Inference Scaling for Long-Context Retrieval Augmented Generation
要約
長文脈の大規模言語モデル (LLM) を用いた知識集約型タスクにおける推論スケーリングに関する研究
-
従来の検索拡張生成 (RAG) 手法を拡張しデモンストレーションベース RAG (DRAG) と反復的 DRAG (IterDRAG) という 2 つの新しい推論スケーリング戦略を提案
-
これらの戦略により計算リソースを効率的に活用して RAG の性能を向上させる事が出来る。特に有効コンテキスト長(推論に使用される総トークン数)が増加するにつれて RAG の性能がほぼ線形に向上する事を示している
-
RAG の性能と推論パラメーターの関係をモデル化する「計算割り当てモデル」を提案。このモデルは与えられた計算予算内で最適な推論パラメーターを予測するのに役立つ
-
ベンチマークデータセットでの実験により提案手法の有効性を実証。最大で 58.9% の性能向上を達成
-
研究結果に基づいて長文脈 RAG の推論スケーリング法則を導出し RAG の性能と推論計算量の関係を定式化
-
提案モデルの一般化能力や長さの外挿性能についても検証し様々なタスクや計算予算に適用可能である事を示している
-
検索品質、エラー分析、長文脈モデリングの課題など RAG の性能に影響を与える追加要因についても議論している
Abstract
-
研究目的 : 長文脈大規模言語モデル (LLM) を用いた検索拡張生成 (RAG) における推論スケーリング調査
-
提案手法
- デモンストレーションベース RAG (DRAG)
- 反復的デモンストレーションベース RAG (IterDRAG)
-
主な発見
- 最適に構成された場合 RAG の性能は推論計算量とほぼ線形に向上する
- この関係を「RAG の推論スケーリング則」と呼んでいる
-
提案モデル
- RAG の計算割り当てモデル
- 異なる推論構成で RAG 性能を予測
-
実験結果
- ベンチマークデータセットで最大 58.9% の性能向上を達成
- 最適な構成を予測し実験結果と密接に一致
1. Introduction
-
長文脈 LLM の紹介 :
- 長い入力シーケンスを処理出来るに設計されている(例 : Gemini 1.5 Pro は最大 2M トークン)
- 増加した推論計算と組み合わせて様々なタスクでパフォーマンスが向上
-
知識集約型タスクにおける RAG の重要性 :
- 検索された文書の量や大きさを増やす事で一定の閾値まで性能が向上
-
現在の RAG 手法の限界 :
- 知識量の増加だけでは不十分
- LLM は超長シーケンスから関連情報を効果的に見つける事が困難
- 検索量の増加が性能低下を引き起こす可能性
-
提案手法 :
- DRAG : in-context 学習を活用
- IterDRAG : クエリーの分解と反復的な検索・生成を導入
-
研究目的 :
- RAG 性能と推論計算量のスケーリング関係を調査
- 最適な計算配分の予測モデル開発
-
主な貢献 :
- RAG の推論スケーリング則発見
- 計算割り当てモデル開発と検証
- ベンチマークデータセットで大幅な性能向上

Figure 1 : Normalized performance vs. effective context lengths on MuSiQue. Each line represents a fixed configuration, scaled by adjusting the number of documents. Red dots and dash lines represent the optimal configurations and their fitting results. Standard RAG plateaus early at tokens, in contrast, DRAG and IterDRAG show near-linear improvement as the effective context length grows.

Figure 2 : Evaluation accuracy of Gemini 1.5 Flash using different methods: zero-shot QA, many-shot QA, RAG (with an optimal number of documents), DRAG and IterDRAG on benchmark QA datasets. By scaling up inference compute (up to 5M tokens), DRAG consistently outperforms baselines, while IterDRAG improves upon DRAG through interleaving retrieval and iterative generation.
2. Related Work
2.1 Long-Context LLMs
- 長文脈 LLM は拡張された入力シーケンスを処理するために設計されている
- 初期の研究ではメモリー要件を削減するためのスパース / 低ランクカーネルに焦点を当てていた
- 再帰型モデルや状態空間モデル (SSM) がトランスフォーマーベースのモデルの効率的な代替として提案されている
- 最近の効率的な注意メカニズムの進歩により何百万トークンもの入力シーケンスを処理出来る LLM が可能になった
2.2 In-Context Learning
- 少数のタスク例を条件として与える事で推論時にモデルのパフォーマンスを向上させる計算効率が良いアプローチ
- 文脈内学習を最適化するための事前学習戦略や few-shot 例の選択的使用が研究されている
- 長文脈 LLM の出現により多数の例を用いた in-context 学習が可能になり様々なタスクでのパフォーマンス向上が示されている
2.3 Retrieval Augmented Generation
- 外部ソースからの関連知識を組み込むことで言語モデルのパフォーマンスを向上させる手法
- 検索段階の最適化、文書のエンコーディング、選択的な知識利用などの手法が提案されている
- 長文書の検索やデータストアのスケーリングなど長文脈 RAG のパフォーマンスを最適化する研究が進められている
- しかし知識集約型設定での推論スケーリングはまだ十分に探求されていない領域
3. Inference Scaling Strategies for RAG
3.1 Preliminaries
- 推論計算を「有効文脈長」で測定。これは最終回答を出力する前の全イテレーションにわたる入力トークンの総数と定義
- 出力トークンと検索コストは分析から除外
- 目的は推論計算のスケーリングが RAG のパフォーマンスにどう影響するかを理解する事
3.2 Demonstration-Based RAG (DRAG)
- 長文脈 LLM の能力を活用するため in-context 学習を利用
- 拡張された入力文脈に文書と in-context 例の両方を組み込む
- 単一の推論リクエストで入力クエリーへの回答を生成
- 検索モデルを使って各 in-context 例と実行時クエリーに対してトップ k の文書を選択
- 検索された文書の順序を逆にしランクの高い文書をクエリに近づける

Figure 3 : DRAG vs. IterDRAG. IterDRAG breaks down the input query into sub-queries and answer them to improve the accuracy of the final answer. In test-time, IterDRAG scales the computation through multiple inference steps to decompose complex queries and retrieve documents.
3.3 Iterative Demonstration-Based RAG (IterDRAG)
- 複雑なマルチホップクエリーに対処するためクエリーをより単純なサブクエリーに分解
- 各サブクエリーに対して検索を行い追加の文脈情報を収集
- 中間回答を生成し最終的に全ての情報を統合して最終回答を合成
- サブクエリーと中間回答を含む in-context 例を生成するため制約付きデコーディングを使用
- 推論時には各リクエストでサブクエリー、中間回答または最終回答を生成
- 最大 5 回のイテレーションを許可しテスト時の計算をスケールアップ
4. RAG Performance and Inference Computation Scale
4.1. Fixed Budget Optimal Performance
与えられた推論計算予算
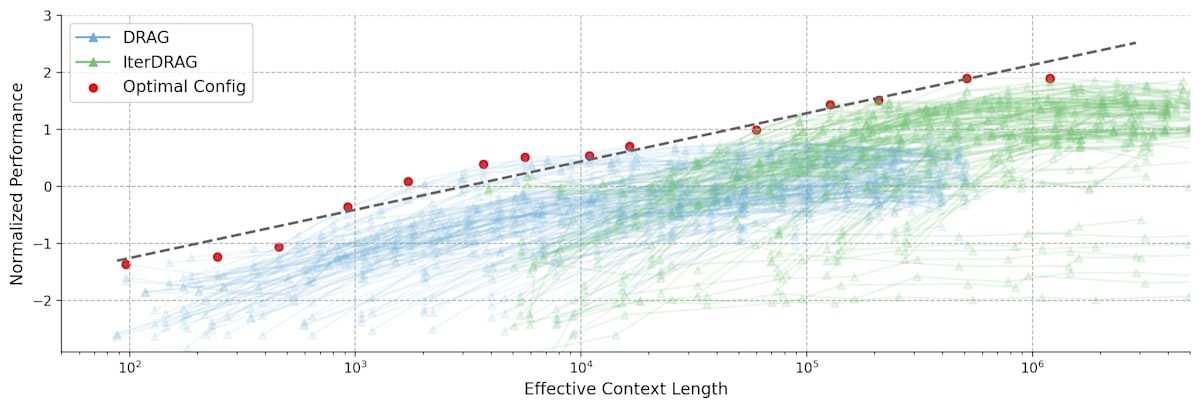
Figure 4 : Normalized performance vs. effective context lengths across datasets. Each line represents a fixed configuration, scaled by varying the number of documents. Red dots indicate the optimal configurations, with the dashed line showing the fitting results. The observed optimal performance can be approximated by a linear relationship with the effective context lengths.
4.2. Overall Performance
Gemini 1.5 Flash モデルを使い複数のデータセットで評価を実施。
- DRAG と IterDRAG は他の手法より優れたスケーリング特性を示す
- DRAG は短い文脈長で優れ IterDRAG は長い文脈長でより効果的にスケール
4.3. Inference Scaling Laws for RAG
有効文脈長増加に伴う性能変化を分析。主な知見は
- 最適性能は推論計算の対数スケールとほぼ線形関係にある
-
10^5 - 1M トークン以降は性能向上が緩やかになる
4.4. Parameter-Specific Scaling
- 文書数増加は一般に大きな性能向上をもたらす
- ショット数増加は IterDRAG でより有効
- DRAG と IterDRAG で飽和点が異なる
- 最適な
\theta
これらの分析から文書数、デモ数、イテレーション数増加は RAG 性能を向上させるが、その寄与は異なる事が判明。最適なハイパーパラメーター組み合わせの特定は依然として課題である
5. Inference Computation Allocation for Long-Context RAG
5.1. Formulation and Estimation
長文脈 RAG のテスト時スケーリング特性をモデル化する計算配分モデルを提案。平均性能メトリック
ここで
5.2. Validating the Computation Allocation Model for RAG
計算配分モデルを評価するため予測メトリックと実際の値を比較
- DRAG について予測値と実際の値が高い一致度を示す
- データセットにより一致度が異なり Bamboogle が最も高く HotpotQA がやや変動大きい
- IterDRAG も同様のトレンドを示すが DRAG より大きな変動がある
アブレーション実験を実施
-
b i \theta - 提案モデルが最も高い
R^2
ドメイン汎化実験
- 未知のドメインでも高い予測精度を示す(最適性能の 96.6% を達成)
長さ外挿実験
- 短い文脈長から長い文脈長への外挿を評価
- 1M トークンまでは高い精度、5M トークンでは予測精度やや低下
これらの結果から提案する計算配分モデルは RAG 性能を正確に予測し様々な知識集約型タスクに適用可能である事が示された
6. Discussion
6.1. Retrieval
- RAG 性能向上に重要な要素は検索文書の質
- 文書数増加に伴い再現率は向上するが NDCG などのランキング指標は飽和
- 100-500 文書で RAG 性能がピークに達する傾向
- 複雑なマルチホップクエリーに対しては再ランキングなど検索精度向上が必要
- IterDRAG の反復検索はシンプルなサブクエリーを用いて追加文脈を収集し再現率を改善
- 文書数増加は必ずしも生成品質向上につながらない事を示唆
6.2. Error Analysis
主な誤り要因を 4 つに分類
- 不正確または古い検索結果
- 推論の誤りまたは欠如
- ハルシネーションまたは不忠実な推論
- 評価問題または回答拒否
これらの分析から
- 検索手法の改善と最新の知識ベース維持が重要
- IterDRAG はマルチホップクエリーに対して効果的
- 忠実な LLM 開発とハルシネーション緩和戦略が必要
- より堅牢で信頼性の高い評価手法が求められる
6.3. Long-Context Modeling
- 文書数増加は一般に RAG 性能向上に寄与
- 単純な文脈長拡張は必ずしも良好な結果をもたらさない
- DRAG は約
10^5 10^6 - 非常に長い文脈(
\geq 10^5 - 大量の「類似」文書から関連情報を識別する能力向上が必要
- 長文脈モデリングを改善し複数の長いデモンストレーションを用いた in-context 学習能力を強化する必要性を示唆
7. Conclusion
本研究は長文脈 RAG における推論スケーリングを探求し以下の主要な成果を得た
- 異なる推論設定下での性能を体系的に調査
- 最適な推論パラメーター下では RAG 性能がテスト時計算量の対数スケールとほぼ線形に向上する事を実証
- この観察に基づき RAG の推論スケーリング則と対応する計算配分モデルを導出
- 広範な実験により最適構成を正確に推定可能で実験結果と密接に一致する事を示した
Appendices
A. Retrieval Quality
- DRAG と IterDRAG の検索品質を評価
- 文書数増加に伴い再現率は向上するが NDCG や MRR は早期に飽和
- IterDRAG は DRAG より高い検索性能を示し、特に複雑なマルチホップクエリーで効果的
B. Chain-of-Thought vs. IterDRAG
- Chain-of-Thought (CoT) と IterDRAG を比較
- IterDRAG が CoT を一貫して上回る性能を示す
- 性能差の要因 : 反復検索の有無、モデルサイズ、例の生成方法の違い
C. Additional RAG Results
- IterDRAG の詳細結果を報告
- 一問一答データセットに対する DRAG の結果も提示
- StrategyQA データセットでの実験結果も含む
D. Additional Results on Inference Scaling Laws for RAG
- データセット固有の結果を提示
- 各データセットで有効文脈長増加に伴う性能変化を視覚化
E. Additional Results on Computation Allocation Model for RAG
- IterDRAG の予測結果を視覚化
- モデルパラメーター推定結果と統計量を報告
- DRAG と IterDRAG の予測曲面を図示
F. Error Analysis
- 主な誤り事例を分類し、詳細に分析
- 検索精度、推論能力、ハルシネーション、評価手法に関する課題を特定
G. Implementation
- 実験設定の詳細を記述
- 文書検索、プロンプト構成、生成プロセスの実装方法を説明
- 計算配分モデルのパラメーター推定手順を詳述
Discussion