Kubeflow + MLflowを使ってHuggingFaceのBERTの転移学習の実験管理をする。
はじめに
前回、Ubuntu Server の Microk8s 上に Kubeflow + MLflow の環境を構築した。
この環境を用いて HuggingFace の BERT を転移学習させてその実験管理を行う。
ノートブックの作成
Kubeflow の Notebooks から、以下の条件で JupyterLab のコンテナを作成する。
- Image:
kubeflownotebookswg/jupyter-tensorflow-cuda-full:v1.7.0 - GPU: 1, NVIDIA
- Volume size: 100GB
ノートブックに接続して、以下のパッケージをインストールする。
!pip install transformers datasets mlflow==2.1.1 boto3
mlflow は mlflow-server のバージョンに合わせる必要がある。mlflow-server のバージョンはGitHubから確認する。boto3 は mlflow が学習結果を Minio にアップロードするのに利用する。
モデルの構築
MLflow の設定
はじめに、MLflow の環境変数を設定する。
import os
import mlflow
import mlflow.tensorflow
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
os.environ["MLFLOW_S3_ENDPOINT_URL"] = "http://minio.kubeflow.svc.cluster.local:9000"
os.environ["AWS_ACCESS_KEY_ID"] = "minio"
os.environ["AWS_SECRET_ACCESS_KEY"] = "<password>"
os.environ["MLFLOW_TRACKING_URI"] = "http://mlflow-server.kubeflow.svc.cluster.local:5000"
mlflow.set_experiment("bert")
mlflow.tensorflow.autolog()
ノートブックのコンテナは Kubeflow の namespace とは別の namespace に作成されるため、Minio や MLflow の DNS はフルで指定する必要がある。また、Minio のアクセスキーはjuju config minio secret-key=<password>で設定したものを用いる。
学習
from datasets import load_dataset
from transformers import (BertTokenizerFast, TFBertForSequenceClassification, create_optimizer)
import tensorflow as tf
BATCH_SIZE = 16
EPOCH_NUM = 10
データセットはIMDbを用いる。
# Dataset
dataset = load_dataset('imdb')
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
tokenized_dataset = dataset.map(lambda x: tokenizer(x['text'], truncation=True, padding=True), batched=True)
tf_train_dataset = tokenized_dataset["train"].to_tf_dataset(
columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'],
shuffle=True,
batch_size=BATCH_SIZE,
)
tf_train_dataset = tf_train_dataset.map(lambda x: ({'input_ids': x['input_ids'], 'token_type_ids': x['token_type_ids'], 'attention_mask': x['attention_mask']}, x['label'])).take(10)
for x, y in tf_train_dataset.take(1):
print(x['input_ids'].shape, x['token_type_ids'].shape, x['attention_mask'].shape, y.shape)
# (16, 512) (16, 512) (16, 512) (16,)
tf_test_dataset = tokenized_dataset["test"].to_tf_dataset(
columns=['input_ids', 'token_type_ids', 'attention_mask', 'label'],
shuffle=False,
batch_size=BATCH_SIZE,
)
tf_test_dataset = tf_test_dataset.map(lambda x: ({'input_ids': x['input_ids'], 'token_type_ids': x['token_type_ids'], 'attention_mask': x['attention_mask']}, x['label'])).take(10)
for x, y in tf_test_dataset.take(1):
print(x['input_ids'].shape, x['token_type_ids'].shape, x['attention_mask'].shape, y.shape)
# (16, 512) (16, 512) (16, 512) (16,)
モデルの学習。
# Train
model = TFBertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
batches_per_epoch = len(tokenized_dataset["train"]) // BATCH_SIZE
total_train_steps = int(batches_per_epoch * EPOCH_NUM)
optimizer, schedule = create_optimizer(init_lr=2e-5, num_warmup_steps=0, num_train_steps=total_train_steps)
tensorboard_callback = tf.keras.callbacks.TensorBoard()
model.compile(optimizer=optimizer, metrics=['accuracy'])
model.fit(tf_train_dataset, epochs=EPOCH_NUM, validation_data=tf_test_dataset, callbacks=[tensorboard_callback])
モデルの学習時には TensorBoard のコールバックを設定しログを取る。
学習結果
TensorBoard
TensorBoard は学習中の様々なメトリクスを取得しながら可視化できる。
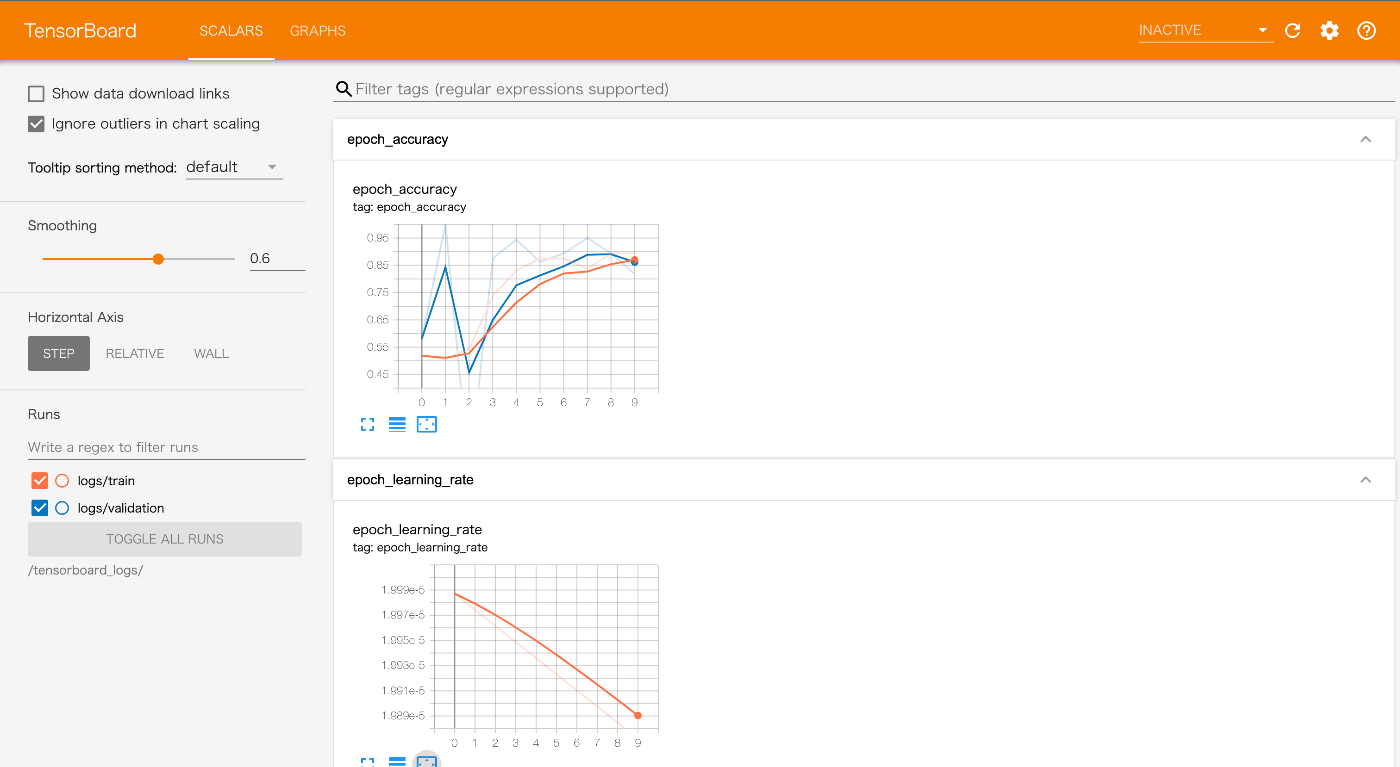
上記の画面に加えて計算グラフも見ることができる。細かく設定すれば学習中のバリデーションデータへの推論結果も可視化できると思う。実験管理はフォルダベースなので、毎回フォルダを設定しないといけない。
MLflow
MLflow は学習を回すたびに実験結果が追加されていく。これまでの実験を管理し最適なモデルを選択できる。
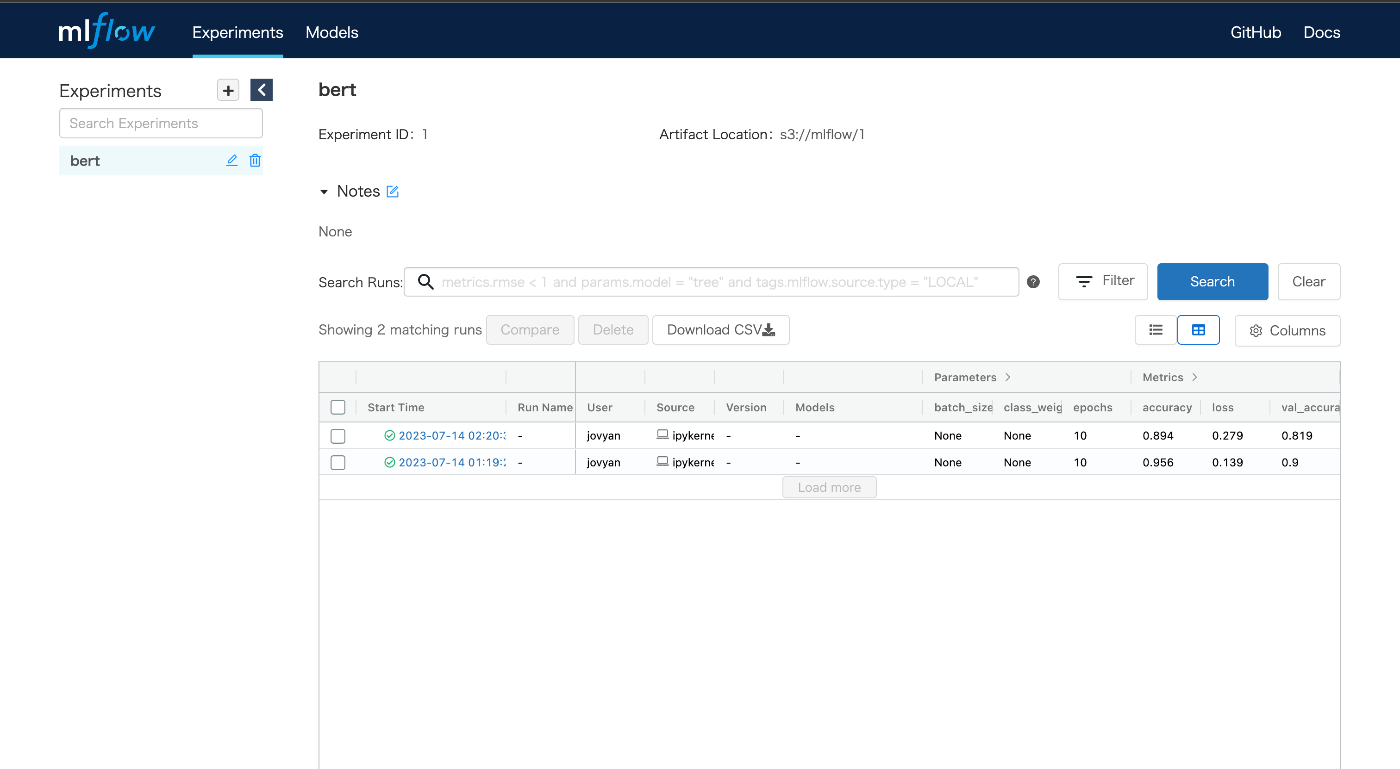
それぞれの実験のメトリクスを可視化できる。モデルは自動的に Minio に保存される。
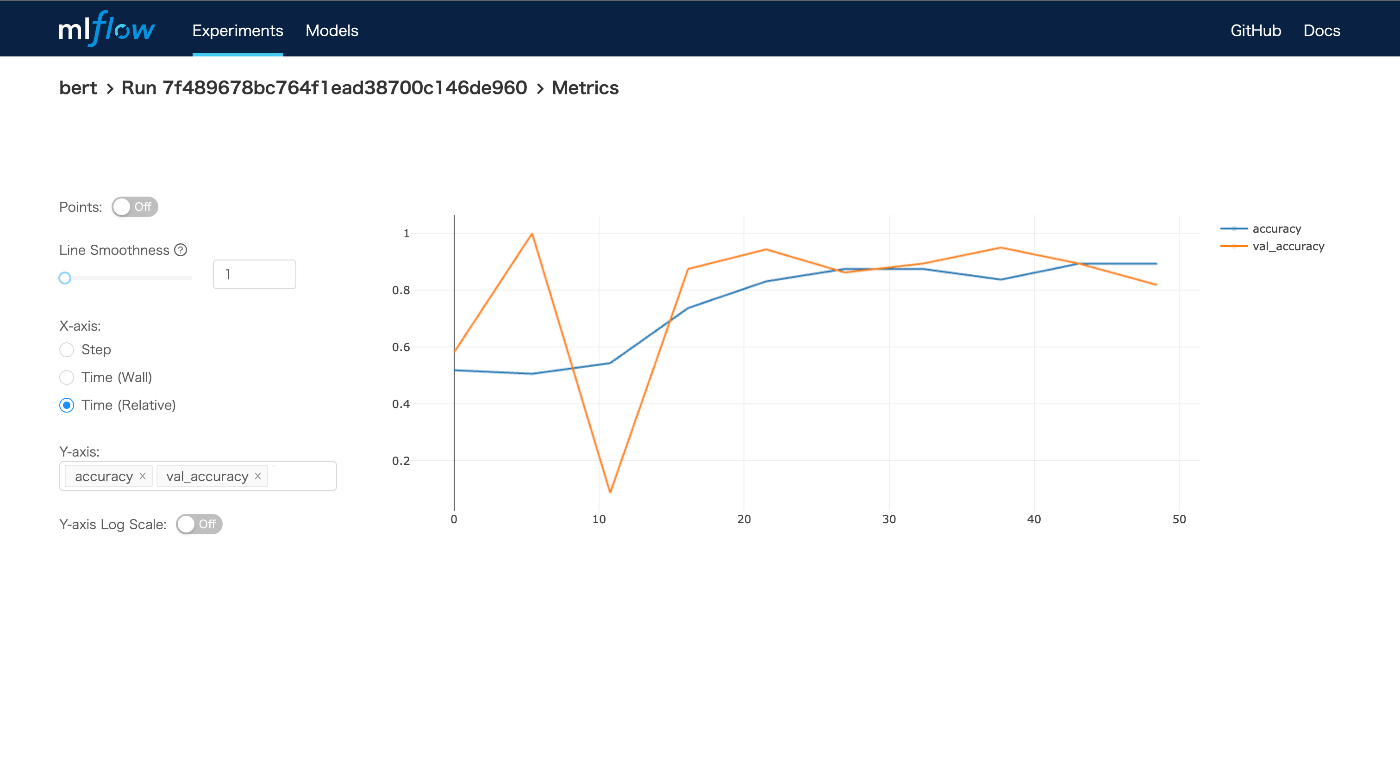
MLflow は設定不要で最低限の実験管理が可能である。非常に使いやすいと思う。
おわりに
Kubeflow + MLflow を用いて HuggingFace の Bert モデルの転移学習を実験管理を行った。TensorBoard はモデルを 1 から作る際には有用で、MLflow はハイパーパラメーターチューニングの実験管理には有用と感じた。ただ、機能は被っているので基本は MLflow を常に使う設定にしておいて、TensorBoard は必要な時だけ設定するという運用が一番楽かなと思っている。
ノートパソコンにインストールした VSCode でコーディングするのが一番快適なので、この Kubeflow の JupyterLab 環境を常用したくない。そのため、私が使うなら microk8s のホストに SSH して外部から NodePort を通じて MLflow や Minio にアクセスする形で運用することになるのかなと思っている。あと、Kubeflow でも JupyterLab はブラウザを閉じるとセッションが切れるのでこれも使いもににならない。この辺もどうにかしたい。
学習用の機械学習の環境ってコンテナで環境分離する必要ってほとんどなく、大抵は conda で分離すれば済む。そのため kubeflow がコンテナで環境を分離してるのは少し冗長なやり方だと思う。例えば、JAX/Flax を試したいだけなのにわざわざ Dockerfile を作ってコンテナをビルドして、Docker Hub に上げてから Kubeflow で使うとかやってられない気がする。なので、kubeflow とは別の conda だけが使える環境は作成しておきたい。ただ、いつまでも自分の conda 環境だけで開発していてもしょうがないので、どっかのタイミングでコンテナ作って機械学習基盤に載せてパラメーターをチューニングして、サービスとしてリリースするみたいな開発の仕方になるんだと思う。
Kubeflow にはパラメーターを自動でチューニングする機能があるらしい。その機能と MLflow や TensorBoard を組み合わせて使ってみたい。
Discussion