こんにちは。バックエンドエンジニアのhaind01です。
大規模テーブルの移行はコストも時間もかかり、途中失敗するリスクも高いです。そのため、複数の方法を比較検討し、自分の課題や状況に適切な方法を選定することが重要だと考えています。
今回は、AWS GlueとDynamoDBのS3からインポート機能を活用し、数十億レコード規模のDynamoDBテーブルを一括移行できた事例をシェアしたいと思います。同様の課題をお持ちの方の参考になれば幸いです!
課題の概要
セキュリティの都合上、実案件の詳細は共有できませんが、以下の仮定で説明します。
- DynamoDBのオンデマンドモードで
user_activitiesテーブルが存在 - ユーザーのアクティビティログを保持(投稿、削除、閲覧、いいね、コメントなど)
- ユーザーは自分のアクティビティログの参照は可能だが編集・削除は不可
- レコード数は 30億件
ビジネス要件の変更により、新しいカラムを追加した new_user_activities テーブルに移行が必要になりました。
例:category カラム(ポスト関連、アカウント関連、ログイン関連などを分類)
従来型バッチ処理の見積もり
まず、EC2を使った並列バッチ処理を想定して見積もりました。
- 複数のEC2インスタンスで旧テーブルからデータを並列読み込み
- データ加工後に新テーブルに書き込み
仮に 1分間10万レコードを処理できたとしても、
30億レコード ÷ 10万レコード/分 〜 約3.47日
さらに、途中失敗やインフラ障害で再実行が必要になると時間もコストも増大します。制御も非常に複雑です。
DynamoDBのS3へのエクスポート & インポート機能
DynamoDBにはS3へのエクスポートとS3からのインポート機能があります。
S3へのエクスポート
- ダウンタイムなしで特定のポイントインタイムのデータをAmazon S3へ直接出力できる機能です
- 出力形式は Apache Parquet または DynamoDB JSON
S3からのインポート
- S3上の DynamoDB JSON または CSV を新しいテーブルとして直接取り込む機能です
- フルマネージドで大規模データも高速処理可能
- エクスポートしたデータに調整が不要であれば、旧テーブルからS3へエクスポートしたデータをそのまま新テーブルへインポートできるため、とても便利です。
- 重要:インポート実行中はテーブルがまだ作成されていないため、テーブルへのアクセスや書き込みができません。そのため、システム無停止で移行を行う場合は、この期間中に生成されたデータを一時的に別の場所へ保存しておくことをおすすめします。
料金について、東京リージョンでは現時点で USD 0.171/GB です。したがって、1TBの場合は 171 USD となり、非常に低コストです。(公式ドキュメント)
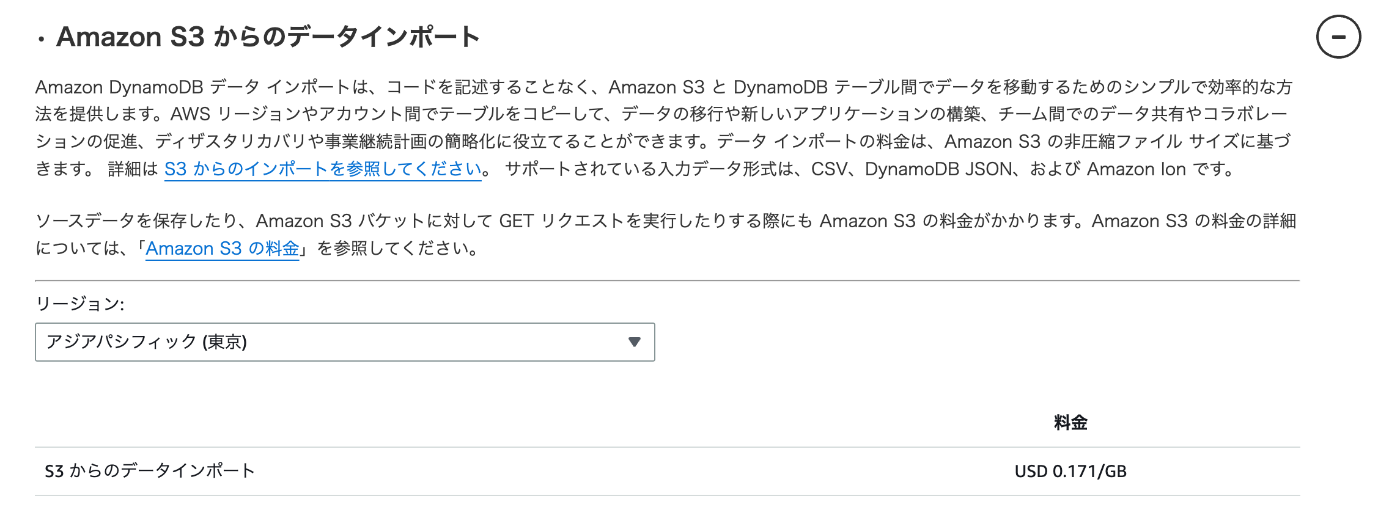
東京リージョンではS3オブジェクト合計サイズの上限が1TBのため、超える場合は事前申請が必要です。
参考:公式ドキュメント
DynamoDB JSON形式について
DynamoDB JSONは、DynamoDBのデータをJSON形式で表現する方法であり、各属性に型情報(例:S=文字列、N=数値、BOOL=論理値 など)を明示的に付与できるのが特徴です。
一方、CSV形式でインポートするとPKとSK以外の項目はすべて文字列として保存されるため、カラムごとに適切なデータ型を保持したい場合はDynamoDB JSONを使用する必要があります。
サンプル
{
"Item": {
"UserId": { "S": "12345" },
"Name": { "S": "Taro Yamada" },
"Age": { "N": "29" },
"IsActive": { "BOOL": true }
}
}
AWS Glueについて
AWS Glueは様々なデータソースからデータ検出・データ抽出・結合などを簡単に行うために用意されたAmazonの『サーバーレス・データ統合サービス』です。データ分析のためのデータ環境を整えるためには多くの工数やコストが掛かりますが、AWS Glueの利用によってそれらの工数やコストを大幅に減らすことが可能になります。
今回のケースでは以下の用途で使用しました。
-
user_activitiesをS3にエクスポート - Glue ETLジョブで 30億件のデータを処理し、新しい
categoryカラムを付与 - 処理済みデータを DynamoDB JSON形式 でS3に出力
GlueはDynamoDBテーブルへの直接書き込みもサポートしていますが、
S3からのインポート機能の方が安価かつ高速でした。
Glue ETLジョブの料金
課金体系
-
課金単位:DPU (Data Processing Unit)
- 1 DPU = 4 vCPU + 16GB メモリ
- 最小2 DPUから実行
-
課金式:
DPU数 × 実行時間 × 単価- 東京リージョン:0.44 USD / DPU / 時間
計算例
2 DPU × 0.25時間(15分) × 0.44 USD = 0.22 USD
実際の移行フロー
-
旧テーブル → S3エクスポート
- 実行時間:約30分
-
AWS Glueでデータ加工 → S3出力
- 実行時間:約8時間(8 DPUのworker typeを利用した)
- AWS Glueはデータの分割と並列処理を自動で行ってくれますが、データをそのまま一括処理すると失敗する可能性が残ります。
そのため、手動でデータを分割して処理を安定させるのがおすすめです。
私の場合は、DataFrameの randomSplit を使ってデータを分割しました。
-
S3 → 新テーブルへインポート
- 実行時間:約5時間
- GSI、LSIも設定できます
発生したコスト
今回の移行にかかったコストは合計で$500以下に抑えることができました。
弊社インフラでは、複数のリソースや機能が同時に稼働・移行しているため、本移行に起因する正確なコストを単独で確認するのは困難ですが、事前に見積もっていた範囲から大きく乖離することはありませんでした。
なお、同様の処理をバッチ方式で実行した場合、DynamoDBのWrite Request Units(WRU)によるコストは、100万WRUあたり$0.715の価格に基づくと、$2,000以上かかると試算されます。今回のアプローチと比較すると、大幅なコスト削減が可能と思います。
まとめ
- DynamoDBのS3エクスポート & インポート機能を使えば、大規模テーブルを安価かつ短期間で安全に移行可能です
- AWS Glueを組み合わせることで、データ加工も柔軟に対応できます
- この方法はデータ追加のみのテーブルに向いていると思います。一方で、データ更新が発生するテーブルでは、エクスポート後にデータが古くなってしまう可能性があるため、システム無停止での移行には適していないと思います。その場合はメンテナンス期間を設けて移行を行う必要があると考えます。
- テーブルのマイグレーションに加え、システムを無停止で機能移行するためにはAPIとの連携をしっかり設計する必要があります。次回は、このAPI部分について詳しくお話ししたいと思います。

Discussion