0. はじめに
こんにちは!
23 新卒で株式会社ディー・エヌ・エーに入社し,MLOps エンジニアをやっている @a5chin です.
本記事では,Event-Driven[1] で Cloud Storage から Cloud Spanner[2] にデータを取り込む Dataflow を作りたいと思います.
ベストプラクティスに関する情報がなかったので,試行錯誤した結果を記事にしました.
1. 結論
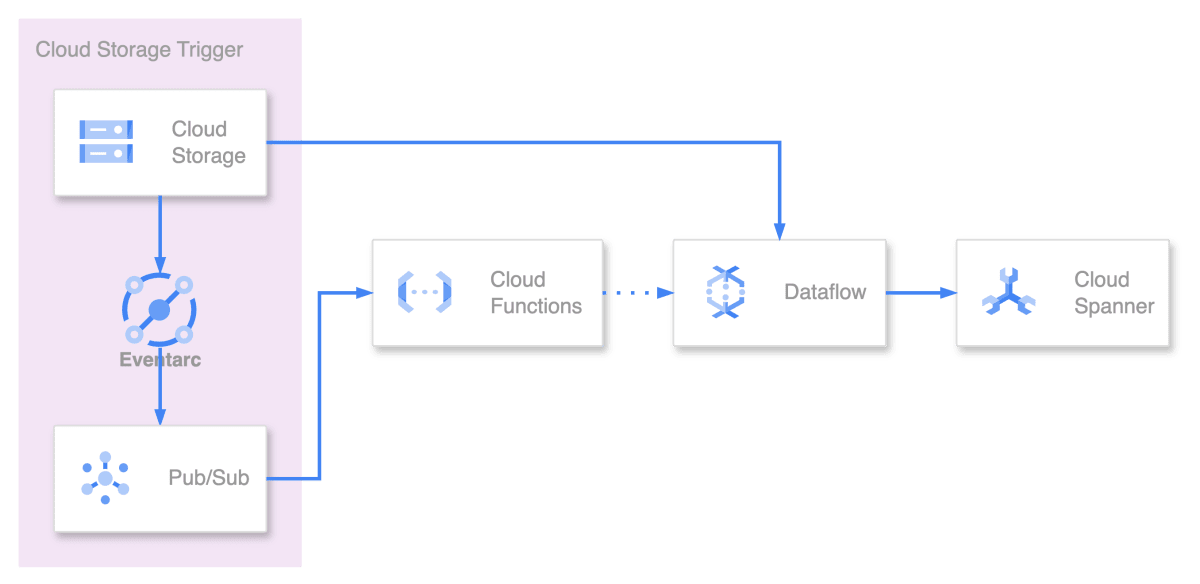
Event-Driven[1:1] に Dataflow を作成するためのアーキテクチャ
本記事では,以下のフローの様な Cloud Storage(Avro)から Cloud Spanner[2:1] にデータを取り込む Terraform[3] Module を作成します.
- Cloud Storage にファイルが格納されたら Eventarc から イベントを受け取る
- 受け取ったイベントにより Cloud Functions が起動する
- 格納されたファイルが
spanner-export.jsonであれば - Google API の Access Token を取得し
- Dataflow 作成 API に POST[4] することによって Dataflow を作成する
- 作成された Dataflow によって Cloud Storage の Bucket[5] に存在する
spanner-export.jsonと同じ階層の.avroファイルを Cloud Spanner[2:2] に Import する
1.1. サンプルプログラム
本記事で解説する内容は上記のリポジトリでサンプルを実行できます.
上記のリポジトリにおける,treeコマンドの出力を下記に示します.
Terraform[3:1]のベストプラクティスに則って,以下の様なenvironments, modulesに階層を分ける構成にして実装していきます.
.
├── environments
│ └── dev
│ ├── .terraform-version
│ ├── .terraform.lock.hcl
│ ├── backend.tf
│ ├── main.tf
│ ├── provider.tf
│ ├── terraform.tfvars
│ ├── variables.tf
│ └── versions.tf
└── modules
├── bucket.tf
├── dataflow.tf
├── functions.tf
├── sa.tf
├── src
│ ├── authz.py
│ ├── extract.py
│ ├── logger.py
│ ├── main.py
│ ├── requirements.txt
│ └── tests
│ └── test_extract.py
└── variables.tf
2. Cloud Storage
Cloud Storage は,Google Cloud でオブジェクトを保存するためのサービスで,本記事では以下の用途で利用します.
- Cloud Spanner[2:3] に Import する
.avroファイルの格納 - Cloud Spanner[2:4] で Import するために必要な
spanner-export.jsonファイルの格納 - Cloud Functions のソースコードの格納
- Dataflow のステージングに用いるファイルを一時的に格納
Cloud Storage is a service for storing your objects in Google Cloud. An object is an immutable piece of data consisting of a file of any format. You store objects in containers called buckets.
2.1. spanner-export.json
上記リンク先に記載の通り,Cloud Storage から Cloud Spanner[2:5] にデータを取り込む Dataflow を動かすためには,以下の様なフォーマットのspanner-export.jsonという名前のファイルを作成する必要があります.
記載する情報としては,以下 2 点です.
- Cloud Spanner[2:6] のテーブル名
-
spanner-export.jsonファイルから見た時の.avroファイルまでの相対パス
{
"tables": [
{
"name": "TABLE1",
"dataFiles": [
"RELATIVE/PATH/TO/TABLE1_FILE1",
"RELATIVE/PATH/TO/TABLE1_FILE2"
]
},
{
"name": "TABLE2",
"dataFiles": ["RELATIVE/PATH/TO/TABLE2_FILE1"]
}
],
"dialect": "DATABASE_DIALECT"
}
2.2. Terraform コード
locals {
filename = "00000000.zip"
}
// Cloud Functions のソースコードを zip ファイルに圧縮する
data "archive_file" "src" {
type = "zip"
source_dir = "${path.module}/src/"
output_path = "tmp/${local.filename}"
}
// zip ファイルに圧縮した Cloud Functions のソースコードを Bucket にコピーする
resource "google_storage_bucket_object" "dataflow_creator" {
name = "dataflow-creator/${local.filename}"
source = data.archive_file.main.output_path
bucket = "${var.project_id}_build_artifacts"
}
// `.avro`, `spanner-export.json`ファイルの格納に用いる Bucket
resource "google_storage_bucket" "input_dir" {
name = var.dataflow.parameters.inputDir
location = var.location
public_access_prevention = "enforced"
uniform_bucket_level_access = true
}
// Cloud Storage の Service Identity
resource "google_project_service_identity" "storage" {
provider = google-beta
project = var.project_id
service = "storage.googleapis.com"
}
// Cloud Storage に Pub/Sub の Topic に Publish できる権限を付与する
resource "google_project_iam_member" "storage" {
project = var.project_id
role = "roles/pubsub.publisher"
member = "serviceAccount:service-${data.google_project.main.number}@gs-project-accounts.iam.gserviceaccount.com"
}
3. Eventarc
Eventarc は,基盤となるインフラストラクチャを実装・カスタマイズ・メンテナンスすることなく,イベントドリブン[1:2]なアーキテクチャを構築できます.
本記事では,Cloud Storage にファイルが格納されたことをトリガーにして Pub/Sub にイベントを送信する用途で使用します.
Eventarc は,Terraform[3:2] で Cloud Functinos 内にオプションとして記述でき,以下の章で解説していきます.
Eventarc lets you build event-driven architectures without having to implement, customize, or maintain the underlying infrastructure. Eventarc offers a standardized solution to manage the flow of state changes, called events, between decoupled microservices. When triggered, Eventarc routes these events to various destinations (in this document, see Event destinations) while managing delivery, security, authorization, observability, and error-handling for you.
3.1. 送信するイベント情報のフォーマット
Eventarc から送信され,Pub/Sub を通じて Cloud Functions が受け取るイベント情報は以下のフォーマットです.
一部正規表現等を使って匿名化しています.
{
"attributes": {
"specversion": "1.0",
"id": "[0-9]{17}",
"source": "//storage.googleapis.com/projects/_/buckets/{bucket}",
"type": "google.cloud.storage.object.v1.finalized",
"datacontenttype": "application/json",
"subject": "objects/2024/01-01/spanner-export.json",
"time": "2024-01-01T00:00:00.000000Z",
"bucket": "{bucket}"
},
"data": {
"kind": "storage#object",
"id": "{bucket}/2024/01-01/spanner-export.json/[0-9]{16}",
"selfLink": "https://www.googleapis.com/storage/v1/b/{bucket}/o/2024%2F01-01%2Fspanner-export.json",
"name": "2024/01-01/spanner-export.json",
"bucket": "{bucket}",
"generation": "[0-9]{16}",
"metageneration": "1",
"contentType": "application/json",
"timeCreated": "2024-01-01T00:00:00.000Z",
"updated": "2024-01-01T00:00:00.000Z",
"storageClass": "STANDARD",
"timeStorageClassUpdated": "2024-01-01T00:00:00.000Z",
"size": "{size}",
"md5Hash": "{md5Hash}",
"mediaLink": "https://storage.googleapis.com/download/storage/v1/b/{bucket}/o/2024%2F01-01%2Fspanner-export.json?generation=[0-9]{16}&alt=media",
"crc32c": "{crc32c}",
"etag": "{etag}"
}
}
3.2. Terraform コード
本記事では,Eventarc のコードは Cloud Functions のオプションを使うので一部抜粋して解説します.
...
event_trigger {
trigger_region = var.location
retry_policy = var.functions.event.event_type
// 新しいオブジェクトが作成されるか,既存のオブジェクトが上書きされ
// そのオブジェクトの新しい世代が作成されると送信される
event_type = "google.cloud.storage.object.v1.finalized"
// Eventarc, Pub/Sub で用いる Service Account
service_account_email = google_service_account.event.email
// イベントを発火する Buckt を指定する
event_filters {
attribute = "bucket"
value = google_storage_bucket.input_dir.name
}
}
...
resource "google_service_account" "event" {
account_id = var.functions.event.sa.id
display_name = "The service account for the syncer in notification"
}
resource "google_project_iam_member" "event" {
for_each = ["roles/artifactregistry.reader", "roles/eventarc.eventReceiver"]
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.event.email}"
}
// Eventarc, Pub/Sub に Cloud Functions を起動する権限を付与する
resource "google_cloud_run_v2_service_iam_member" "event" {
project = google_cloudfunctions2_function.main.project
location = google_cloudfunctions2_function.main.location
name = google_cloudfunctions2_function.main.name
role = "roles/run.invoker"
member = "serviceAccount:${google_service_account.event.email}"
}
4. Cloud Functions
Cloud Functions は対象のイベントが発生するとトリガーされるサービスで,本記事では以下の流れとなるように実装します.
- Eventarc からイベントを取得し
- Cloud Storage に格納されたファイルをフィルタリングし
spanner-export.jsonであれば - Google API の Access Token を取得し
- Dataflow を作成する Google API に POST[4:1] することによって Dataflow を作成する
Google Cloud Functions is a serverless execution environment for building and connecting cloud services. With Cloud Functions you write simple, single-purpose functions that are attached to events emitted from your cloud infrastructure and services. Your function is triggered when an event being watched is fired. Your code executes in a fully managed environment. There is no need to provision any infrastructure or worry about managing any servers.
4.1. POST 時に渡すパラメータ
Google API を使ってcurl[6]で Dataflow を作成するサンプルを書きました.
本記事では,以降で Cloud Functions を使って Post する様に構築していきます.
curl -X POST https://dataflow.googleapis.com/v1b3/projects/{PROJECT_ID}/locations/{LOCATION}/templates \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-d '{ \
"jobName": "JOB_NAME", \
"gcsPath": "GCS_PATH", \
"parameters": { \
"instanceId": "INSTANCE_ID", \
"databaseId": "DATABACE_ID", \
"inputDir": "INPUT_DIR", \
}, \
"environment": { \
"serviceAccountEmail": "SERVICE_ACCOUNT_EMAIL", \
"tempLocation": "TEMP_LOCATION", \
}, \
}'
4.2. Python コード
import os
from pathlib import Path
import requests
import functions_framework
from cloudevents.http.event import CloudEvent
from authz import get_token
from extract import get_folder, is_file_exists
from logger import get_logger
@functions_framework.cloud_event
def create_dataflow(cloud_event: CloudEvent):
# 受け取るイベントのフォーマットが変化する可能性もあるためのエラーハンドリング
try:
# attributes から subject を取得する
subject = Path(cloud_event.get("subject"))
except KeyError:
raise KeyError(f"Cannot found key 'subject' in Cloud Event attributes.")
logger = get_logger()
logger.info(f"Subject: {subject}")
if subject.name != "spanner-export.json":
logger.info("Skip Sync due to different file.")
return
# `spanner-export.json`ファイルが格納されたフォルダを抽出する
folder = get_folder(subject.as_posix())
# `.avro`ファイルが`spanner-export.json`ファイルと同じフォルダに存在しない場合
if not is_file_exists(os.environ["INPUT_DIR"], folder, extension := ".avro"):
raise FileNotFoundError(f"{extension} file is not found.")
# Access Token を取得する
access_token = get_token()
api = f"https://dataflow.googleapis.com/v1b3/projects/{os.environ['PROJECT_ID']}/locations/us-central1/templates"
headers = {"Authorization": f"Bearer {access_token}"}
body = {
"jobName": os.environ["JOB_NAME"],
"gcsPath": os.environ["GCS_PATH"],
"parameters": {
"instanceId": os.environ["INSTANCE_ID"],
"databaseId": os.environ["DATABACE_ID"],
"inputDir": f"{os.environ['INPUT_DIR']}/{folder}",
},
"environment": {
"serviceAccountEmail": os.environ["SERVICE_ACCOUNT_EMAIL"],
"tempLocation": os.environ["TEMP_LOCATION"],
},
}
response = requests.post(api, json=body, headers=headers)
logger.debug(body)
assert response.status_code == requests.codes.ok
4.4. Terraform コード
resource "google_cloudfunctions2_function" "dataflow_creator" {
name = var.functions.name
location = var.location
build_config {
runtime = "python310"
entry_point = "create_dataflow"
// Cloud Functions のソースコードの所在
source {
storage_source {
bucket = google_storage_bucket_object.dataflow_creator.bucket
object = google_storage_bucket_object.dataflow_creator.name
}
}
}
// Cloud Functions の設定
service_config {
max_instance_count = 1
min_instance_count = 0
available_memory = "128Mi"
timeout_seconds = var.functions.timeout_seconds
environment_variables = local.environment_variables
ingress_settings = "ALLOW_INTERNAL_ONLY"
service_account_email = google_service_account.gcf.email
}
// Eventarc, Pub/Sub の設定
event_trigger {
trigger_region = var.location
event_type = var.functions.event.event_type
retry_policy = var.functions.event.retry_policy
service_account_email = google_service_account.event.email
event_filters {
attribute = "bucket"
value = google_storage_bucket.input_dir.name
}
}
}
data "google_project" "main" {
}
resource "google_service_account" "gcf" {
account_id = "gcf"
display_name = "The service account for the syncer in Cloud Functions"
}
// Dataflow を作成するための権限を付与する
resource "google_project_iam_member" "gcf" {
for_each = ["roles/iam.serviceAccountUser", "roles/dataflow.developer"]
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.gcf.email}"
}
5. Dataflow
1 つ以上のソースから,ストリーム・バッチで大規模なデータを読み取り,変換し,宛先に書き込むデータパイプラインを作成するサービスで,本記事では以下の用途で利用します.
- Cloud Storage から
spanner-export.jsonに書かれている.avroファイルを読み取る - 読み込んだファイルを,作成したパイプラインで Cloud Spanner[2:7] の指定テーブルに Insert する
Dataflow is a Google Cloud service that provides unified stream and batch data processing at scale. Use Dataflow to create data pipelines that read from one or more sources, transform the data, and write the data to a destination.
5.1. テンプレートを実行するために必要なパラメータ
| パラメータ名 | 説明 | サンプル |
|---|---|---|
| JOB_NAME | Dataflow のジョブ名 | gcs-avro-to-cloud-spanner |
| GCS_PATH | Google 提供の Dataflow テンプレートが格納されている CLoud Storage Path | gs://dataflow-templates/2024-01-30-01_RC00/GCS_Avro_to_Cloud_Spanner |
| INSTANCE_ID | Cloud Spanner[2:8] の Instance ID | hoge |
| DATABACE_ID | Cloud Spanner[2:9] の Database ID | huga |
| INPUT_DIR | Cloud Spanner[2:10] に取り込む Avro ファイルと spanner-export.jsonが存在している Cloud Storage の Path |
gs://piyopiyo |
| SERVICE_ACCOUNT_EMAIL | Dataflow で使用する Service Account[7] のメールアドレス | dataflow@{PROJECT_ID}.iam.gserviceaccount.com |
| TEMP_LOCATION | Dataflow のステージングに用いられる一時的なファイルが格納される Cloud Storage の Path | gs://dataflow-staging-us-central1/temp/ |
5.2. Terraform コード
// Cloud Functions に渡す環境変数
locals {
environment_variables = {
PROJECT_ID = var.project_id
JOB_NAME = var.dataflow.name
GCS_PATH = var.dataflow.gcsPath
INSTANCE_ID = var.dataflow.parameters.instanceId
DATABACE_ID = var.dataflow.parameters.databaseId
INPUT_DIR = "gs://${google_storage_bucket.input_dir.name}"
SERVICE_ACCOUNT_EMAIL = google_service_account.dataflow.email
TEMP_LOCATION = "gs://${var.dataflow.temp_gcs_location}"
}
}
resource "google_service_account" "dataflow" {
account_id = var.dataflow.sa.id
display_name = "The service account for the syncer in Dataflow"
}
// Dataflow に適切な権限を付与する
resource "google_project_iam_member" "dataflow" {
for_each = [
"roles/dataflow.worker",
"roles/monitoring.metricWriter",
"roles/spanner.databaseUser",
"roles/storage.objectUser"
]
project = var.project_id
role = each.value
member = "serviceAccount:${google_service_account.dataflow.email}"
}
6. 苦労した点
本記事のアーキテクチャを構成するにあたって苦戦したポイントがいくつかあるので,まとめたいと思います.
6.1. Pub/Sub で Google API の認証を突破できない
Google API を利用して Dataflow を作成することがゴールです.
そのためには,Google API の認証 Access Token を取得して突破する必要があります.
6.1.1. 検討したアーキテクチャ
Pub/Sub 機能の 1 つとして Push Subscription があり,認証機能も存在しているので Push Subsrcription から Google API を叩けると思っていました.
しかし,Google API への認証が通らずpush_request_count auth_required_401 Error が帰ってきていました.
原因としては,Push Subscription で署名される JWT[8] は Access Token ではなく ID Token であったためです.
そのため,本記事では Cloud Functions を使って Access Token を生成することで認証を突破しています.
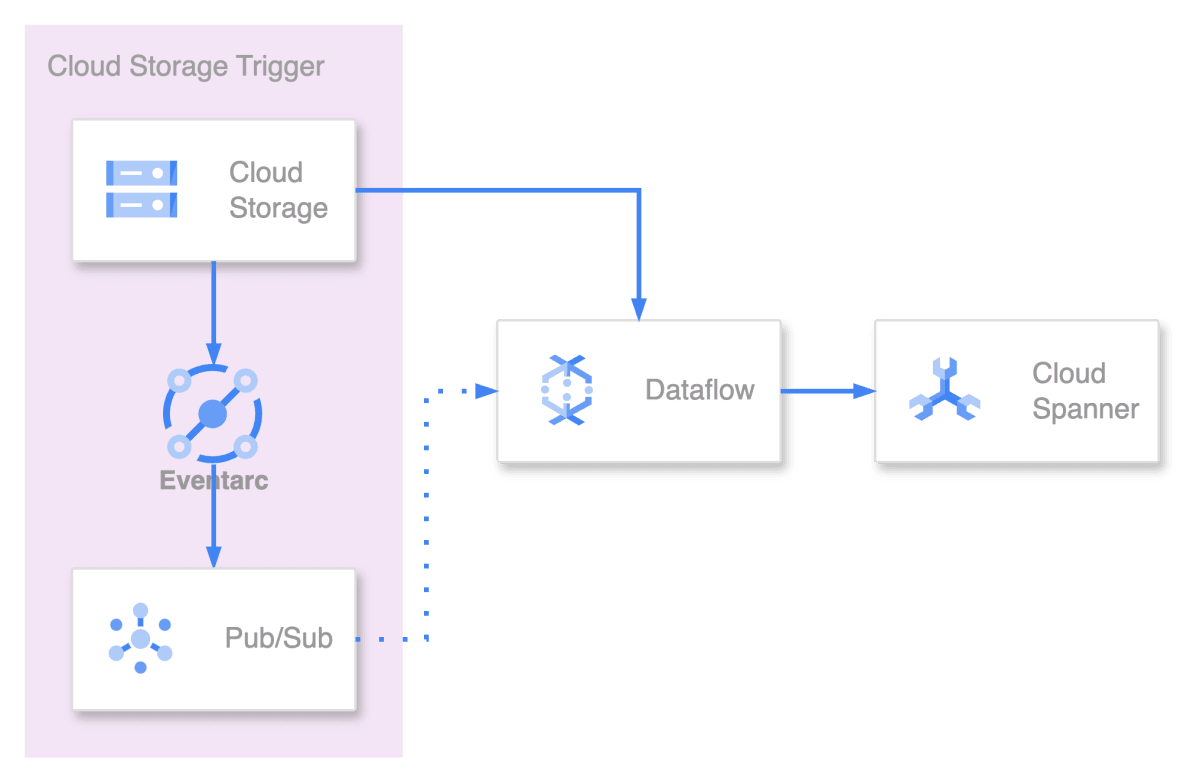
採用したかったが要件を満たせなかったアーキテクチャ
6.1.2. Access Token
Access tokens are opaque tokens that conform to the OAuth 2.0 framework. They contain authorization information, but not identity information. They are used to authenticate and provide authorization information to Google APIs.
以下 Access Token の特徴とフォーマットです.
- Google API に認証情報を提供するために使用する
- 認可情報のみが含まれている
- ID 情報は含まれていない
- 通常デフォルトで1時間(3,600秒)の有効期限
- 期限が切れると,新しい Token を取得する必要あり
{
"azp": "32553540559.apps.googleusercontent.com",
"aud": "32553540559.apps.googleusercontent.com",
"sub": "111260650121245072906",
"scope": "openid https://www.googleapis.com/auth/userinfo.email https://www.googleapis.com/auth/cloud-platform https://www.googleapis.com/auth/accounts.reauth",
"exp": "1650056632",
"expires_in": "3488",
"email": "user@example.com",
"email_verified": "true"
}
6.1.3. ID Token
Unlike access tokens, which are opaque objects that cannot be inspected by the application, ID tokens are meant to be inspected and used by the application. Information from the token, such as Who signed the token or the identity for whom the ID token was issued, is available for use by the application.
以下 ID Token の特徴とフォーマットです.
- ユーザー認証情報ではなく,Service Account[7:1] から提供される認証情報を使用する
- 通常デフォルトで1時間(3,600秒)の有効期限
- 期限が切れると,新しい Token を取得する必要あり
{
"iss": "https://accounts.google.com",
"azp": "32555350559.apps.googleusercontent.com",
"aud": "32555350559.apps.googleusercontent.com",
"sub": "111260650121185072906",
"hd": "google.com",
"email": "user@example.com",
"email_verified": "true",
"at_hash": "_LLKKivfvfme9eoQ3WcMIg",
"iat": "1650053185",
"exp": "1650056785",
"alg": "RS256",
"kid": "f1338ca26835863f671403941738a7b49e740fc0",
"typ": "JWT"
}
6.2. Dataflow の パラメータに関する情報の記載が無い
Dataflow を作成する Google API に POST[4:2] するにあたって,body を正確に書く必要がありますが,ドキュメントに記載が無く発掘にとても苦労したので本記事でまとめます.
6.2.1. Batch Template のドキュメント
ドキュメントには,以下の 2 つの必要な情報が抜けており,リソースを適切に作成することができませんでした.
- Service Account[7:2]
- tempLocation
{
"jobName": "JOB_NAME",
"parameters": {
"instanceId": "INSTANCE_ID",
"databaseId": "DATABASE_ID",
"inputDir": "gs://GCS_DIRECTORY"
},
"environment": {
"machineType": "n1-standard-2"
}
}
6.2.2. REST API のドキュメント
REST API のドキュメントに詳細が書かれており,Service Account[7:3], tempLocation については environmentフィールドに記載することができるので,記載するようにしましょう.
以下が Request に含めることができるフィールド一覧です.
{
"environment": {
"additionalExperiments": [],
"additionalUserLabels": {},
"bypassTempDirValidation": false,
"diskSizeGb": 0,
"enableStreamingEngine": false,
"ipConfiguration": "",
"kmsKeyName": "",
"machineType": "",
"maxWorkers": 0,
"network": "",
"numWorkers": 0,
"serviceAccountEmail": "",
"streamingMode": "",
"subnetwork": "",
"tempLocation": "",
"workerRegion": "",
"workerZone": "",
"zone": ""
},
"gcsPath": "",
"jobName": "",
"location": "",
"parameters": {}
}
7. まとめ
本記事では,Cloud Storage にspanner-export.jsonが格納されたことをトリガーにして Dataflow を作成する方法について解説しました.
認証が通らなかったり,POST[4:3] する body の情報が見つけられない人の助けになれば幸いです.
最後になりますが,弊社では MLOps エンジニアを募集しているのでご応募お待ちしています!
-
グローバルに分散され,強整合性を備えたデータベースサービスです.リレーショナルデータベースの構造と非リレーショナルデータベースの水平スケーラビリティを兼ね備え,クラウドに特化した設計となっています.スケーラビリティをトランザクション,SQL クエリ,リレーショナル構造と組み合わせている点でユニークな DB です. ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎ ↩︎
-
Infrastructure as Code(IaC)と呼ばれるツールの一種でインフラの構成をソースコードとして管理できる ↩︎ ↩︎ ↩︎
-
バケットは,データを格納する基本的なコンテナです.Cloud Storage 内に保存するデータはすべてバケットに格納する必要があります.バケットは,データの整理やアクセス制御に使用できますが,ディレクトリやフォルダと異なり,入れ子構造にすることはできません. ↩︎ ↩︎
-
コマンドラインから HTTP リクエストを送信するためのオープンソースのツール ↩︎
-
Service Account は,ユーザーではなく,アプリケーションやコンピューティングワークロードで通常使用される特別なアカウントです.Service Account は,アカウント固有のメールアドレスで識別されます.アプリケーションは Service Account を使用して,認可された API 呼び出しを行います. ↩︎ ↩︎ ↩︎ ↩︎
-
電子署名により改ざん検知できる Json Web Token のことで,HTTP Header に付与する. ↩︎

Discussion