はじめに
DeNAの@634kamiです。
LEAP - Atmospheric Physics using AI (ClimSim)というコンペティションが 2024/7/16 まで開催されており、こちらに参加して最終4位でした。
コンペが終了してしばらく立ちましたが、リーク騒動などがあり解法共有が許可されるまで2週間程度かかるなど解法を詳細に確認するタイミングを失っていました。先日ちょうど主催したDeNAでの振り返り会も終わったので、自身の備忘録も兼ねて上位解法をまとめておきたいと思います。
コンペ概要
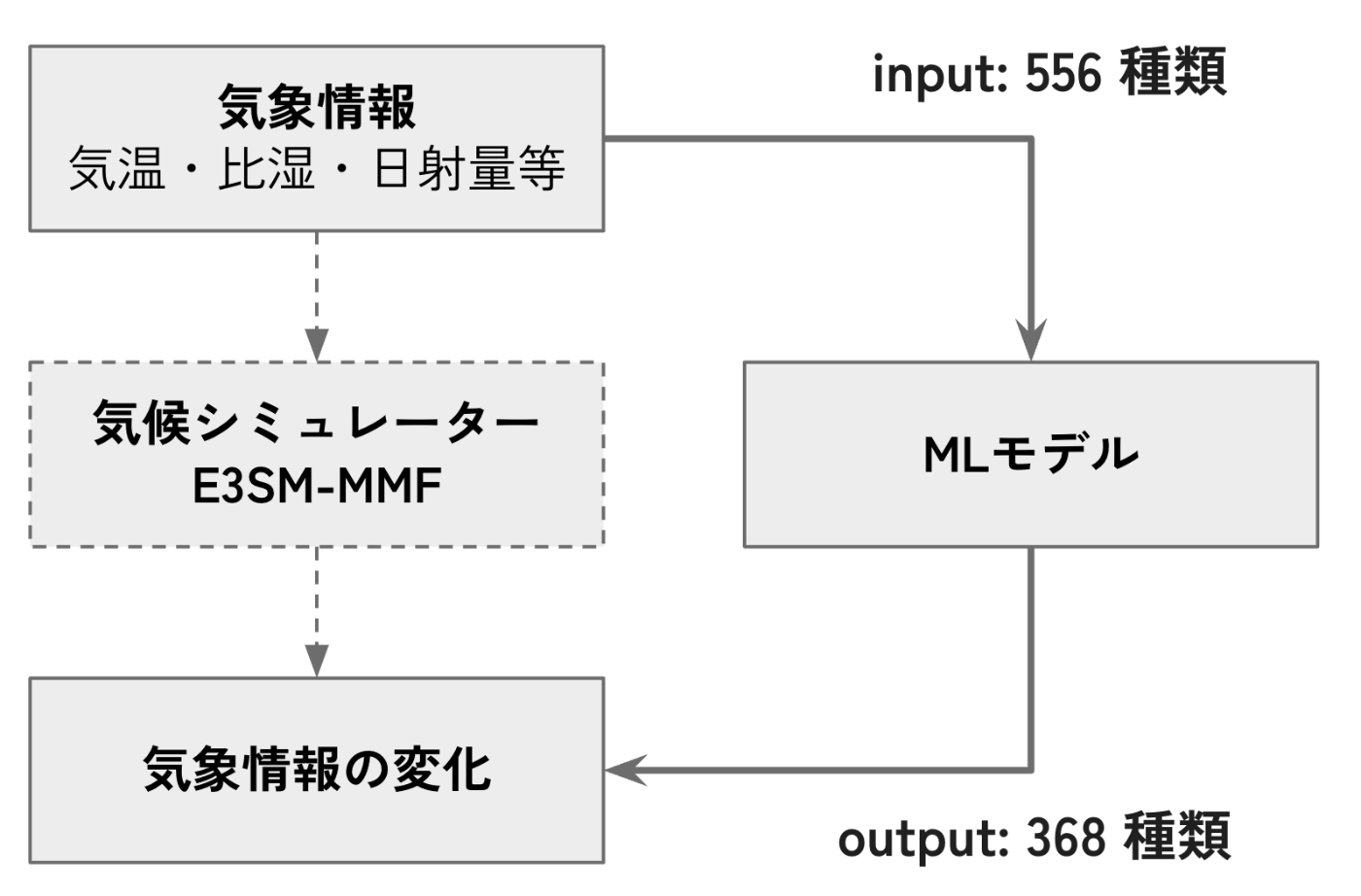
- 計算コストが高い気候シミュレータ(E3SM-MMF)をエミュレートするMLモデルを作成するコンペでした。
データについて
- 時間ごとに 384 地域ずつデータが与えられました。
- 1 地域ごとに 556 種類 の input が与えられ、368 種類の予測を行うことになります。

Kaggle外の提供データ
Kaggleで提供されているデータは別に、hugging face 上で追加データが与えられていました。
- Low-Resolution Real Geography (744 GB)
- Kaggleで提供されている Train データはここから抽出
- 元データは20分間隔、Kaggleデータは140分間隔のデータ
- Testデータはこれと同じ設定でさらに未来のデータから作成
- Low-Resolution Aquaplanet (744 GB)
- 土地が無い (海しか存在しない) 設定でシミュレーション
- High-Resolution Real Geography (41.2 TB)
- 上記2つよりも地域の分割が細かい(384地域 → 21600地域)設定でシミュレーション
評価指標
- 決定係数
R^2 - 368種類の各ターゲットに対して R2 を計算しその平均値で評価されます。
- 一部は重み0 (計算対象外) のターゲットもありました。
- 出力を少し間違えるとスコアがマイナスになってしまうこともあり、SNSで盛り上がっていました。
※
基本的な解法
- 特徴量の空間的な特性を加味したモデリングをするのが重要でした。
- 556種類の特徴量の中には、鉛直方向に60個ずつ区切られた意味を持つ特徴量が 9x60 種類存在しました。

空間的な構造の参考図, 引用元:[Gettelman, A., & Rood, R. B. 2016]
- 明示的にニューラルネットワークで扱えるように reshape してモデルに入力するのが重要でした。

モデリングの例
リーク騒動について
コンテスト期間中にリークに関する騒動があったのでそちらについての簡単な概要をまとめておきます。
ホストの意図する解法
最初に前提知識として、ホストがどのような解法を望んでいたのかを説明しておきます。
ホストの都合から、複数の地域を同時に入力に利用するような解法は望ましくないと言及されていました。

経緯の流れ
- コンペ開始直後
- ホストから、テストデータは位置と時間情報が分からないようにシャッフルしていると説明
- 最終的な終了日の1ヶ月前(当初予定していたコンペ終了 2~3 週間前)
- テストデータがシャッフルされておらず、並び順から位置と時間情報が復元できると報告
- テストデータの差し替え&2週間の延長になる
- 最終的な終了日の 1 週間前
- 月・日・位置ごとに固有の値をもつ特徴量が存在することが報告。1年間のデータを見ればテストデータの情報が分かることに
- prize 圏内はソリューションチェックを行い、リーク利用をしていた場合にdisqualifyされることに決定
上位チーム解法まとめ
上位チームの解法まとめになります。それ以外の解法も大変参考になるのでぜひディスカッションを確認してみてください。
データ
- 全てのチームが hugging face 上で与えられた外部データの Low-Resolution をメインに利用していました。
- 1位の方は Low-Resolution と High-Resolution データを 2:1 で利用していたようです。
- 5位のチームは Low-Resolution Aquaplanet のデータや、High-Resolution データをミックスさせて学習したモデルを利用していました。
前処理
- soft cliping (1st[1])
- input には時々外れ値のような非常に大きい値が出現するので、クリッピングするチームが多かったのですが、一定閾値を超えた値を同じ値に丸め込むのではなく、ルートを取ったり対数変換するなどして soft にまるめています。
- これにより情報量が失われること無く clipping することが可能になります。
- Multiple data representation
- inputについても複数の表現方法を同時に入力するチームが多かったです。
- 例えばinput を正規化する方法についても、以下のように複数の方法が考えられます。
- 特徴量それぞれについて平均値と標準偏差それぞれを用いて正規化する方法
- 特徴量の種類ごとに共通化した正規化方法(例えば高さごとに正規化方法を変えないなど)
- 1位の方はASLFRの 1st place solutionから着想を得たそうです。
- 特徴量エンジニアリング
- いくつかのチームは特徴量エンジニアリングをしてモデルに入力していました。
- climate-invariant features (Climate-Invariant Machine Learning)
- 風の強さ
- 水分量
- 飽和水蒸気(saturation vapor pressure)
- 前後の高さの特徴量との1次微分(diff)や2次微分(diff-diff)
- いくつかのチームは特徴量エンジニアリングをしてモデルに入力していました。
モデル
- モデルに関しては (batch, 60, num_feats) の形式の入力を受け取れるようなアーキテクチャであれば様々なものが利用されていました。
- 例えば以下のアーキテクチャをベースにした(もしくは組み合わせた)ものが利用されていました。
- Squeezeformer(1st[1:1], 7th[2])
- Transformer (2nd[3], 3rd[4], 4th[5], 7th[2:1], 8th[6], 10th[7])
- 1d CNN (2nd[3:1], 3rd[4:1], 4th[5:1], 7th[2:2], 8th[6:1], 10th[7:1])
- 1d UNet (3rd[4:2], 4th[5:2], 10th[7:2])
- LSTM,GRU (2nd[3:2], 3rd[4:3], 4th[5:3], 5th[8], 7th[2:3], 8th[6:2], 10th[7:3])
- Mamba (2nd[3:3])
学習方法
- 損失関数
- MAE (1st[1:2]), smoothl1 (2nd[3:4], 4th[5:4], 8th[6:3]), HuberLoss(3rd[4:4],10th[7:4]) もしくはそれらの組み合わせ(5th[8:1], 7th[2:4])を利用しているチームが多かったです
- 評価指標を最適化するために 公開ノートブックでは MSE を利用していることが多かったです。
- 外れ値となるような大きな値を持つサンプルがいくつかあったためその影響を軽減する目的や、回帰タスクで損失を色々変更してみるのはよくあるということから導入したチームが多かったのではと思います
- 7位チームは MAEで学習後、MSEで fine tuning しており、これにより 0.002 のブーストがあった模様です。
- MAE (1st[1:2]), smoothl1 (2nd[3:4], 4th[5:4], 8th[6:3]), HuberLoss(3rd[4:4],10th[7:4]) もしくはそれらの組み合わせ(5th[8:1], 7th[2:4])を利用しているチームが多かったです
- Confidence-aware MSE loss (10th[7:5])
- ハードサンプルによる大きな誤差の寄与を緩める効果を期待して、pred と var の2つを予測して以下のように損失を計算しています。
loss = 0.5 * (target - pred) ** 2 / var + 0.5 * torch.log(var) - Google Brain - Ventilator Pressure Prediction の9位解法から着想を得たそうです
- ハードサンプルによる大きな誤差の寄与を緩める効果を期待して、pred と var の2つを予測して以下のように損失を計算しています。
- Auxiliary Loss
- Confidence Loss (1st[1:3])
- 各ターゲットの損失そのものを予測します。簡単に実装できる割に効果的だったそうです。
- Ribonanza の 3rd place solution を参考に導入したようです。
- Auxiliary diff loss (2nd[3:5], 3rd[4:5])
- ターゲット、予測値それぞれの高さ方向の差分についても損失を計算しています。
- Confidence Loss (1st[1:3])
- Group fine-tuning (2nd[3:6])
- 368個のターゲットがありますが、高さ60個それぞれについて値を持つ特徴量が6種類 + その他の特徴量8種類に分類されます。グループごとに最後に1エポック分 fine-tuning することで 0.0005 ~ 0.0015 ほどの性能向上が見られたということでした。
後処理
- 公開ノートブックを含めて、ほとんどのチームが予測が難しいターゲットの処理を何かしら行っていました。0埋めする、y[t] = -x[t]/1200 で埋める (詳細) などがあります。
アンサンブル
- CSV提出型のコンペティションというのもあってアンサンブルがしやすく、ほとんどのチームが複数のモデルの予測結果を用いてアンサンブルを行っていました。
- 加重平均のチームもありましたが、スタッキングを用いたチームもありました。(4th[5:5])
まとめ
大きなデータを用いたニューラルネットワークの学習ができる面白いコンペティションでした。数日かけて学習する解法が多くあったと思います。
SNS上で人によって効いたこと効かなかったことが異なったりする話などもよく耳にしたので、手持ちのアイデアを試しつつ、特定手法をしっかりとチューニングしきることが重要だったのではないかと思います。
資料
-
Kaggle LEAP Competition Solution解説&振り返り
- 3位に入賞されたpaoさんによるコンペのSolution解説及び振り返り資料です。

Discussion