こんにちは。
AIに仕事を奪われたフロントエンドエンジニアです。
2025年3月から、事業で達成したい目的のために、本格的にAIの勉強やエンジニアリングを始めまして、AI開発界隈の巨人の肩を感じながら昼夜過ごしておりました。
システムにAIを組み込み使うために、先行開発者たちが築いてきたライブラリは非常に助けになります。
我々は、技術選定で「LangChain」と、それをベースとした派生モジュールである「LangGraph」、「LangSmith」を採用しました。
そして実際に動かしてみたりして、感じたメリット等をここにまとめてみました。
こんな感じで動くものがLang〇〇だと作れました。
LangChain、LangGraph、LangSmithについて
これらは、一言で言えば、「AIを使ったアプリケーションを開発するのに便利なライブラリが集まっているものたち」です。
AIに直接的に関係のあるもの、関節的に関係があるもの、よくみると別に関係ないが、あると嬉しいものが提供されています。
これら3つについてそれぞれ説明し、最後にすべてを丸っと使うと、どう言うアウトプットがあり、どういう良いところがあるのかについて、お見せします。
技術選定でLang〇〇を選んだ理由について
結論からいうと、「決め打ち」要素が大きいです。事業にAIを親和させこれまで出来なかった方面を成長させたいという目的だけが先行していたのもあります。
現時点では、いろいろなメリットが後付けで見つかったため、採用を続行している。というステータスで相違ないです。Lang〇〇を採用して致命的に困っている要素も見当たっていない・ということも付記します。
個人的な感想に留まりますが、AI、またはそれを使ったアプリケーションを速やかに構築すること目指したいのであれば、それだけで採用に値すると思います。
LangChain
LangChainは、OSSであり、フレームワークであり、会社名です。
かなり、ややこしいです。
会社のほうは、正確な所在地が不明だったりして、会社内で取引先を登記する際に苦労したものです。
一旦、LangChainが何がいいのか、公式の情報を引用します。
LangChain は次の用途に使用できます:
リアルタイムのデータ拡張。LangChain のモデルプロバイダー、ツール、ベクターストア、リトリーバーなどとの統合に関する膨大なライブラリを活用して、LLM をさまざまなデータソースや外部/内部システムに簡単に接続します。
モデルの相互運用性。エンジニアリング チームがアプリケーションのニーズに最適な選択肢を見つけるために実験する際に、モデルを入れ替えます。業界の最先端が進化しても、すばやく適応できます。LangChain の抽象化により、勢いを失うことなく前進し続けることができます。
「AWS語っぽさ」がすごいんですが、要約すると、
-
前者は、さっき説明した「AIに直接的に関係のあるもの、関節的に関係があるもの、よくみると別に関係ないがあると嬉しいものが入ってます。」の部分に相当します。さまざまなクラスが内包されていて、本質の開発に集中できるようなライブラリデザインになっています。
-
後者は、日々進化するAI関連の変更に、「LangChainとして僕たちは、頑張ってメンテして、追従していきます」って意思表明に見えます。
という感じかと思います。
AI関連のサービス、そしてそれにぶら下がるSDK・ライブラリなどは本当に変化が早いし破壊的な変更もたまにあるみたいなので、LangChainがそれらを吸収してくれるのはありがたいです。
結論、AI、またはそれを使ったアプリケーションを速やかに構築することを目指した巨大なライブラリであり、エコシステムであり、会社である。それがLangChainという理解でいいと思います。
LangGraph
LangGraphは、LangChainの一部です。
先ず、LangChainが「速やかに作れる」のはそうなんですが、ある程度モノを細かく作り出すと以下のような症状が起こります。
- LangChainが提供するモジュールが、あまりにも色々な処理を包含してるので、内部状態がよくわからない...
- LangChainが、非同期、再帰、状態遷移などが絡むとコードが複雑になる。特にlangChainはステートレスを掲げているのでそれが不都合だと困る...
- LangChainはGUIを提供しないので、作ったプロダクトの見栄えが地味で共有しづらい...
- そもそもLangChainを、REST-API的に動かしたいんだけど....
- そもそも作ったAgentは、クラウドに置きたいんだけど....
これらの問題をまるっと解決するのが、LangGraphです。
LangGraphは、分解するといくつかのモジュールに分解できます。LangGraphの名を冠したそれらが、LangChainで作ったソースコードを強力なアプリケーションに昇華してくれます。
- LangGraph Server:作ったAIアプリケーション=Agentを、サーバー的に動かすことをサポート。
- LangGraph CLI:langGraph Serverをlocal等で実行したり、dockerにまとめたりしてくれるツール
- LangGraph Studio:langGraphで作ったAgentの動きを「可視化」するシステム
- LangGraph Platform:これらすべてを包含した1パッケージを、ホスティングしてくれるもの。およびPaaS。Next.jsに対してのVercelが近い。
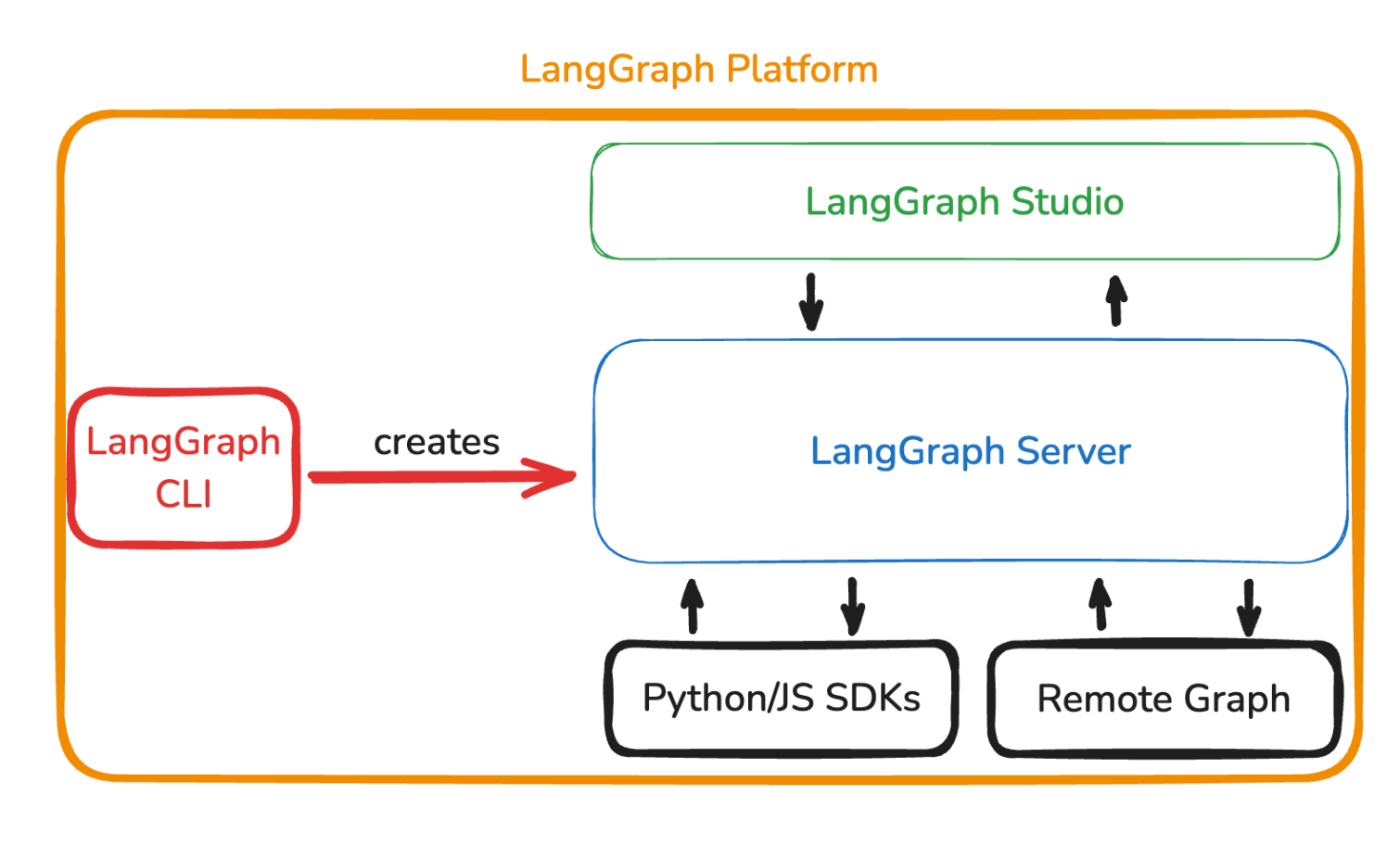 公式が提供している図で、langGraph 〇〇をよく説明している
公式が提供している図で、langGraph 〇〇をよく説明している
つまるところLangGraphは、LangChainで構築したAgentをより固く作るためのお作法を提供し、それによりPlatform上で定義されたホスティング・監視・可視化etc...を提供してくれるもの・という理解でOKです。
LangSmith
LangChain、LangGraphがライブラリであるのに対して、LangSmithは「PaaS、
SaaS」と見ていいです。
簡単な登録と設定を済ませれば、LangChain/Graphが実行したワークフローを、LangSmithで蓄積。専用のコンソールサイトでそれを閲覧、そして動作のログや、掛かったコストなど管理したりできます。
特に、AI開発というのは、開発中も本物のLLMにAPIでアクセスすることを必要とするので、油断してるとめちゃくちゃAPI使用料がかかります。
なので、かかったコストを綿密に記録してくれる人がいると嬉しくて、LangSmithはその役割を担っています。
ちなみに、先述のLangGraph Platformは、LangSmithのコンソールサイト内にデプロイの動線があります。のでLangSmithの一部と見た方が自然かもしれません。
LangSmithのメリットについては、実際の画面を見ると「なるほど」と感じると思うので、以降の内容を見てください!
3者の役割分担・技術選定のポイント
まとめると、LangChainは、「AI開発便利ツールの集まり」で、LangGraphはそこに「お作法」を与えシステムとして固くさせてくれるもの、そしてLangSmithが「ホスティング」と「管理」を司っている・という構造です。
この「1パッケージ感」がLang〇〇のメリットであると、強く思っています。
アウトプットしてみる
Lang〇〇でどういう開発体験が可能なのかについて、実際の様子とともに見てみましょう。
ここでは、聞かれた質問に対して、WikipediaかGoogle検索で得た情報をファクトにしつつ回答を行う。お手軽ファクトベース推論Agentを作っている様子をお見せします。
このAgentは、テキストを用いた推論こそAIを使うが、wikipediaやGoogle検索で実データを得る作業はAIの役割の外であり、別のものが賄う必要があります。
その手段として、Google検索に関するAPIを使ったり、wikipediaのAPIを使ったりという方法があります。
けどそもそも、それらAPIに対して、どういうクエリでデータを引っ張ってこればいいのかはAIに柔軟に判断してもらいながら行わせたいし、考え出すと色々不明瞭な部分があります。
しかし、「Function Calling」という推論モデル側(OpenAI側)の機能と、これの利用をシンプルにサポートするLangGraphを使えば、超スムーズにこれを実装することができます。
ソースコード
別途必要なインストールは、以下になります。
執筆時点でのおすすめのバージョンも併記しますが、必ずしもそうでなくなるかも。
(ヌケモレがあったら、ごめんなさい🙏)
"langchain-google-community (==2.0.7)",
"langchain-openai (==0.3.8)",
"langgraph (==0.3.11)",
"typing-extensions (==4.12.2)",
"wikipedia (==1.4.0)",
LangGraphのお作法に伴う、「おまじないファイル」が続きます。
from typing import Literal
from langgraph.graph import END, START, StateGraph
from typing_extensions import TypedDict
from src.sample.utils.nodes import (
call_model,
should_continue,
tool_node,
)
from src.sample.utils.state import AgentState
# 超おまじないです。
workflow = StateGraph(AgentState)
workflow.add_node("agent", call_model)
workflow.add_node("action", tool_node)
workflow.add_edge(START, "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "action",
"end": END,
},
)
workflow.add_edge("action", "agent")
# StateGraphをコンパイルしたものを変数として置いておきます。
graph = workflow.compile()
LangGraphでは、「Node」と呼ばれる処理単位があり、公式チュートリアルでも、こののサンプルでも、だいたい以下のように扱ってます。
from functools import lru_cache
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import ToolNode
from src.sample.utils.state import AgentState
from src.sample.utils.tools import tools
# OpenAIのクライアント呼び出す。
@lru_cache(maxsize=4)
def _get_model():
model = ChatOpenAI(temperature=0, model="gpt-4o").bind_tools(tools)
return model
# 今は何だこれと思っててOK。Function CallingというOpenAI APIの機能で使われます。
def should_continue(state: AgentState):
messages = state["messages"]
last_message = messages[-1]
if not last_message.tool_calls:
return "end"
else:
return "continue"
system_prompt = """Be a helpful assistant"""
# OpenAIのモデル呼び出して、prompt組んで、発行する関数
def call_model(state: AgentState, config: RunnableConfig):
messages = state["messages"]
messages = [{"role": "system", "content": system_prompt}] + list(messages)
model = _get_model()
response = model.invoke(messages)
return {"messages": [response]}
# 次の次の説明で登場
tool_node = ToolNode(tools)
LangGraphで取り扱うStateの型定義のファイルです。
これは、Agentに与える引数としての役割、そしてそれがそのままLangGraph内でのステートの骨子にもなります。
from typing import Annotated, Sequence, TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph import add_messages
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
「wikipediaのデータとってくる・Google検索でデータとってくる」の部分です。
なんとどちらも、LangChainが@toolとかいうお手軽拡張を提供してくれていて、簡単に定義できます。なんて親切。
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.tools import tool
from langchain_google_community import GoogleSearchAPIWrapper
search = GoogleSearchAPIWrapper()
wiki = WikipediaAPIWrapper()
# おまじない。
# これにより、Function callingに乗っ取ったFMTのデータにコンパイルされる。
@tool
def searchGoogle(query: str):
"""Use this to get information from Google Search. (Do not use this tool in parallel processing)"""
return search.results(query=query, num_results=10)
# おまじない。
# これにより、Function callingに乗っ取ったFMTのデータにコンパイルされる。
@tool
def searchWikipedia(query: str):
"""Use this to get information from Wikipedia."""
return wiki.run(query)
# おまじないで作ったtoolを配列で包んで変数としておいておくだけ。
# さきほどnode.pyとかで参照されてた。
tools = [searchGoogle, searchWikipedia]
最後に、LangGraphは、ディレクトリルートに以下のようなFMTのjsonがあれば、これを軸に勝手に構成を決めて起動させることができます。
LangGraphとその周辺システムにおいて、このファイルがすべての起点になるので超重要です。
{
"dependencies": ["."],
"python_version": "3.XX", # 3.12くらいがおすすめ。
"graphs": {
"sample": "./main.py:graph" # main.pyでつくったグラフ(変数)を指すようにする
},
"env": "./.env" # 環境変数ファイルの在処
}
いろいろなAPIを使うために準備する
LangChainがいろいろなAPIを内包してくれているが、環境変数の設定・SaaS側の設定が色々必要ではあるので、ざっくり紹介します。(逆に言えば、今後どんなツールが必要になるかがわかります。)
-
LangSmithに登録して、APIキーを発行。
https://smith.langchain.com/o/settings -
envに、Lang〇〇関連の4つ環境変数を設定する。
LANGSMITH_API_KEY={langSmithで発行したトークン}
LANGCHAIN_TRACING_V2=true
LANGSMITH_ENDPOINT=https://api.smith.langchain.com
LANGSMITH_PROJECT={好きな名前}
- OpenAIのAPIに登録し、OPENAIのAPIキーを発行する。
...
OPENAI_API_KEY={OpenAIのAPIキー}
-
Google Cloudで、「Custom Search API」を任意のAPIキーで使えるようにしておきます。
https://console.cloud.google.com/marketplace/product/google/customsearch.googleapis.com -
Programmable Search Engineに登録して、Custom Search Engineというものを作ります。
これは、Googleが提供しているツールで、「カスタムGoogle検索」なるものを作るためのものなのですが、シンプルにCSE_IDという変数が欲しいだけなので、特別な設定はせず、脳死で作ってOKです。このテストで作る目的でのみ利用するならば、忘れそうになる前に棚卸しましょう。
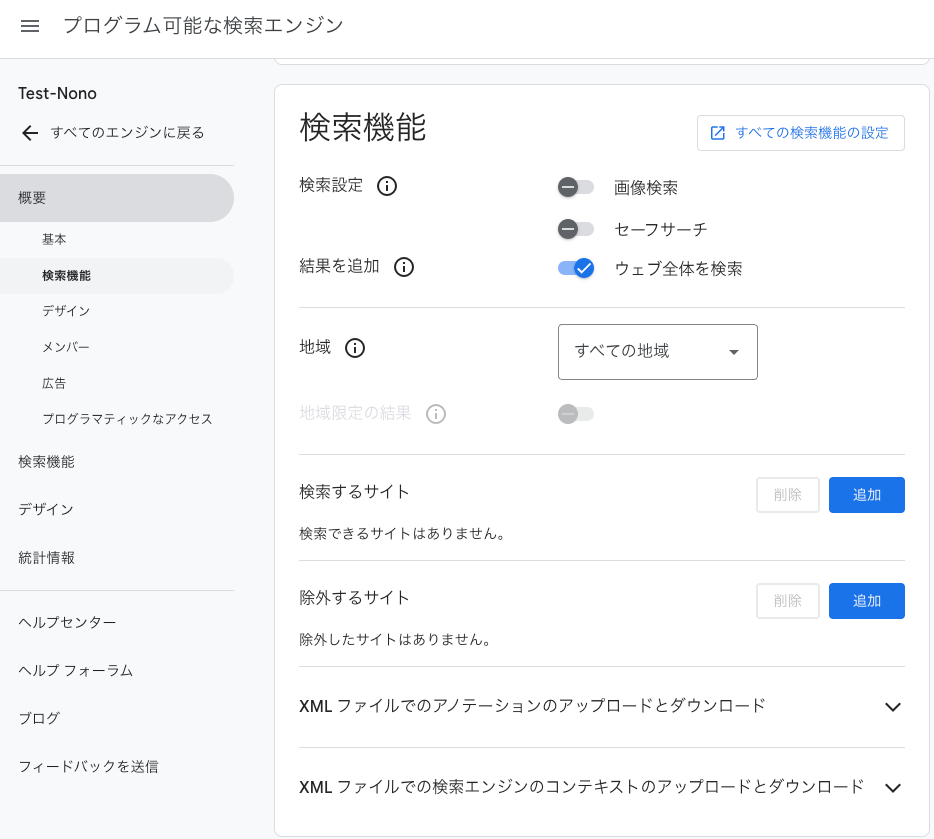
PSEの設定は、こんな感じで適当でOK
...
GOOGLE_API_KEY={Google Cloudの、Custom Search APIが認可されてるAPIキー}
GOOGLE_CSE_ID={「検索エンジンID」を入れる}
localで動かす
一番ダイナミックに動いて紹介に適しているので、LangGraphにデフォで内包されたシステムである「LangGraph Server」を起動して動作を見てみます。
コマンドlanggraph devにより、起動します。

お手軽な2単語でLangGraph Serverが起動。
LangGraph側の挙動で、勝手にブラウザが起動します。LangSmithのWebサイトに飛ばされます。
お金は掛からないのでログインしてみましょう。(2025年4月執筆時点)
すると以下のような画面が。
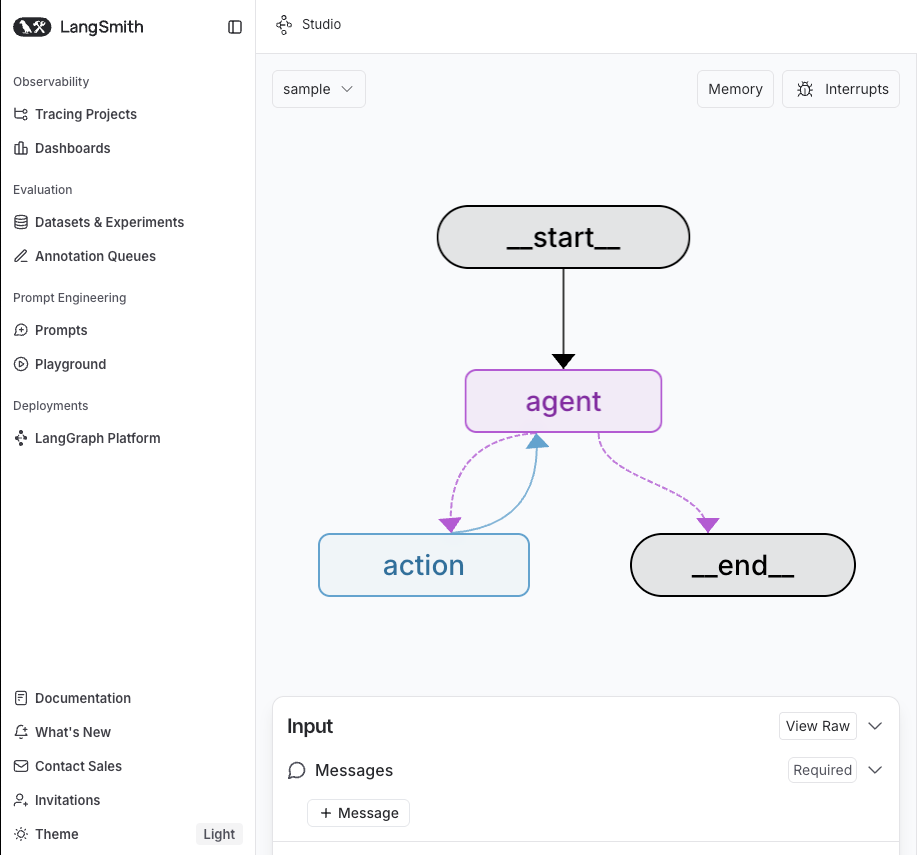
これが、LangGraph、およびLangGraph Studioが提供する「可視化」。ちょっと奇妙な感覚なのですが、localhostなWebアプリケーションがブラウザで表示されるのではなく、本番環境のLangSmithにアクセスし、それが、localのLangGraphのデータを参照して、可視化を提供してくれます。
作ったサンプルをこのGUIで動かしてみましょう。最近「JIN(仁)」をネトフリで見てて脳内が幕末モードなので、「西郷隆盛と坂本龍馬が協力して何をしたか調べて」と聞きます。
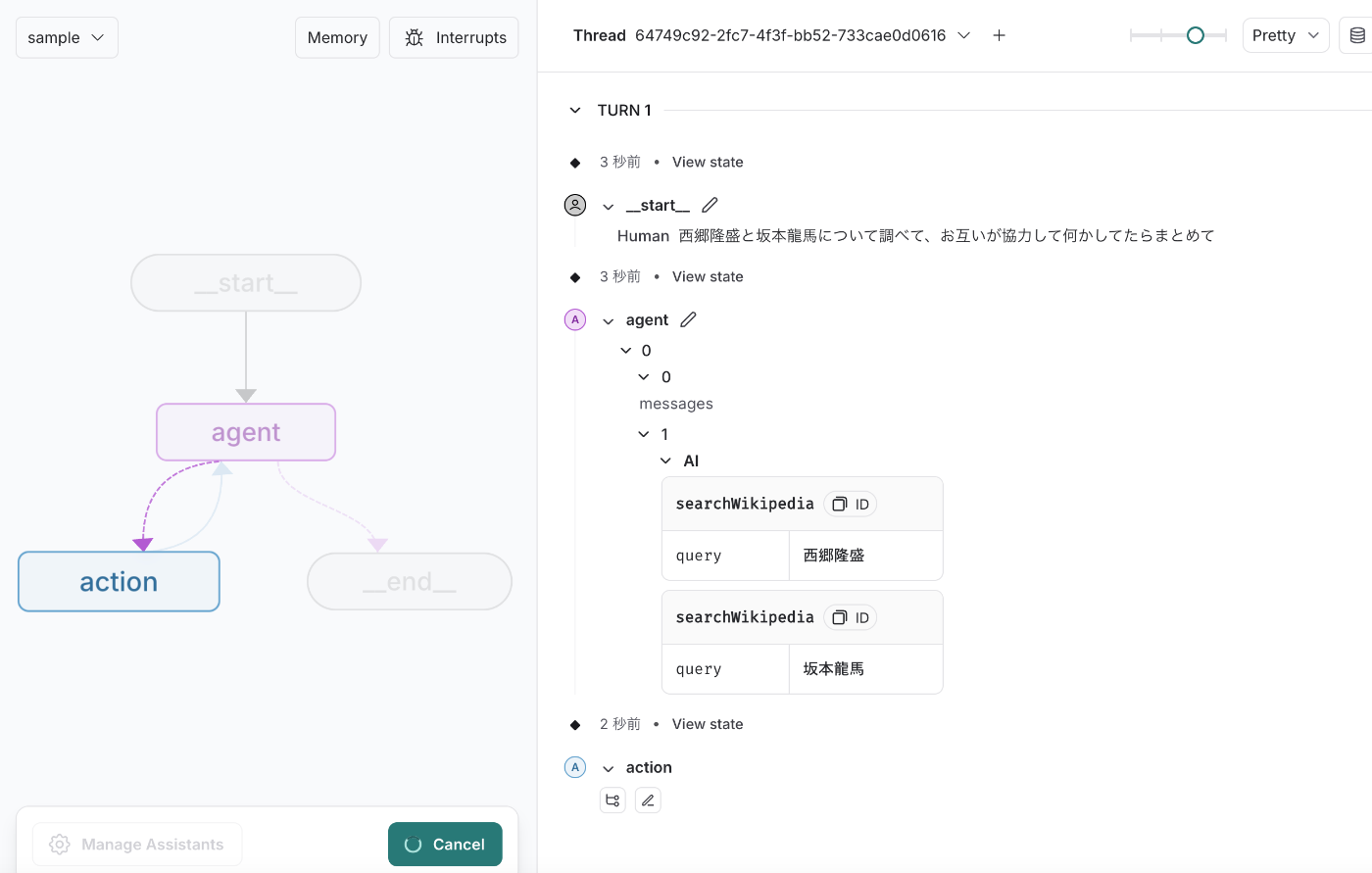
プロンプトから判断して、wikipediaで二人のことを調べる意思決定をAIがした。(すごい)
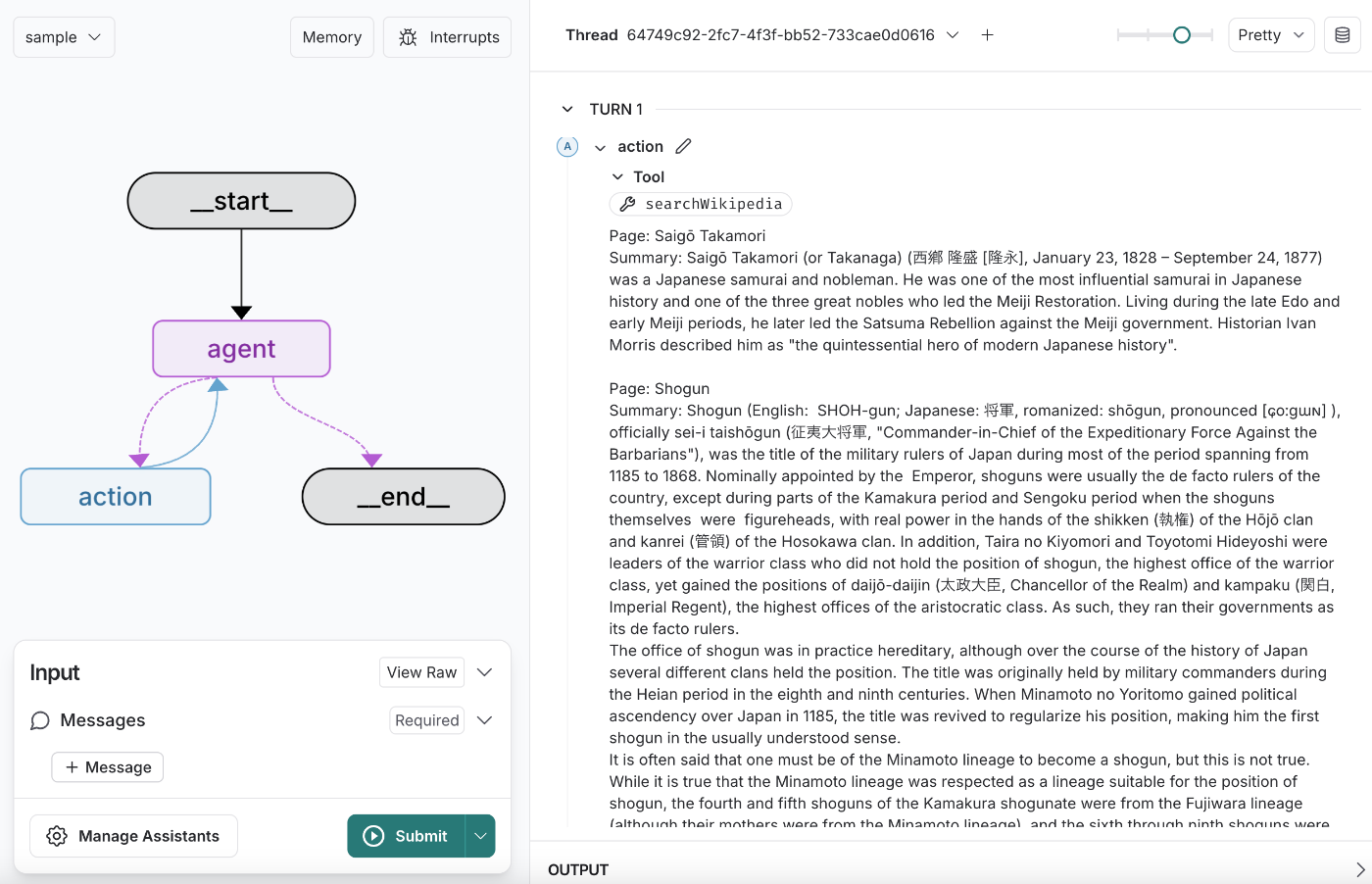
調べた結果をひとまずAIに読ませたいから、モデルに流し込んだみたいだ。(パワープレイ)

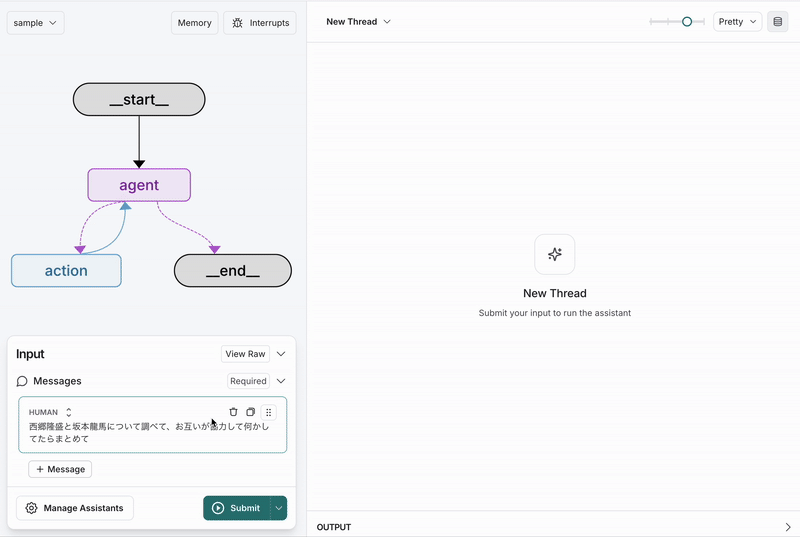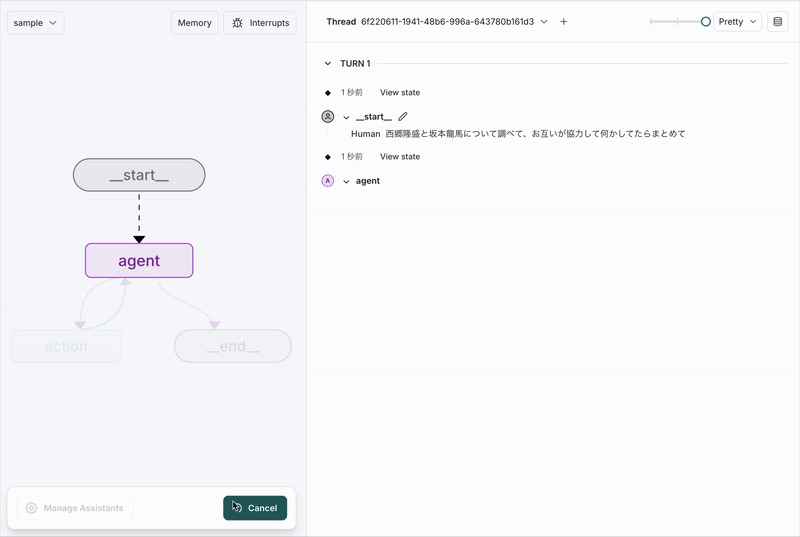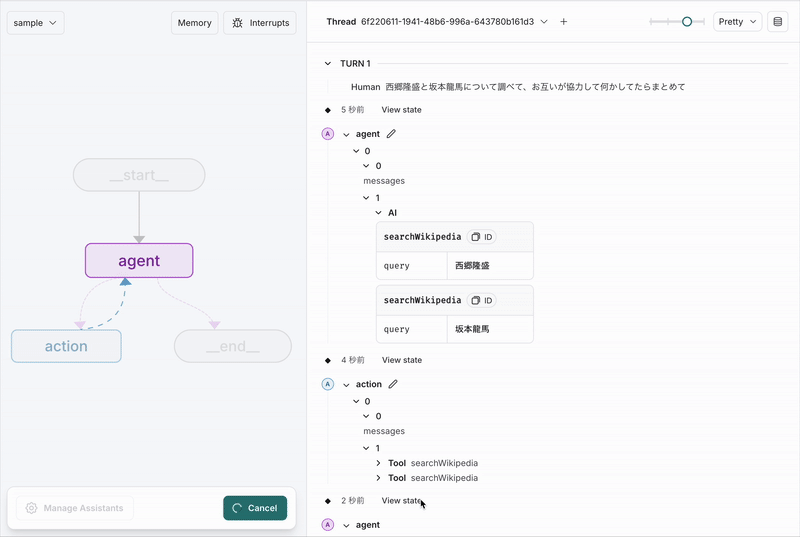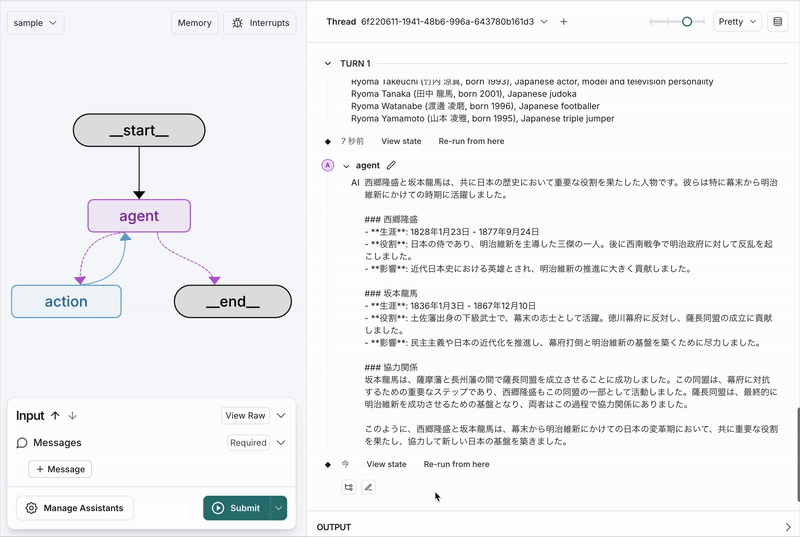
最終的にこんな感じにまとめたみたいだ。(かしこい)
西郷隆盛と坂本龍馬は、共に日本の歴史において重要な役割を果たした人物です。彼らは特に幕末から明治維新にかけての時期に活躍しました。
西郷隆盛について
生涯: 西郷隆盛(1828年1月23日 - 1877年9月24日)は、日本の侍であり、明治維新を主導した三傑の一人です。彼は薩摩藩出身で、後に明治政府に反旗を翻した西南戦争を指導しました。
役割: 明治維新の立役者として、徳川幕府を倒し、新しい政府の樹立に貢献しました。坂本龍馬について
生涯: 坂本龍馬(1836年1月3日 - 1867年12月10日)は、土佐藩出身の下級武士で、幕末の志士として活躍しました。彼は徳川幕府に反対し、開国と近代化を推進しました。
役割: 龍馬は薩摩藩と長州藩の同盟(薩長同盟)を仲介し、幕府に対抗する勢力を結集させました。協力関係
西郷隆盛と坂本龍馬は、直接的な協力関係にあったわけではありませんが、共に幕府打倒と新政府樹立を目指して活動しました。特に、坂本龍馬が仲介した薩長同盟は、西郷隆盛が所属する薩摩藩と長州藩の協力を促進し、幕府に対抗する大きな力となりました。この同盟は、最終的に明治維新の成功に繋がる重要なステップとなりました。このように、彼らはそれぞれの立場から日本の近代化に貢献し、歴史に名を残しています。
歴史詳しくないんですけど、あってます?
API的に動かす
LangGraphのお作法にしたがって構築した場合、LangGraphは専用のAPIサーバーを勝手に稼働させてくれます。
アウトプット関連では、ストリーム的に生成内容を送るもの・async/awaitするので最終結果だけ送ってとリクエストできるものなどいくつかあります。
APIランナーで結果を見やすいので、後者を使ってみます。
/assistants/searchAPIで作ったAgentに割り振られているIDを調べてから、/run/waitAPIを使って動かします。
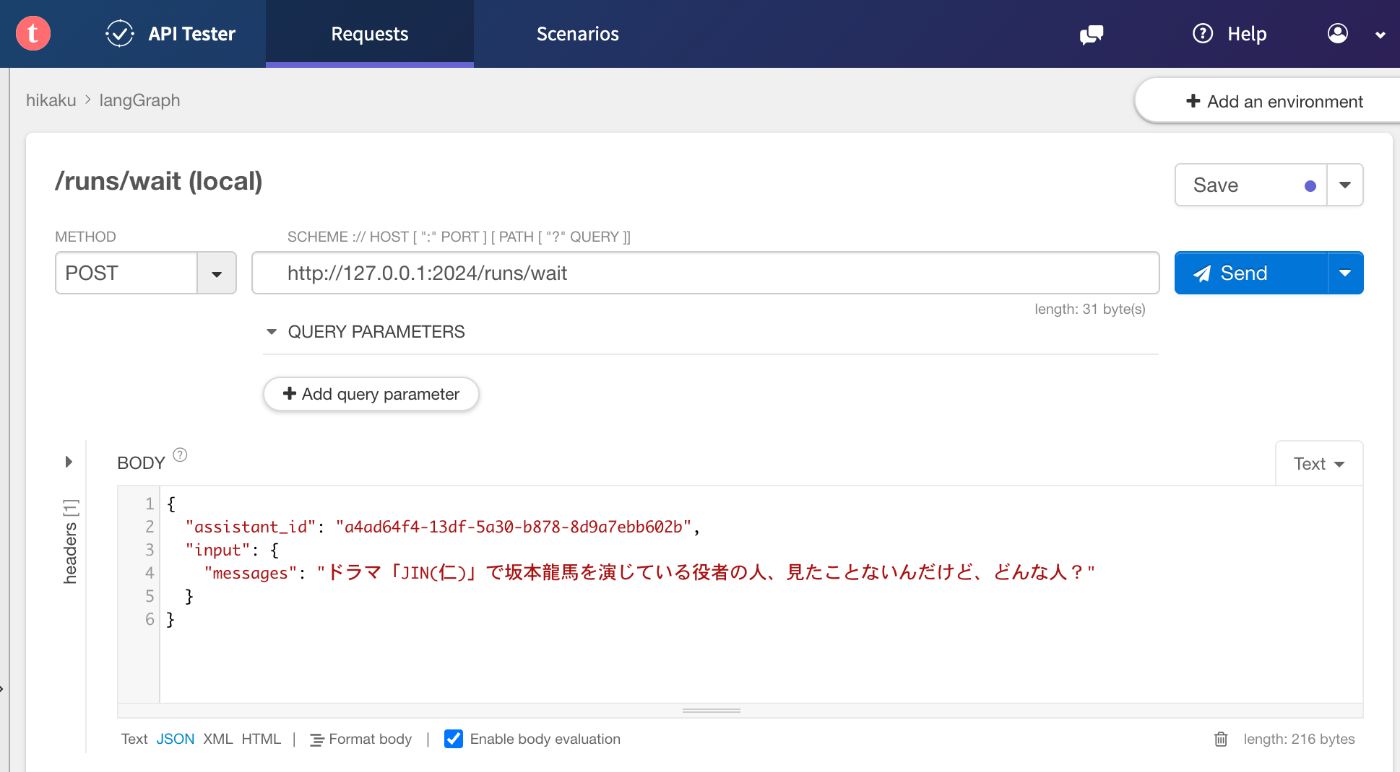
こんどは違うこと聞いてみる
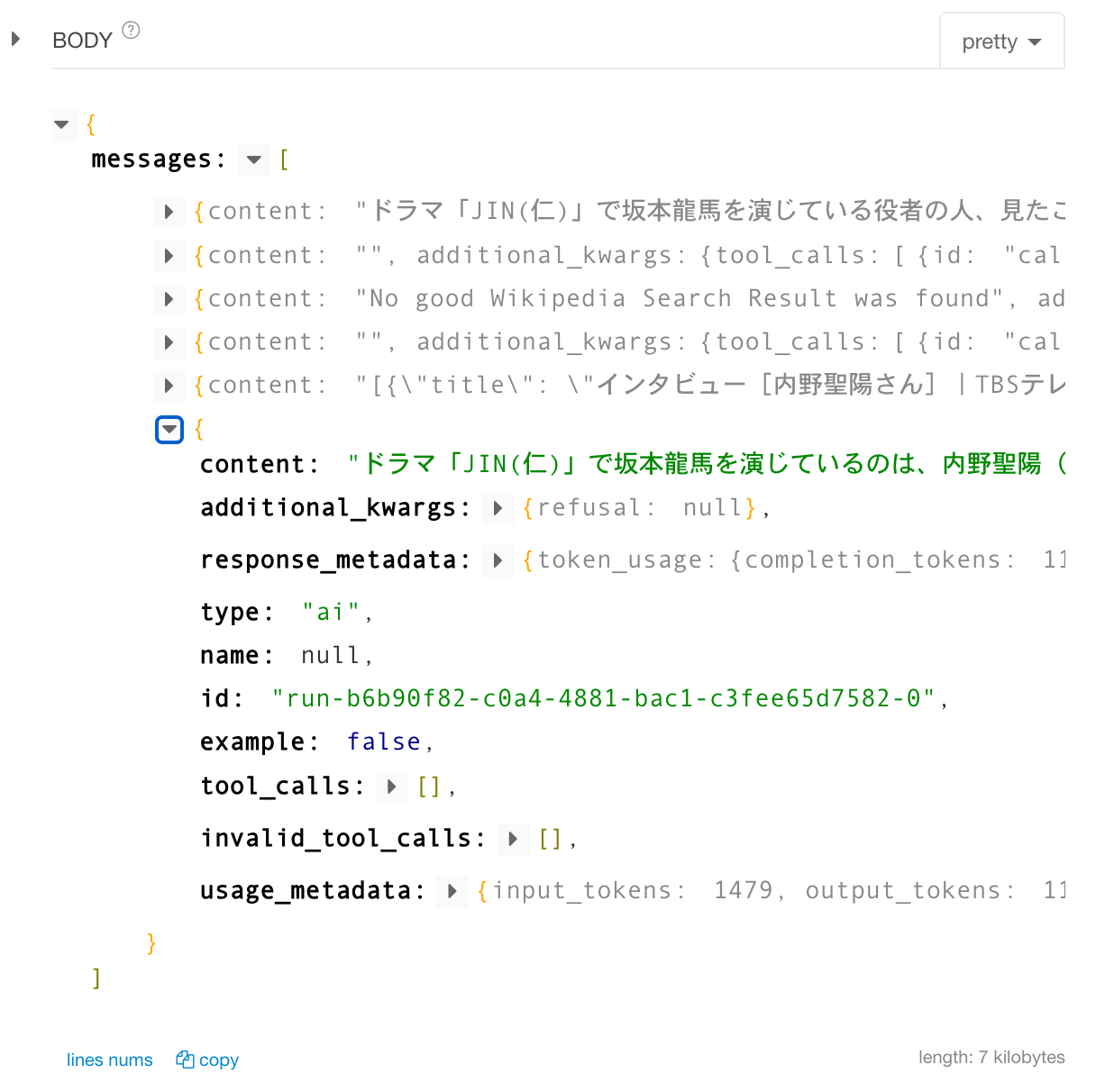
数秒後に値が返ってきた。内野さんっていうんだ〜覚えとこ
正直APIで推論結果が返ってきたら「こっちのもん」感があります。
「内部フロー」のログを見る
今回のサンプルの設定では、LangSmithにフローのログを残させるように動かしています。
環境変数LANGSMITH_PROJECTに保存した文字列を思い出しつつ、LangSmithの「Tracing Projects」にアクセスします。(https://smith.langchain.comへ。)
すると、

うわ、すご。さっき/run/waitでリクエストして、内部状態がよくわかんなかった処理が完全に可視化されてるやん
ログ見りゃ一目瞭然ですが、
- いつOpenAIにリクエストしたか
- どのタイミングでwikipediaを参照したか
- どのタイミングでGoogle検索を使ったか
- かかったコストざっくり見積もり (超重要)
といった情報が、すごく分かりやすいです。

ログ見て気づいたけど、wikipediaに「ドラマ JIN 坂本龍馬 役者」って調べに行ってるのは、頭悪いから改良しないといけないポイントかも。こういうことにも気づけます。
LangGraph Platformに上げてみる
いまローカルでやっていたことをリモートにあげたいよ。けどリモートの用意めんどくさいよ....という場合には$40ドル/人ほどの課金が必要ですが、LangGraph Platformがおすすめです。
お作法に従い実装した場合、LangChain社が用意したクラウド環境に、このアプリケーションをホスティングしてくれます。可視化やログについてもlocalと同じ温度感で引き続き利用できます。
- プラン加入 (https://www.langchain.com/pricing-langsmith)
-
https://smith.langchain.com/o/{project_id}/hostへアクセスし導線に従う
クラウドにあげるに際し、アクセスコントロールや認証も入れることができます。ドキュメント見る限り、作法は定義するので、仕組みは各自頼みますといったところでしょうか。
この手のPaaSは、月額でお金がかかるように見えるが、経営目線だと、PaaSに頼ることでインフラエンジニア(AWSエンジニア)のコストが浮いていることを加味すると、お釣りは帰ってくるとは思います。
感想
LangChain/Graph/Smithは、AI開発に必要な要件をかなり満たしているのもそうですが、お作法に従うと初学者レベルでもそこそこ動くものを実現できるので、開発体験がいいのと、「AI開発ってなんかむずかしそう...」という幻想を、容易く壊してくれるのがいいなと思いました。
言語選択・その他選択肢
執筆時点での情報ですが、LangGraphは現在pythonとJavaScriptの2つの言語をサポートしています。
筆者はJSのほうのLangChainを全く触っていないし、TypeScriptをストレスなく導入できないとなるとバニラJavaScriptをシステムに組み込むことに不安があるため、pythonを選択しています。
また、どうしてもTypeScriptを選択したいと言う場合は、そもそもLangChainでなくてもいいかもしれないです。以下をご確認ください。
気になっていること
この世には、huggingfaceというものが存在していて、事前学習済みのモデルも落ちてるみたいです。さすがにGPT-4oは落ちてないですが、型落ちであるGPT-2くらいならある様子でした。
開発中も本物のAIのAPIに接続するのでお金が溶けます
という話をさっきしましたが、「huggingfaceでモデルDLしてローカルで動かしたらいいんちゃうか....?」と思ってたりします。
ただ、型落ち品や未学習のモデルしかない問題とかあるので、取捨選択って感じですかね。
自分のPC等にLLMを設置して遊ぶことを「ローカルLLM」というそうです。
ちなみに、なぜこれを気にしているかというと、LangChainはhuggingfaceに対応したモジュールを持ってるみたいです。対応範囲やばいですねLangChain...
まとめ
- LangChain/Graph/Smithという存在があることを示しました。
- LangChainは、AI開発に関する便利モジュールの集合体です。
- LangGraphは、LangChainで作ったものを状態管理容易化・可視化・APIサーバー化などをする拡張的ライブラリです。
- LangSmithは、LangChain/Graphで作ったものの動作をロギングしたり、クラウドに上げたりできるサービスです。
- これらを丸っと使うと、どういうものが作れるのか示しました。
- 類似のサービス・代替手段等も簡単に示しました。
以上です!
どんな開発も、「簡単なところから入り、徐々に難しいところへ」というのがあるとおもいます。Agent開発に関しても、それは同じかなと思いますので、「入門としてLangChainをすごくおすすめしたい」という締めで本記事を終了します!

Discussion