Stable Diffusion で遊んでみる (2) — Diffusers の中をほんの軽くだけ見る
目的
Hugging Face の Diffusers の中を本当に軽く、雰囲気だけ見てみたい。
Diffusers の解説を見る
GitHub と公式ページ Diffusers によると、
Diffusers: State-of-the-art diffusion models for image and audio generation in PyTorch and FLAX.
Diffusers is the go-to library for state-of-the-art pretrained diffusion models for generating images, audio, and even 3D structures of molecules
ということで、Stable Diffusion のような生成モデルをお手軽に扱えるライブラリである。
Our library is designed with a focus on usability over performance, simple over easy, and customizability over abstractions.
使いやすさ等が優先なので、物凄いシビアな要件がある場合は自作も必要かもしれない。
Stable Diffusion について軽く見る
論文 arXiv:2112.10752 High-Resolution Image Synthesis with Latent Diffusion Models (LDM)[1]を使用した生成モデルということになるであろう。CompVis/stable-diffusion や Stability-AI/stablediffusion が Stable Diffusion の実装ということになるのだろうか。
公式サイトの絵的に以下のようなアーキテクチャとのことである。
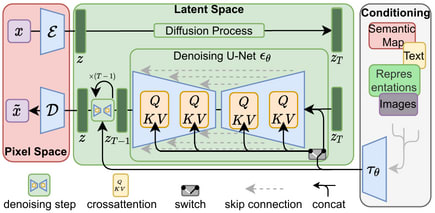
緑の部分をブラックボックスと思うと、
のような形になっていて、“VAE” のような構造になっている。真ん中の
To represent the reverse process, we use a U-Net backbone similar to an unmasked PixelCNN++ [52, 48] with group normalization throughout [66]. Parameters are shared across time, which is specified to the network using the Transformer sinusoidal position embedding [60]. We use self-attention at the 16 × 16 feature map resolution [63, 60]. Details are in Appendix B.
とあるように、時間情報を Transformer の位置エンコーディングでコード化して、U-Net の畳み込みブロックに差し込む実装をよく見かけるように思う。この辺は解説を 100 回読むよりは、1 回だけで十分なので ゼロから作るDeep Learning ❺ ―生成モデル編 を写経しつつ解説を読むのが一番理解できる気がする[2]。
Latent Diffusion では、マルチモーダルな情報(text-to-image であればテキスト)で条件付けをするために、条件をエンコードしてそれも U-Net の畳み込みブロックに差し込む形になっているようだ。マルチモーダルなエンコーダというと arXiv:2103.00020 Learning Transferable Visual Models From Natural Language Supervision (CLIP) が有名であろうか。
Diffuser を見ていく
Diffusers の GitHub の README をさっと見んで以下のようなコードを書いてみた。有名な馬に乗っているやつではなく、ちょっと鳥のように空を飛ばせてみたくなった。
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16
)
pipeline.to("cuda")
prompt = "a photo of an astronaut flying like a bird in the sky of the mars"
image = pipeline(prompt).images[0]
display(image)

楽しそう(?)である。
pipeline
作成した pipeline を出力してみると以下のようになっていた。transformers とか CLIP という文字列が見える。
print(pipeline)
StableDiffusionPipeline {
"_class_name": "StableDiffusionPipeline",
"_diffusers_version": "0.29.0",
"_name_or_path": "runwayml/stable-diffusion-v1-5",
"feature_extractor": [
"transformers",
"CLIPImageProcessor"
],
"image_encoder": [
null,
null
],
"requires_safety_checker": true,
"safety_checker": [
"stable_diffusion",
"StableDiffusionSafetyChecker"
],
"scheduler": [
"diffusers",
"PNDMScheduler"
],
"text_encoder": [
"transformers",
"CLIPTextModel"
],
"tokenizer": [
"transformers",
"CLIPTokenizer"
],
"unet": [
"diffusers",
"UNet2DConditionModel"
],
"vae": [
"diffusers",
"AutoencoderKL"
]
}
トークナイザとテキストエンコーダ
テキスト埋め込みをどうやって作っているのかを念のため確認したい。
print(type(pipeline.tokenizer))
print(type(pipeline.text_encoder))
<class 'transformers.models.clip.tokenization_clip.CLIPTokenizer'>
<class 'transformers.models.clip.modeling_clip.CLIPTextModel'>
上のほうで既に文字列で見えているが CLIP で処理しているようである[3]。
ガイダンス
一旦画像を生成すると動的にセットされる属性として do_classifier_free_guidance というのがあって、これを表示してみる:
print(pipeline.do_classifier_free_guidance)
True
ということで、いわゆる「分類器なしガイダンス」をやっているようである。OpenAI の「分類器ガイダンス」(arXiv:2105.05233 Diffusion Models Beat GANs on Image Synthesis) と Google Research の「分類器なしガイダンス」(arXiv:2207.12598 Classifier-Free Diffusion Guidance) と目まぐるしい。
U-Net
U-Net 部分を見てみたい
print(pipeline.unet)
すると
UNet2DConditionModel(
(conv_in): Conv2d(4, 320, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_proj): Timesteps()
(time_embedding): TimestepEmbedding(
(linear_1): Linear(in_features=320, out_features=1280, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=1280, out_features=1280, bias=True)
)
...
)
ということで diffusers/models/unets/unet_2d_condition.py#L70-L1305 の UNet2DConditionModel クラスが使われている。arXiv:1505.04597 の頃の素朴な U-Net に比べて随分と大変な代物になっているのが窺える。
まとめ
ざっと見ただけだが、ゼロから作るDeep Learning ❺ ―生成モデル編 で「分類器なしガイダンス」くらいの技術までの拡散モデル周辺についてざっと学んで LDM の論文 arXiv:2112.10752 High-Resolution Image Synthesis with Latent Diffusion Models のアーキテクチャと見比べると(色々やっているのでゴチャゴチャしている部分はあるにせよ)論文に出て来るモジュールが並んでいるのだなと思う。
軽くでも眺めて文章化すると、少し見通しが良くなる気がする。
-
対応コード CompVis/latent-diffusion ↩︎
-
DDPM 論文の Eq. (11) の
\mu_\theta (\mathbf{x}_t, t) = \frac{1}{\sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1 - \bar{\alpha}_t}} \, \epsilon_\theta (\mathbf{x}_t, t) \right) \epsilon_\theta (\mathbf{x}_t, t) -
LDM の論文中でも少し名前が出ている。 ↩︎
Discussion