AWS生成AIキャッチアップ
AWS で始める生成系 AI for Entry
独自の情報を生成AIで活用する方法
-
RAG
- Amazon Kendraの機能をくみあわせてRAGワークフローを実装し、生成AIの出力を組織や企業データを元に生成させる
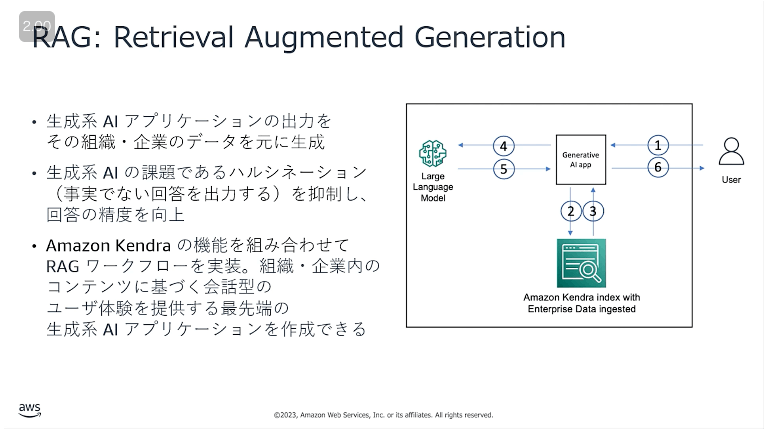
- Amazon Kendraの機能をくみあわせてRAGワークフローを実装し、生成AIの出力を組織や企業データを元に生成させる
-
Fine-Tuning
- 基盤モデルに社内のドキュメントデータを与えて追加のトレーニングを行い、新たに基盤モデルを作成する
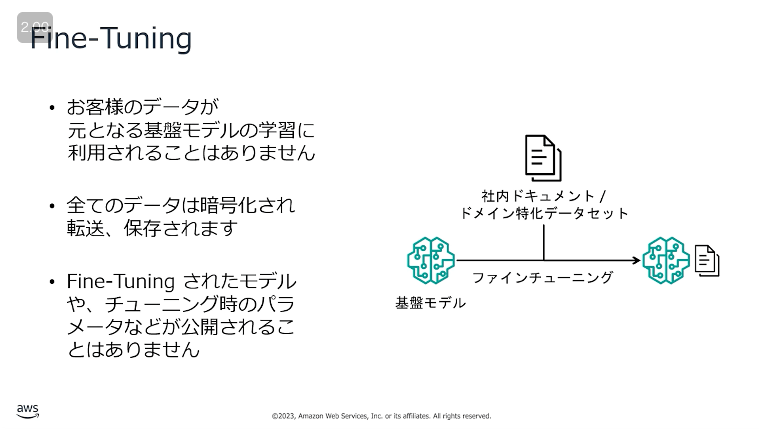
- 基盤モデルに社内のドキュメントデータを与えて追加のトレーニングを行い、新たに基盤モデルを作成する
生成 AI プロジェクトの計画におけるステップ
ステップ 1: スコープを定義する
お客様はこれを希望しているか
お客様、お客様のペインポイント、どのようなソリューションがより良いカスタマーエクスペリエンスを提供できるかを深く理解する
- どのような問題を解決しようといるのか。
- 達成したいお客様の成果は何か。
- ソリューションの対象とするお客様は誰か。
あなたの組織にこれが可能か
組織がソリューションを現実のものとするために必要な資金、時間、労力を特定する
- 社内のガバナンスやポリシーのハードルは何か。
- このソリューションの資金はどこから出ているのか。
- テクニックまたはエンジニアリング上の最大の課題は何か。
組織はこれを行うべきか
そのソリューションは市場においてどのような課題に直面しうるか、そのソリューションが組織にどのような利点をもたらす可能性があるのかを理解する
- お客様はそのソリューションをどのようにして繰り返し使用するか。
- ソリューションの主な競合他社は誰か。
- なぜお客様は新しいお客様に貴社を紹介したいのか。
長期的影響と短期的影響
それぞれのソリューションがもたらす長期的影響と短期的影響を評価する
ステップ 2: モデルの選択
事前にトレーニングされたモデルをそのまま使うか、モデルを fine-tuning してカスタマイズするか
ステップ 3: モデルの適応
モデルから得られる出力のタイプをカスタマイズする方法は 2 つ
-
プロンプトエンジニアリング
- モデルがニーズに合った特定の種類の出力を生成するために、プロンプトまたは入力を設計し改良する
-
Fine-tuning
- 基盤モデル またはオープンソースモデルを fine-tuning する
ステップ 4: モデルの使用
生成 AI のいくつかの潜在的懸念事項
有害性
リスク
扇動的、攻撃的、または不適切なコンテンツの生成。
緩和策
- トレーニングデータの厳選
- これらのフレーズを事前に特定し、トレーニングデータから削除すると、出力として生成されるのを防ぐことができます。
- ガードレールモデル
- これらのモデルは不要なコンテンツを検出し、フィルターにより排除します。
ハルシネーション
リスク
間違っているのにもっともらしい回答
緩和策
すべてをチェックしなければならないことをユーザーに教えてください。基盤モデルが語るストーリーが現実に基づいているか、事実に促しているかを検証するにあたっては、基盤モデルを信頼することはできませんが、コンテンツが独立情報源によって検証されているかどうかをチェックすることで、さらに緩和できるでしょう。したがって、生成されたコンテンツを未検証としてマークし、検証が必要であることをユーザーに警告することができます。
知的財産
リスク
基盤モデルは時折、トレーニングデータを正確に複製したコンテンツを生成することがあります。その結果、オリジナルにかなり近いコンテンツができあがり、プライバシーの問題を引き起こす可能性があります。
緩和策
知的財産をめぐる懸念事項は、技術、政策、法機構の混合によって、時間をかけて対処されていくでしょう (Michael Kearns、2023 年)。
- モデル破棄
- 保護されたコンテンツは削除または削減されます。
- 差分プライバシーモデル
- トレーニングデータは生成済みコンテンツの影響を削減します。
- シャーディング
- トレーニングモデルを小さなモデルに分割し、大きなモデルに影響を与えることなくそれらを再トレーニングするアプローチ。
- フィルタリング
- 生成されたコンテンツは保護されたコンテンツと比較され、一致する場合は削除されます。これは複製された生成コンテンツを減らすこともできます。
盗用と不正行為
リスク
生成 AI が作成する人間が書いたようなコンテンツは、本物の人間が作成したコンテンツとの区別を難しくします。そのため、これを教育課題などの文書コンテンツに使用すると、不正行為や盗用という望ましくない結果を招く可能性があります。
緩和策
人間または生成モデルによって生成されたコンテンツを検出できるようモデルをトレーニングしてください。モデルは単語を 2 つのリスト (レッド、グリーン) に分けるようにトレーニングされます。もしモデルがグリーンリストからしか取得を許可されなければ、グリーンリストから生成された文章を人間が作成することは事実上不可能でしょう。
仕事の性質の混乱
リスク
生成 AI が実行するタスクやクリエイティブなコンテンツ生成のスピードや正確さが意味するのは、企業が人間ではなくプログラムを使いたがるという懸念につながる可能性があるということです。
現在人間が行っているナレッジタスクの一部は、将来自動化されるでしょう。
このアプローチは、組み立てラインで人間が行っていた肉体労働の一部をロボットを使用して自動化するのと似ています。
緩和策
生成 AI は、自動化するのと同じくらい多くの雇用を創出する可能性があります。モデルをオープンエンドにするのではなく、より専門的にすることで、特定の領域を保護することができます。
Amazon Bedrock Getting Started
- Amazon Bedrock を使用すると、データ (プロンプト、プロンプトの補完のための情報、基盤モデルの応答、カスタマイズされた基盤モデルなど) は、API コールを処理するリージョン内に留まります。データは転送中に TLS 1.2 で暗号化され、サービスが管理する AWS Key Management Service (AWS KMS)キーを使って暗号化されて保管されます。
- お客様データが、ベースとなる基盤モデルの改善や強化のために使用されることはありません。また、お客様のデータがモデルのプロバイダーに共有されることもありません。
- Amazon Bedrock は、仮想プライベートクラウド (VPC) 内で構成されないフルマネージドサービスです。サービスエンドポイントには AWS PrivateLink を通じて VPC からアクセスできます。
- 基盤モデルを Fine-tuning する際に、ベースとなる基盤モデルを複製したモデルに対して、お客様のデータを用いてトレーニングします。この Fine-tuning はプライベートです。Fine-tuning に使用されたお客様のデータも、Fine-tuning された基盤モデルも、他のお客様やベースとなる基盤モデルのプロバイダーに共有されることはありません。