BigQueryの内部構造について調べてみた
今回はGoogle CloudのBigQueryの内部構造を公式ブログなどを元に調べてみました。
なぜBigQueryは高速化つスケーラブルなのか、その実態に迫りたいと思います。
BigQueryのざっくり内部構造
BigQueryはざっくりいうと、CPU部分、メモリ部分、ストレージ部分が分離しているアーキテクチャーになっています。なので、CPUだけ拡張、メモリだけ拡張、ストレージだけ拡張みたいな感じでどこかがボトルネックになったところでその部分だけ拡張する。みたいなことができるのです。
[参考URL]
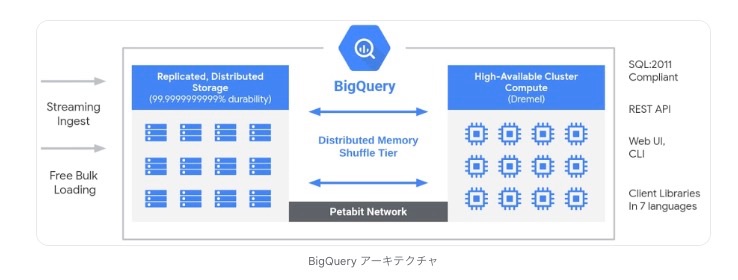
ただ、それぞれを分離してしまうと、その間を流れる帯域を大幅に確保しておかないと今度はCPUとメモリ、ストレージを繋ぐ部分がボトルネックになってしまうのですが、BigQueryはこのネットワーク部分をJupiterという最強のネットワークで繋いているので、アーキテクチャが分離してても大丈夫なんです。
ちなみにJupiterについての詳細な説明はこちらにあります。(英語)
どういうPrincipalでネットワークが設計されているのかが記載されています。
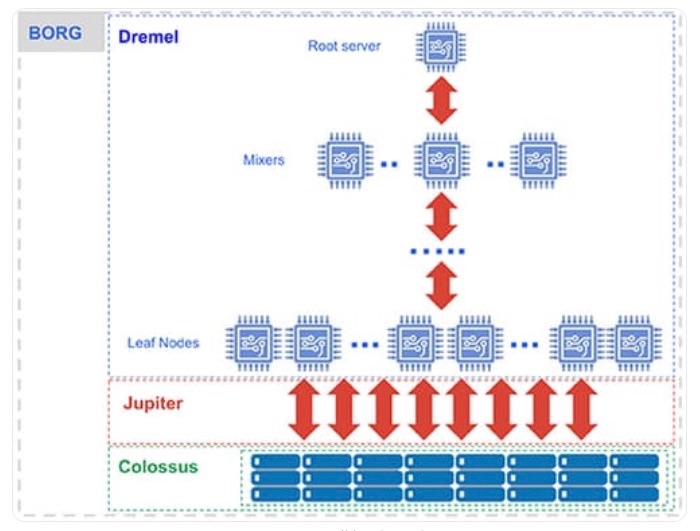
BigQueryのコンピューティング編 - Dremel
DremelとはBigQueryの分散処理を司っているコンピューティング部分を指しています。
Dremel は、SQL クエリを実行ツリーに変換します。ツリーのリーフはスロットと呼ばれ、ストレージからデータを読み込むという手間のかかる処理と必要な計算を行います。ツリーのブランチは、集計を行うミキサーの役割を担います。
Dremel は、必要に応じてスロットをクエリに動的に割り当て、複数のユーザーからの同時実行クエリに対する公平性を保ちます。1 人のユーザーが数千のスロットを取得してクエリを実行できます。
BigQueryのストレージ編 - データ保管方法
参考にした公式ブログはこちら
従来のRDBは行単位でデータを保存
BigQueryは列単位でデータを保存
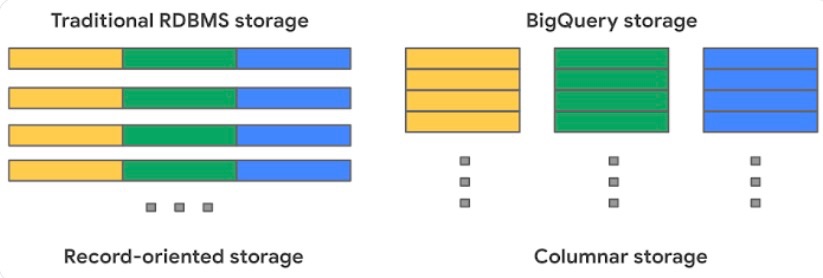
BigQueryの内部では、Capacitorという独自のカラム型でデータが保存されます。
簡単にいうと、列指向のデータ保存の仕方をします。
従来のデータ保存形式だと、不要な列のデータも読み込む必要があったのですが、必要な列だけ読み出すことができるので効率的な読み込みができるというのが特徴です。
Capacitorとして分割されたデータはCollosusという分散ファイルシステムに書き込まれます。
[参考] Capacitorの仕組みについて
Capacitorについてはこちらの公式ブログをもとに説明します。
[参考] Collosusの仕組みについて
Colossus はレプリケーションや(ディスク クラッシュ時の)復元のほか、分散型管理も行います(そのため単一障害点がありません)
Collosusについてはこちらの公式ブログをもとに説明します。
BigQueryデータを取り込み編
BigQueryのデータ取り込みについてはこちらの公式ガイドを参考にしてます。
データがロードされる時のデータの形式には以下のように、高速取り込めるものと、少し時間がかかる傾向のものがあります。
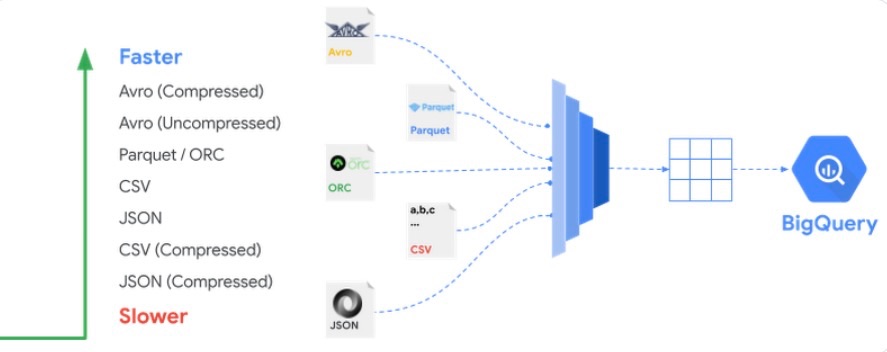
データをロードするまでのステップ
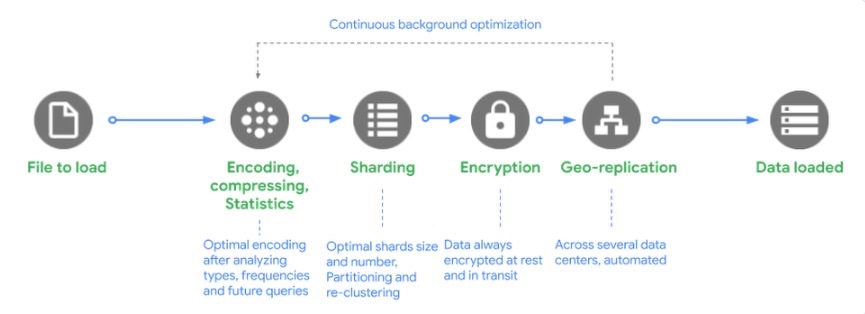
① エンコード、圧縮、統計: BigQuery は、データ型と値の頻度を分析した後、データを最適にエンコードし、大規模な構造化データの読み取り用に最適化された方法でデータを圧縮します。
② シャーディング: データを最適なシャードに分散し、テーブルの定義方法に基づいて、データを特定のパーティション、クラスタに読み込み、データを再クラスタ化します。
③ 暗号化: BigQuery は、データをディスクに書き込む前に、デフォルトで常にデータを暗号化します。追加で操作を行う必要はありません。データは承認済みのユーザーが読み取りを行う際に、自動的に復号されます。転送中のデータの場合、マシン間でデータが転送されるときに Google データセンター内でデータが暗号化されます。
④ ジオレプリケーション: BigQuery は、データセットのロケーションをどのように定義したか(リージョン内かマルチリージョンか)に応じて、複数のデータセンターにデータを自動的に複製します。
BigQuery内部構造 - データ処理編 -
こちらのURLを参考にしています。
この記事は随時アップデートしていきたいと思います。
Discussion