Transformer に触れてみる (1)
目的
- 機械学習エンジニアのためのTransformers をパラパラめくってもさっぱり理解できる気がしない。
- arXiv:1706.03762 Attention Is All You Need のいつもの N 字型のアーキテクチャを見るのはもう飽きた。
のを何とかしたい。
Vibe coding
そこで時代の波に乗って、GPT-4.1 にお願いして vibe coding で学習素材を作らせた。勿論生産性爆上がりなので一気に凄いものができてしまった・・・ということは勿論なくて、試行錯誤を繰り返し何時間もリテイクしまくって、漸く動くようになった。勿論自分でも調べて、「エラーはこうすれば直るんじゃ?」と一緒にも考えた。
作ったもの
- タスクの内容:
input_seq = ["<BOS>", "f", "l", "y", "c", "a", "t", "c", "h", "e", "r", "<EOS>", "<PAD>", "<PAD>"]からoutput_seq = ["f", "l", "y", "c", "a", "t", "c", "h", "e", "r", "<EOS>", "<PAD>", "<PAD>"]を自己回帰的に求める、つまり次の 1 文字を予測するタスク[1] を考慮。 - データセットには動物、果物、野菜の名前からなる数百個の単語を利用。強い傾向があるわけでも、大量のデータがあるわけでもないので、モデルの学習における汎化性能は大きくは期待できない。
-
Attention Is All You Need に近い形の Transformer の実装である
FullTransformerと、そのアーキテクチャを大幅に簡易化したMiniFormerを用いて比較を行う。 -
FullTransformerはエンコーダ・デコーダアーキテクチャで、MiniFormerはエンコーダ・デコーダを持たない「自己回帰的セルフアテンション層」のみのモデル。 -
FullTransformerはデコーダのセルフアテンション(4 ヘッド)を、MiniFormerは「自己回帰的セルフアテンション層」(1 ヘッド)を可視化。
※ 結果の画像を見せると、多少の見え方の違いはあるが、概ね整合性のある結果になっていると GPT-4.1 は評価している。
実装
全部を理解できていないので、単純に貼り付ける。Google Colab 上で実行する。NVIDIA T4 で実行できる。訓練は FullTransformer のほうでも 1 分程度なのですぐ完了する。
準備やデータセット
ざっと眺めると、何となくこんな感じで良さそうに感じる。
!pip install -qU bertviz
from __future__ import annotations
import json
import random
import string
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import numpy as np
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED)
ANIMALS = [
"cat",
"caracal",
"capybara",
"canary",
"cavy",
"caiman",
"cacomistle",
"caribou",
"cassowary",
"caterpillar",
"dog",
...
] # 長いので割愛
FRUITS_VEGGIES = [
"apple",
"apricot",
"avocado",
"artichoke",
"banana",
"bilberry",
"blackberry",
"blueberry",
"boysenberry",
"breadfruit",
"cantaloupe",
"casaba",
...
] # 長いので割愛
# 1. データセット用:動物名+果物・野菜名で計1000種弱
NAMES = ANIMALS + FRUITS_VEGGIES
# 2. 文字のボキャブラリ作成
ALL_CHARS = sorted(set("".join(NAMES)))
SPECIAL_TOKENS = ["<PAD>", "<BOS>", "<EOS>"]
ALL_TOKENS = SPECIAL_TOKENS + ALL_CHARS
VOCAB_SIZE = len(ALL_TOKENS)
CHAR2IDX = {ch: i for i, ch in enumerate(ALL_TOKENS)}
IDX2CHAR = {i: ch for ch, i in CHAR2IDX.items()}
PAD_IDX = CHAR2IDX["<PAD>"]
BOS_IDX = CHAR2IDX["<BOS>"]
EOS_IDX = CHAR2IDX["<EOS>"]
def encode_word(word, max_len):
tokens = [BOS_IDX] + [CHAR2IDX[c] for c in word] + [EOS_IDX]
tokens += [PAD_IDX] * (max_len - len(tokens))
return tokens
def decode_tokens(tokens):
chars = []
for idx in tokens:
if idx == EOS_IDX:
break
if idx >= len(IDX2CHAR):
continue
ch = IDX2CHAR[idx]
if ch not in SPECIAL_TOKENS:
chars.append(ch)
return "".join(chars)
# 3. PyTorch Dataset
class NameDataset(Dataset):
def __init__(self, words, max_len):
self.max_len = max_len
self.data = []
for w in words:
tokens = encode_word(w, max_len)
self.data.append(tokens)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
tokens = self.data[idx]
x = torch.tensor(tokens[:-1], dtype=torch.long)
y = torch.tensor(tokens[1:], dtype=torch.long)
return x, y
MiniFormer
セルフアテンションや FFN があるので何となくそれっぽい。逆にそれしかないので、Transformer としては驚異的にシンプル。
# 4. シンプルな位置エンコーディング
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
if d_model > 1:
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe)
def forward(self, x):
# x + self.pe[:x.size(1)].unsqueeze(0)
return x + self.pe[:x.size(1)]
# 5. MiniFormer本体(シングルヘッド、1層)
class MiniFormer(nn.Module):
def __init__(self, vocab_size, d_model=32, max_len=16):
super().__init__()
self.d_model = d_model
self.embed = nn.Embedding(vocab_size, d_model)
self.pos_enc = PositionalEncoding(d_model, max_len)
# シングルヘッドAttention
self.q_linear = nn.Linear(d_model, d_model)
self.k_linear = nn.Linear(d_model, d_model)
self.v_linear = nn.Linear(d_model, d_model)
self.attn_out = nn.Linear(d_model, d_model)
# FFN
self.ffn = nn.Sequential(
nn.Linear(d_model, d_model),
nn.ReLU(),
nn.Linear(d_model, d_model)
)
self.ln1 = nn.LayerNorm(d_model)
self.ln2 = nn.LayerNorm(d_model)
self.fc_out = nn.Linear(d_model, vocab_size)
self.max_len = max_len
self.attn_weights = None # for visualization
def forward(self, x, return_attn=False):
emb = self.embed(x)
emb = self.pos_enc(emb)
# Attention
Q = self.q_linear(emb)
K = self.k_linear(emb)
V = self.v_linear(emb)
scores = torch.matmul(Q, K.transpose(-2, -1)) / np.sqrt(self.d_model)
# causal mask
mask = torch.triu(torch.ones(scores.size(-2), scores.size(-1)), diagonal=1).bool().to(x.device)
scores = scores.masked_fill(mask, float('-inf'))
attn = torch.softmax(scores, dim=-1)
attn_out = torch.matmul(attn, V)
attn_out = self.attn_out(attn_out)
x1 = self.ln1(emb + attn_out)
x2 = self.ln2(x1 + self.ffn(x1))
logits = self.fc_out(x2)
if return_attn:
self.attn_weights = attn.detach().cpu().numpy()
return logits, attn
return logits
訓練ループ
# 6. 訓練ループ
def train(model, loader, optimizer, criterion, device):
model.train()
total_loss = 0
for x, y in loader:
x = x.to(device)
y = y.to(device)
optimizer.zero_grad()
logits = model(x)
loss = criterion(logits.view(-1, VOCAB_SIZE), y.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
def evaluate(model, loader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device)
logits = model(x)
loss = criterion(logits.view(-1, VOCAB_SIZE), y.view(-1))
total_loss += loss.item()
return total_loss / len(loader)
# 7. 可視化用attention保存関数 (BertViz 形式に近いJSON)
def save_attention(attn_matrix, input_tokens, filename="attn_weights.json"):
# attn_matrix: [seq_len, seq_len]
data = {
"tokens": input_tokens,
"attentions": attn_matrix.tolist()
}
with open(filename, "w") as f:
json.dump(data, f, indent=2)
学習
%%time
# 設定
max_word_len = max(len(w) for w in NAMES) + 2 # BOS, EOS
batch_size = 16
d_model = 32
#n_epochs = 30
n_epochs = 100
device = "cuda" if torch.cuda.is_available() else "cpu"
# データ分割
random.seed(42)
random.shuffle(NAMES)
split = int(len(NAMES) * 0.8)
train_words = NAMES[:split]
test_words = NAMES[split:]
train_ds = NameDataset(train_words, max_word_len)
test_ds = NameDataset(test_words, max_word_len)
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=batch_size, shuffle=False)
# モデル
model = MiniFormer(VOCAB_SIZE, d_model, max_word_len).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
# 学習
for epoch in range(1, n_epochs+1):
train_loss = train(model, train_loader, optimizer, criterion, device)
test_loss = evaluate(model, test_loader, criterion, device)
if epoch % 5 == 0:
print(f"Epoch {epoch:2d}: train loss={train_loss:.4f}, test loss={test_loss:.4f}")
sample_word = "flycatcher"
x = torch.tensor([encode_word(sample_word, max_word_len)[:-1]], dtype=torch.long).to(device)
model.eval()
with torch.no_grad():
logits, attn = model(x, return_attn=True)
pred_indices = logits.argmax(dim=-1)[0].cpu().numpy()
print(f"Input: {sample_word}")
print(f"Predicted: {decode_tokens(pred_indices)}")
# 可視化用attention保存
input_tokens = [IDX2CHAR[idx] for idx in x[0].cpu().numpy()]
save_attention(attn[0], input_tokens, filename="attn_weights.json")
print("Saved attention weights to attn_weights.json. You can visualize with BertViz or any custom tool.")
Epoch 5: train loss=2.5863, test loss=2.5995
...
Epoch 100: train loss=1.9568, test loss=2.4564
CPU times: user 21.4 s, sys: 765 ms, total: 22.2 s
Wall time: 24.3 s
学習はほぼ一瞬で終わる。
セルフアテンション(1 ヘッド)の可視化
import json
import torch
from bertviz import head_view
# attn_weights.jsonを読み込む
with open('attn_weights.json') as f:
data = json.load(f)
tokens = data['tokens'] # トークン列
attn = data['attentions'] # (seq_len, seq_len) のリスト
# BertViz用に次元調整
attn_tensor = torch.tensor(attn).unsqueeze(0).unsqueeze(0) # (1, 1, seq_len, seq_len)
# BertVizで可視化
head_view(attention=[attn_tensor], tokens=tokens)
FullTransformer
詳細は分からないけど、Transformer っぽいモジュール名が並んでいる。
可視化については「正解系列」に対するセルフアテンションを見たかったので、FullTransformer の推論時、デコーダ入力に正解系列 (=teacher forcing) を与えて forward し self-attention を保存するという方法をとってもらった。
SEED = 42
random.seed(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(SEED)
# 2. Transformer Decoder(self-attentionもcross-attentionも返す)
class SimpleTransformerDecoder(nn.Module):
def __init__(self, d_model=64, max_len=16, nhead=4, num_layers=2):
super().__init__()
self.embedding = nn.Embedding(VOCAB_SIZE, d_model)
self.pos_enc = nn.Parameter(self._init_pe(max_len, d_model), requires_grad=False)
self.layers = nn.ModuleList([
nn.TransformerDecoderLayer(d_model, nhead, dim_feedforward=128, batch_first=True)
for _ in range(num_layers)
])
self.max_len = max_len
self.d_model = d_model
self.num_layers = num_layers
self.nhead = nhead
def _init_pe(self, max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
if d_model > 1:
pe[:, 1::2] = torch.cos(position * div_term)
return pe.unsqueeze(0)
def forward(self, tgt, memory, tgt_key_padding_mask=None, memory_key_padding_mask=None, return_attn=False):
tgt_emb = self.embedding(tgt) + self.pos_enc[:, :tgt.size(1), :]
self_attn_weights_layers = []
cross_attn_weights_layers = []
output = tgt_emb
tgt_mask = nn.Transformer.generate_square_subsequent_mask(tgt.size(1)).to(tgt.device)
for layer in self.layers:
# Self-attention
tgt2, self_attn_weights = layer.self_attn(
output, output, output,
attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask,
need_weights=True,
average_attn_weights=False
)
output = output + layer.dropout1(tgt2)
output = layer.norm1(output)
# Cross-attention
tgt2, cross_attn_weights = layer.multihead_attn(
output, memory, memory,
key_padding_mask=memory_key_padding_mask,
need_weights=True,
average_attn_weights=False
)
output = output + layer.dropout2(tgt2)
output = layer.norm2(output)
# FFN
tgt2 = layer.linear2(layer.dropout(layer.activation(layer.linear1(output))))
output = output + layer.dropout3(tgt2)
output = layer.norm3(output)
if return_attn:
self_attn_weights_layers.append(self_attn_weights.detach().cpu())
cross_attn_weights_layers.append(cross_attn_weights.detach().cpu())
if return_attn:
return output, self_attn_weights_layers, cross_attn_weights_layers
else:
return output
# 3. FullTransformer: Encoder + カスタムDecoder
class FullTransformer(nn.Module):
def __init__(self, vocab_size, d_model=64, max_len=16, nhead=4, num_layers=2):
super().__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.pos_enc = nn.Parameter(self._init_pe(max_len, d_model), requires_grad=False)
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model, nhead, dim_feedforward=128, batch_first=True),
num_layers=num_layers
)
self.decoder = SimpleTransformerDecoder(d_model, max_len, nhead, num_layers)
self.fc_out = nn.Linear(d_model, vocab_size)
self.max_len = max_len
self.d_model = d_model
def _init_pe(self, max_len, d_model):
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
if d_model > 1:
pe[:, 1::2] = torch.cos(position * div_term)
return pe.unsqueeze(0)
def forward(self, src, tgt, src_key_padding_mask=None, tgt_key_padding_mask=None, return_attn=False):
src_emb = self.embedding(src) + self.pos_enc[:, :src.size(1), :]
memory = self.encoder(src_emb, src_key_padding_mask=src_key_padding_mask)
if return_attn:
dec_out, self_attn_layers, cross_attn_layers = self.decoder(
tgt, memory,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=src_key_padding_mask,
return_attn=True
)
logits = self.fc_out(dec_out)
return logits, self_attn_layers, cross_attn_layers
else:
dec_out = self.decoder(
tgt, memory,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=src_key_padding_mask,
return_attn=False
)
logits = self.fc_out(dec_out)
return logits
訓練ループ
# 4. 訓練ループ
def train(model, loader, optimizer, criterion, device):
model.train()
total_loss = 0
for x, y in loader:
x = x.to(device)
y = y.to(device)
src_key_padding_mask = (x == PAD_IDX)
tgt_key_padding_mask = (x == PAD_IDX)
optimizer.zero_grad()
logits = model(x, x, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=tgt_key_padding_mask)
loss = criterion(logits.view(-1, VOCAB_SIZE), y.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(loader)
def evaluate(model, loader, criterion, device):
model.eval()
total_loss = 0
with torch.no_grad():
for x, y in loader:
x = x.to(device)
y = y.to(device)
src_key_padding_mask = (x == PAD_IDX)
tgt_key_padding_mask = (x == PAD_IDX)
logits = model(x, x, src_key_padding_mask=src_key_padding_mask, tgt_key_padding_mask=tgt_key_padding_mask)
loss = criterion(logits.view(-1, VOCAB_SIZE), y.view(-1))
total_loss += loss.item()
return total_loss / len(loader)
def save_attention_bertviz(attn_layers, tokens, filename="self_attn_bertviz.json"):
"""
attn_layers: [num_layers][nhead, tgt_len, tgt_len]
tokens: トークン列
"""
all_layers = []
for layer in attn_layers:
layer_heads = []
for head in layer:
if isinstance(head, torch.Tensor):
head = head.cpu().numpy()
layer_heads.append(head.tolist())
all_layers.append(layer_heads)
data = {
"all": all_layers,
"tokens": tokens
}
with open(filename, "w") as f:
json.dump(data, f, indent=2)
print(f"Saved self-attention to {filename} (bertviz format, with tokens)")
学習
%%time
max_word_len = max(len(w) for w in NAMES) + 2
batch_size = 16
d_model = 64
n_epochs = 100
device = "cuda" if torch.cuda.is_available() else "cpu"
random.seed(42)
random.shuffle(NAMES)
split = int(len(NAMES) * 0.8)
train_words = NAMES[:split]
test_words = NAMES[split:]
train_ds = NameDataset(train_words, max_word_len)
test_ds = NameDataset(test_words, max_word_len)
train_loader = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_ds, batch_size=batch_size, shuffle=False)
model = FullTransformer(VOCAB_SIZE, d_model, max_word_len, nhead=4, num_layers=2).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
for epoch in range(1, n_epochs + 1):
train_loss = train(model, train_loader, optimizer, criterion, device)
test_loss = evaluate(model, test_loader, criterion, device)
if epoch % 5 == 0:
print(f"Epoch {epoch:2d}: train loss={train_loss:.4f}, test loss={test_loss:.4f}")
# ---- 正解系列(teacher forcing)でセルフアテンション保存 ----
sample_word = "flycatcher"
x = torch.tensor([encode_word(sample_word, max_word_len)[:-1]], dtype=torch.long).to(device)
tgt = torch.tensor([encode_word(sample_word, max_word_len)[:-1]], dtype=torch.long).to(device) # 正解系列
model.eval()
with torch.no_grad():
logits, self_attn_layers, cross_attn_layers = model(
x, tgt,
src_key_padding_mask=(x == PAD_IDX),
tgt_key_padding_mask=(tgt == PAD_IDX),
return_attn=True
)
attn_layers = [
[self_attn_layers[l][0, h].cpu().numpy() for h in range(self_attn_layers[l].shape[1])]
for l in range(len(self_attn_layers))
]
tokens = [IDX2CHAR[idx] for idx in tgt[0].cpu().numpy()]
save_attention_bertviz(attn_layers, tokens, filename="self_attn_bertviz.json")
print("Saved self-attention weights to self_attn_bertviz.json. You can visualize with BertViz.")
Epoch 5: train loss=0.4274, test loss=0.3032
...
Epoch 100: train loss=0.0101, test loss=0.0208
Saved self-attention to self_attn_bertviz.json (bertviz format, with tokens)
Saved self-attention weights to self_attn_bertviz.json. You can visualize with BertViz.
CPU times: user 1min 10s, sys: 314 ms, total: 1min 10s
Wall time: 1min 11s
学習はすぐ終わる。
セルフアテンション(4 ヘッド)の可視化
import numpy as np
from bertviz import head_view
with open('self_attn_bertviz.json') as f:
data = json.load(f)
attn_all = np.array(data['all']) # (num_layers, num_heads, seq_len, seq_len)
tokens = data['tokens']
attention = [torch.tensor(attn_all[i]).unsqueeze(0) for i in range(attn_all.shape[0])]
print(f"attn_all.shape: {attn_all.shape}, tokens: {tokens}")
head_view(attention=attention, tokens=tokens)
セルフアテンションの比較
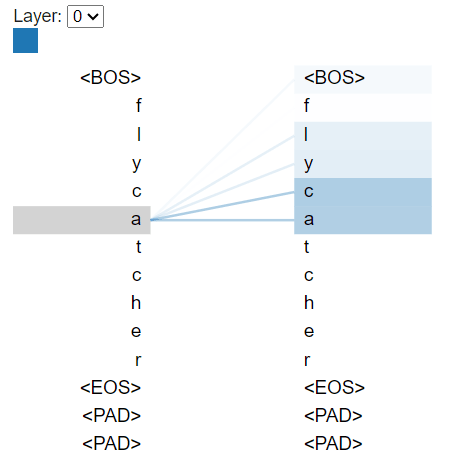
上記の実装における bertviz で見た結果を比較する。大らかな気持ちで眺めると何となく傾向的には近い気はする。MiniFormer では直前のトークンに強くアテンションしている一方、FullTransformer ではより広範なトークンにアテンションが分散しているようだ。この違いは、ヘッド数やモデルの構造の違いに起因する可能性がある。
MiniFormer
| 全体 | 「a」の部分 |
|---|---|
 |
 |
FullTransformer
| 全体 | 「a」の部分 |
|---|---|
 |
 |
GPT-4.1 によるお気持ち表明
以下のようなことらしい。これが正しいということを数学的に証明できないので、ある程度定性的に見るしかなさそう?
画像1: 全体アテンション
- 「flycatcher」の各文字(およびBOS, EOS, PAD)が並んでいます。
- 対角線(自分自身)や直前トークンへのアテンションが強く出ていることが多いのは、自己回帰型のTransformerデコーダの典型的なパターンです。
- 太い線は、各トークンが過去のどこに強く注意を払っているかを示します。
画像2: 「a」のアテンション
- "flycatcher" の "a" の位置について、どこにアテンションしているかを拡大表示しています。
- 灰色の横バーが現在注目している"出力位置"("a")で、そこから過去(BOS, f, l, y, c, a)に線が伸びています。
- a自身と、"y"や"c"にもアテンションが少し向いているのが分かります。
こうした可視化から分かること
- MiniFormerは自分自身や直前のトークンに強くアテンションしがち(言語モデルの基本的傾向)。
- 「a」のセルフアテンションも、BOSや直前の文字など、過去の情報だけにアクセスしている(未来方向には線が出ていない)。
まとめ
- この可視化はMiniFormer(自己回帰的デコーダ)の標準的なセルフアテンション挙動を示しています。
- 正しい可視化ができていると判断して問題ありません!
まとめ
Transformer をフルスクラッチで実装することも、簡易化することもできないので生成 AI に実装してもらったが、手間はかかったが実装できた。可視化も定量的には示せないものの、2 つのモデルについて、実装の複雑度の違いがある一方で傾向としては似ている気がする。数学的に証明できないので、一旦はこれで概ね正しいと思うことにして、色々実験したり改造したりすること、例えば MiniFormer のヘッド数や層の数を増やすことで、理解がより進むのではないかと期待したい。
参考文献
- 機械学習エンジニアのためのTransformers
- arXiv:1706.03762 Attention Is All You Need
- torch.nn.Transformer
- bertviz
-
つまり
input_seq[:-1]からinput_seq[1:]を推定するタスク。 ↩︎
Discussion