犬の写真から犬種を判別するアプリを作成してみた
概要
今回は犬の画像を用いて、犬の犬種を判別するAIアプリを作っていきたいと思います。
実際僕は犬の犬種については全く詳しくないので、犬の画像や名前を言われてもいつもピンとこないので、犬の画像を入力すると犬種が返ってくるというアプリを作りたいと思います。
とはいえ、いきなり全種類の犬種の判別はかなりハードルが高いので、まずは特徴が大きく異なる3種類の犬種の判別をできるアプリを作っていきたいと思います
今回のエントリーナンバ-
No1. コーギー

No2. ドーベルマン

No3. パグ

この3種類の犬の犬種を判別するアプリを作っていきたいと思います!
目次
今回の開発は大きく分けて
①モデルの作成と②アプリの作成に分けてやっていきます
①モデルの作成
・画像の準備
・モデルの作成
・モデルの学習
・モデルの評価
・モデルのテスト
②アプリの作成
・htmlファイルの作成
・CSSファイルの作成
・Flaskアプリの作成
・Git Hubとの連携
・Renderにデプロイ
・動作確認
主にこのような流れでやっていきます!!
モデルの作成
今回使用する環境
google colaboratoryを使ってモデルを学習させ、学習させたモデルをファイルとして出力します
そのモデルをアプリに埋め込んで、画像の入力に対して推論し、推論結果を返すということをしたいと思います。
また言語はpythonを使用します。
そしてアプリはRenderの上で動作させていきます!
画像の準備
今回はkaggleで公開されている犬の画像データを用いて
Stanford Dogs Datasetを用いて学習させていきます。
kaggleには機械学習で使用できそうなデータが画像に限らずたくさん転がっているので是非チェックしてみてください。
Google DriveをGoogle Colaboratoryにマウント
from google.colab import drive
drive.mount('/content/drive')
# 今回はGoogle Driveに3種類の犬の画像を格納
【参考】実際の実行画面はこんな感じ
必要なモジュール、パッケージのインポート
まずは、今回のモデルの作成、学習、グラフの描画などに必要なモジュールをインポートしていきます。
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
画像データの前処理
# データのパスを指定する
path_corgi = os.listdir('/content/drive/MyDrive/dogclassification/corgi')
path_doberman = os.listdir('/content/drive/MyDrive/dogclassification/doberman')
path_pug = os.listdir('/content/drive/MyDrive/dogclassification/pug')
#img_corgi、img_doberman、img_pugという空のリストを用意します。
img_corgi = []
img_doberman = []
img_pug = []
for i in range(len(path_corgi)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/corgi/' + path_corgi[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_corgi.append(img)
for i in range(len(path_doberman)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/doberman/' + path_doberman[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_doberman.append(img)
for i in range(len(path_pug)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/pug/' + path_pug[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_pug.append(img)
X = np.array(img_corgi + img_doberman + img_pug)
y = np.array([0] * len(img_corgi) + [1] * len(img_doberman) + [2] * len(img_pug))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X) * 0.8)]
y_train = y[:int(len(y) * 0.8)]
X_test = X[int(len(X) * 0.8):]
y_test = y[int(len(y) * 0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train, num_classes=3)
y_test = to_categorical(y_test, num_classes=3)
画像データ前処理のコードの説明
上記のコードの説明をしていきます!
path_corgiの箇所は、os.listdir関数によって、指定されたディレクトリの中のファイル名が全て格納される形になります。
例えば、以下のような配列型のデータとして格納されていたりします。
['corgi1.jpg', 'corgi2.jpg', 'corgi3.jpg']
forループでは、各犬種の画像ファイルに対して以下の処理を行っています。
① cv2.imread()関数を使って、画像ファイルを読み込みます
② 読み込んだ画像はBGR(青、緑、赤)の順で色が格納されているため、cv2.split()関数でB、G、Rの色チャンネルに分割しています
③ cv2.merge()関数を使って、RとBの色チャンネルを入れ替えてRGBの順に戻しています
④ cv2.resize()関数を使って、画像のサイズを50x50ピクセルに縮小しています
⑤ 上記の処理を終えた画像を、それぞれの犬種に対応するリスト(img_corgi、img_doberman、img_pug)に追加します。
これらの処理によって、img_corgiにはコーギーの加工済みの画像が、img_dobermanにはドーベルマンの加工済みの画像が、img_pugにはパグの加工済みの画像が格納されることになります!
モデルの作成
続いてモデルの作成をやっていきますが、学習データの画像がそれぞれ150枚程度なので、vgg16を使用して転移学習をしていきたいと思います!
# モデルにvggを使います
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、3クラス分類する層を定義します
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax'))
# vggと、top_modelを連結します
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
モデル作成のコード説明
上記のコードの説明をしていきます。
input_tensor = Input(shape=(50, 50, 3))
この行は、入力として使う画像のサイズを指定しています。ここでは犬の画像を50x50ピクセルのサイズにリサイズし、RGBの3チャンネルを持つ画像として扱っています。
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
この行は、VGG16という事前学習済みの深層学習モデルを使用しています
VGG16は、大規模な画像データセットで学習されたモデルで、特徴抽出に優れた性能を持ちます。include_top=Falseは、VGG16の全結合層を含まないことを意味し、weights='imagenet'は、VGG16の重みを事前に学習済みの重みで初期化することを指定しています。
top_model = Sequential()
この行は、独自の分類用のモデルを作成するためのSequentialモデルを定義します
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
この行は、VGG16の出力を1次元のベクトルに平坦化しています
top_model.add(Dense(256, activation='relu'))
この行は、256個の「ニューロン」と呼ばれるデータ処理の単位を持つ「全結合層」という部分を追加しています!全結合層は、前の段階で抽出された特徴を使って最終的な判別を行います。activation='relu'という部分は、この全結合層の活性化関数(情報の伝達を制御する関数)にReLU関数を使うという意味です。ReLU関数は、0より小さい場合は0を出力し、それ以外の場合はそのままの値を出力します
top_model.add(Dropout(0.5)
この行は、「Dropout」と呼ばれる学習の手法を使って過学習を防止するために使っています!
Dropoutは、一部のニューロンをランダムに無効にし、モデルの汎化性能を向上させる効果があります。ここでは、ネットワーク内のニューロンのうち、50%の割合をランダムに使わないように設定しています。
top_model.add(Dense(3, activation='softmax')): この行は、3つのクラスに分類するための最終的な全結合層を追加します。ここでは、犬がコーギー、ドーベルマン、パグの3つのクラスに分類されるので、出力のニューロン数を3にしています。また、activation='softmax'という部分は、この出力層の活性化関数に「ソフトマックス関数」と呼ばれる関数を使うという意味です。ソフトマックス関数は、各クラスに対して確率を出力するために使われ、合計が1になるような関数です。
model = Model(vgg16.inputs, top_model(vgg16.output))
この行は、先ほど定義したVGG16と分類用のモデル(top_model)を連結して、最終的なモデルを作成します。
for layer in model.layers[:19]: layer.trainable = False
この部分は、モデルのVGG16部分の重みを固定して学習しないように設定しています。VGG16の重みは事前に学習されたものを使い、ここではそれを固定しておくことで、新しい分類用のモデルの重みだけを学習させています。
model.compile(loss='categorical_crossentropy', optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=['accuracy'])
この行は、モデルをコンパイルして使用可能にします。loss='categorical_crossentropy'は、モデルの誤差を計算するための損失関数を指定しています。
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9)は、確率的勾配降下法(SGD)を使ってモデルを最適化することを意味しています。lr=1e-4は学習率を指定し、momentum=0.9はSGDのモーメンタム(慣性)を指定しています。最後のmetrics=['accuracy']は、モデルの評価指標として正解率を使うことを意味します。
と、ちょっと長々と書きましたが、これでモデルの準備は整いました!
モデルの学習とモデルの評価
# 学習を行います
history = model.fit(X_train, y_train, batch_size=100, epochs=50, validation_data=(X_test, y_test))
# グラフ表示する
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.suptitle("model", fontsize=12)
plt.legend()
plt.show()
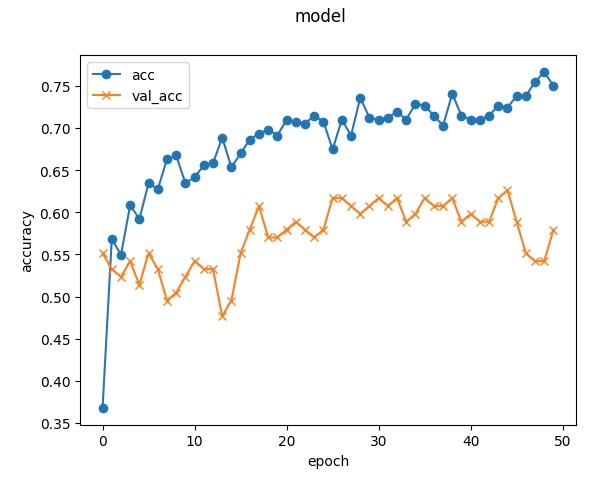
エポック数50で実施してみましたが、まだ精度が改善しそうな勢いなのでもう少しエポック数を増やしてみたいと思います。
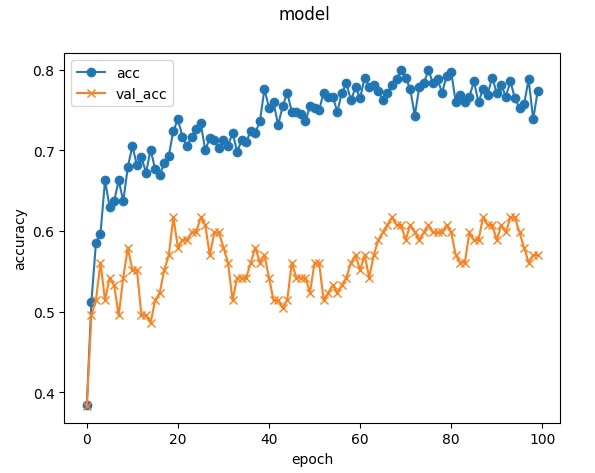
エポック数は大体70くらいで頭打ちしていることがわかりますね。
ですのでエポック数としては70でいきたいと思います!
テスト
# 画像を一枚受け取り、犬種を判定する関数
def predict_dog_breed(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'コーギー'
elif pred == 1:
return 'ドーベルマン'
else:
return 'パグ'
# 精度の評価(適切なモデル名に変えて、コメントアウトを外してください)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# 画像に対して犬種を予測します
img = cv2.imread('/content/drive/MyDrive/dogclassification/corgi/' + path_corgi[0])
b, g, r = cv2.split(img)
img1 = cv2.merge([r, g, b])
plt.imshow(img1)
plt.show()
print(predict_dog_breed(img))

やや精度は低いものの、コーギーと判定してくれました。
モデルをダウンロード
# モデルデータを出力
from google.colab import files
# resultディレクトリを作成
result_dir = "result"
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習したモデルを保存
model.save(os.path.join(result_dir, "model.h5"))
files.download("/content/result/model.h5")
ダウンロードしたモデルの稼働確認
以下のようにダウンロードしたモデルに実際の画像を入力してみて、判定されるかどうかを確認していきます。
from tensorflow.keras.preprocessing import image
from tensorflow.keras.models import load_model
import matplotlib.pyplot as plt
import numpy as np
# モデルに画像を適用するテスト
testModel = load_model("/content/result/model.h5") # 学習済みモデルのファイルパスを指定
testImage = image.load_img("/content/drive/MyDrive/dogclassification/corgi/n02113023_1496.jpg", target_size=(50, 50)) # テスト用の画像ファイルパスを指定し、適切なサイズにリサイズ
plt.imshow(testImage)
plt.show()
testImage = image.img_to_array(testImage)
data = np.array([testImage]) / 255.0 # 画像のピクセル値を0から1の範囲にスケーリング
# 画像データをモデルに渡して予測結果をresultへ代入
result = testModel.predict(data)[0]
# クラスインデックスを確率の最も高いクラスに変換して表示
predicted_class_index = np.argmax(result)
print("answer = {}".format(predicted_class_index))

ちゃんとコーギーと認識されたみたいです。
最終的なGoogle Colaboratoryの中のアウトプット
from google.colab import drive
drive.mount('/content/drive')
# 今回はGoogle Driveに3種類の犬の画像を格納
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras import optimizers
# データのパスを指定する
path_corgi = os.listdir('/content/drive/MyDrive/dogclassification/corgi')
path_doberman = os.listdir('/content/drive/MyDrive/dogclassification/doberman')
path_pug = os.listdir('/content/drive/MyDrive/dogclassification/pug')
img_corgi = []
img_doberman = []
img_pug = []
for i in range(len(path_corgi)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/corgi/' + path_corgi[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_corgi.append(img)
for i in range(len(path_doberman)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/doberman/' + path_doberman[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_doberman.append(img)
for i in range(len(path_pug)):
img = cv2.imread('/content/drive/MyDrive/dogclassification/pug/' + path_pug[i])
b, g, r = cv2.split(img)
img = cv2.merge([r, g, b])
img = cv2.resize(img, (50, 50))
img_pug.append(img)
X = np.array(img_corgi + img_doberman + img_pug)
y = np.array([0] * len(img_corgi) + [1] * len(img_doberman) + [2] * len(img_pug))
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
# データの分割
X_train = X[:int(len(X) * 0.8)]
y_train = y[:int(len(y) * 0.8)]
X_test = X[int(len(X) * 0.8):]
y_test = y[int(len(y) * 0.8):]
# 正解ラベルをone-hotの形にします
y_train = to_categorical(y_train, num_classes=3)
y_test = to_categorical(y_test, num_classes=3)
# モデルにvggを使います
input_tensor = Input(shape=(50, 50, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
# vggのoutputを受け取り、3クラス分類する層を定義します
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation='relu'))
top_model.add(Dropout(0.5))
top_model.add(Dense(3, activation='softmax'))
# vggと、top_modelを連結します
model = Model(vgg16.inputs, top_model(vgg16.output))
# vggの層の重みを変更不能にします
for layer in model.layers[:19]:
layer.trainable = False
# コンパイルします
model.compile(loss='categorical_crossentropy',
optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
metrics=['accuracy'])
# 学習を行います 修正ポイント①
# model.fit(X_train, y_train, batch_size=100, epochs=30, validation_data=(X_test, y_test))
# 学習を行います
history = model.fit(X_train, y_train, batch_size=100, epochs=100, validation_data=(X_test, y_test))
# グラフ表示する
plt.plot(history.history["accuracy"], label="acc", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_acc", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.suptitle("model", fontsize=12)
plt.legend()
plt.show()
# 画像を一枚受け取り、犬種を判定する関数
def predict_dog_breed(img):
img = cv2.resize(img, (50, 50))
pred = np.argmax(model.predict(np.array([img])))
if pred == 0:
return 'コーギー'
elif pred == 1:
return 'ドーベルマン'
else:
return 'パグ'
# 精度の評価(適切なモデル名に変えて、コメントアウトを外してください)
scores = model.evaluate(X_test, y_test, verbose=1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
# モデルの調整が終わったら、モデルデータを出力
from google.colab import files
# resultディレクトリを作成
result_dir = "result"
if not os.path.exists(result_dir):
os.mkdir(result_dir)
# 学習したモデルを保存
model.save(os.path.join(result_dir, "model.h5"))
files.download("/content/result/model.h5")
アプリ開発
学習済みモデルは作成することができたので、ここからはフロント側のwebアプリケーションを作成していきます。このWebアプリケーションから画像をアップロードして、犬種の判定結果が返ってくるというところの作成をしていきます!
必要な準備
今回フロントサイトの構築をしていくにあたって以下の手順で進めていきます。
・html、cssのプログラム作成 (フロントエンド部分)
・Flaskでのアプリ開発 (アプリケーション部分)
・Git Hubとの連携
・Renderへデプロイ
ちなみに最終的には以下のようなファイル構成になります。
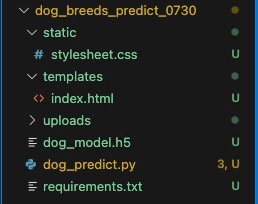
index.htmlの作成
今回はdog_breeds_predictディレクトリ、templatesディレクトリを作成し、index.htmlというファイルを作成します。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Dog Breeds Prediction</title>
<link rel="stylesheet" href="./static/stylesheet.css">
</head>
<body>
<header>
<img class="header_img" src="https://owl-stock.work/download/12430/?version=png"
alt="Y.S">
<a class="header-logo" href="#">Dog Breeds Prediction</a>
</header>
<div class="main">
<h2> AIが送信された画像の犬の犬種を識別します</h2>
<p>画像をアップロードしてください</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file">
<input class="btn" value="submit!" type="submit">
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img class="footer_img" src="https://owl-stock.work/download/12430/?version=png"
alt="Y.S">
<small>© Dog Breeds Prediction Application</small>
</footer>
</body>
</html>
CSSファイルの作成
以下のようにstaticディレクトリを作成し、style.cssファイルを作成します。
header {
background-color: #808080;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #fff;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #F7F7F7;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 25px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}
Flaskアプリケーションの作成
dog_predict.pyというファイルで以下のように作成していきます。
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
classes = ["コーギー", "ドーベルマン", "パグ"]
image_size = 50
UPLOAD_FOLDER = "uploads"
ALLOWED_EXTENSIONS = set(['png', 'jpg', 'jpeg', 'gif'])
app = Flask(__name__)
def allowed_file(filename):
return '.' in filename and filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
model = load_model('./dog_model.h5') #学習済みモデルをロード
@app.route('/', methods=['GET', 'POST'])
def upload_file():
if request.method == 'POST':
if 'file' not in request.files:
flash('ファイルがありません')
return redirect(request.url)
file = request.files['file']
if file.filename == '':
flash('ファイルがありません')
return redirect(request.url)
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
file.save(os.path.join(UPLOAD_FOLDER, filename))
filepath = os.path.join(UPLOAD_FOLDER, filename)
#受け取った画像を読み込み、np形式に変換
img = image.load_img(filepath, grayscale=False, target_size=(image_size,image_size))
img = image.img_to_array(img)
data = np.array([img]) / 255.0 # 画像のピクセル値を0から1の範囲にスケーリング
#変換したデータをモデルに渡して予測する
result = model.predict(data)[0]
predicted = result.argmax()
pred_answer = "これは " + classes[predicted] + " です"
return render_template("index.html",answer=pred_answer)
return render_template("index.html",answer="")
if __name__ == "__main__":
port = int(os.environ.get('PORT', 8080))
app.run(host ='0.0.0.0',port = port)
Gitでコードを管理してみよう!
今回上記で作成したコードをGit Hubと連携していきます。
dog_breeds_predictディレクトリで以下のコードを実行します。
$ git init
$ export PYTHONIOENCODING=utf8 # 文字コードをUTF-8に固定
これでこのディレクトリー配下のファイルがGitの管理下に置かれました。
次にCommitのステータスを確認していきます。
$ git status
>>> 出力結果
On branch main
No commits yet
Untracked files:
(use "git add <file>..." to include in what will be committed)
.DS_Store
dog_model.h5
dog_predict.py
requirements.txt
static/
templates/
uploads/
nothing added to commit but untracked files present (use "git add" to track)
全てのファイルをCommitするためのステージングに追加します。
$ git add .
それでは新規作成したファイルや更新をかけたファイルのCommitをしていきます。
$ git commit -m "first commit"
>>> 出力結果
[main (root-commit) 1e7e88f] first commit
7 files changed, 160 insertions(+)
create mode 100644 .DS_Store
create mode 100644 dog_model.h5
create mode 100644 dog_predict.py
create mode 100644 requirements.txt
create mode 100644 static/stylesheet.css
create mode 100644 templates/index.html
create mode 100644 uploads/.gitkeep
Git Hubに公開する
Git Hubでレポジトリの作成
まずはGitHubにアクセスして、会員登録を行います。
その後右上の+を押し、New repositoryを押します。Repository nameに好きな名前をつけて
他の箇所は何も操作しないまま、Create repositoryを押します。
Gitと連携するための認証トークンを発行 (後で使います!)
repoにクリックをするだけでその他は放置でOK!
するとPersonal Access Tokenが発行されるのでそれをコピーしておきます!
Renderへのデプロイ
RenderとGit Hubの連携
以下のURLを開きます。
Git Hubとの連携が済んでいる場合は以下のように、作成したレポジトリが表示されます。
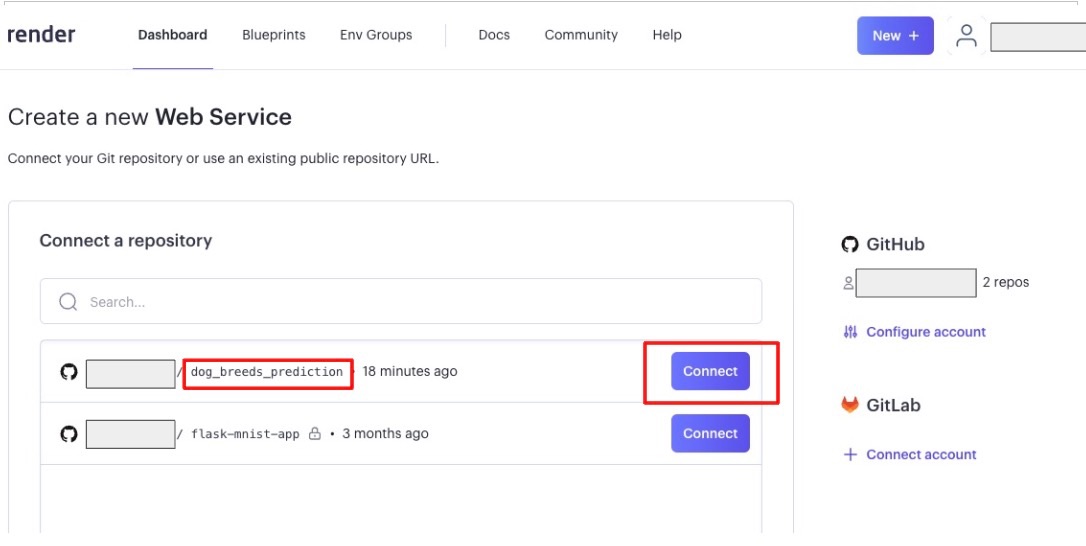
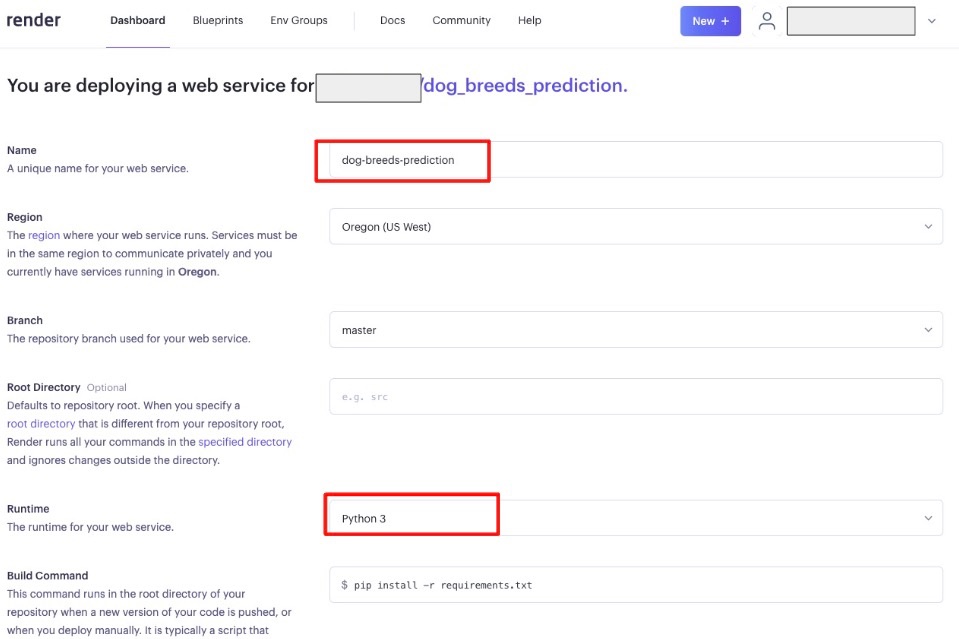
今回はdog_breeds_predictionをConnectします!
なぜ連携しているのかというと、GitHub上で管理しているコードをそのままPaasであるRenderでDeployすることができるためです。
Render デプロイの設定項目の入力
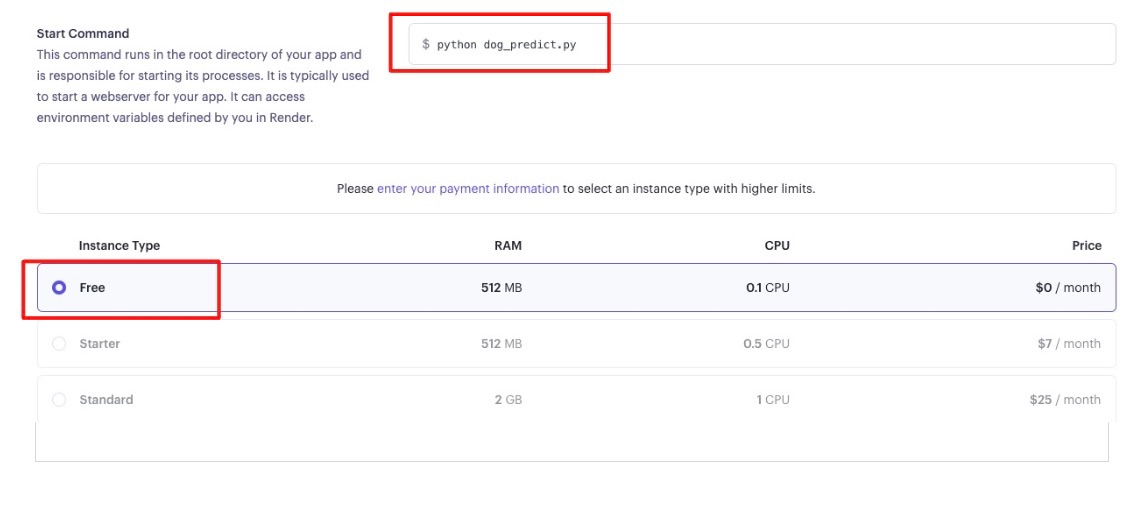
これでGitHubにPushするごとに最新バージョンのアプリケーションがRenderにデプロイされるようになりました。
Git HubのリモートレポジトリーへPushを実行
ローカルのdog_breeds_predictディレクトリーに戻って、以下を実行
$ git push -u origin main
Username for 'https://github.com': <GitHubのユーザー名>
Password for 'https://XXXXXXXX': <GitHubで生成した認証トークン>
Enumerating objects: 16, done.
Counting objects: 100% (16/16), done.
Delta compression using up to 8 threads
Compressing objects: 100% (11/11), done.
Writing objects: 100% (16/16), 53.13 MiB | 6.08 MiB/s, done.
Total 16 (delta 2), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (2/2), done.
remote: warning: See https://gh.io/lfs for more information.
remote: warning: File dog_model.h5 is 57.22 MB; this is larger than GitHub's recommended maximum file size of 50.00 MB
remote: warning: GH001: Large files detected. You may want to try Git Large File Storage - https://git-lfs.github.com.
To https://github.com/saitoyutaro/dog_breeds_prediction.git
* [new branch] main -> main
branch 'main' set up to track 'origin/main'.
すると、先ほどまではローカルのGitでしか管理していなかったコードファイルがGitHub上でも確認できました。
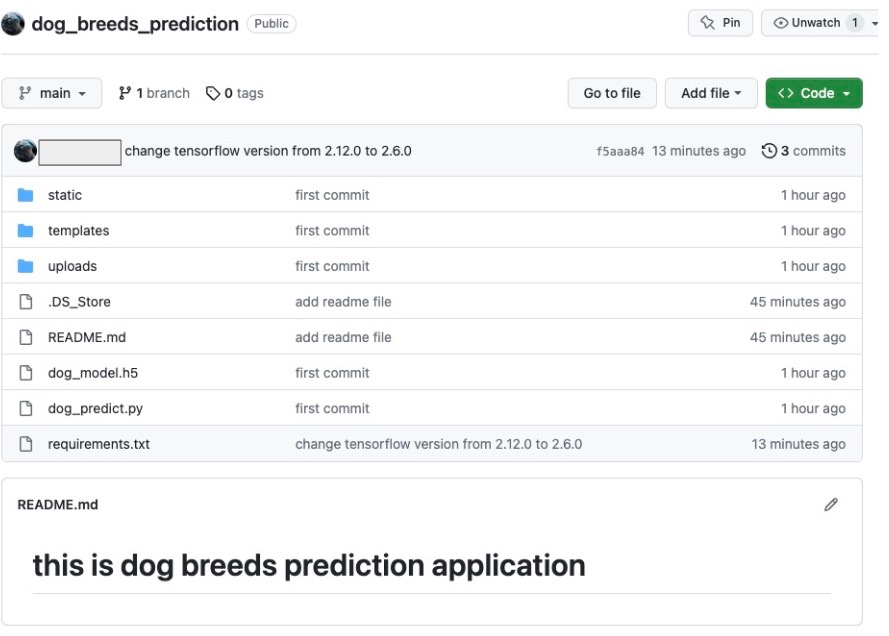
Render上でDeployが成功したことを確認
以下のようにRender上でDeployが成功していることを確認します。
今回tensorflowのバージョンの互換性で少し躓いたのですが、少し修正して成功させることができました。
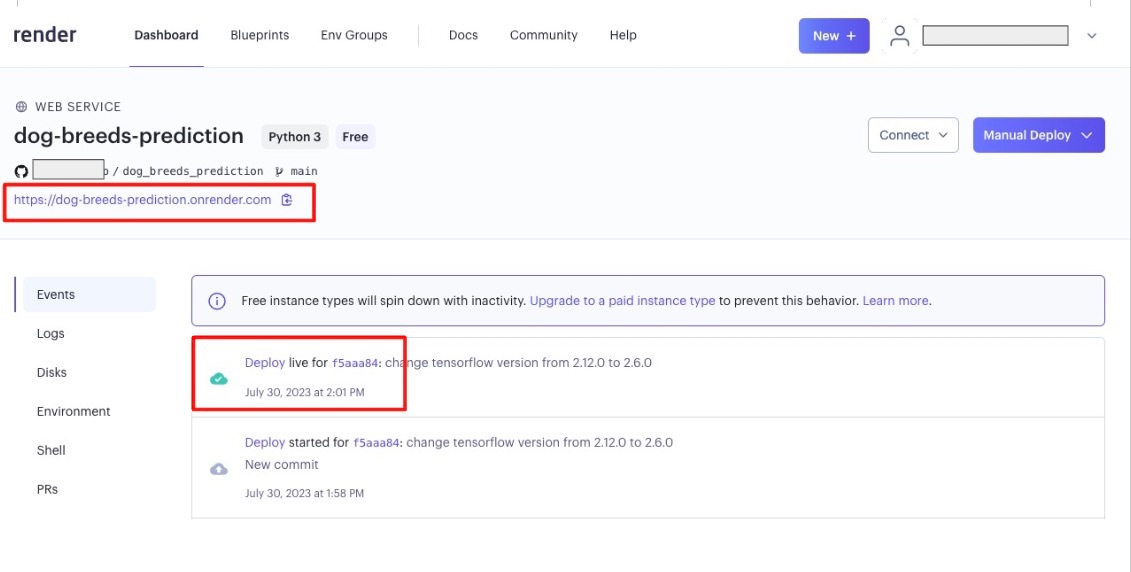
アプリとして公開されたことを確認
以下のリンクでアプリとして公開しています。
アプリのUIは必要最低限のものだけ用意しています(めっちゃ質素www)
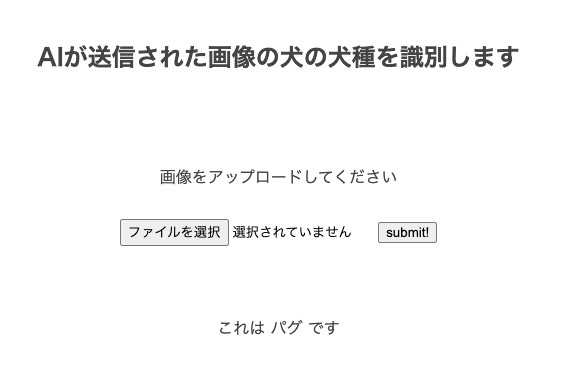
例えば、次のパグの画像を入力してみましょう!

おぉ!!正常にパグと返ってきました!
次にこのコーギーの画像を入れてみましょう!

この画像もコーギーと認識してくれました。

反省点
ドーベルマンを入れるとパグと判定されることが多く、、、
精度が高いとはとてもじゃないですが、言えないですね。
そもそもモデルの評価の時にもテストデータに対しての精度が良くなかった。
もし精度を高めるためには以下のようなことが実施できたのかなと思います。
・学習データを増やす必要あり
・学習データにはシンプルに犬だけが写っているもの以外にも背景や人が写っている画像もあったので前処理をもっと綺麗にしてあげる。つまり犬だけの画像にくり抜いてあげる。
・学習データを水増ししてあげることもできそうですね。
・ここは勉強不足なんですが、今だとVGG以外にも精度の高いモデルがあるのかもしれないですね。
終わりに
今回のアプリケーション開発を通して、精度は高くないものの、画像の準備、前処理、モデル学習と評価、アプリ作成、Git Hubとの連携からのシームレスなDeployまでを学習することができました!
今後はこの経験を活かしてもっと面白いモデルを考えてみたいと思います。
最後までお付き合いいただきありがとうございます!
Discussion
ブログ拝見させていただきました。
わんちゃんの識別アプリ以外も日々の学習を発信している様子を拝見し、私も頑張れねばと刺激をもらった次第です。
わんちゃん識別アプリの内容について質問です。
Renderデプロイ時にtensorflowのバージョン互換性で少し躓いたとありますが、私も今同じようなアプリを作っていて絶賛躓き中です。
差し支えなければどうやって解決したか教えていただけませんか?