Dify + Llama 3 で遊んでみる (1)


目的
幾らでもこの手の記事はあって何番煎じどころではないが、手元でざっと動かしたので備忘録的にまとめておきたい。
最終的には RAG を使って、今年の新しい論文の概要について答えさせるところをゴールとする。
環境
とある Ubuntu 22.04.4 LTS 環境上で Docker を用いて Dify + Ollama (Llama 3 7B) でやってみる。
環境構築
Docker を使えるようにする
Install Docker Engine on Ubuntu に従ってセットアップ。内容はすぐ陳腐化しそうなので転載はしない。書いてある通りにやるだけ。
Docker で GPU を使えるようにする
Installing the NVIDIA Container Toolkit の通りにやる。これもすぐ陳腐化しそうなので転載はしないが、最終的には以下を実行すると思われる。Docker Hub の ollama/ollama を見ても良い。
$ sudo apt-get install -y nvidia-container-toolkit
もし Docker の daemon が起動していなければ以下のような感じで起動する:
$ sudo service docker start
使うものを整理
-
Dify
- DifyはオープンソースのLLMアプリ開発プラットフォームです。その直感的なインターフェースは、AIワークフロー、RAGパイプライン、エージェント機能、モデル管理、観測可能な機能などを兼ね備えており、プロトタイプから製品化まで迅速に行うことができます。(by DeepL)
-
Ollama
- Llama 3、Mistral、Gemma、その他の大規模な言語モデルで稼働させましょう。(by DeepL)
- というのはピンと来ないが、ググった感じでは色んなモデルをローカル LLM として動かせる OSS
Ollama セットアップ
Docker でやるので、
$ docker pull ollama/ollama:latest
する。ところで何故か llama3 のダウンロード時に Pulling manifest fails with error "read: connection reset by peer" と同様のエラーが起こったので、モデルのダウンロード用に
$ docker pull ollama/ollama:0.1.27
した。とりあえずモデルをダウンロードしたいので公式の手順と同様に以下を実行する。コンテナを stop した時に残骸が消えて欲しいので --rm を追加している。
$ docker run -d --rm --gpus=all -v ollama:/root/.ollama -p 11434:11434 \
--name ollama ollama/ollama:0.1.27
Llama 3 7B のダウンロードは以下のようにする:
$ docker exec -it ollama ollama run llama3
...
pulling manifest
pulling 6a0746a1ec1a... 58% ▕████████████████████████████████████ ▏ 2.7 GB/4.7 GB 11 MB/s 2m50s
ダウンロードが終わるとプロンプトが起動するので、
>>> What's your name?
I don't have a personal name. I'm an AI, so my purpose is to assist and communicate with users like you without a
personal identity. I exist solely to provide helpful information, answer questions, and engage in productive
conversations. You can think of me as "Assistant" or simply "AI" – no need for a specific name!
>>> /bye
などと遊んであげる。
なお、コンテナ起動時にボリュームのマッピングとして ollama:/root/.ollama としていたので、
$ docker system df -v
...
VOLUME NAME LINKS SIZE
...
ollama 1 4.661GB
...
というのように「ollama」というボリュームに Llama 3 7B がダウンロードされる。要らなくなったらボリュームを破棄したほうが良さそうだ。
これが完了すれば、次回以降の ollama の起動は「ollama/ollama:0.1.27」ではなく「ollama/ollama:latest」で良さそうだった。
Ollama のセットアップは以上である。
Dify セットアップ
$ git clone https://github.com/langgenius/dify.git
$ cd dify/docker
から始める。今回、docker-compose.yaml を少し書き換える。Nginx をポート 8080 で起動しつつ、Docker コンテナの中からホストの 11434 番ポートで動いている Ollama が見えるようにしたい。ホスト側のネットワークを見えるようにする魔法を「extra_hosts」でセットする。
version: '3'
services:
# API service
api:
...
extra_hosts:
- "host.docker.internal:host-gateway"
nginx:
ports:
- "8080:80"
より具体的には以下である:
$ git diff
diff --git a/docker/docker-compose.yaml b/docker/docker-compose.yaml
index c3b54305..e784a132 100644
--- a/docker/docker-compose.yaml
+++ b/docker/docker-compose.yaml
@@ -191,6 +191,8 @@ services:
networks:
- ssrf_proxy_network
- default
+ extra_hosts:
+ - "host.docker.internal:host-gateway"
# worker service
# The Celery worker for processing the queue.
@@ -486,7 +488,7 @@ services:
- api
- web
ports:
- - "80:80"
+ - "8080:80"
#- "443:443"
networks:
# create a network between sandbox, api and ssrf_proxy, and can not access outside.
ここまでできたら Dify の起動は簡単で、以下である:
$ docker compose up -d
終了する時は以下である。
$ docker compose down
Dify の UI から設定
localhost:8080 でアクセスする。ローカル LLM なので適当なユーザーとパスワードを設定する形でアカウントを作る。終わったらメイン画面に遷移する。
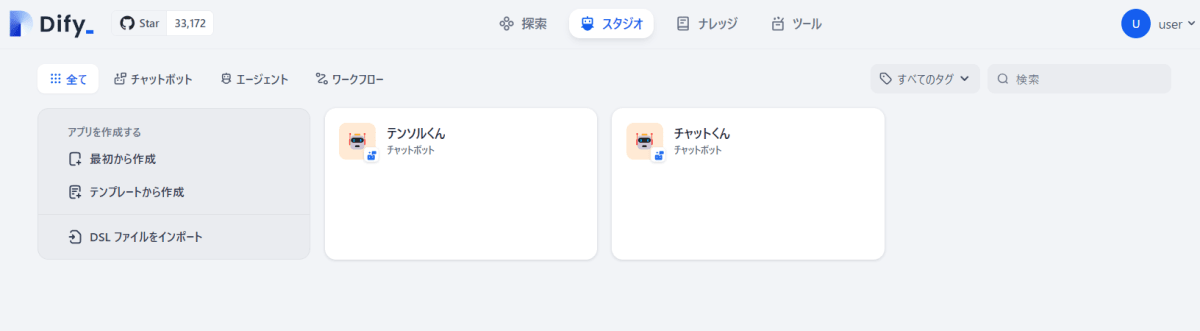
ユーザーアイコンをクリックすると「設定」があるので、そこから LLM の設定をする。
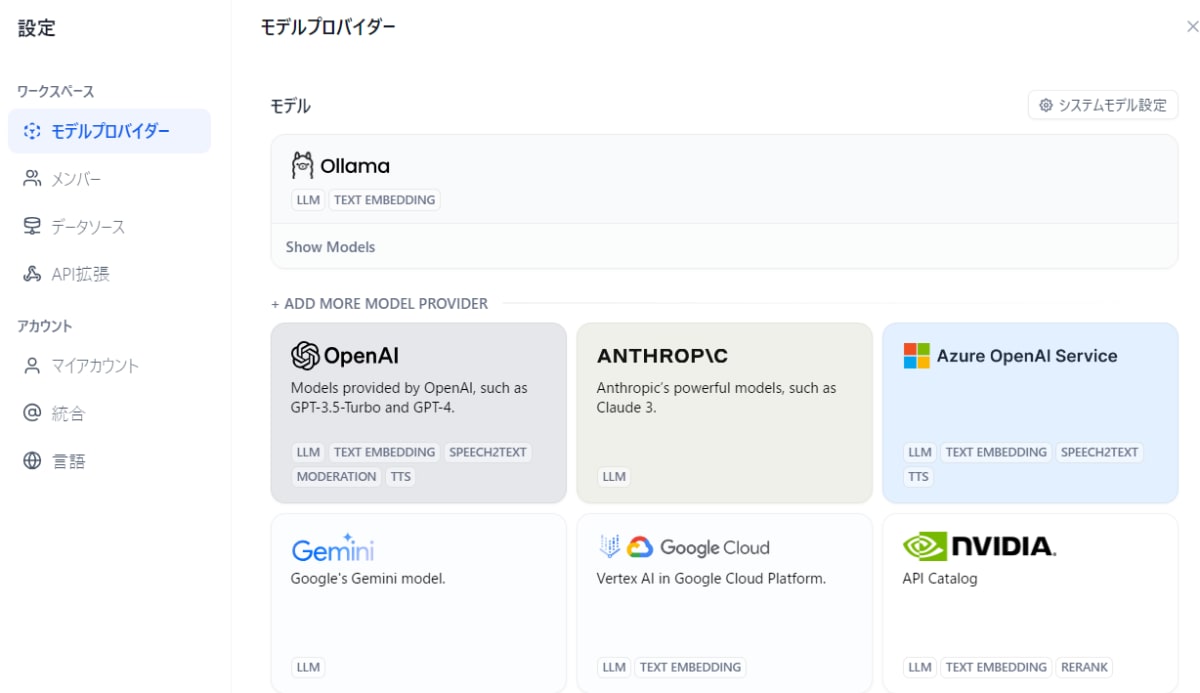
色々見えているが Ollama があるので、以下のような感じで設定する。
Model Name: llama3
Base URL: http://host.docker.internal:11434
Completion mode: Chat
Model context size: 4096
Upper bound for max tokens: 500
Vision support: No
再びメニューに戻って、中央上部の「スタジオ」から「チャットボット」を選んで「最初から作成」などを選択する。
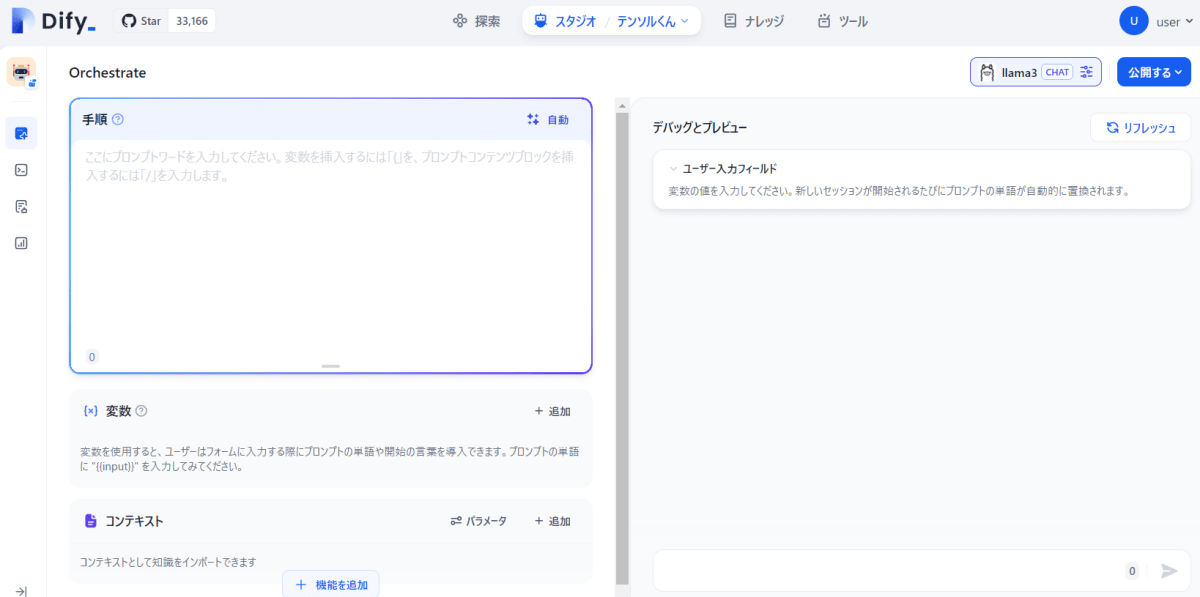
右下の入力欄のようなところに何か入力すると ChatGPT のようにお話ができる。但し英語で返答してくることが多いようなので「日本語で」といった指定を入れると便利であった。
RAG
これだけだと面白くないので RAG をする。NRI の解説 RAG によると、
RAGとは
Retrieval-Augmented Generation (RAG) は、大規模言語モデル(LLM)によるテキスト生成に、外部情報の検索を組み合わせることで、回答精度を向上させる技術のこと。
ということである。素の Llama 3 の場合、以下のような感じで知らないことはかなり適当な回答になる。

ここで問うている CompactifAI とは CompactifAI: Extreme Compression of Large Language Models using Quantum-Inspired Tensor Networks という LLM をテンソルネットワーク技術でモデル圧縮する今年の論文である。流石にこんな知識を持っているとは思えない。
Dify のメニューの中央上部に「スタジオ」の右に「ナレッジ」があるので、ここでナレッジを拡張できる。「知識を作成」をクリックすると以下のようなフローティングウィンドウが出るが何と pdf がそのままいけるということで D&D してアップロードする
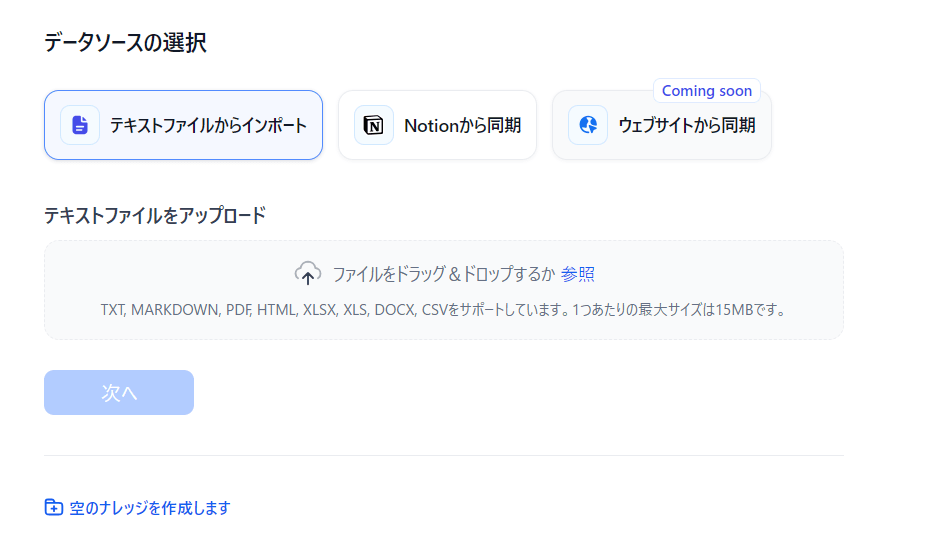
終わったらチャットボットの画面に戻って、左下の「コンテキスト」で「+ 追加」でアップロードした pdf のナレッジを登録する。
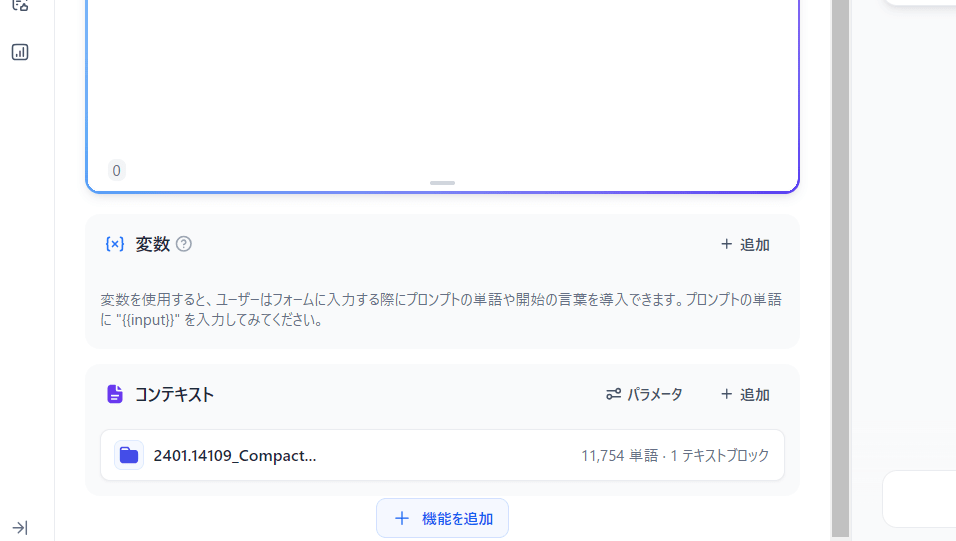
この状況で 先ほどとまったく同じ 質問をすると段違いの反応が得られる。

まとめ
Dify + Ollama で Llama 3 を動かして、RAG のナレッジを追加して今年の論文について簡単な概要を答えさせることができた。かなり作業スペースを食うというか、どんどんストレージを圧迫するので、余裕を見て 100GB くらいの空き容量 は欲しいところである。Docker を使わないならもう少しコンパクトにできるかもしれないが、ホスト環境が汚れそうなので個人的には嫌である。
Discussion
補足
ストレージの消費量は例えば以下のように推移する:
また、docker のイメージが沢山 pull される: