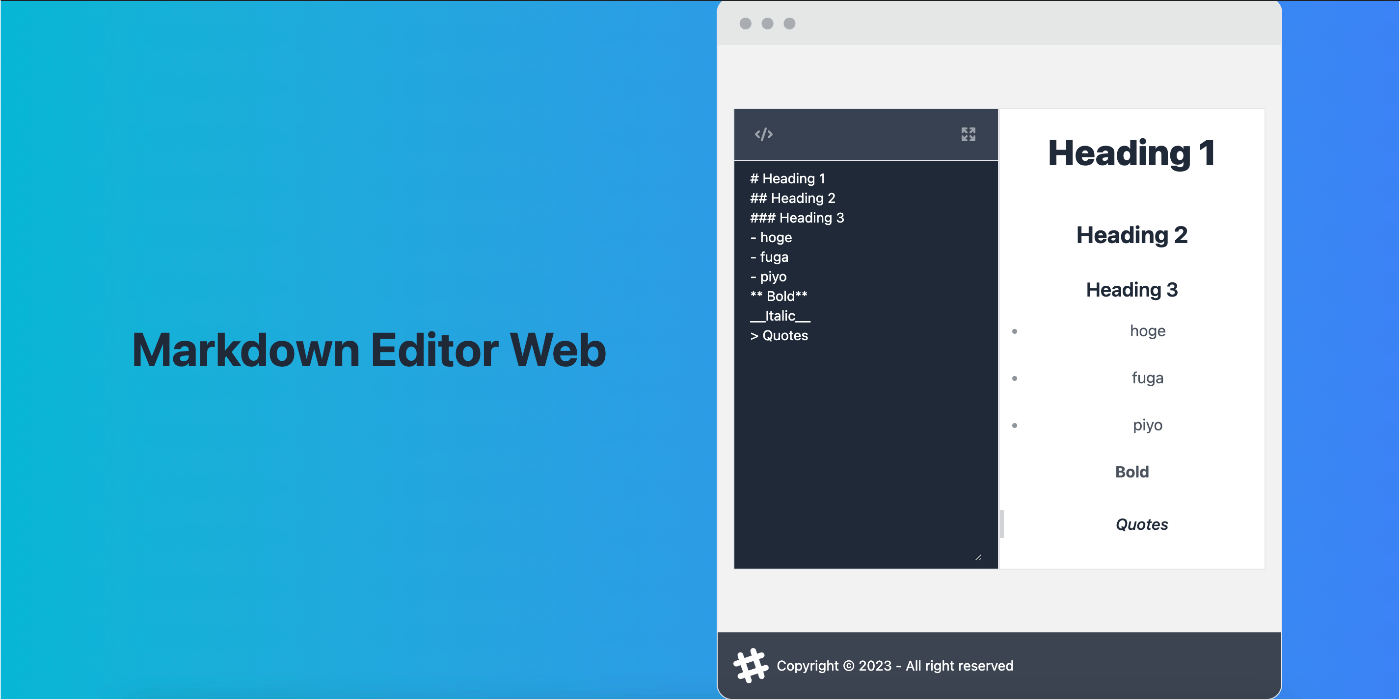
Rustでマークダウンパーサーを自作して、WASM+Nuxt3+Viteで動かしてみた
はじめに
Rustと言語処理系の勉強のため、簡易的なマークダウンパーサーをスクラッチで実装し、生成したWASMをNuxt3+Viteの環境で動かしてみました。
言語処理系の概要
マークダウンパーサを実装する前に、一般的な言語処理系について考えてみます。
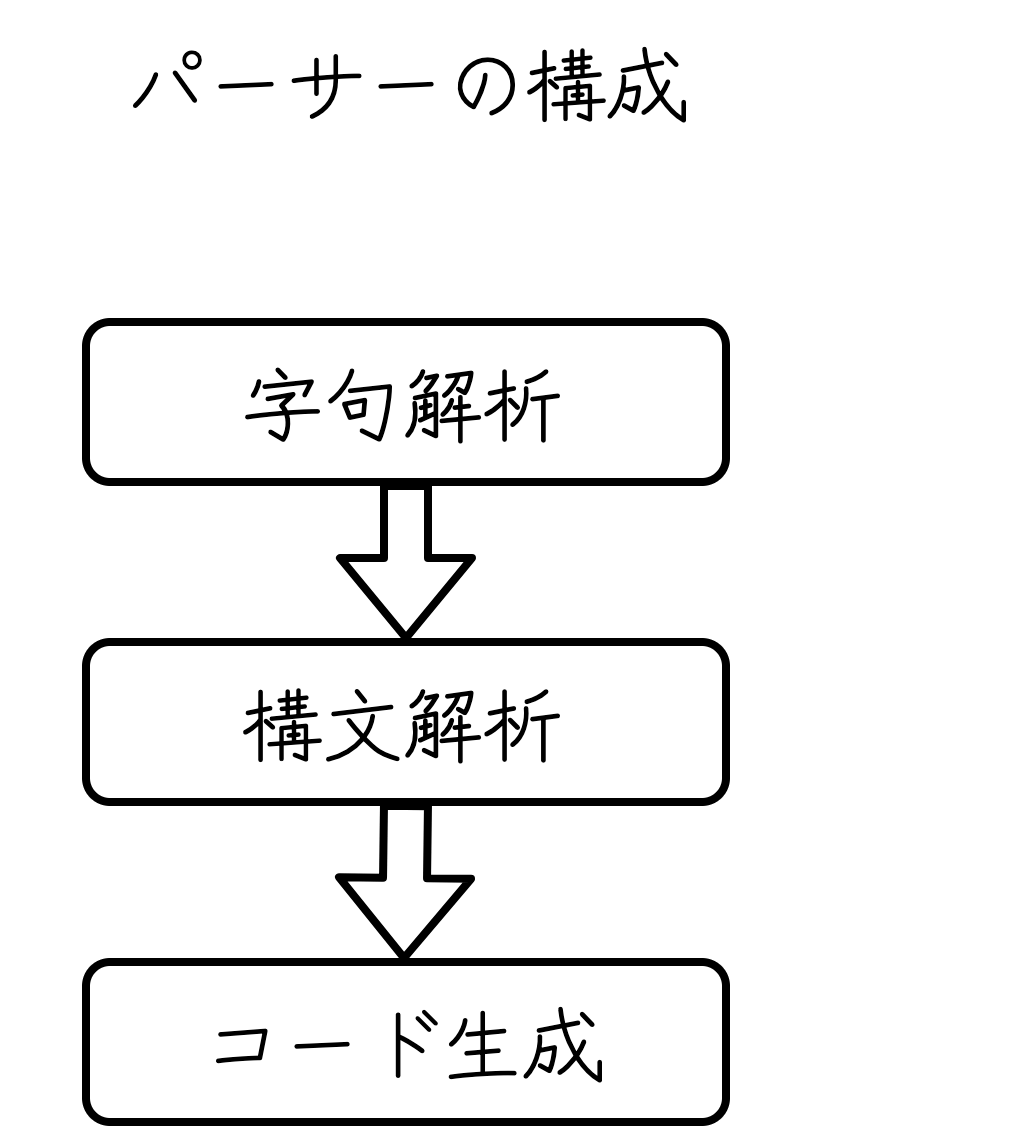
コンパイラやインタプリタに代表される処理系の構成は以下のようになっています。

- 字句解析
- テキストを字句の列(トークン)に分解すること
字句解析を行うプログラムを 字句解析器(lexerまたはtokenizer) と呼びます。
- 構文解析
- トークン列を 抽象構文木(abstract syntax treeまたはAST) に変換する。抽象構文木とは、言語の構文を解釈し、データ構造を取り出した(抽象化した)木構造のこと
たとえばDOMツリーは、HTMLの構文を解釈(構文解析)し、要素(タグ)を木構造で表現したものです。
構文解析を行うプログラムを 構文解析器(parser) と呼びます。
3. 意味解析
- 構文木の意味を解析する
- コンパイラでは、この段階で中間コードを生成する
4. 最適化
中間コードを変形して、効率のよいプログラムに変換すること
- 効率のよいプログラムとは、実行速度が高速であったり、使用するメモリ容量がより少ないプログラムのこと
- 使用するアルゴリズムを変更したり、命令数を減らすことで効率化を行う
- コンパイラでは、パースしたソースコードから無駄な処理を分析し、コード最適化を行う
5. コード生成
- 抽象構文木を入力とし、ターゲットとなる言語のコードを生成する
- コンパイラでは、この段階で中間コードをネイティブコード(ターゲットのCPUが解釈できる実行形式のバイナリコード)に変換する
コード生成器を行うプログラムを コード生成器(Generator) と呼びます。
今回作成するマークダウンパーサーは、次の三つの処理系から構成されています。
マークダウンテキストを入力としてトークンに分割(字句解析)し、ASTに変換(構文解析)、最終的にHTMLを生成(コード生成)できるようにします。
ここからは、マークダウンパーサーの内部実装を見ていきます。
1. 字句解析器(Lexer)の実装
字句解析器は、以下のような工程で実装します。
- 字句の列(トークン)を定義する
- 入力されたテキストをトークンに分割する
マークダウン記法について
マークダウンには、非常に多くの記法が存在します。
簡単化のため、マークダウンの以下の記法に限定して実装します。
- 見出し(
<h1>~<h6>) - 太字(
<b>) - 斜体(
<i>) - 引用(
<blockquotes>) - リスト(
<ul>,<li>)
今回の記事では、見出し/Heading の実装を例に解説します。
# 見出し<h1>
## 見出し<h2>
### 見出し<h3>
...
###### 見出し<h6>
トークンを定義する
まず最初に、Heading,Bold,Italic,BlockQuotes,Lists の5つのトークンを作成します。
#[derive(Clone, Debug, PartialEq)]
#[cfg_attr(feature = "serde", derive(Serialize, Deserialize))]
pub enum Token {
Heading(HeadingLevel, String),
Bold(String),
Italic(String),
Text(String),
BlockQuotes(String),
Lists(String),
}
#[derive(Copy, Clone, Eq, PartialEq, Ord, PartialOrd, Hash, Debug)]
#[cfg_attr(feature = "serde", derive(Serialize, Deserialize))]
pub enum HeadingLevel {
H1 = 1,
H2,
H3,
H4,
H5,
H6,
}
マークダウンテキストを言語の要素(トークン)の列に分割する:字句解析(Tokenize)
字句解析は関数lexが担います。
字句解析のための文字列操作はイテレータで行います。
イテレータとは、複数個の要素の集まり(配列・リストなど)から、次の要素を一つずつ順に取り出すインターフェースです。
Rustにおいては、標準ライブラリのIteratorトレイトで定義されています。
一連の要素をイテレータで処理する - The
Rust Programming Language 日本語版
やstd::iter::Iterator - Rust を読み進めながら、Iteratorトレイトを使って実装します。
fn next(&mut self) -> Option<Self::Item>
nextはイテレータを消費するメソッドです。
呼び出されるたびにイテレータを消費し、Some に包まれた一要素を返します。
繰り返しが終わるとNoneを返します。
使い切ったイテレータを再度使おうとする(Noneを呼び出したときにnext()を再度呼び出す)とき、Someを再び返し始める場合とNoneを返す場合があるようです。
Returns None when iteration is finished. Individual iterator implementations may choose to resume iteration, and so calling next() again may or may not eventually start returning Some(Item) again at some point.
while let Some(c) = chars.next()
で、入力された文字列を一つずつ取り出し、変数cに格納します。
match (c, in_bold, in_italic) {
('#', false, false) => {
}
// ...
}
でパターンマッチングを行います。
見出しタグの判定では、頭文字が#と (半角スペース)で始まる語句を識別できるようにしたいです。
そのため、変数cが#、in_boldがfalse(太字ではない)でin_italicがfalse(斜体ではない)のときにのみ処理を行います。
pub fn peek(&mut self) -> Option<&<I as Iterator>::Item>
peekはイテレータを消費する前に、前もって参照を返す(新たなイテレータPeekable<T>を返す)メソッドです。
let mut level = 1;
while chars.peek() == Some(&'#') {
chars.next();
level += 1;
}
で、行頭に#が連続して出現する時(chars.peek()とSome(&'#')が等しい時)、一文字ずつ文字列を読み進めながら、levelを1ずつ加算していきます。
levelの値に応じて見出しのレベルを判定します。
tokens.push(Token::Heading(
match level {
1 => HeadingLevel::H1,
2 => HeadingLevel::H2,
3 => HeadingLevel::H3,
4 => HeadingLevel::H4,
5 => HeadingLevel::H5,
_ => HeadingLevel::H6,
},
chars.collect(),
));
で、適切なToken::Headingをtokensに追加し、見出しをトークン化します。
また、
while let Some(' ') = chars.peek() {
chars.next();
}
では、現在の文字が半角スペースのときにのみ、charsから文字を取り出します。これにより、半角スペースの後に続くテキストがTokenの値に正しく解釈されます。
以下のテストコードを例に見てみます。
#[test]
fn test_lex() {
let input = "## Heading 2";
let expected_output = vec![
Token::Heading(HeadingLevel::H2, "Heading 2".to_string()),
];
assert_eq!(lex::lex(input), expected_output);
}
## Heading 2から半角スペース を削除し、後に続くテキスト"Heading 2".to_string()を正しく解釈して、Headingの第二引数に出力します。
...
while let Some(c) = chars.next() {
let mut tokens = Vec::new();
let mut buffer = String::new();
let mut in_bold = false;
let mut in_italic = false;
match (c, in_bold, in_italic) {
('#', false, false) => {
// Heading
let mut level = 1;
while chars.peek() == Some(&'#') {
chars.next();
level += 1;
}
// Skip whitespace
while let Some(' ') = chars.peek() {
chars.next();
}
tokens.push(Token::Heading(
match level {
1 => HeadingLevel::H1,
2 => HeadingLevel::H2,
3 => HeadingLevel::H3,
4 => HeadingLevel::H4,
5 => HeadingLevel::H5,
_ => HeadingLevel::H6,
},
chars.collect(),
));
break;
}
...
lex.rsの最終的な実装は以下のようになります。
use crate::{HeadingLevel, Token};
pub fn lex(input: &str) -> Vec<Token> {
let mut tokens = Vec::new();
let mut buffer = String::new();
let mut in_bold = false;
let mut in_italic = false;
for line in input.lines() {
let mut chars = line.chars().peekable();
while let Some(c) = chars.next() {
match (c, in_bold, in_italic) {
('#', false, false) => {
// Heading
let mut level = 1;
while chars.peek() == Some(&'#') {
chars.next();
level += 1;
}
// Skip whitespace
while let Some(' ') = chars.peek() {
chars.next();
}
tokens.push(Token::Heading(
match level {
1 => HeadingLevel::H1,
2 => HeadingLevel::H2,
3 => HeadingLevel::H3,
4 => HeadingLevel::H4,
5 => HeadingLevel::H5,
_ => HeadingLevel::H6,
},
chars.collect(),
));
break;
}
('>', false, false) => {
// BlockQuotes
if !buffer.is_empty() {
tokens.push(Token::Text(buffer.clone()));
buffer.clear();
}
// Skip whitespace
while let Some(' ') = chars.peek() {
chars.next();
}
tokens.push(Token::BlockQuotes(chars.collect()));
break;
}
('-' | '+', false, false) => {
// Lists
if !buffer.is_empty() {
tokens.push(Token::Text(buffer.clone()));
buffer.clear();
}
// Skip whitespace
while let Some(' ') = chars.peek() {
chars.next();
}
tokens.push(Token::Lists(chars.collect()));
break;
}
('*', false, false) if chars.peek() == Some(&'*') => {
// Bold
chars.next();
if !buffer.is_empty() {
tokens.push(Token::Text(buffer.clone()));
buffer.clear();
}
in_bold = true;
}
('*', true, false) if chars.peek() == Some(&'*') => {
// End of Bold
chars.next();
tokens.push(Token::Bold(buffer.clone()));
buffer.clear();
in_bold = false;
}
('_', false, false) => {
// Italic
chars.next();
if !buffer.is_empty() {
tokens.push(Token::Text(buffer.clone()));
buffer.clear();
}
in_italic = true;
}
('_', false, true) if chars.peek() == Some(&'_') => {
// End of Italic
chars.next();
tokens.push(Token::Italic(buffer.clone()));
buffer.clear();
in_bold = false;
}
_ => {
// Text
buffer.push(c);
}
}
}
if !buffer.is_empty() {
tokens.push(Token::Text(buffer.clone()));
buffer.clear();
}
tokens.push(Token::Text("\n".to_string()));
if let Some(Token::Text(last)) = tokens.last() {
if last == "\n" {
tokens.pop();
}
}
}
tokens
}
テスト
テストを書きます。
#[test]
fn test_lex() {
let input = "## Heading 2\n\n> This is a blockquote.\n\nMore **bold** and __italic__ text.";
let expected_output = vec![
Token::Heading(HeadingLevel::H2, "Heading 2".to_string()),
Token::BlockQuotes("This is a blockquote.".to_string()),
Token::Text("More ".to_string()),
Token::Bold("bold".to_string()),
Token::Text(" and ".to_string()),
Token::Italic("italic".to_string()),
Token::Text(" text.".to_string()),
];
assert_eq!(lex::lex(input), expected_output);
}
テストが通れば、Lexerは完成です。
warning: `markdown-parser` (lib test) generated 1 warning
Finished test [unoptimized + debuginfo] target(s) in 1.29s
Running unittests src/lib.rs (target/debug/deps/markdown_parser-8cdd342dfae61de5)
running 1 test
test lex::test_lex ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
2. 構文解析器(Parser)の実装
- トークンから抽象構文木(AST)を構築する
- ASTはノードが集まってできた木構造
- たとえば
Heading(見出し)タグは、Heading Level(見出しレベル)ノードとText(文字列)ノードが集まってASTを構築する
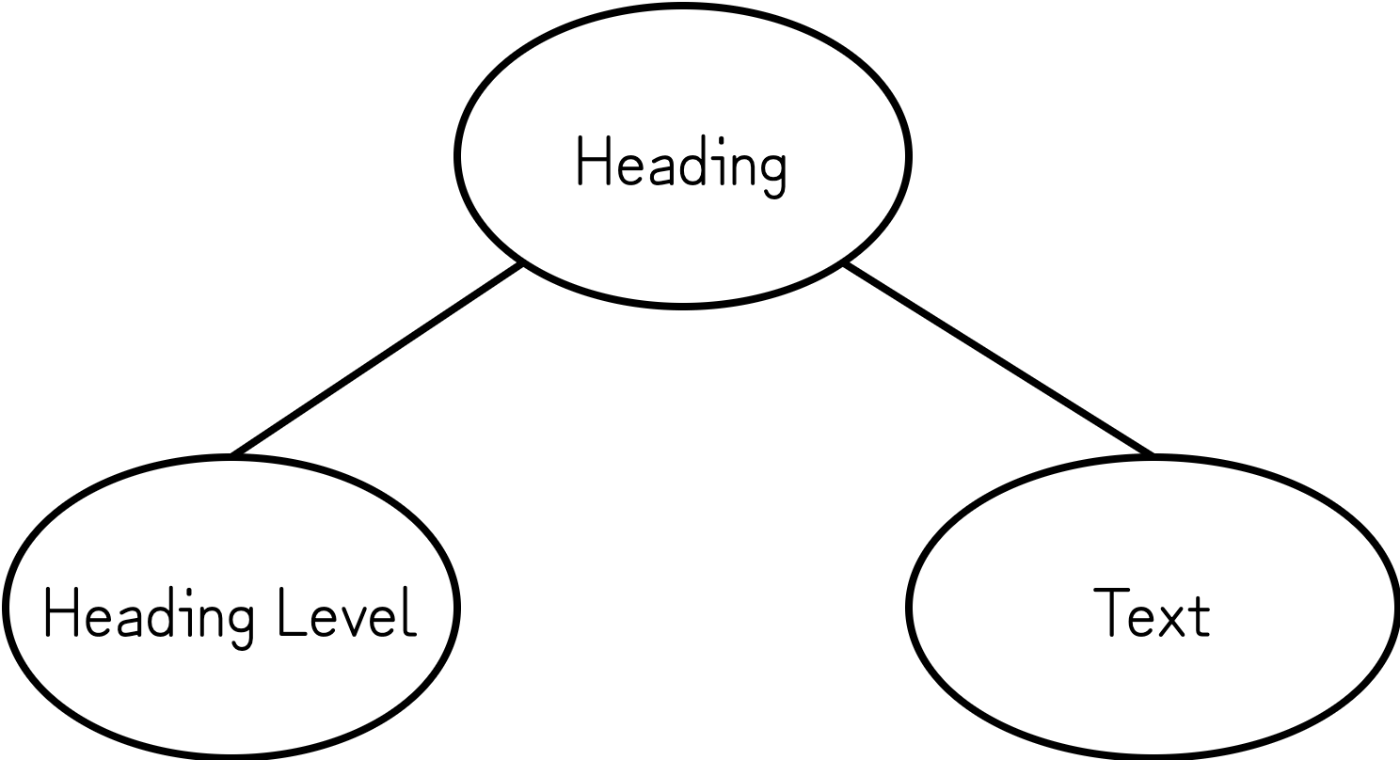
トークンから抽象構文木(AST)を構築する
トークン配列から抽象構文木(AST)を構築します。
use crate::token::HeadingLevel;
#[derive(Clone, Debug, PartialEq)]
pub enum AstNode {
Heading(HeadingLevel, String),
Bold(String),
Italic(String),
Text(String),
BlockQuotes(String),
Lists(String),
Paragraph(Vec<AstNode>),
}
以下のコードでは、Token::Headingをパースして、AstNode::Headingに変換しています。
Token::Heading(level, text) => {
if !current_paragraph.is_empty() {
result.push(AstNode::Paragraph(current_paragraph.clone()));
current_paragraph.clear();
}
result.push(AstNode::Heading(level.clone(), text.clone()));
}
parse.rsの最終的な実装は以下のようになります。
use crate::{ast::AstNode, token::Token};
pub fn parse(tokens: &[Token]) -> Vec<AstNode> {
let mut result = Vec::new();
let mut current_paragraph = Vec::new();
let mut in_bold = false;
let mut in_italic = false;
for token in tokens {
match token {
Token::Heading(level, text) => {
if !current_paragraph.is_empty() {
result.push(AstNode::Paragraph(current_paragraph.clone()));
current_paragraph.clear();
}
result.push(AstNode::Heading(level.clone(), text.clone()));
}
Token::BlockQuotes(text) => {
if !current_paragraph.is_empty() {
result.push(AstNode::Paragraph(current_paragraph.clone()));
current_paragraph.clear();
}
result.push(AstNode::BlockQuotes(text.clone()));
}
Token::Lists(text) => {
if !current_paragraph.is_empty() {
result.push(AstNode::Paragraph(current_paragraph.clone()));
current_paragraph.clear();
}
result.push(AstNode::Lists(text.clone()));
}
Token::Bold(text) => {
if !in_bold {
current_paragraph.push(AstNode::Bold(text.clone()));
in_bold = true;
} else {
current_paragraph.push(AstNode::Text(text.clone()));
in_bold = false;
}
}
Token::Italic(text) => {
if !in_italic {
current_paragraph.push(AstNode::Italic(text.clone()));
in_italic = true;
} else {
current_paragraph.push(AstNode::Text(text.clone()));
in_italic = false;
}
}
Token::Text(text) => {
if !in_bold && !in_italic {
current_paragraph.push(AstNode::Text(text.clone()));
} else {
let mut inner_paragraph = Vec::new();
inner_paragraph.push(AstNode::Text(text.clone()));
if in_bold {
inner_paragraph.push(AstNode::Bold(text.clone()));
}
if in_italic {
inner_paragraph.push(AstNode::Italic(text.clone()));
}
in_bold = false;
in_italic = false;
}
}
}
}
if !current_paragraph.is_empty() {
result.push(AstNode::Paragraph(current_paragraph.clone()));
current_paragraph.clear();
}
result
}
テスト
lexer~parserの挙動を見るためのテストを書きます。
#[test]
fn test_lex_and_parse() {
let input = "\
# Hello, world!\n
> This is a blockquote\n
This is a **markdown** __parser__.";
let expected_output = vec![
AstNode::Heading(HeadingLevel::H1, "Hello, world!".to_string()),
AstNode::BlockQuotes("This is a blockquote".to_string()),
AstNode::Paragraph(vec![
AstNode::Text("This is a ".to_string()),
AstNode::Bold("markdown".to_string()),
AstNode::Italic("parser".to_string()),
]),
];
let tokens = lex::lex(input);
let output = parse::parse(&tokens);
assert_eq!(output, expected_output);
}
テストが通ればParserの実装は完成です。
warning: `markdown-parser` (lib test) generated 1 warning
Finished test [unoptimized + debuginfo] target(s) in 1.60s
Running unittests src/lib.rs (target/debug/deps/markdown_parser-8cdd342dfae61de5)
running 1 test
test parse::test_lex_and_parse ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
3. コード生成器(Generator)の実装
- 構築されたASTをHTMLに変換する
AstNode型のスライスを参照するast: &[AstNode]を引数に持ち、Stringを返す関数generate_htmlを定義します。
let mut result = String::new();
for node in ast {
match node {
// ...
}
}
で、パターンマッチングを行います。
AstNode::Heading(HeadingLevel::H1, text) => {
result.push_str(&format!("<h1>{}</h1>", text));
}
AstNode::Heading(HeadingLevel::H2, text) => {
result.push_str(&format!("<h2>{}</h2>", text));
}
AstNode::Heading(HeadingLevel::H3, text) => {
result.push_str(&format!("<h3>{}</h3>", text));
}
...
ASTのノードをhtmlタグにフォーマットし、result配列に追加する処理を愚直に書きます。
generator.rs の全実装は以下のようになります。
use crate::{AstNode, HeadingLevel};
pub fn generate_html(ast: &[AstNode]) -> String {
let mut result = String::new();
for node in ast {
match node {
AstNode::Heading(HeadingLevel::H1, text) => {
result.push_str(&format!("<h1>{}</h1>", text));
}
AstNode::Heading(HeadingLevel::H2, text) => {
result.push_str(&format!("<h2>{}</h2>", text));
}
AstNode::Heading(HeadingLevel::H3, text) => {
result.push_str(&format!("<h3>{}</h3>", text));
}
AstNode::Heading(HeadingLevel::H4, text) => {
result.push_str(&format!("<h4>{}</h4>", text));
}
AstNode::Heading(HeadingLevel::H5, text) => {
result.push_str(&format!("<h5>{}</h5>", text));
}
AstNode::Heading(HeadingLevel::H6, text) => {
result.push_str(&format!("<h6>{}</h6>", text));
}
AstNode::BlockQuotes(text) => {
result.push_str(&format!("<blockquote>{}</blockquote>", text));
}
AstNode::Lists(text) => {
result.push_str(&format!("<ul><li>{}</li></ul>", text));
}
AstNode::Bold(text) => {
result.push_str(&format!("<b>{}</b>", text));
}
AstNode::Italic(text) => {
result.push_str(&format!("<i>{}</i>", text));
}
AstNode::Text(text) => {
result.push_str(&text);
}
AstNode::Paragraph(nodes) => {
result.push_str("<p>");
result.push_str(&generate_html(nodes));
result.push_str("</p>");
}
}
}
result
}
4. レンダリング
ここまでに作成したパッケージを、関連関数text_to_tokenで呼び出します。
mod ast;
mod lex;
mod parse;
mod to_html;
mod token;
pub fn text_to_token(input_text: &str) -> String {
let tokens = lex::lex(input_text);
let ast = parse::parse(&tokens);
to_html::generate_html(&ast)
}
5. WASMを生成する
ここでは、wasm-packというツールを使ってビルドを行います。
下記のコマンドでインストールをし
curl https://rustwasm.github.io/wasm-pack/installer/init.sh -sSf | sh
Cargo.tomlで環境設定を行います。
...
[dependencies]
cfg-if = "1.0.0"
js-sys = "0.3.61"
wasm-bindgen = "0.2.84"
[dependencies.web-sys]
version = "0.3"
features = [
"Window"
]
[lib]
crate-type = ["cdylib", "rlib"]
lib.rsに#[wasm_bindgen]アトリビュートを付与します。
extern crate wasm_bindgen;
mod ast;
mod lex;
mod parse;
mod to_html;
mod token;
#[wasm_bindgen]
pub fn text_to_token(input_text: &str) -> String {
let tokens = lex::lex(input_text);
let ast = parse::parse(&tokens);
to_html::generate_html(&ast)
}
WASMをコンパイルするため、wasm32-unknown-emscriptenというターゲットアーキテクチャの追加を行います。
% rustup target add wasm32-unknown-unknown
ビルドを行います。
% wasm-pack build
target/wasm32-unknown-unknown/release に、最適化されたビルドバイナリが出力されます。
6. Webフロントエンド側の実装
ビルド成功後、pkg/ というディレクトリが生成されます。
フロントエンドのビルド時にwasm-packが走るにしたいので、フロントエンド側のリポジトリにvite-plugin-wasm-packを追加します。
vite.config.ts で設定を行います。
plugins: [wasmPack("./markdown-parser")] で、Rust側のディレクトリのpathを指定しています。
import { defineConfig } from "vite";
import wasmPack from "vite-plugin-wasm-pack";
export default defineConfig({
build: {
minify: false,
},
// pass your local crate path to the plugin
plugins: [wasmPack("./markdown-parser")],
});
package.json に以下の実行コマンドを追加し、% npm run wasmでビルドが走るようにします。
{
...
"scripts": {
"wasm": "wasm-pack build ./markdown-parser --target web" // ./markdown-parserにはRust側のディレクトリのpathを指定する
}
...
}
Viewの実装の詳細は以下のようになっています。
<script lang="ts">
...
import { text_to_token } from "markdown-parser";
let wasmContainer: { text_to_token: typeof text_to_token };
import("markdown-parser").then((wasm) => (wasmContainer = wasm));
...
</script>
で読み込んだtext_to_token を
<script lang="ts">
...
export default defineComponent({
name: "App",
components: {},
setup() {
const inputText = ref("");
const outputHtml = ref("");
const convert = () => {
console.log(inputText.value);
console.log(wasmContainer?.text_to_token(inputText.value));
outputHtml.value = wasmContainer?.text_to_token(inputText.value);
};
return { convert, inputText, outputHtml };
},
});
</script>
ここで実行しています。
フロントエンド側のディレクトリでローカルサーバーを立ち上げ後、
% npm run dev
http://localhost:3000 でレンダリング結果が確認できます。
最後に
Rust製のマークダウンパーサーは、有名なものとしてpulldown-cmark があります。
扱いやすく多機能なため、手軽にマークダウンエディタを作りたいときは上記のライブラリを使うのがよさそうです。
車輪の再発明ですが、一度はスクラッチで言語処理系の実装をしてみたかったため、よい勉強になりました。
参考文献
Discussion
perser -> parser ?
ご指摘ありがとうございます!
修正しましたmm