[Pandas] DataFrameの使い方
DataFrameでは、表形式のデータを加工することができるライブラリです。
このライブラリの主な使い方を見ていきましょう!
DataFrameでhead()、tail()を使用した参照
DataFrameのデータを確認する際にPrint文を実行すると、以下のように前後5行しか表示してくれません。
import pandas as pd
import numpy as np
df = pd.read_csv("test_dir/df_test.csv") # ファイル読み込み
print(df)
>>>出力結果
0 shinjuku apple 500 2
1 shinjuku orange 600 5
2 shibuya banana 400 3
3 shinjuku banana 800 6
4 shinjuku apple 550 4
.. ... ... ... ...
145 shibuya grape 700 5
146 shibuya orange 450 2
147 shibuya grape 550 3
148 shinjuku banana 600 3
149 shibuya banana 800 8
しかし、headメソッドを使用することで、指定した行数表示させることが可能になります。
print(df.head(10))
>>>出力結果
store product price quantity
0 shinjuku orange 598 1
1 shinjuku banana 450 4
2 shibuya orange 396 3
3 shinjuku banana 976 7
4 shinjuku orange 914 6
5 shibuya grape 678 2
6 shinjuku banana 782 9
7 shibuya orange 540 5
8 shibuya banana 423 2
9 shinjuku pineapple 892 4
headメソッドは上からの行数分のデータを表示するのに対して、tailメソッドは下からの行数分のデータを表示するのに使用します。
メソッド.Tを使ってみる
.Tを使うと行方向と列方向が転置されます
例えば、先ほどと同じデータを用いるとしてhead().Tメソッドを使用してみましょう!
print(df.head().T)
>>>出力結果
0 1 2 3 4
store shinjuku shinjuku shibuya shinjuku shinjuku
product orange banana orange banana orange
price 598 450 396 976 914
quantity 1 4 3 7 6
メソッドlocを用いてデータ参照
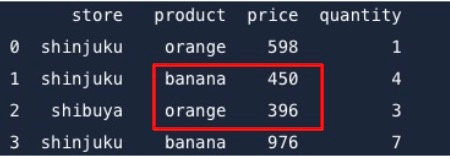
locメソッドを使用することで、指定の行と列のデータを抽出することができます。
例えば、インデックス番号1と2の行と、productとpriceの列を抽出したい場合は以下のように書きます
print(df.loc[1:2,"product":"price"])
すると以下の部分だけを抽出することが可能です
条件でフィルタリングしてみる
DataFrameのデータから条件に合致するものだけ抽出するということができます。
SQL文でいうところのWhere句になります。
dfの後の[]のなかに条件を指定します。
例えば[df["price"]>500]でpriceが500以上のものという条件が加わります。
print(df[df["price"]>500])
>>>出力結果
store product price quantity
0 shinjuku orange 598 1
3 shinjuku banana 976 7
4 shinjuku orange 914 6
5 shibuya grape 678 2
6 shinjuku banana 782 9
7 shibuya orange 540 5
9 shinjuku pineapple 892 4
DataFrameのデータをソートしてみよう
DataFrameのデータはsort_valuesメソッドでカラムを指定してソートすることができます。
例えば、df.sort_values(by="カラム名", ascending=True)とすることで特定のカラムで昇順にソートすることが可能です。
ascending=False は降順になります。
df.sort_values(by="price", ascending=True)
store product price quantity
2 shibuya orange 396 3
8 shibuya banana 423 2
1 shinjuku banana 450 4
7 shibuya orange 540 5
0 shinjuku orange 598 1
5 shibuya grape 678 2
9 shinjuku apple 892 4
6 shinjuku banana 782 9
4 shinjuku orange 914 6
3 shinjuku banana 976 7
DataFrameのレコード追加をやってみよう
df.appendメソッドでレコードを追加することができます。
df.append(series, ignore_index=True)で新しいレコードを追加することができます。
ここではseriesを追加していますが、seriesを追加する
series = pd.Series(
{"store": "shibuya", "product": "peach", "price": 900, "quantity": 2}) # Seriesの作成
df = df.append(series, ignore_index=True) # 非破壊なメソッドなのでイコールを用いて上書き
print(df) #レコード追加ごとのdfを表示
>>>出力結果
store product price quantity
0 shinjuku orange 598 1
1 shinjuku banana 450 4
2 shibuya orange 396 3
3 shinjuku banana 976 7
4 shinjuku orange 914 6
5 shibuya grape 678 2
6 shinjuku banana 782 9
7 shibuya orange 540 5
8 shibuya banana 423 2
9 shinjuku pineapple 892 4
10 shibuya peach 900 2
DataFrameのカラム追加をやってみよう
DataFrameのカラムの追加は
DataFrameの変数["新たなカラム名"]=リスト or Series
で実施することが可能です。
例えば、先ほどのDataFrameに追加で次のようなコードを実行してみましょう
df["day"] = ["Sunday","Saturday","Wednesday","Thursday",Monday","Monday","Tuesday",Friday","Saturday","Wednedday"]
print(df)
>>>出力結果
store product price quantity day
0 shinjuku orange 598 1 Sunday
1 shinjuku banana 450 4 Saturday
2 shibuya orange 396 3 Wednesday
3 shinjuku banana 976 7 Thursday
4 shinjuku orange 914 6 Monday
5 shibuya grape 678 2 Monday
6 shinjuku banana 782 9 Tuesday
7 shibuya orange 540 5 Friday
8 shibuya banana 423 2 Saturday
9 shinjuku pineapple 892 4 Wednesday
10 shibuya peach 900 2 Wednesday
dayというカラムが追加されたことが確認できました。
DataFrameのレコードの削除
dropメソッドを使用してDataFrameのレコードを削除することができます。
早速具体例を見た方が早いのでサンプルコードで確認してみましょう!
前項でのdfのデータをそのまま使っていることを前提にします。
df = df.drop(range(0, 2)) # インデックス0と1のレコードを削除
>>>出力結果
store product price quantity day
2 shibuya orange 396 3 Wednesday
3 shinjuku banana 976 7 Thursday
4 shinjuku orange 914 6 Monday
5 shibuya grape 678 2 Monday
6 shinjuku banana 782 9 Tuesday
7 shibuya orange 540 5 Friday
8 shibuya banana 423 2 Saturday
9 shinjuku pineapple 892 4 Wednesday
10 shibuya peach 900 2 Wednesday
DataFrameのカラムの削除
カラムの削除はdrop("削除対象のカラム", axis=1)で削除することができます。
こちらもサンプルコードを見てみましょう!
df = df.drop("store", axis=1) # カラムstoreの削除
>>>出力結果
product price quantity day
0 orange 598 1 Sunday
1 banana 450 4 Saturday
2 orange 396 3 Wednesday
3 banana 976 7 Thursday
4 orange 914 6 Monday
5 grape 678 2 Monday
6 banana 782 9 Tuesday
7 orange 540 5 Friday
8 banana 423 2 Saturday
9 pineapple 892 4 Wednesday
10 peach 900 2 Wednesday
要約統計量を表示する
df.describeメソッドで平均値、最大値、最小値などの要約統計量データをまとめて出してくれます。
早速具体例を見てみましょう!
先ほどのDataFrameのデータに対して、df.describeを実施した例になります。
print(df.describe())
>>>出力結果
price quantity
count 10.000000 10.000000
mean 681.900000 4.300000
std 217.202066 2.494438
min 396.000000 1.000000
25% 504.750000 2.250000
50% 640.000000 4.000000
75% 875.000000 5.750000
max 976.000000 9.000000
DataFrameのグループ化
DataFrameではSQLと同様Group化も可能です。
df.groupby('グループ化したい列').計算関数())
でグループ化することが可能です!
print(df.groupby('store').max()) #storeごとにpriceとquantityのMax値を表示
>>>出力結果
price quantity
store
shibuya 1200 5
shinjuku 1250 5
yokohama 800 1
DataFrameの連結
今までは一つのDataFrameを想定してデータ加工の仕方を学びましたが、実際にデータを加工する場合には一つのDataFrameだけでなく複数のデータを用いれ分析や機械学習をすることが多いかと思います。
その際に複数のDataFrame同士を一定の方向についてそのままつなげる操作を連結と呼びます。
concatメソッドを使って連結することができます。
pd.concat([連結するDataFrameのリスト], axis= 0 or 1)
引数にaxis=0を渡すとインデックス方向(行方向に)、axis=1を渡すとカラム方向(列方向に)に連結されます。
DataFrameの結合
DataFrameの結合はmerge関数を用いて記述します。
import pandas as pd
pd.merge(左のDataFrame, 右のDataFrame, on = "keyにするカラム名", how="結合の種類")
結合の種類の箇所に
内部結合の場合 "inner"
左外部結合の場合 "left"
右外部結合の場合 "right"
完全外部結合の場合 "outer"
と記述することで結合の種類を分けることができる。
まとめ
本記事ではDataFrameの基本的な使い方を抑えていきました。
ほとんどSQL文でできそうなことをDataFrameを使ってできるというものになります。
pythonでデータ加工などをしたいときには便利そうですね。
このデータを使った計算処理などはNumpyにお任せすることができます。
Discussion