バイアス-バリアンスについて考える (1)
目的
色々思うところがあって[1]、たまには Pattern Recognition and Machine Learning を読んでバイアスとバリアンスについて思いを馳せてみようという企画。読書メモとも言う。
今回の範囲
PRML 1.5.5 Loss functions for regression (pp.46-47) を眺める。この内容は推定問題について神様的な視点で全体を見渡した時の話で、関係する世界中のデータをかき集めてきた時にどういった事が言えるか?を評価するものである。
課題
あるラベル付きのデータセットが与えられた時に、データからラベルを推定する最良のモデルを構築したい。この時、バイアスやバリアンスの視点でモデルを取り巻く状況を数理的にとらえたい。前提として、データセットの規模に制限はなく望めば世界中、過去も未来のデータさえも得られるものとする。
バイアスとバリアンス
このコンテキストで言う “バイアス” はニューラルネットの線形層に出てくる
そこで、賃貸の条件(データ; 特徴量)と賃料(ラベル)の擬似的なデータセットを作って考察をしてみたい。
賃貸の条件と賃料の擬似的なデータセット
主観で作ったものだが、以下のようなデータセットを考えてみたい。1 部屋なら 家賃 3.5 万円、2 部屋なら 5 万円、3 部屋なら8 万円、4 部屋なら 11 万円くらいにしてみて、駅から遠いとか築年数が相当経っているなら少しお安くするみたいな気持ちで適当に作ったものである。
import numpy as np
from dataclasses import dataclass
@dataclass
class Condition:
distance: int # minutes on foot from the station
rooms: int # number of rooms
age: int
datasets = np.array([
(Condition(5,1,20),3.5),(Condition(10,1,30),3), (Condition(10,2,15),5),
(Condition(5,1,20),3.5),(Condition(20,3,40),6.8),(Condition(15,1,10),3.4),
(Condition(7,2,5),5), (Condition(7,3,20),8), (Condition(3,1,5),3.5),
(Condition(15,4,25),10.8),(Condition(20,3,40),6.8),(Condition(10,2,15),5),
(Condition(20,1,15),3.3),(Condition(5,2,10),5), (Condition(3,1,40),3)
])
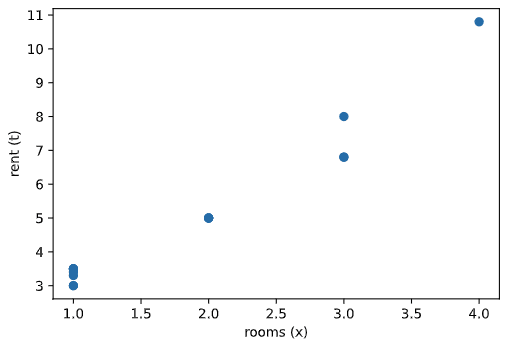
これを部屋数と家賃について 2D で可視化すると以下のようになる。都合良く作ったデータセットなので以下にも線形回帰しやすそうだ。
import matplotlib.pyplot as plt
conditions = datasets[:, 0]
rents = datasets[:, 1]
key = 'rooms'
plt.scatter([getattr(c, key) for c in conditions], rents)
plt.xlabel(f'{key} (x)')
plt.ylabel('rent (t)')
plt.show()
ここで
この散布図では表現できていないが、同じ
以下では世界中のありとあらゆるデータ
モデルとその理想的な姿
適当な説明変数のベクトル
世界中のデータをかき集めたものは
この確率分布のもとで、モデルの推定値と実際の賃料の 2 乗誤差
となる。[2] これを何とかして可能な限り小さくしたいというのが課題のゴールである。果たして
今回、
変分法の数学的な扱いは置いておいて、
となる。これをまとめて累次積分の形で書くと
を得る。ここで、
(2) 式で
を得る。ここで、
PRML に倣って、何の期待値であるか?という情報
理想的とは言えない一般のモデルについて何が言えるか?
理想の姿を求めたので、一般のモデル
再び (1) 式に戻って、被積分関数を展開する。理想が分かったので、理想
であるが、(1) 式と同様に積分
ここで、
前にこの推定誤差の期待値について「果たして
一方で、右辺第 1 項は制御可能であり、例えば神様なら世界中のありとあらゆる、過去と未来、時間を超えた家賃も分かるので、完璧なモデル
ところがそんなデータセットが得られるわけがないじゃないかということで、現実的には手に入るデータから家賃を推定することになる。これが次回の記事のスコープである。
まとめ
他人の褌で相撲を取っているわりには長い記事になってしまった。PRML はそれほど行間の広い本だとは思わないが、記号の意味などについて著者が自明と思っているケースでは定義が省略されるように見えるし、条件付き〇〇の類については立ち止まって意味を考えないと次第に数式が分からなくなる。ということで家賃推定モデルの言葉で書き直したり、変分法のもやもやする部分を細かく展開しているうちに長くなってしまった。
とにかく「一般には、最良のモデルであっても、予測誤差は完璧には
-
実務上は「ML なんて実務に耐える結果が出たら何でもいいでしょ。過学習が何?数式が何?」って態度でとりあえず訓練回して、グラフは最悪な形状だけど実際にパラメータをロードしたら「お、案外いいじゃない」となれば mission completed な気持ちで過ごしている。誰も数式に興味がないし「正規方程式を解くと」とか「このモデルの設計のポイントは」なんて話は受けが悪い。すると結果が出る話とお金になる話ばかりに頭が行ってしまう。が、毎回そうだと格好悪いことになる時も出てくるかもしれないので、PRML を読んで分かった気持ちになっておこう、ということである。 ↩︎
-
こう書くと急に小難しくなるが、今回は「連続確率分布
p(\mathrm{x}, t) \frac{1}{K} \sum_{i=1}^K (y(\mathrm{x}_i) - t_i)^2 \mathrm{x} t d\mathrm{x} dt \exist i\ \text{s.t.}\ (\mathrm{x},t) = (\mathrm{x}_i,t_i) (\mathrm{x},t) 0 -
放物線
y = x^2 x=0 \frac{dy}{dx}|_{x=0} = 0 0 \varepsilon x = 0 + \varepsilon (0 + \varepsilon)^2 -
F(\mathrm{x}) \frac{\delta \mathbb{E}(L)}{\delta y(\mathrm{x})} y(\mathrm{x}) \partial \delta
Discussion