TensorFlowでDCGANのモデルを構築し、CelebAの顔画像を学習させる方法
はじめに
TensorFlow のチュートリアルには、深層畳み込み敵対的生成ネットワーク(DCGAN)が解説されている。
このチュートリアルでは MNIST の画像を生成する方法が解説されている。また、次のステップに CelebA で実験してみると良いでしょうと記載されている。
そこでこの記事では CelebA のデータセットを使って DCGAN のモデルを構築し、人の顔を生成してみる。また、この記事では DCGAN の論文[1]に記載せれているモデルの構築のコツやハイパーパラメーターの設定についても解説する。
コードの全体は以下に配置した。この記事では重要な部分だけを解説する。
データセット
CelebaA は有名人の顔画像をカラー 178×218 ピクセルで 202,599 枚集めたデータセットである。以下から取得して用いる。
以下は 64×64 ピクセルに変換した画像である。この画像を DCGAN で生成したい。

以下のように、値を-1〜1 に変換して用いる。
import tensorflow as tf
def scaling(image):
return image / 127.5 - 1
dataset = tf.keras.preprocessing.image_dataset_from_directory(
directory="./dataset/img_align_celeba/img_align_celeba/",
label_mode=None,
image_size=(64, 64),
shuffle=False,
)
dataset = dataset.map(scaling).unbatch().cache().shuffle(10000).batch(128)
これは generator の最後のレイヤーの活性化関数が tanh であるためである。
モデルの構築
今回構築した DCGAN のモデルを部品ごとに解説する。基本的には、DCGAN の著者の記事[2]に記載されているコツを試す。以下は論文に記載されている指針である。記事にはこれより詳しいコツが記載されている。
安定した深層畳み込みGANのためのアーキテクチャ指針
- プーリング層をストライドコンボリューション(識別器)とフラクショナルストライドコンボリューション(生成器)で置き換える。
- 生成器と識別器の両方でbatchnormを使用する。
- より深いアーキテクチャのために、完全接続された隠れ層を削除する。
- Tanhを使用する出力を除くすべての層で、ジェネレータでReLU活性化を使用する。
- すべての層の識別器にLeakyReLU活性化を使用する。
生成器モデル
generator のモデルは以下のように構築した。
self.generator = Sequential([
Input((100,)),
Dense(4*4*1024),
Reshape((4, 4, 1024)),
Conv2DTranspose(512, 4, strides=2, padding="same"),
BatchNormalization(),
LeakyReLU(0.2),
Conv2DTranspose(256, 4, strides=2, padding="same"),
BatchNormalization(),
LeakyReLU(0.2),
Conv2DTranspose(128, 4, strides=2, padding="same"),
BatchNormalization(),
LeakyReLU(0.2),
Conv2DTranspose(3, 4, strides=2, padding="same", activation="tanh")
], name="generator")
以下を意識して構築した。
- kernel_size が strides で割り切れるように構築する。
- 活性化関数は全て LeakyReLU(0.2)を用いる。
- 全ての Conv レイヤーに BatchNormalization を用いる。
- hidden layer として Dense を使わない。
1.についてはこの記事[3]を参考にして設定した。割り切れないと特有の GAN 模様が現れてしまう。 2.記事[2:1]に従った。(論文に従って generator だけ ReLU にして学習したら学習が進まなかった) 3.については BatchNormalization の元論文[4]を参考に活性化関数の直前で適用するようにした。 4.元論文[1:1]に従った。
分類器
discriminator のモデルは以下のように構築した。
self.discriminator = Sequential([
Input((64, 64, 3)),
Conv2D(64, 4, strides=2, padding="same"),
LeakyReLU(0.2),
Conv2D(128, 4, strides=2, padding="same"),
BatchNormalization(),
LeakyReLU(0.2),
Conv2D(256, 4, strides=2, padding="same"),
BatchNormalization(),
LeakyReLU(0.2),
Conv2D(1, 4, strides=2, padding="same"),
Flatten(),
Dense(1, activation="sigmoid")
])
以下を意識して構築した。
- MaxPooling を使用せず、Conv 2 D を strides=2 を用いる。
- hidden layer として Dense を使わない。
その他の設定
compile は上書きする。GAN は二つのモデルを同時に学習するため Optimizer や loss も二つ必要になる。
def compile(self, d_optimizer, g_optimizer, loss_fn):
super(GAN, self).compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
self.d_loss_tracker = tf.keras.metrics.Mean(name="d_loss")
self.g_loss_tracker = tf.keras.metrics.Mean(name="g_loss")
@property
def metrics(self):
return [self.d_loss_tracker, self.g_loss_tracker]
d_loss と g_loss を記録すると、綱引きしながら学習が進んでいく様が観察できる。
学習ステップの定義
学習ステップは以下のようにした。順番に解説する。
def train_step(self, real_images):
batch_size = tf.shape(real_images)[0]
# 1.
random_latent_vectors = tf.random.normal(shape=(batch_size, 100))
# 2.
real_labels = tf.ones((batch_size, 1)) + 0.5 * tf.random.uniform((batch_size, 1), minval=-1, maxval=1)
fake_labels = tf.zeros((batch_size, 1)) + 0.25 * tf.random.uniform((batch_size, 1), )
flipped_fake_labels = tf.ones((batch_size, 1))
# 3.
with tf.GradientTape() as d_tape, tf.GradientTape() as g_tape:
real_preds = self.discriminator(real_images)
fake_images = self.generator(random_latent_vectors)
fake_preds = self.discriminator(fake_images)
d_loss_real = self.loss_fn(real_labels, real_preds)
d_loss_fake = self.loss_fn(fake_labels, fake_preds)
d_loss = d_loss_real + d_loss_fake
g_loss = self.loss_fn(flipped_fake_labels, fake_preds)
d_grads = d_tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(zip(d_grads, self.discriminator.trainable_weights))
g_grads = g_tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(g_grads, self.generator.trainable_weights))
# 解説しない
self.d_loss_tracker.update_state(d_loss)
self.g_loss_tracker.update_state(g_loss)
return {"d_loss": self.d_loss_tracker.result(), "g_loss": self.g_loss_tracker.result()}
- 潜在変数は一様分布ではなく、正規分布から取得する。
random_latent_vectors = tf.random.normal(shape=(batch_size, 100))
これは記事[2:3]に記載がある。
- discriminator が見るラベルにはノイズを加える。
real_labels = tf.ones((batch_size, 1)) + 0.5 * tf.random.uniform((batch_size, 1), minval=-1, maxval=1)
fake_labels = tf.zeros((batch_size, 1)) + 0.25 * tf.random.uniform((batch_size, 1), )
flipped_fake_labels = tf.ones((batch_size, 1))
これも記事[2:4]に記載がある。CelebA にはラベルがあるのでこれを予想させるように変更を加えるとさらに学習が進むかもしれない。また、discriminator のラベルを時々反転させると学習が進むと記載があるがそれは実装していない。
- 一回のミニバッチで全て real か全て fake かを当てさせる。
with tf.GradientTape() as d_tape, tf.GradientTape() as g_tape:
real_preds = self.discriminator(real_images)
fake_images = self.generator(random_latent_vectors)
fake_preds = self.discriminator(fake_images)
d_loss_real = self.loss_fn(real_labels, real_preds)
d_loss_fake = self.loss_fn(fake_labels, fake_preds)
d_loss = d_loss_real + d_loss_fake
g_loss = self.loss_fn(flipped_fake_labels, fake_preds)
d_grads = d_tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(zip(d_grads, self.discriminator.trainable_weights))
g_grads = g_tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(g_grads, self.generator.trainable_weights))
これも記事[2:5]に記載がある。以下でそれが実現できてるのかはよくわからない。基本的に tensorflow のチュートリアルを参考に実装している。
モデルの学習
モデルは以下のように学習させる。
model.compile(
d_optimizer=Adam(0.0002, 0.5),
g_optimizer=Adam(0.0002, 0.5),
loss_fn=tf.keras.losses.BinaryCrossentropy(),
)
model.fit(
dataset,
epochs=50
)
optimizer は Adam を学習率 0.0002 で beta_1 を 0.5 に設定すると学習がよく進む。これは論文[1:3]にも記事[2:6]にも記載がある。実際に、このパラメータを消して学習させてみたが上手く学習が進まなかった。(学習率落とすのはわかるけど、beta_1=0.5 にはどういう意味があるんだろう。。。)
結果
学習は以下のようになった。

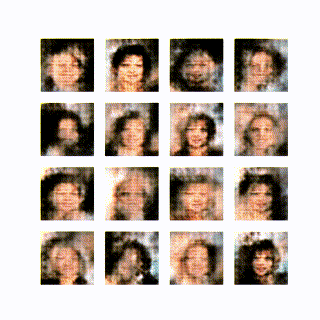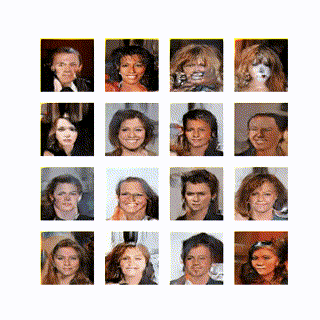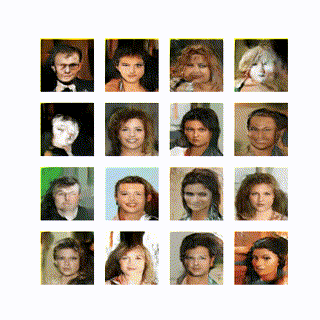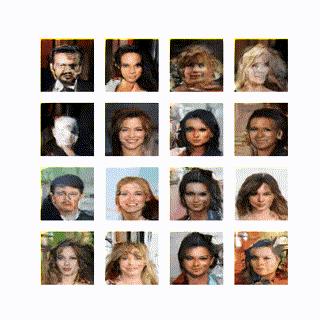
学習の初期からかなり生成できているのは上記の様々な工夫が効いているためだと思う。いくつかのパラメータを変えて学習してみたが 10epoch 経ってやっと顔の輪郭が見えてくるとかに悪化した。
Zenn は Gif を 3MB まで圧縮しないとアップロードできないので、高画質版を YouTube にアップロードした。気になる人はご覧ください。
おわりに
DCGAN を用いて画像の生成を実施してみた。数年前に、TensorFlow のチュートリアルを改造するして実装したことがあったが、今回は元の論文に立ち返って実装することで理解が深まった。特に、今回のモデル構築のコツの部分は論文著者が最も苦労して見つけて部分だと思うので、その知見を吸い出すことに成功したのは大きい。新しいモデルを構築する時は元の論文に目を通すようにしたい。また、なぜ ReLU()より LeakyReLU(0.2)が良いのかや、なぜ Adam を beta_1=0.5 で使うと良いのかなどの疑問は解消されなかった。この辺の基礎的な部分について考察が面白そうなので研究を探していきたい。
今後の課題として、最終的な画像が元論文の掲載画像より歪であるという部分が残っている。これは、今回用いたデータセットに歪な画像が含まれているからや、モデルのパラメータ数が少ないなどが考えられる。CelebA-HQ[5]のデータセットの方が綺麗なので、こちらを使ったらもっと良い画像が生成できるかもしれない。これらは今後の課題として残しておく。
Discussion