}の形式を活用
-
ヒエラルキーはないため重複は削除
- DevinのKnowledgeシステムには明示的な階層構造がないため、重複するナレッジは削除すべき
- 複数のナレッジが呼び出される場合は、その優先度はDevinが関連性に基づいて判断
これらのTipsにより、関連する全知識を包括的に活用し、断片的でなく統合的な問題解決アプローチを実現できます。
4. Devinの実践的な応用例

前章では、Devinのメモリシステムの仕組みについて詳しく掘り下げました。本章では、これらの知見を踏まえ、Devinを実際の開発プロジェクトでどのように活用できるかについて、具体的な応用例を紹介します。
1. ペアプログラミング的な活用
Devinはジュニアエンジニアレベルという評価されることが多いですが、ペアプロ形式で一緒に作業することで見通しの難しいタスクでも実行できる真のペアプログラミングパートナーとして機能します。その効果的な活用法を共有します。
Cursorによる設計から始める
Devinとのペアプログラミングは、まず適切な設計から始まります。Devinは単体でも強力ですが、CursorエディタなどのAIコーディングツールから呼び出すことで、よりシームレスな開発体験が可能になります。
-
設計段階からの関与
- Cursorのコードベース理解を使って、まずはコーディングの設計を行う
- この設計のデータをDevinに渡しておくことでワンショットごとに正確にタスクを遂行できる
- レポジトリをDevinと共有することでコミットごとにFBを与えることもできる
レポジトリを自分のローカルで共有しつつ、細かいコミットをさせる指示を行い、単発的に学習サイクルを回すことで、ドメイン→プレゼンテーションまでの新機能開発でも一緒に行うことが可能です。
おすすめのナレッジを覚えさせる
また、効果的なペアプログラミングのために、プロジェクト特有の知識を明示的に教えることが重要です。特に初期の育成では有効な手段です。
-
プロジェクト固有の規約を説明
- コーディング規約やアーキテクチャの方針を具体的に伝える
- 例:「このプロジェクトではエラーハンドリングに特定のパターンを使っている」
これらの情報を明示的に共有することで、Devinはより正確に意図を理解し、プロジェクトの文脈に沿った提案ができるようになります。
成功パターンの記録と再利用
Devinとの協働を継続的に改善するためのポイントとして、前述の通り、細かくかんたんなところからコミットを行います。
-
成功体験の積み重ね
- 小さな成功から始め、徐々に複雑なタスクに挑戦
- 例:「50行程度の小規模な変更から始める」
また、詰まったときは、こちらから参考となるコードをプッシュして学習の機会を与えます。
-
うまくいかないときの対処法
- Devinがうまく動作しない場合は、同じレポから自らプッシュし、それをプルしてもらい学習を促す
- 例:「私のコードから学べることを列挙して学習してください」といった共同学習アプローチ
このように、Devinをペアプログラミングパートナーとして活用することで、単なるコード生成ツールではなく、思考を共有できる開発パートナーとして機能させることができます。特に「言語化しきれていない見通しの難しいタスク」も、対話的なアプローチで解決できるという点が従来のAIツールと大きく異なります。
2. Playbookの活用
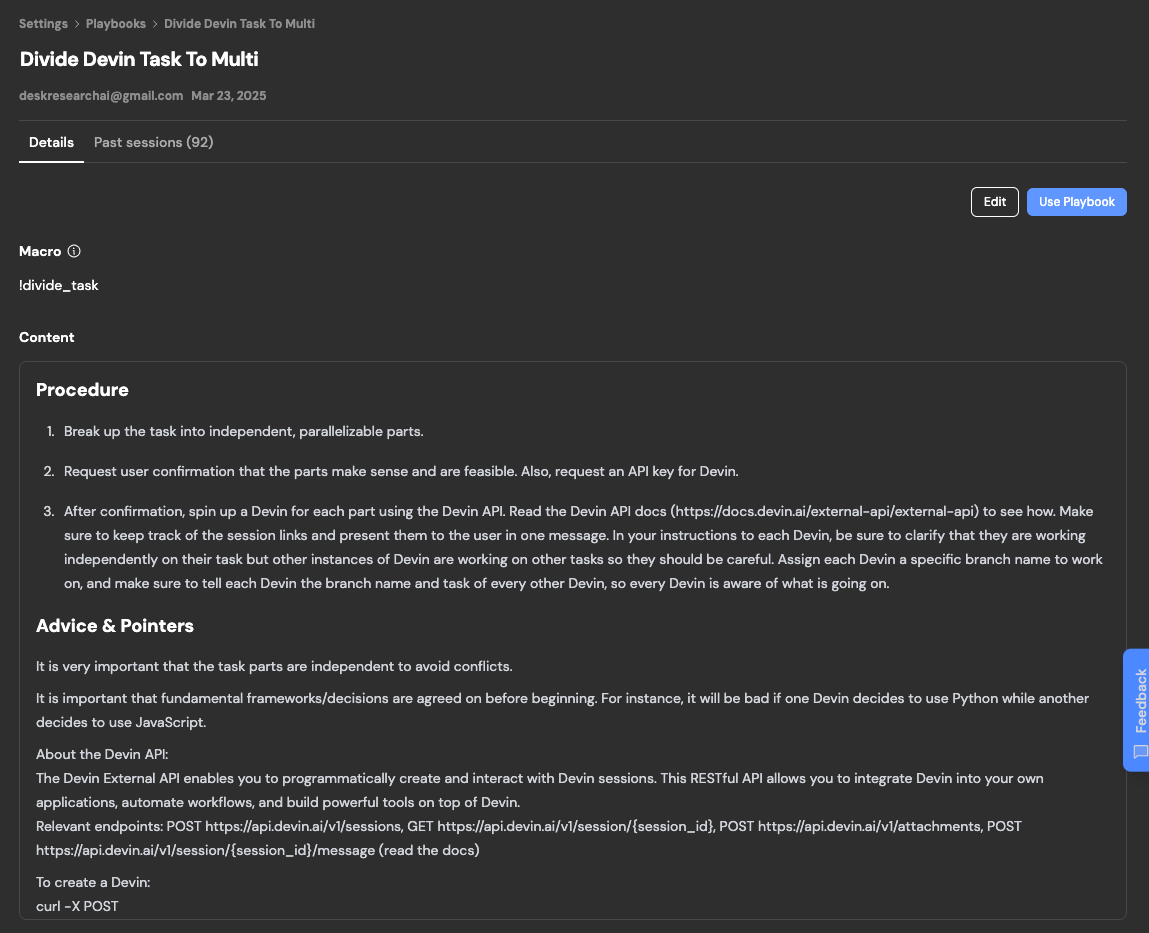
Devinのもう一つの強力な機能はPlaybookです。これは繰り返し実行される作業を効率化し、プロセスの標準化を図るための機能です。
DevinのAPIをコールしてタスクを独立した並列化可能な部分に分割する使い方
例えば、DevinのAPIをコールしてタスクを独立した並列化可能な部分に分割するような高度な活用法も可能です。これは私のアイデアではないですが、Linktreeでは以下のようなプレイブックを活用しているそうです。
-
タスクの自動分割
- 大きな開発タスクを、Devinが自動的に独立した小タスクに分割
- 例:「新しいユーザー管理システムを実装する」というタスクを、「認証機能」「プロフィール管理」「権限設定」などの小タスクに分解
-
依存関係の明確化
- 分割されたタスク間の依存関係を自動的に分析し、実行順序や並列化可能性を判断
- これにより、開発チームは最適な順序でタスクを進められます
-
APIを活用した自動化
- DevinのAPIを活用することで、CI/CDパイプラインなどの自動化プロセスにPlaybookを組み込むことが可能
- GitHubのIssueやプルリクエストに応じて、自動的に適切なPlaybookが実行される仕組みも構築できます
GitHubで公開されているサンプルでは、DevinのAPIを活用して複雑なタスクを分割し、並列実行する方法が示されています。
4. メモリから見る自社のDevinの育成状況可視化
Devinのような高度なAIエージェントを企業に導入する際、その「育成状況」を可視化することで、投資対効果の測定や改善点の特定が可能になります。
育成状況の可視化指標
Devinの育成状況を把握するための主要な指標としては、以下が挙げられます:

-
メモリエントリー状況
- 登録されたナレッジエントリの総数
- カテゴリ別の分布
- 時系列での成長率

-
トピック分析
- 技術スタック別のナレッジカバレッジ
- 知識の偏りや不足領域の特定
- 専門性の深さと広がりのバランス

-
テーマ分析
- 問題解決、設計、実装、テストなどのフェーズ別分布
- チームの作業特性を反映したナレッジの蓄積状態
これらの指標を可視化することで、「AIエージェントの育成余地を可視化する未来」が実現できる可能性があります。しかし、過剰な最適化に陥らないよう、バランスを保つことも重要です。
育成の指標としての活用
Devinのナレッジベースの成長は、以下の観点から組織の成長指標としても活用できます:
-
知識資産の蓄積度
- 組織固有の知識やベストプラクティスの体系化度合い
- 暗黙知の形式知化の進捗度
-
自動化レベルの向上
- 定型作業からの解放度
- 高度な判断を要するタスクへのシフト状況
-
チーム知識の標準化
- 個人に依存しない知識ベースの構築
- 新メンバーのオンボーディング効率化
これらの指標を通じて、単なるツールとしてではなく、組織の知的資産としてのDevinの価値を評価することができます。
Devinの実践的な応用例として、ペアプログラミングパートナーとしての活用、Playbookの効果的な利用、そしてACUを用いた効果測定について紹介しました。これらのアプローチを組み合わせることで、AIを単なるツールではなく、真の開発パートナーとして活用することが可能になります。
特に重要なのは、Devinを使って「何ができるか」ではなく、「どのように組織の開発プロセスと融合させるか」という視点です。技術導入の成功は、最終的にはチームの文化や働き方と調和することで実現します。
次章では、これらの実践例から得られた知見を基に、より効果的なメモリ設計の最適化戦略について探っていきます。
5. メモリ設計の最適化戦略
前章ではDevinの実践的な応用例について探りました。本章では、これらの知見を踏まえ、独自のAIエージェントアプリケーション開発における効果的なメモリ設計の最適化戦略について掘り下げていきます。特に、シーン設計、メモリの抽象化、抽象度のバランスという3つの重要な側面に焦点を当てます。
1. シーン設計の重要性
独自のAIエージェントを構築する際、シーン(場面)に基づいた知識の分類と呼び出しは、効率的なメモリ管理の核心です。シーン設計とは、AIエージェントが異なる作業コンテキストや状況に応じて、適切な知識を呼び出せるようにする設計手法です。
使用コンテキストに基づく分類
効果的なAIアプリケーションでは、使用コンテキストに基づく分類が重要な役割を果たします。具体的には:
-
アプリケーション機能別の分類:
when working in {機能名}というトリガーにより、特定の機能に関連する知識のみを呼び出す -
ユーザータイプによる分類:
when interacting with {ユーザータイプ}というトリガーで、特定のユーザー層に適した知識を活性化 -
タスク特性に基づく分類:
when executing {タスクタイプ}で、特定のタスク(分析、創作、要約など)に最適化された知識を呼び出す
このように、コンテキスト特異性の高いトリガーを設計することで、AIが現在のユーザー状況に関連性の高い知識を包摂的に活用できるようになります。
適切な粒度での情報管理
シーン設計において、情報の粒度は極めて重要な要素です。効果的なAIアプリケーションを構築するために、仮にマクロ、メゾ、マイクロの粒度を設定したとします。
-
マクロレベル: アプリケーション全体の目的やコンセプトに関する包括的な情報
- 例:
when explaining app purpose→ アプリケーションの全体像、主要機能、価値提案
- 例:
-
メゾレベル: 特定の機能領域やユーザージャーニーに関する情報
- 例:
when guiding user through onboarding→ オンボーディングプロセスの詳細とベストプラクティス
- 例:
-
マイクロレベル: 特定の操作や問題解決に関する詳細情報
- 例:
when troubleshooting login errors→ ログインエラーの種類別解決方法
- 例:
例えば、この3段階の粒度設計により、AIは状況に応じて適切な抽象度レベルの知識にアクセスできるのかもしれません。
アクセス効率を考慮した設計
独自アプリケーションのシーン設計では、知識へのアクセス効率も重視する必要があります。効率的なアクセスのための設計原則として、以下のような命名規則を設定することができるかもしれません。
-
トリガーの明確性: 具体的で一義的なトリガーを使用する
- 効果的:
when user asks about pricing plans - 非効果的:
when user has questions(範囲が広すぎる)
- 効果的:
-
トリガーの階層性: より具体的なトリガーが一般的なトリガーよりも優先される設計
- 例:
when enterprise user asks about pricing>when user asks about pricing
- 例:
-
ユーザー状態の考慮: ユーザーの現在の状態(初心者/熟練者、無料/有料など)を加味したトリガー
- 例:
when new user encounters feature limitations
- 例:
これらの原則に基づいてシーンを設計することで、知識アクセスの精度と速度を大幅に向上させることができます。
2. メモリの抽象化
AIアプリケーション開発では、膨大な情報をどのように抽象化して保存・検索するかが大きな課題です。効果的な抽象化のための重要な戦略を考察します。
必要最小限の情報保持
効果的なメモリ抽象化には、情報を詰め込みすぎず、必要最小限のアプローチが有効です:
-
本質的な概念の優先: 細部よりも本質的な概念や原則を優先して保存
- 例:製品説明では、すべての詳細機能ではなく、中核的な価値提案と主要機能を優先
-
代表的なユースケース: すべての可能性ではなく、代表的なユースケースを保存
- 例:トラブルシューティングでは、最も一般的な問題パターンとその解決策を優先
-
転用可能な知識: 様々な状況に応用できる汎用性の高い知識を重視
- 例:異なるユーザーシナリオに適用できる対応原則
この「必要最小限」の原則により、メモリの肥大化を防ぎながら、本質的な知識の密度を高めることが可能になります。おそらく、Devinでもいわゆる512トークンなども適切なトークン数を設定して、適切な長さでナレッジを設計することで、検索精度が向上させていると思われます。もしくはコードベースを読み込んだときに、いくつかの主要なキーワードを意味論的にグルーピングしてGraphにしている可能性もあるかもしれません。
効率的な検索のための最適化
メモリの抽象化においては、検索効率を高めるための最適化も重要です:
-
キーワードの戦略的配置: 検索で引っかかりやすいキーワードを要所に配置
- 例:
when user needs help with subscription management(「subscription management」というキーワードが明確)
- 例:
-
関連概念のグループ化: 相互に関連する概念をグループ化して保存
- 例:支払い関連のすべての情報を論理的にグループ化
-
ユーザーの意図理解: ユーザーが同じ質問を異なる言い方で表現することを想定した設計
- 例:「料金はいくら?」「プランの価格は?」「支払いはどうなる?」などの多様な表現を同じ知識にマッピング
これらの最適化により、AIは現在のユーザーコンテキストに最も関連性の高い知識を迅速かつ正確に検索できるようになります。
不要なメモリの適切な廃棄
効率的なメモリ管理には、不要になった情報を適切に廃棄するメカニズムも重要です:
-
鮮度による管理: 各知識エントリに有効期限を設定し、定期的に更新
- 例:料金プランや機能説明は製品の更新に合わせて自動的に見直し
-
使用頻度の測定: アクセス頻度の低い知識は優先度を下げるか無効化
- 例:3ヶ月間アクセスされていない情報は再評価
-
競合情報の解決: 矛盾する情報が存在する場合、より信頼性の高い情報を優先
- 例:公式ドキュメントからの情報 > ユーザーフィードバックからの情報
-
判断軸の構築: すべての関連するメモリを呼び出して、現状と合わせて判断を下す
- 例:
when user asks about pricing plans→ 料金プランの説明と価格表を呼び出して、現在のユーザーの状況に合わせて判断を下す
- 例:
これらの戦略により、メモリの肥大化を防ぎながら、知識の質と整合性を維持することができます。
3. 抽象度のバランス
AIアプリケーション開発において、具体的な情報と抽象的な知識のバランスを取ることは非常に重要です。適切な抽象度バランスにより、AIは特定の状況に対応しながらも、一般的な原則に基づいて新しい状況に適応できるようになります。
階層的な知識構造の設計
抽象度のバランスを効果的に管理するには、Devinのように階層的な知識構造が参考になるかもしれません。知識保存のタイミングで既定している抽象度にトリガーを設定するなどの工夫が考えられます。
-
基盤となる原則レイヤー: アプリケーションの目的や価値観
- 例:ユーザー中心設計の原則やアクセシビリティの基準
-
ドメイン固有の知識レイヤー: アプリケーションが扱う特定のドメインに関する知識
- 例:金融、健康、教育など特定分野に関する専門知識
-
インタラクションパターンレイヤー: ユーザーとの対話の型や流れ
- 例:初回利用者へのガイダンス、トラブルシューティング対応、アップセルの提案など
-
具体的な応答レイヤー: 特定の質問や状況に対する具体的な応答
- 例:特定の機能の使い方や特定の問題への対処法
この階層構造により、AIは一般的な原則から具体的な応答まで、シームレスにナビゲートできるようになります。
4. 職業別スキルマップに基づくAIメモリ構築手法
人間の職業スキルマップをモデルとしたAIメモリ構築は、特定の専門領域(例:エンジニア、デザイナー、マーケター)に特化したAIエージェントを開発する上で極めて効果的なアプローチです。この手法では、人間の専門家が持つ知識や技能の構造を詳細に分析し、AIのメモリシステムとして再構築します。

エンジニアスキルマップモデル
エンジニアを例に取ると、以下のようなスキルマップモデルを構築できます:
1. 技術スキル層
-
言語・フレームワーク知識
- トリガー:
when discussing {言語/フレームワーク} in {コンテキスト} - 例:
when discussing TypeScript type systems in front-end development - 内容: 構文、ベストプラクティス、一般的なパターン、既知の制限など
- トリガー:
-
アーキテクチャ設計知識
- トリガー:
when designing {アーキテクチャタイプ} for {アプリケーションタイプ} - 例:
when designing microservices for high-traffic e-commerce sites - 内容: 設計原則、トレードオフ、スケーラビリティ考慮点
- トリガー:
-
テスト・品質保証知識
- トリガー:
when implementing {テストタイプ} for {機能タイプ} - 例:
when implementing unit tests for authentication flows - 内容: テスト戦略、カバレッジ基準、自動化アプローチ
- トリガー:
2. プロセススキル層
-
プロジェクト管理能力
- トリガー:
when estimating {タスクタイプ} in {プロジェクトフェーズ} - 例:
when estimating refactoring efforts in legacy systems - 内容: 見積もり手法、リスク分析、優先順位付け
- トリガー:
-
コード管理・レビュースキル
- トリガー:
when reviewing {コードタイプ} in {開発コンテキスト} - 例:
when reviewing API implementation in collaborative projects - 内容: コードレビュー基準、フィードバック方法、変更管理手順
- トリガー:
3. 対人スキル層
-
チームコラボレーションスキル
- トリガー:
when collaborating with {チームロール} on {課題タイプ} - 例:
when collaborating with designers on UI implementations - 内容: 役割間コミュニケーション、期待値調整、フィードバック交換
- トリガー:
-
クライアントコミュニケーション
- トリガー:
when explaining {技術トピック} to {ステークホルダータイプ} - 例:
when explaining technical constraints to non-technical stakeholders - 内容: 専門用語の翻訳、視覚化手法、トレードオフの説明
- トリガー:
4. メタ認知スキル層
-
問題解決・デバッグ思考
- トリガー:
when debugging {問題パターン} in {システムタイプ} - 例:
when debugging performance issues in data-intensive applications - 内容: 体系的診断プロセス、根本原因分析、仮説検証アプローチ
- トリガー:
AIエージェントに人間のエンジニアのような多面的な思考能力を実装する方法を考えるために、このようなスキルマップを網羅的に検討することも設計段階では有効でしょう。
異なる職業への応用
このアプローチは他の職業にも応用可能です:
デザイナー向けメモリモデル
- デザイン理論層:色彩理論、視覚心理学、情報階層など
- ツール技術層:デザインツール、プロトタイピング手法など
- ユーザー理解層:ユーザーリサーチ、ペルソナ開発、共感設計など
- コラボレーション層:エンジニアとの協働、クライアント提案など
マーケター向けメモリモデル
- 戦略思考層:市場分析、競合調査、ポジショニングなど
- チャネル専門層:各マーケティングチャネルの特性と最適化
- 分析能力層:データ解釈、KPI設定、ROI評価など
- クリエイティブ層:コピーライティング、視覚的ストーリーテリングなど
このようなMECE(Mutually Exclusive, Collectively Exhaustive)な職業スキルマップに基づくメモリ設計により、AIエージェントは特定の専門領域において、人間の専門家に近い判断能力を獲得することができます。
5. 技術的・対人的メモリの統合
人間のエンジニアのメモリ構造を参考に、AIアプリケーションにはハードスキル的な技術的知識だけではなく、ソフトスキル的な対人関係メモリを統合することも可能です。人によってはDevinの口調や言語を意図的に操作している事例もたまに見ます。
対人関係メモリの実装
-
ユーザーペルソナ対応: 異なるユーザータイプに合わせた対応の最適化
- 例:初心者向け、上級者向け、管理者向けの異なる対応スタイル
-
感情認識と対応: ユーザーの感情状態を認識し適切に対応
- 例:混乱しているユーザー、焦っているユーザー、探索的なユーザーへの最適な対応
-
会話の文脈記憶: 会話の流れを記憶し、一貫性のある対話を維持
- 例:過去の質問と回答を参照した応答の生成
キャラクター系や仲介系など、密にコミュニケーションを取るタイプのエージェントが設計される場合は、もしかしたら技術的知識以上に、対人的メモリの統合が競争優位性の源泉になる可能性がありそうです。
6. メタ認知的アプローチの導入
より高度なAIアプリケーションには、メタ認知的な能力を実装することも重要です。
自己評価メカニズム
-
回答品質の自己評価: 提供した回答や支援の有効性を評価する仕組み
- 例:「この回答はユーザーの問題解決に役立ったか?」を内部で評価
-
知識ギャップの認識: 自身の知識の限界を認識し、適切に対応
- 例:「この質問に答えるには情報が不足している」と判断できる能力
-
継続的学習プロセス: ユーザーフィードバックからの学習と改善
- 例:ユーザーの反応パターンから効果的な説明方法を学習
状況適応型思考
-
ユーザー状態の推論: 限られた情報からユーザーの状況を推測
- 例:質問の内容や表現から、ユーザーの熟練度や現在の状態を推測
-
先回り思考: ユーザーの次のステップを予測し、先回りして情報提供
- 例:「この後、多くのユーザーは〇〇について質問します」と予測
-
複数視点の考慮: 問題を複数の角度から検討する能力
- 例:技術的観点、ユーザビリティ観点、ビジネス価値観点など
これらのメタ認知能力は、ある意味リランカー的に動作し、AIエージェントに「考えることについて考える」能力を付与し、より適応的で知的な支援を提供することを可能にできるかもしれません。
まとめ

効果的なAIアプリケーション開発のためのメモリ設計には、以下の要素を考えることができます。
-
コンテキスト認識型のシーン設計: ユーザーの状況に応じた最適な知識の活性化
-
多層的な情報構造: マクロ、メゾ、マイクロの3段階の粒度で情報を管理
-
必要最小限の情報と抽象化: 本質的な知識に焦点を当て、メモリの肥大化を防ぐ
-
階層的な知識構造: 原則から具体的な応答まで、シームレスにナビゲート
-
職業別スキルマップの活用: 人間の専門家の知識構造を模倣した体系的メモリ設計
-
技術的・対人的メモリの統合: 製品知識と対人対応能力の融合
-
メタ認知的アプローチ: 自己評価と継続的改善の仕組み
これらの原則を組み合わせることで、AIアプリケーションは効率的かつ効果的に知識を管理・活用できるようになり、より自然で人間らしい支援が可能になるでしょう。
次章では、これらのメモリ設計原則を実際の自社サービスにどのように組み込むか、具体的な実装アプローチについて考察していきます。
6. 自社サービスにメモリをどう組み込むか
前章では、効果的なメモリ設計の原則と最適化戦略について探りました。本章では、Devinのナレッジベース分析から得られた知見を活用し、自律的に動作するAIエージェントを自社サービスにどのように実装できるかを考察します。特に入出力設計、AI自律的思考、長期記憶活用の観点から、実践的なアプローチを検討していきます。

1. 入出力設計とメモリの連携
自律的AIエージェントの成功は、ユーザーとのインタラクションとAIのメモリシステムを有機的に連携させることから始まります。
シーンベースのメモリ活性化
Devinのナレッジベース分析から明らかになったように、シーン(場面)に基づいた記憶の活性化はユーザー入力の文脈を正確に理解する鍵となります。自社サービスでは、以下のような記憶活性化の設計が効果的です。
-
コンテキスト認識入力処理
- ユーザーの入力に応じて、関連するメモリセットを自動的に呼び出す
- 例:「React Hooksのパフォーマンス最適化について」という入力に対して、「React」「フック」「パフォーマンス」に関連するメモリを階層的に活性化
- 実装方法:
when discussing React hooks in performance contextのようなトリガーパターンを設計
-
意図認識メカニズム
- 曖昧な入力に対して、AIが自ら「ユーザーは何について知りたいのか」を推論する能力
- 例:「このエラーの原因は?」という質問に対して、直前の会話やユーザーの行動履歴から文脈を補完
- 実装方法:マクロ(全体的な対話の流れ)、メゾ(現在のタスク)、ミクロ(直前の発言)の3階層でコンテキストを分析
-
使用コンテキストに基づく記憶分類
- ユーザーの使用状況(初回利用、問題解決中、機能探索中など)に応じた記憶の分類
- 例:トラブルシューティング中のユーザーには問題解決に特化したメモリセットを優先
- 実装方法:
when troubleshooting {問題種類} for {ユーザータイプ}のようなメモリ分類
これらの仕組みにより、AIエージェントは単なる質問応答ではなく、ユーザーの状況や意図を深く理解した対話が可能になります。
多層的なメモリアクセス戦略
自律的AIエージェントでは、多層的なメモリアクセス戦略が重要です。以下のようなアプローチが効果的です:
-
情報の粒度に基づく段階的アクセス
- マクロレベル:サービス全体の目的や価値観(常にアクセス可能)
- メゾレベル:特定の機能領域や使用シナリオに関する知識(コンテキストに応じてアクセス)
- マイクロレベル:特定の操作や問題に対する詳細知識(具体的な質問に応じてアクセス)
- 実装方法:階層的なトリガーシステム(一般的なトリガーから具体的なトリガーへの連鎖)
-
予測的メモリロード
- ユーザーの行動パターンから次のアクションを予測し、関連メモリを先行的にロード
- 例:APIドキュメントを閲覧しているユーザーには、実装例や一般的なエラーパターンを事前に準備
- 実装方法:ユーザー行動の時系列分析と予測モデルの構築
-
アクセス効率の動的最適化
- 使用頻度や有用性に基づいてメモリアクセスの優先度を動的に調整
- 例:特定のユーザーに頻繁に参照される情報は「ショートカットメモリ」として優先的にアクセス可能に
- 実装方法:メモリエントリごとのアクセス統計と自動的な再構成メカニズム
これらの戦略により、AIエージェントはリソース制約の中でも効率的に知識を活用し、より迅速で的確な応答を提供できる可能性がありそうです。
インタラクションモデルの高度化
自律的AIエージェントのインタラクションモデルは、単なる質問応答を超えた多次元的なものである必要があります。より継続的なアシスタント的な正確がある場合は、よりソフトスキル的な記憶を強化することがで検討できそうです。
-
会話の文脈維持と発展
- 長時間のセッションでも一貫した文脈を維持するメモリ管理
- 例:キーポイントを「アンカーメモリ」として保存し、話題が変わっても必要に応じて参照
- 実装方法:重要な情報に「持続性」の属性を付与し、通常のコンテキストウィンドウを超えて保持
-
マルチモーダル記憶の統合活用
- テキスト、コード、図表、操作履歴など異なる形式の情報を統合した意思決定
- 例:「このコンセプトは図表で説明すべきか、コード例で説明すべきか」を自律的に判断
- 実装方法:各モダリティのエンコーダと統合レイヤーの実装
-
対話の個性化と適応
- ユーザーの習熟度、好み、過去のインタラクションに基づく対話スタイルの最適化
- 例:技術的背景が豊富なユーザーには専門用語を活用し、初心者には基本概念から説明
- 実装方法:ユーザープロファイリングと対話スタイル調整パラメータの設計
このようなインタラクションモデルにより、AIエージェントはより人間的で、継続的な対話を実現できます。
2. 自律的思考と意思決定プロセス
真に自律的なAIエージェントには、メモリを活用した内部的な思考・意思決定プロセスが不可欠です。
職業別スキルマップに基づく思考モデル
人間の専門家(エンジニア、デザイナー、マーケターなど)の思考プロセスをモデル化し、AIエージェントに実装することが効果的です:
-
エンジニア思考モデルの実装
- 技術スキル層:言語・フレームワーク知識、アーキテクチャ設計思考、テスト戦略など
- プロセススキル層:プロジェクト管理、コードレビュー思考、ドキュメンテーション能力
- 対人スキル層:チームコラボレーション、メンタリング能力、クライアントコミュニケーション
- メタ認知スキル層:問題解決アプローチ、学習・適応能力、キャリア成長視点
- 実装方法:各スキル領域の知識を「when working as engineer on {タスク種類}」などのトリガーで活性化
-
スキルの相互連関性のモデリング
- スキル間の関連性や依存関係を明示的にモデル化
- 例:「フロントエンド開発」と「UX設計」の関連性を定義し、適切なタイミングで両方の知識を活用
- 実装方法:スキル間の連携トリガー(
when optimizing frontend, consider UX principles)の設計
-
熟達度レベルの段階的実装
- 各スキル領域における初級〜上級レベルの知識を段階的に定義
- 例:データベース設計の初級(基本的なCRUD操作)から上級(複雑なパフォーマンス最適化)までの知識階層
- 実装方法:ユーザーの質問レベルに応じた適切な抽象度の知識提供
このような専門家の思考モデルを実装することで、AIエージェントはより構造化された意思決定が可能になります。
メタ認知的アプローチの実装
自律的AIエージェントには、自己の思考プロセスを監視・評価・調整するメタ認知能力が重要です:
-
自己評価と継続的改善
- 提供した回答や判断の質を自己評価するメカニズム
- 例:「この回答はユーザーの問題解決に役立ったか?」を内部で評価し、成功パターンを強化
- 実装方法:回答の有用性指標の定義と自己フィードバックループの構築
-
知識の境界認識
- 自身の知識の限界を明確に認識し、それに基づいて行動を選択
- 例:「この質問に答えるには情報が不足している」と判断し、追加情報を要求するか外部リソースを参照
- 実装方法:確信度スコアリングと閾値に基づく行動選択
-
多視点思考の実装
- 問題を複数の角度から検討する能力
- 例:技術的観点、ユーザビリティ観点、ビジネス価値観点などから総合的に判断
- 実装方法:異なる「思考フレーム」の定義と問題に応じた適用
内部状態と意思決定プロセスの透明化
自律的AIエージェントの信頼性を高めるためには、内部状態と意思決定プロセスの透明化も重要です。Open AIのDeep Researchの意思決定プロセスの表示のように、エージェントの意思決定が見えることが勝ちになるユースケースも存在します。
-
思考過程の可視化
- 重要な判断においては、どのような情報に基づいてその結論に至ったかを説明
- 例:「この推奨事項は、A, B, Cの情報と、X, Yの原則に基づいています」
- 実装方法:意思決定に使用したメモリエントリとその重みづけの記録
-
不確実性の明示
- 判断の確信度や代替案の存在を明示する能力
- 例:「80%の確信度でこの解決策を提案しますが、条件Xが異なる場合は別のアプローチも検討すべきです」
- 実装方法:確信度モデルと代替仮説の管理システム
-
意思決定の説明可能性
- 専門的判断の背景にある理由を、ユーザーの理解レベルに合わせて説明する能力
- 例:技術的決定の背景を非技術者にも理解できるように説明
- 実装方法:異なる抽象度レベルでの説明テンプレートの用意
このような透明性により、ユーザーはAIエージェントの判断をより深く理解し、適切に評価できるようになります。また、正しいコミュニケーションの仕方を理解することもできるでしょう。
3. 長期記憶と継続的学習の実装
自律的AIエージェントの価値を最大化するためには、長期記憶の効果的な活用と継続的な学習メカニズムが不可欠です。
継続的学習と知識更新メカニズム
自律的AIエージェントは、常に進化する知識領域に対応するため、継続的な学習と知識更新の仕組みが必要です。これこそエージェントを常に進化させる仕組みに寄与すると考えられます。
-
ユーザーインタラクションからの学習
- ユーザーとの対話から新しい知識や有用なパターンを学習
- 例:「この説明方法がユーザーの理解を促進した」という成功パターンの抽出と強化
- 実装方法:肯定的フィードバックを受けた説明パターンの優先度向上
-
知識の鮮度管理
- 情報の有効期限管理と更新の優先順位付け
- 例:テクノロジートレンドやライブラリのバージョン情報など、変化の早い知識の定期的更新
- 実装方法:各知識エントリに鮮度スコアを付与し、低スコアのエントリを優先的に更新
-
外部知識源との連携
- 公式ドキュメント、コミュニティフォーラム、最新研究論文などの外部情報源との連携
- 例:新しいフレームワークリリースや重要なセキュリティアップデートの自動取り込み
- 実装方法:外部APIとの連携と定期的なクローリングシステム
記憶の文脈化と関連性強化
単なる事実の蓄積ではなく、文脈に埋め込まれた知識として記憶を組織化することもAIエージェントの種類によってはあり得るかもしれません。他方で過度に記憶をためすぎるのも、負債になる気もしていますのでケースバイケースといえます。
-
連想記憶ネットワークの構築
- 関連する概念や知識を有機的に結びつけるネットワーク構造
- 例:「Reactフック」→「状態管理」→「パフォーマンス最適化」→「メモ化テクニック」といった連想チェーン
- 実装方法:知識グラフとエンベディングの組み合わせによるハイブリッドアプローチ
-
時間的文脈の保持
- 知識の時間的変遷や進化を理解する能力
- 例:「この設計パターンは、以前は標準的でしたが、現在はより効率的な代替手法が推奨されています」
- 実装方法:知識エントリへのタイムスタンプと変遷履歴の付与
-
ユースケースベースの知識組織化
- 実際の使用状況に基づいて知識を組織化
- 例:「初めてAPIを実装するとき」「既存システムの最適化をするとき」などのユースケースに紐づけた知識構造
- 実装方法:ユースケーステンプレートとそれに関連する知識のマッピング
このような文脈化により、AIエージェントは単一の事実だけでなく、その背景や関連知識を含めた包括的な支援が可能になります。これは手続き的な記憶の動的な生成にも繋がる可能性があるかもしれません。
4. 実装上の考慮点と実践的アプローチ
自律的AIエージェントを自社サービスに実装するにあたり、考慮すべき実践的なポイントを検討します。

段階的実装のロードマップ
全ての機能を一度に実装するのではなく、段階的な実装アプローチが効果的です:
-
フェーズ1:基本的な応答能力
- コア領域の知識ベース構築
- 基本的なコンテキスト認識メカニズム
- 単一セッション内での文脈維持
-
フェーズ2:拡張記憶と学習能力
- 長期的なユーザープロファイリング
- インタラクションからの継続的学習
- 多層的なメモリアクセス戦略の実装
-
フェーズ3:完全自律的思考
- メタ認知能力の実装
- 自己評価と改善メカニズム
- 高度な意思決定プロセスの透明化
メモリ自体が競争優位になる可能性はありつつも、必須の機能要件になるかは未知数なところも多く、ミニマムにユーザー価値をテストする必要があります。
まとめ
Devinのナレッジベース分析と最適なメモリ設計戦略の知見を活用することで、真に自律的なAIエージェントを自社サービスに実装することが可能です。シーンベースのメモリ活性化、職業別スキルマップを活用した思考モデル、多層的な知識構造、そしてメタ認知能力を備えたAIエージェントは、単なるツールではなく、ユーザーの真のパートナーとして機能するでしょう。
自律的AIエージェントの実装は一朝一夕には実現できませんが、本章で示した段階的アプローチと実践的な考慮点を踏まえることで、確実にその目標に近づくことができます。最終的には、AIエージェントはユーザーの意図を深く理解し、専門知識を適切に活用して、価値ある支援を提供する存在となるでしょう。
次章では、AIエージェントのメモリシステムの今後の発展方向性と、業界全体における論点について探っていきます。
7. AIエージェントのメモリの今後の論点
前章まで、Devinのメモリシステムの分析と自社サービスへの実装方法について詳しく見てきました。本章では、AIエージェントのメモリシステムに関する今後の重要な論点と発展可能性について考察します。業界全体の動向を踏まえつつ、競争優位性の源泉としてのメモリ設計について探っていきましょう。

1. 強化学習との棲み分け
AIエージェントのメモリシステムと強化学習アプローチには、それぞれの強みと適用領域があります。今後、両者の棲み分けと統合が重要な論点となるでしょう。
エッジケースの抽象的な記憶
強化学習は一般的なパターンを効率的に学習できますが、稀にしか発生しないエッジケースへの対応においては、明示的なメモリシステムに優位性があります:
-
失敗パターンの暗黙知保存
- 強化学習では捕捉しにくい「一度だけ遭遇した重大な失敗」のような事例を記録
- 例:特定の条件下でのみ発生するバグや異常ケースの記憶
- 実装例:
when encountering error pattern similar to {特定の失敗事例}のようなトリガー
-
文脈依存事例の凍結
- 確率論的アプローチでは一般化されやすい、特定コンテキストに強く依存する例外事例
- 例:「この特定のユーザーに限り、通常とは異なる対応をする」といった例外ルール
- 実装例:ケースライブラリとしてのエピソードメモリ
ユーザーごとの最適化
強化学習が集団の一般的な傾向を捉えるのに対し、メモリシステムは個々のユーザーに特化した最適化に強みを発揮するかもしれません。
-
認知バイアス補正のための参照フレーム
- 各ユーザーの思考パターンや判断バイアスを理解し、それに合わせた情報提供
- 例:詳細志向のユーザーには具体的データ、全体像重視のユーザーには概念的フレームワーク
- 実装例:ユーザーごとの「メンタルモデルメモリ」の構築
-
作業スタイルに適応したショートカット
- ユーザー固有の作業パターンを学習し、最適化された支援を提供
- 例:「このユーザーはいつもこの順序で作業する」という行動パターンの記憶
- 実装例:
when user X is working on task Y, suggest shortcut Z
-
タスク完了の先読み
- 現在のタスクの次に何をするかを予測し、先回りして準備
- 例:ドキュメント作成後に必ず校正を行うユーザーには、先に校正ツールを提案
- 実装例:時系列タスク予測モデル
ハイブリッドアプローチの可能性
今後は、強化学習とメモリシステムを組み合わせたハイブリッドアプローチが主流になると考えられます:
-
強化学習による一般パターンの獲得
- 大量のデータから一般的な法則性を抽出
- 高速かつ効率的な応答生成
-
メモリシステムによる例外処理と個別化
- エッジケースや特定コンテキストへの適応
- ユーザー固有の最適化
おそらく、トッププレイヤークラスは、このハイブリッドアプローチにより、AIエージェントはより柔軟かつ適応的な支援をしていく可能性がありますが、メモリのニッチさはどこまで対応しきれるのかはまだ未知数です。ルールの設定の必要もあります。
2. MVPとしてのメモリ
AIエージェントを開発する際の現実的なアプローチとして、メモリシステムをどのようにMVP(最小限の実用的製品)として設計するかも重要な論点です。
出力精度と導入コストのバランス
メモリシステムの実装には相応のコストがかかるため、導入効果と実装コストのバランスを慎重に検討する必要があります:
-
メモリ実装の効果予測
- どの程度の出力精度向上が見込めるか
- 特にエッジケースの発生率が低い領域では、コスト対効果が低くなる可能性も
-
失敗リスクの許容度評価
- AIエージェントの誤りがビジネスにどの程度の影響をもたらすか
- 高リスク領域ではメモリシステムの実装価値が高まる
途中からAIエージェントにする難しさ
既存のAIサービスを後から「エージェント化」することは技術的にも設計的にも困難な場合が多いため、初期設計の重要性が増しています。ある意味、エージェントに振り切る意思決定がない場合は、往々にして中途半端なLLMアプリケーションになることもありえます。
-
事後的なメモリ統合の課題
- 既存システムにメモリレイヤーを追加する技術的複雑さ
- 過去データの記憶化における構造的問題
-
ユーザー体験の一貫性
- 突然「記憶力が向上した」AIに対するユーザーの違和感
- 長期的な関係性構築の難しさ
3. メモリをAIエージェントの競争優位性(Moat)とするために
前回の発表で示唆したように、AIエージェントのメモリシステムは将来的な競争優位性(Moat)になる可能性があります。この潜在的なMoatを最大化するための戦略を考察します。
協調的メモリエコシステム
単一エージェントのメモリではなく、エージェント間で共有されるメモリエコシステムの構築も将来的に重要になります:
-
集合知の形成
- 複数のAIエージェントによる知識の集約と共有
- 例:あるユーザーとのインタラクションから学んだ知見を他のユーザー支援にも活用
- 実装例:匿名化された知識レポジトリの構築
-
役割別エージェントのメモリ連携
- 異なる役割を持つAIエージェント間での記憶の連携
- 例:分析エージェントが発見したインサイトを、執筆エージェントが報告書に反映
- 実装例:エージェント間のナレッジトランスファープロトコル
-
組織記憶としての発展
- 企業の知的資産としてのAIメモリシステム
- 例:退職者の知識や経験をAIエージェントのメモリとして保存
- 実装例:ナレッジマネジメントとAIメモリの統合
説明可能性と透明性の確保
メモリシステムが競争優位性として機能するためには、ユーザーとの信頼関係構築が不可欠です:
-
記憶活用の可視化
- AIがどの記憶に基づいて判断したかを透明化
- 例:「この提案は過去のプロジェクトXとYの成功事例に基づいています」
- 実装例:判断根拠となった記憶エントリの引用機能
-
記憶編集の制御権
- ユーザーが自分に関するAIの記憶を確認・編集できる権限
- 例:「このエピソードは記憶から削除したい」「この情報は更新したい」
- 実装例:ユーザー制御可能なメモリダッシュボード
-
記憶の継承と移行
- エージェント間やバージョン間での記憶の継承メカニズム
- 例:新しいAIエージェントに過去の関係性や学習内容を引き継ぐ
- 実装例:標準化されたメモリエクスポート・インポートプロトコル
4. AIメモリの進化と将来展望
より長期的な視点で、AIエージェントのメモリシステムがどのように進化していくかを考察します。
メモリの専門化と多様化
将来的には、AIエージェントのメモリシステムはより専門化・多様化し、目的別の記憶構造が発展すると予想されます:
-
創造的連想記憶
- 一見無関係な概念間の創造的な関連付けを促進
- 例:異なるドメインのアイデアを組み合わせた革新的な解決策の生成
- 実装例:拡散型意味ネットワークの構築
-
批判的評価記憶
- 過去の成功・失敗事例に基づく提案内容の批判的評価
- 例:「この解決策は過去のケースXで問題が発生した」
- 実装例:反例検索と整合性チェックシステム
-
社会的関係性記憶
- 複雑な人間関係や社会的コンテキストの理解
- 例:組織図だけでなく、非公式な影響力関係も考慮した対応
- 実装例:明示的・暗黙的関係性を含む社会グラフ
集団的記憶インフラの出現
長期的には、AIエージェント間で共有される集団的記憶インフラが出現する可能性があります。特化型のSLMのようにも思えますが、学習のコストが低いため、意外とメモリパックのOSSみたいなものがでても面白いかもしれません。
-
業界共通知識ベース
- 特定業界の基本知識や慣行に関する共有メモリ
- 例:医療AIエージェント間で共有される医学知識ベース
- 実装例:業界コンソーシアムによる標準メモリデータベース
-
エージェント間経験共有
- 個別AIエージェントの経験を匿名化して共有する仕組み
- 例:ある状況での成功アプローチを他のエージェントも学習可能に
- 実装例:分散型経験データベースと学習連携システム
-
クロスドメイン知識転移
- 異なる専門領域間での知識や問題解決アプローチの転用
- 例:金融で成功した異常検知手法を医療診断に応用
- 実装例:知識アナロジーマッピングシステム
まとめ
AIエージェントのメモリシステムは、今後も技術的進化と実用的な応用の両面で重要な研究・開発領域であり続けるでしょう。特に以下の点がメモリシステムの競争優位性を高める鍵となります:
-
強化学習とメモリの最適な組み合わせ:それぞれの長所を活かしたハイブリッドアプローチ
-
段階的かつ実用的なMVP設計:コストと効果のバランスを考慮した実装戦略
-
環境適応と協調的メモリエコシステム:特定環境への深い適応と複数エージェント間の知識共有
-
透明性と制御可能性の確保:ユーザーとの信頼関係構築を通じた長期的な価値創出
-
専門化・多様化するメモリ構造:目的に応じたメモリ設計と集団的記憶インフラの発展
この発展過程において、デベロッパーやプロダクト設計者は、AIエージェントを単なる質問応答システムではなく、共に成長し、学習し、適応するチームメイトとして設計することが重要です。その中核を担うのが、本記事で探ってきたメモリシステムであると思います。
Devinの事例から学んだように、適切に設計されたメモリシステムは、AIエージェントの能力を飛躍的に向上させ、ユーザーにとっての価値を最大化します。これからのAIエージェント開発において、メモリシステムの設計は単なる技術的要素ではなく、製品の核心的な差別化要因となりえる興味深い機能です。
About me
現在、市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai
ぜひお気軽にチャットしましょう!Devinもいます。
生成AIデスクリサーチサービス Deskrex | サービスページ
生成AIデスクリサーチエージェント Deskrex App | アプリケーションサイト
DeskrexAIリサーチ | メディア
株式会社Deskrex | 会社概要
Deskrex | Xページ
- 会社概要:https://www.deskrex.ai/
- Deskrex App:https://app.deskrex.ai/
- サービスページ:https://lp.deskrex.ai/
- メディア:https://media.deskrex.ai/
- X:https://x.com/deskrex

Discussion