Open5
AWS Summit 2025
Amazon S3 によるデータレイク構築と最適化
- 汎用バケットのスケーリングの仕組み
- Prefix毎にリクエストがスケール
- 3,500(PUT/COPY/POST/DELETE)
- 5,500(GET/HEAD)
- トラフィックが新しいPrefixに移動すると内部的なスケールを開始する。スケーリングが実行されている間は、アプリケーションがエラーレスポンスを受ける可能性がある。
- YYYY/MM/DD/hh などで分けると00分にスケールが発生する。
- ランダム性を持った値を上位に持ってくることで、S3は常に複数のPrefixにリクエストが分散されるので、スケールによるエラーの影響を減らすことができる。
- session-id/YYYY/MM/DD/hh
- Prefix毎にリクエストがスケール
- クエリの最適化
- Iceberg(オープンテーブルフォーマット)を使用することで、ユーザー側がクエリを作成する際にパーティションを指定しなくても、自動でパーティションを考慮したアクセスが実行される
- オープンテーブルフォーマットは、データモデルに新しい層を追加する。既存のデータ層を置き換えるものではなく、CSVやParquetの上のレイヤーで動く
- データの効率的なアクセスの手助けを行う

- Icebergをフルマネージドで管理するS3がS3Tables
- 表形式に特化した設計
アクション
- S3 Tablesを試す
クラウドストレージのコスト最適化戦略 - AWS ストレージの賢い活用法
- S3オブジェクトの移行コストはオブジェクト数に依存する。オブジェクト数に応じて、ストレージクラス移行にともなうコストを回収する期間は変わる
- S3Lensを活用する
- アクセス頻度を分析し、自分でライフサイクルを作成することも検討する
AI アプリケーションのためのデータエンジニアリング戦略 - Amazon Bedrock で実現する構造化データ活用
- テーブルデータなどの構造化データへのアクセスには、セマンティック検索以上の情報が必要
- 自然言語からSQLへの変換(NL2SQL; Natural Language to SQL)は構造化データのためのRAG
- NL2SQLがうまく動くには
- スキーマ構造を与える必要がある。
- データの中身を知る必要がある。
- SQLの文法を理解する必要がある。
- 構造化データを取得する機能が「Amazon Bedrock Knowledge Bases」
- あらかじめ構造化データに関するメタデータを保持
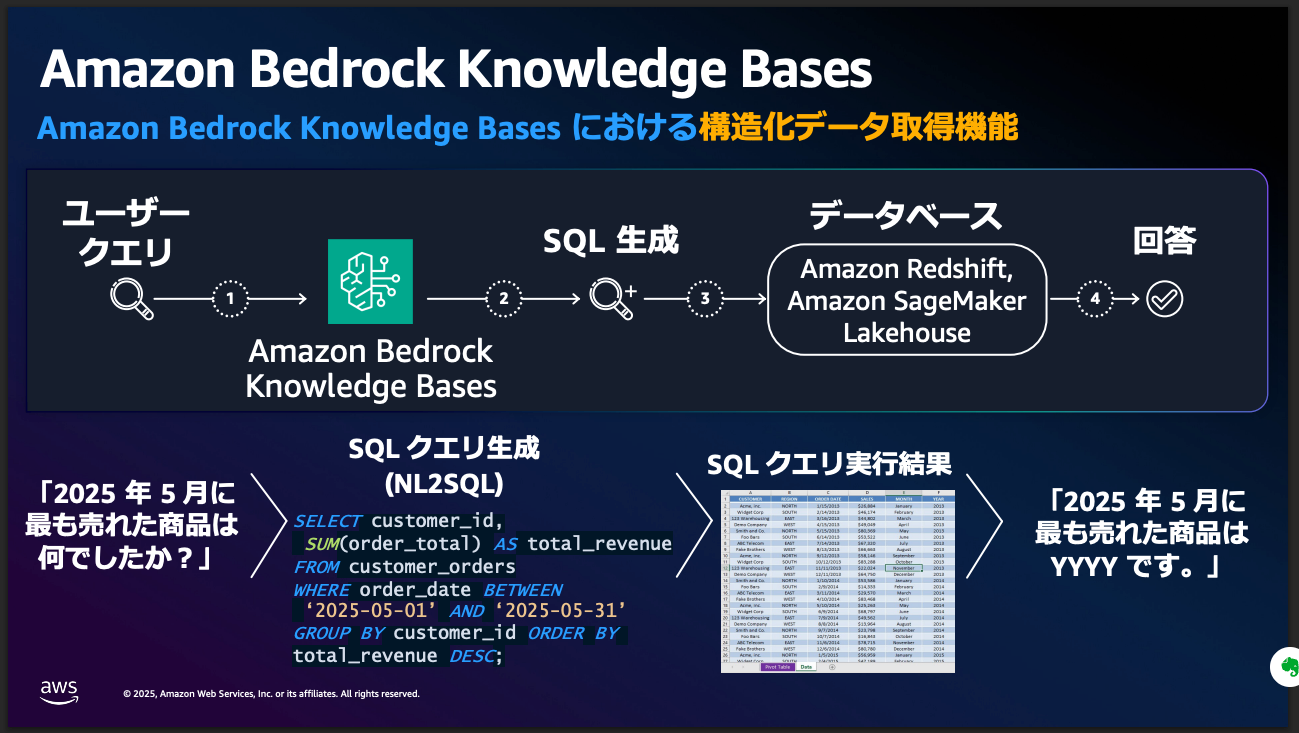
- クエリ設定オプションでSQL改善のための独自のルールを追加可能
- あらかじめ構造化データに関するメタデータを保持
アクション
- Amazon Bedrock Knowledge Basesで、S3 Exportした構造化データへのアクセスを試す
生成 AI のためのデータ活用実践ガイド
- 拡張プロンプトに含める情報
- システムプロンプト
- プロンプトテンプレートリポジトリ
- 状況コンテキスト
- AmazonAurora
- セマンティックコンテキスト
- OpenSearch Serverless
- システムプロンプト
- RAGの手法
- Naiive RAG
- Advanced RAG
- Mudular RAG