クリーンアーキテクチャについて
はじめに
はじめまして。現在大学4年生の とうふ です。
これまでバイトやインターンで Web アプリケーション開発に携わる中で、次第に「設計の大切さ」を強く感じるようになりました。
2社のインターンを継続しており、現在まで開発経験を積んできましたが、どちらの現場でもクリーンアーキテクチャが採用されており、自然とその設計手法に触れる機会がありました。
最近、同期のエンジニアから「クリーンアーキテクチャって、ざっくり言うとどんな設計なの?」と聞かれる場面がありました。
そのとき、設計に馴染みのない人にもわかりやすく説明することが意外と難しく、自分の理解を整理し直したいと感じたのが、この記事を書こうと思ったきっかけです。
クリーンアーキテクチャを初めて学ぶ方や、うまく説明できずにもどかしさを感じた方の参考になれば嬉しいです。
そもそもクリーンアーキテクチャとは?
クリーンアーキテクチャとは、アプリケーションの中核となるビジネスロジック(ユースケースやエンティティ)を、フレームワークやデータベースといった外部の技術要素から切り離すことで、システム全体を変更や拡張に強くすることを目的とした設計アーキテクチャです。
この考え方は、「関心事の分離(Separation of Concerns)」という設計原則に基づいています。
アプリケーションの中核となる処理(ビジネスロジック)が、Web フレームワークやデータベースなどの技術的な要素に直接依存しないようにする
というのが、クリーンアーキテクチャの基本的な思想です。
特に重要なのが、「依存関係の方向は内側(ビジネスロジック)に向かうように制限されている」という点です。
つまり、外側の層(Web フレームワーク、DB、UI など)は内側に依存できますが、内側の層は外側に依存してはいけないというルールがあります。
この構造によって、たとえば次のような変更があっても、ビジネスロジックにはほとんど影響がありません:
- Web フレームワークのバージョンやライブラリの変更
- フロントエンドとの通信方式の変更(REST → gRPC など)
- データベースの種類やクエリ方法の変更
また、各層の責務が明確になることで、それぞれの層でやるべきことに集中でき、他の部分をあまり意識せずに実装を進めやすくなるのも、クリーンアーキテクチャの大きな利点です。
このように、「システムの本質的なロジックを守りつつ、変化に柔軟な構造を作る」ことが、クリーンアーキテクチャのもっとも重要な目的だと私は理解しています。
クリーンアーキテクチャの図解と各層の意味
以下はクリーンアーキテクチャの代表的な図です。中心にあるビジネスロジックを、外側の技術的な要素から守る構造になっています。
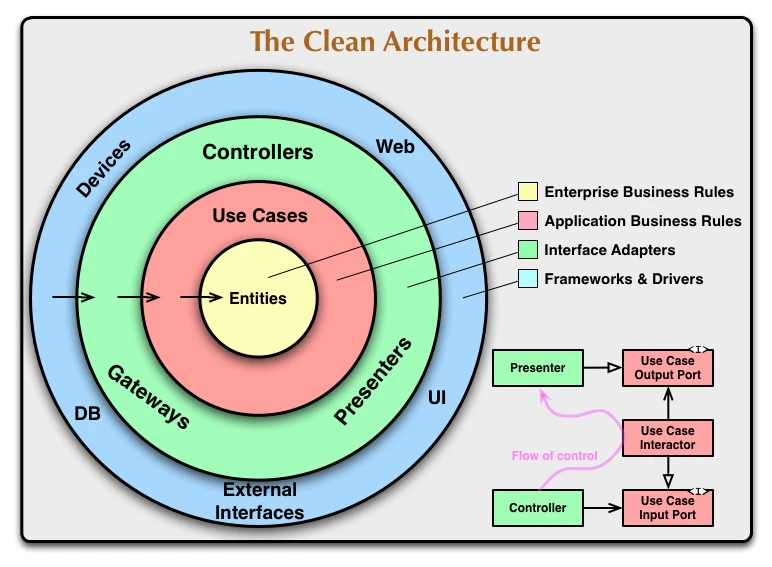
🟡 Entities(エンティティ)
Enterprise Business Rules
アプリケーションの最も本質的な部分で、ビジネス上のルールやオブジェクトを表します。フレームワークやデータベースに一切依存しないものです。
🔴 Use Cases(ユースケース)
Application Business Rules
ユーザーの操作やアプリケーションの振る舞いを定義します。
エンティティを使って具体的な処理を行う場所です。
🟢 Interface Adapters(インターフェースアダプタ)
Controllers / Presenters / Gateways
ユースケースやエンティティと、外部との橋渡しをする層です。
コントローラーやプレゼンター、リポジトリの実装などがここに該当します。
🔵 Frameworks & Drivers(フレームワークとドライバ)
Web / DB / UI / Devices
最も外側の層で、フレームワーク(Express, Djangoなど)やデータベース、外部ライブラリがここに該当します。 また、最も変更が多くなる層でもあります。
依存関係は常に内側に向かうように設計されており、内側の層は外側の層に依存しないのが原則です。
このように、各層は役割を明確に分け、依存方向を内側に限定することで、変更に強く・テストしやすい設計を実現しています。
クリーンアーキテクチャは“型”ではなく“考え方”
クリーンアーキテクチャの図や説明を見ていると、
「この構成を再現しないといけないの?」「この層を必ず分けなきゃいけないの?」と思ってしまうことがあるかもしれません。
でも実際は、クリーンアーキテクチャは「守るべき構造」ではなく、「守りたい考え方」です。
- レイヤーをどう分けるか
- どこまで抽象にするか
- 責務をどう持たせるか
といった設計の細部は、プロジェクトの規模やチームの方針に応じて柔軟に決めるべきものです。
大事なのは、
「ビジネスロジックを技術的な依存から守る」という考え方を、自分たちに合った形で実現することだと私は思っています。
実際、私が関わった案件でも、DI(依存性注入)をどこまで厳密に適用するかは明確に決まっていたわけではなく、プロジェクトの規模や開発方針によって異なっていました。
大切なのは、「この構造でなければいけない」と形式的に考えることではなく、チーム全体が理解しやすく、保守しやすい形で依存関係を適切にコントロールすることだと感じています。
レイヤー同士の関係をイメージしてみる
ここで、ある具体的なデータ構造(例:イベント情報)を使って、各レイヤーがどう役割を分担しているかを簡単に説明します。
たとえば、アプリケーションの中で使われる Event というオブジェクトがあるとします。
// Entity層の一部(Zodを使った例)
export const Event = z.object({
id: z.string(),
name: z.string(),
description: z.string(),
startDate: z.date(),
endDate: z.date(),
location: z.string(),
createdAt: z.date(),
updatedAt: z.date(),
});
Entity はビジネスロジックの一部であり、アプリケーション(今回であればイベントのCRUD)における中心的なルールや性質を表す層です。
ドメインの本質を担っているため、外部技術の変更に左右されにくく、変更が最も起きにくい場所とも言えます。
次に、useCaseではentityのEventを操作する擬似のコードを書きます。以下のようになります。
export class EventUseCase {
constructor(private readonly repository: IEventRepository) {}
async create(input: CreateEventInput): Promise<void> {
const now = new Date();
// Entityを生成(制約などは今回は省略)
const event = new Event(
crypto.randomUUID(),
input.name,
input.description,
input.startDate,
input.endDate,
input.location,
now,
now
);
// 結果をOutputPortに渡す(UseCaseは出力方法を知らない)
this.repository.create(event);
}
}
ここで注目してほしいのは、UseCaseでは「何をするか」を淡々と記述しているという点です。
この例では、イベントの生成 → 出力 という最小限の処理だけを行っており、名前や日付のバリデーションなどの制約はあえて省略しています。
もし、たとえば「開始日が終了日よりも後になってはいけない」といった制約がある場合は、
そのビジネスルールを Entity(または別のドメイン層のコンポーネント)に持たせて、UseCase側からその処理を呼び出す構成にすればOKです。
つまり、UseCaseはあくまで“アプリケーションの振る舞い”を組み立てる場所であり、具体的なルールや処理の詳細はドメイン層に委ねるというのが基本的な考え方です。
また、IRepository に依存しており、データベースの処理を UseCase は一切知らないという点も、注目すべきポイントです。
たとえば、イベントを保存したりログに記録したりするような処理は、UseCaseの中には書かれていません。
その代わり、UseCaseは出力処理を行うインターフェースだけを知っており、具体的にどう出力されるか(保存されるのか、ログに出るのか)を一切意識していません。
参考に、インターフェースのサンプルコードは以下のような感じになります。
// interface/output-port.ts
import { Event } from "../entity/event";
// 出力の形式や振る舞いを定義するOutputPort層
export interface IEventRepository {
create(event: Event): void;
}
このように、UseCaseはあくまでアプリケーションの流れ(振る舞い)を記述するだけであり、
データベースやUIといった外部の詳細な実装には依存しない構造になっています。
この構造を守ることで、出力方法が変わっても(たとえば、データベースを変更したり、ORMをPrismaから別のものに変えたりしても)、UseCaseのロジックは一切変更せずに再利用できるという利点があります。
データベースへの保存などの処理は、通常 Repository を通じて行いますが、今回の記事では構造の理解を優先するため、その部分は省略しています。
クリーンアーキテクチャにおいて重要なのは、UseCaseが Repositoryというインターフェースを通して依存する 構造であり、実際の保存処理はUseCaseの外側(インフラ層)に任せる という点です。
なお、IEventRepository の各メソッドの中身を実装すれば、実際にデータベースとやり取りできるようになります(たとえば、PrismaやSequelizeを使った保存処理など)。
クリーンアーキテクチャのメリットと注意点
ここまでの内容を踏まえて、実際にクリーンアーキテクチャを採用することで得られるメリットと、注意すべき点を簡単にまとめておきます。
✅ メリット
-
ビジネスロジックを守れる
→ UIやDBの変更に強く、ロジックの再利用性が高い -
責務が分離されているため、保守性・テスト性が高い
→ 各層をモック化して単体テストがしやすい
⚠️ 注意点(デメリット)
-
構造が複雑になりがち
→ 小規模な開発では「レイヤー分けすぎて逆にわかりにくい」ことも -
初心者にとって導入ハードルが高い
→ DIやinterfaceの設計に慣れていないと混乱することもある -
設計に正解があるわけではない
→ 適切にカスタマイズしないと「過剰設計」になりやすい
👀 実体験を交えて補足
私自身、最初はクリーンアーキテクチャで実装した際、「わざわざここまで分ける必要ある?」と感じることも正直ありました。
しかし、開発が進み機能が増えていく中で、「ここがUseCase」「ここがEntity」と役割が分かれていて何をするべきかが明確になり、開発がしやすいと感じました。
特に、既存の機能に手を加えるときや、別の人が書いたコードを読むときに、「これはどの層の責務なのか」が構造として見えていることで、迷いが少なく、安心して変更できるようになりました。
今では、「どういう責務のコードを書いているのか」を自然と意識できるようになり、設計がブレにくくなる感覚を実感しています。
まとめ
ここまで読んでいただき、ありがとうございました。
この記事は、私にとって初めて書いた技術記事です。
正直、「うまく伝えられるかな?」と不安もありましたが、クリーンアーキテクチャについて自分の言葉で整理し直す、とても良い機会になりました。
ここでは、クリーンアーキテクチャの基本的な考え方から、実際のコード構成例、そして私自身が感じたメリットまでを紹介しました。
「クリーンアーキテクチャ」と聞くと、少し堅苦しくて難しそうな印象を持たれるかもしれませんが、
その本質は「アプリケーションの中核となるロジックを守るために、責務ごとにコードを整理する」という、実はとてもシンプルな考え方です。
最初は取っつきにくくても、実際に使ってみると、設計の指針としてとても心強いものになると思います。
私自身、まだまだ学びの途中ですが、この記事が「クリーンアーキテクチャってなんだろう?」と思っている方の最初の一歩になれたら嬉しいです。
Discussion