DeepSeekMath : Pushing the Limits of Mathematical Reasoning in Open LM
要約
この論文はオープンソース言語モデルの数学的推論能力を向上させる DeepSeekMath を提案している。主な貢献は以下の 2 点
-
スケーラブルな数学プリトレーニング
- Common Crawl から 120B トークンの高品質な数学コーパスを構築
- 7B パラメーターモデルで Minerva 540B と同等のパフォーマンスを達成
- コードトレーニングが数学的推論能力向上に寄与する事を実証
-
効率的な強化学習手法 GRPO を提案
- PPO の Value モデルを不要としグループスコアからベースラインを推定
- メモリー使用量を削減しつつ数学的推論能力を向上
- 教師あり学習済みモデルのパフォーマンスを更に改善
評価結果 :
- MATH ベンチマークで Top1 精度 51.7% を達成(オープンソースモデルで初)
- GSM8K で 88.2%, CMATH で 88.8% など複数のベンチマークで SOTA を達成
- Self-consistency による 64 サンプル評価で MATH 60.9% を達成
実験から得られた知見 :
- コードトレーニングは数学的推論能力向上に有効
- arXiv 論文のトレーニングは予想に反して効果が限定的
- オンライン学習とプロセス監視が強化学習の性能向上に重要
Abstract
コアアーキテクチャー
- DeepSeek-Coder-Base-v1.5 7B をベースに採用
- Common Crawl から抽出した 120B トークンの数学関連データでプリトレーニング
- コードと自然言語データも併用してトレーニング
ベンチマーク性能
- MATH ベンチマークで 51.7% を達成(外部ツールや投票なし)
- 64 サンプル Self-consistency で 60.9% を達成
- GPT-4 や Gemini-Ultra に匹敵する性能を実現
主要な技術的革新点
- データ選択パイプラインの最適化により公開 Web データから高品質な数学コーパスを構築
- Group Relative Policy Optimization (GRPO) を導入
- PPO の変種として設計
- 数学的推論能力を向上
- メモリー使用量を最適化

1. Introduction
大規模言語モデル (LLM) は数学的推論分野において革新的な進展をもたらし定量的推論や幾何学的推論のベンチマークで大きな進歩を遂げている。Tao (2023) が示すように、これらのモデルは複雑な数学問題を解く際の人間支援にも有効だ
しかし GPT-4 や Gemini-Ultra などの最先端モデルは非公開であり現在利用可能なオープンソースモデルはパフォーマンスで大きく劣る
本研究では DeepSeekMath を提案する :
-
Common Crawl から 120B トークンの高品質な数学コーパスを構築
- fastText ベースの分類器を使用
- OpenWebMath をポジティブサンプルとして使用
- 人手によるアノテーションで品質を向上
-
DeepSeek-Coder-Base-v1.5 7B を初期モデルとして採用
- コードトレーニングが一般的な LLM より効果的と判明
- MMLU や BBH ベンチマークでも性能向上を確認
- 数学的能力だけでなく一般的な推論能力も向上
-
Chain-of-thought, Program-of-thought, Tool-integrated reasoning を用いた数学的命令チューニングを実施
-
Group Relative Policy Optimization (GRPO) を導入
- PPO の変種として設計
- クリティックモデル不要でメモリー使用量を削減
- 英語の命令チューニングデータのみで顕著な性能向上を達成
1.1. Contributions
本研究の貢献は以下の 2 つの主要な領域に分類される :
スケーラブルな数学プリトレーニング
- Common Crawl から 120B トークンの DeepSeekMath コーパスを構築
- Minerva データの 7 倍、OpenWebMath の 9 倍の規模を実現
- パラメーター数は重要でない事を証明(DeepSeekMath Base 7B が Minerva 540B と同等の性能)
- コードトレーニングが数学的推論向上に効果的と判明
- arXiv 論文トレーニングは効果が限定的と判明
強化学習の探索と分析
- GRPO (Group Relative Policy Optimization) を提案
- クリティックモデル不要
- グループスコアからベースラインを推定
- メモリー使用量を大幅に削減
- 命令チューニング済みモデルに対する GRPO の有効性を実証
- ドメイン外タスクでの性能向上も確認
- RFT, DPO, PPO, GRPO の統一的な理解枠組みを提供
- オンライン vs オフライン、アウトカム vs プロセス監視など多様な実験を実施
評価メトリクス
-
英語・チャイナ語の数学的推論
- 小学校から大学レベルまでの多様なベンチマークで評価
- テキストベース解答と Python ツール使用の両方で検証
-
形式数学
- miniF2F による非形式から形式への定理証明タスクで評価
- Isabelle プルーフアシスタントを使用
-
言語理解・推論・コーディング
- MMLU, BBH, HumanEval, MBPP で総合的に評価
- 数学プリトレーニングが言語理解と推論能力も向上させる事を確認
1.2. Summary of Evaluations and Metrics
評価は以下の 3 つの主要分野で実施
-
英語・中国語の数学的推論
- 英語ベンチマーク
- GSM8K : 小学校レベルの数学
- MATH : 大学入試レベルの競技数学
- SAT : 大学入学適性試験
- OCW コース
- MMLU-STEM : 科学技術分野の総合評価
- チャイナ語ベンチマーク
- MGSM-zh : GSM8K のチャイナ語版
- CMATH: チャイナ数学問題集
- Gaokao-MathCloze/MathQA : チャイナ高考数学
- テキストベース解答と Python による解法の両方で評価
- 英語ベンチマーク
-
形式数学
- Isabelle プルーフアシスタントを使用
- miniF2F ベンチマークで非形式から形式への定理証明を評価
- Few-shot オートフォーマライゼーション性能を検証
-
一般言語理解・推論・コーディング能力
- MMLU : 57 の多岐選択タスクによる総合評価
- BBH : マルチステップ推論タスク
- HumanEval / MBPP : コーディング能力評価
- 数学プリトレーニングが言語理解と推論能力向上に寄与
2. Math Pre-Training
2.1. Data Collection and Decontamination
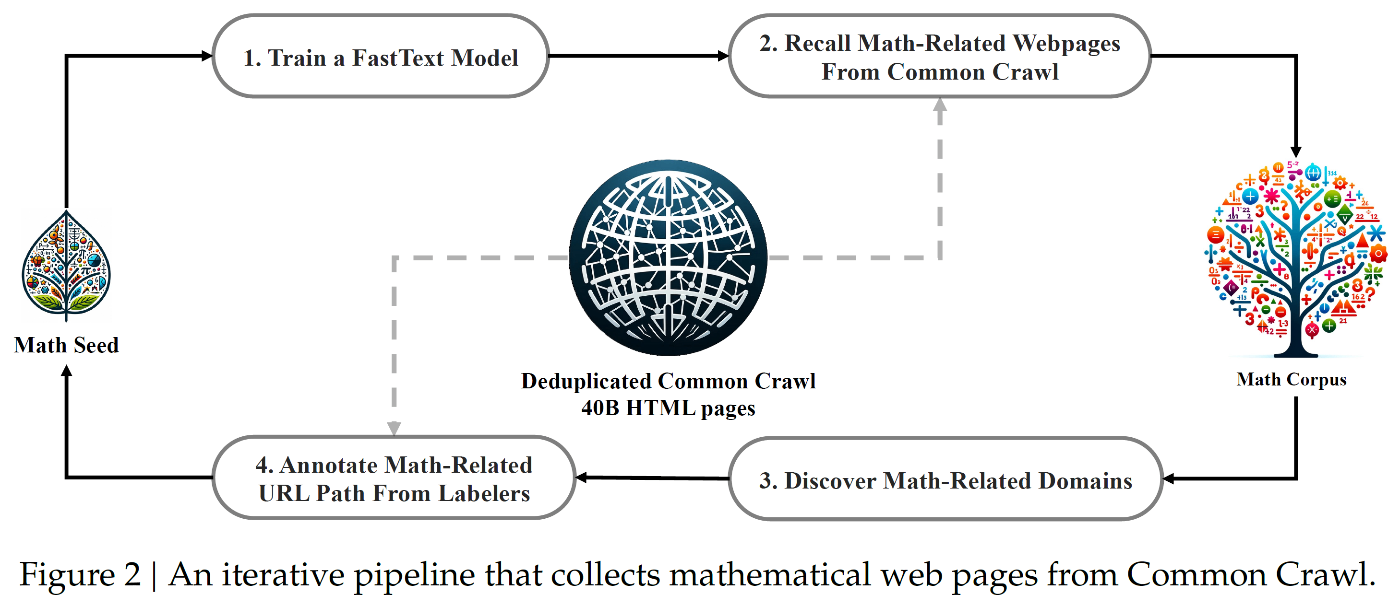
データ収集パイプライン
- OpenWebMath を初期シードコーパスとして利用
- fastText モデルを使用して数学関連 Web ページを収集
- シードコーパスから 50 万件をポジティブサンプル
- Common Crawl から 50 万件をネガティブサンプル
- ベクトル次元 256, 学習率 0.1, 最大 n-gram 長 3 で設定
データ品質向上プロセス
- URL ベースの重複・準重複除去により 40B HTML ページに圧縮
- fastText モデルによるスコアリングとフィルタリング
- イテレーション 1 では上位 40B トークンを保持
- 数学関連ドメインの特定
- ドメイン単位で Web ページを整理
- 収集率 10% 超のドメインを数学関連と分類
- mathoverflow.net などを識別
4 回のイテレーションで収集したデータ
- 総計 35.5M の数学関連 Web ページ
- 120B トークン規模のコーパス
- 3 回目のイテレーションで 98% のデータを収集完了
ベンチマークコンタミネーション防止
- GSM8K, MATH などの英語ベンチマークを除去
- CMATH, AGIEval などのチャイナ語ベンチマークも除去
- 10-gram 一致による厳密なフィルタリング
- 3-gram 以上の短いテキストにも完全一致フィルターを適用
2.2. Validating the Quality of the DeepSeekMath Corpus
構築した DeepSeekMath コーパスを評価するため近年公開された以下の数学トレーニングコーパスと比較検証を実施
比較対象コーパス
-
MathPile(8.9B トークン)
- 教科書、Wikipedia, ProofWiki, CommonCrawl, StackExchange, arXiv から構成
- 85% 以上が arXiv ソース
-
OpenWebMath(13.6B トークン)
- CommonCrawl から数学コンテンツをフィルタリング
-
Proof-Pile-2(51.9B トークン)
- OpenWebMath
- AlgebraicStack(10.3B トークン)
- arXiv 論文(28.0B トークン)
- arXiv : Web : Code = 2:4:1 の比率で構成
これらのコーパスと DeepSeekMath コーパスを用いて事前学習とベンチマーク評価による比較実験を実施
2.2.1. Training Setting
ベースモデル
- DeepSeek-LLM 1.3B を使用
- DeepSeek LLM と同一フレームワーク
トレーニングプロセス
- 各数学コーパスで 150B トークンのトレーニングを実施
- HAI-LLM トレーニングフレームワークを採用
オプティマイザー設定
- AdamW オプティマイザーを使用
-
\beta_1 \beta_2 - weight_decay = 0.1
- マルチステップ学習率スケジュール採用
学習率スケジュール
- 2,000 ステップでウォームアップ後にピーク
- トレーニング 80% 時点で 31.6% まで低下
- 90% 時点でピーク値の 10.0% まで低下
- 最大学習率 = 5.3e-4
バッチサイズ設定
- 4M トークン/バッチ
- コンテキスト長 4K を使用
2.2.2. Evaluation Results
DeepSeekMath コーパスの評価結果を 3 つの主要な特徴で分析
- 高品質
- 8 つの数学ベンチマークで few-shot chain-of-thought プロンプティングによる評価を実施
- Table 1 が示すように DeepSeekMath コーパスで学習したモデルが最高性能を達成
- Proof-Pile-2 の 1 エポック(50B トークン)と較べて高い平均品質を確認
- 多言語対応
- 英語とチャイナ語を主要言語として収録
- Table 1 で示されるように英語・チャイナ語双方のベンチマークで性能向上を確認
- 既存の英語中心コーパスと異なりチャイナ語数学推論でも性能劣化を回避
- 大規模性
- 既存の数学コーパスの数倍の規模を実現
- Figure 3 で示される通り、より急峻な学習曲線と持続的な改善を確認
- 既存コーパスは小規模で複数回の反復学習が必要だがプラトーに早期到達
- DeepSeekMath は大規模データによる継続的な性能向上を実現


2.3. Training and Evaluating DeepSeekMath-Base 7B
トレーニング設定
- DeepSeek-Coder-Base-v1.5 7B を初期モデルに採用
- 500B トークンでトレーニング
- データ分布
- DeepSeekMath コーパス : 56%
- AlgebraicStack : 4%
- arXiv : 10%
- GitHub コード : 20%
- Common Crawl 自然言語 : 10%(英語・チャイナ語)
- 学習率 4.2e-4、バッチサイズ 10M トークン
ベンチマーク評価
-
数学的問題解決能力
- Chain-of-thought プロンプティングによる評価
- 英語・チャイナ語 8 ベンチマークで検証
- 定量的推論と多肢選択問題を包含
- オープンソースモデルで最高性能を達成
- MATH データセットで Minerva 540B を上回る性能
-
Tool-augmented 解法
- Program-of-thought プロンプティングで評価
- GSM8K と MATH で Python コード生成能力を検証
- 先行 SOTA モデル Llemma 34B を上回る性能
-
形式数学
- miniF2F による informal-to-formal 定理証明タスク
- Isabelle プルーフアシスタントで評価
- Few-shot オートフォーマライゼーションで優れた性能
-
一般言語理解・推論・コーディング
- MMLU, BBH, HumanEval, MBPP で総合評価
- Mistral 7B を上回る性能を達成
- 数学プリトレーニングによる一般的な推論能力の向上を確認



3. Supervised Fine-Tuning
3.1. SFT Data Curation
数学的インストラクションチューニングデータセットを以下の構成で作成 :
データセット規模
- 総トレーニング例 : 776K
- 複数の数学分野と難易度をカバー
- Chain-of-thought, Program-of-thought, Tool-integrated reasoning の 3 フォーマットで解答を提供
英語データセット
- GSM8K, MATH を Tool-integrated ソリューションで注釈付け
- MathInstruct の一部を採用
- Lila-OOD トレーニングセットを CoT / PoT フォーマットで使用
- 代数、確率論、数論、微積分、幾何学など幅広い分野をカバー
チャイナ語データセット
- K-12 数学問題を収集
- 76 のサブトピックで構成
- 線形方程式などの基本概念を網羅
- CoT と Tool-integrated reasoning の両フォーマットで注釈付け
3.2. Training and Evaluating DeepSeekMath-Instruct 7B
トレーニング設定
- DeepSeekMath-Base ベースで数学的インストラクションチューニングを実施
- コンテキスト長 4K トークンでランダム連結
- バッチサイズ 256, 学習率 5e-5 で 500 ステップ実行
ベンチマーク比較対象
クローズドソースモデル
- GPT4 ファミリー (GPT-4, GPT-4 Code Interpreter)
- Gemini (Ultra, Pro)
- Inflection-2, Grok-1
- Baichuan-3, GLM-4
オープンソースモデル
- 汎用モデル
- DeepSeek-LLM-Chat 67B
- Qwen 72B
- SeaLLM-v2 7B
- ChatGLM3 6B
- 数学特化モデル
- InternLM2-Math 20B
- Math-Shepherd-Mistral 7B
- WizardMath シリーズ
- MetaMath 70B
- ToRA 34B
- MAmmoTH 70B
評価結果
- MATH データセットで約 60% 精度を達成
- Tool-integrated 解法でオープンソースモデル最高性能を記録
- DeepSeek-LLM-Chat 67B と同等の性能を 7B モデルで実現
- Chain-of-thought 解法で MATH データセット 46.8% を達成
- オープンソースモデルとチャイナプロプライエタリーモデルを上回る性能を確認

4. Reinforcement Learning
4.1. Group Relative Policy Optimization
強化学習 (RL) は教師あり学習 (SFT) 後の LLM 数学的推論能力を効果的に向上させる事が実証済みである。本セクションでは、より効率的な RL アルゴリズム Group Relative Policy Optimization (GRPO) を提案する
4.1.1. From PPO to GRPO
PPO の目的関数を以下の式 (1) で定義する :
ここで :
-
\pi_\theta \pi_{\theta_{old}} -
q o -
\epsilon -
A_t -
|o|
基本アーキテクチャー
- PPO はアクター・クリティック型 RL アルゴリズム
- サロゲート目的関数を最大化
- KL ダイバージェンスによるペナルティーを導入
GRPO の主要な改良点
- バリュー関数を排除
- グループスコアによるベースライン推定
- メモリー使用量を大幅に削減
- トークン単位の KL ペナルティーを損失関数に直接追加
技術的特徴
- 1 ステップ更新を想定した近似アプローチ
- 同一クエリーに対する複数出力をグループ化
- グループ内相対評価でアドバンテージを計算
- リファレンスモデルとの KL ダイバージェンスを正規化項として使用
改善ポイント
- 最終トークンのみ報酬が与えられる LLM 特性に対応
- バリュー関数学習の複雑さを回避
- 分散削減にグループ統計量を活用
報酬関数は以下の式 (2) で表現される :
ここで :
-
r_\varphi -
\pi_{ref} -
\beta -
o_{\leq t} -
o_{<t}
GRPO の目的関数は以下の式 (3) で定義される :
ここで :
-
\epsilon \beta -
\hat{A}_{i,t} -
G -
D_{KL}
KL ダイバージェンスの不偏推定値を以下の式 (4) で表す:
この推定値は以下の特徴を持つ:
- Schulman (2020) による不偏推定量を採用
- 常に正の値を保証
- KL ダイバージェンスのバイアスなし計算を実現
- リファレンスモデルとトレーニングポリシー間の差異を定量的に評価

4.1.2. Outcome Supervision RL with GRPO
アーキテクチャー設計
- ポリシーモデル
\pi_{\theta_{old}} q G - リワードモデルで各出力をスコアリング
\{r_1, r_2, ..., r_G\} - グループ平均と標準偏差による正規化を実施
アドバンテージ計算
- 出力
o_i - すべてのトークンに同一アドバンテージ
\hat{A}_{i,t} - 正規化報酬:
\tilde{r}_i = \frac{r_i - mean(r)}{std(r)}
最適化プロセス
- 式 (3) で定義される目的関数を最大化
- グループ単位での相対的評価を実現
- 出力全体の品質を単一スコアで評価
4.1.3. Process Supervision RL with GRPO
入力処理
- クエリー
q G \{o_1, o_2, ..., o_G\} - プロセスリワードモデルで各ステップを評価
- リワード系列 :
R = \{\{r^{index(1)}_1, ..., r^{index(K_1)}_1\}, ..., \{r^{index(1)}_G, ..., r^{index(K_G)}_G\}\}
リワード正規化
-
index(j) j -
K_i i - グループ全体の平均と標準偏差で正規化:
\tilde{r}^{index(j)}_i = \frac{r^{index(j)}_i - mean(R)}{std(R)}
アドバンテージ計算
- 各トークンのアドバンテージは後続ステップの正規化リワード総和
\hat{A}_{i,t} = \sum_{index(j) \geq t} \tilde{r}^{index(j)}_i - 式 (3) の目的関数を最大化
4.1.4. Iterative RL with GRPO
トレーニングサイクル
- ポリシーモデルからサンプリングした結果でリワードモデル学習データを生成
- 履歴データ 10% を含むリプレイメカニズムでリワードモデル更新
- リファレンスモデルをポリシーモデルに設定
- 新リワードモデルでポリシー更新を継続
アルゴリズム構成
- 初期ポリシーモデル
\pi_{\theta_{init}} r_\phi - タスクプロンプト
D \epsilon \beta \mu - 各イテレーションで参照モデルを更新し GRPO 最適化を実行
- グループ相対アドバンテージ推定による効率的な学習を実現
主要な特徴
- リワードモデルと参照モデルの継続的更新によるパフォーマンス向上
- 効率的なグループ単位評価システム
- リプレイバッファによる安定的な学習
- オンラインアプローチによる適応的な最適化

4.2. Training and Evaluating DeepSeekMath-RL
トレーニング設定
- DeepSeekMath-Instruct 7B をベースモデルに採用
- チェーン・オブ・ソート形式の GSM8K / MATH 問題 144K を使用
- SFT データを除外し RL 効果の純粋な評価を実施
- Wang et al. (2023b) に基づくリワードモデル構築
パラメーター設定
- 学習率 : リワードモデル 2e-5、ポリシーモデル 1e-6
- KL 係数 : 0.04
- サンプル数 : クエリ毎に 64 出力
- 最大長 : 1024 トークン
- バッチサイズ : 1024
評価結果
- GSM8K : チェーン・オブ・ソートで 88.2% 達成
- MATH : チェーン・オブ・ソートで 51.7% 達成
- すべてのベンチマークで DeepSeekMath-Instruct を上回る
- オープンソースモデル中で最高性能を記録
- 多くのクローズドソースモデルを超える性能を実現
注目点
- 限定的な学習データでも広範な性能向上を達成
- ドメイン外タスクでも一貫した改善を確認
- シンプルな実装での高い汎化性能を実証
5. Discussion
5.1. Lessons Learnt in Pre-Training
5.1.1. Code Training Benefits Mathematical Reasoning
コードトレーニングの効果
- DeepSeek-LLM 1.3B を用いた評価を実施
- コードトレーニング後の数学トレーニングが最も高い性能を達成
- プログラム補助型数学推論でも優位性を確認
- コードとの混合トレーニングは特に有効
手法比較
-
Two-Stage トレーニング
- コード 400B トークン + 数学 150B トークンが最良
- 汎用データよりコードデータの優位性を確認
-
One-Stage トレーニング
- コードと数学の混合トレーニングにより忘却を防止
- 数学的推論とコーディング能力の同時向上を実現


5.1.2. ArXiv Papers Seem Ineffective in Improving Mathematical Reasoning
arXiv データの効果検証
- DeepSeek-LLM 1.3B で 150B トークンの実験
- DeepSeek-Coder-Base-v1.5 7B で 40B トークンの実験
- MathPile と ArXiv-RedPajama を評価
- 予想に反し数学的推論の改善は限定的
制約事項
- 特定の数学タスクへの影響は未検証
- 他のデータ種との組み合わせ効果は未評価
- 大規模モデルでの効果は今後の課題


5.2. Insights of Reinforcement Learning
5.2.1. Towards to a Unified Paradigm
学習手法の統一的パラダイムを以下の枠組みで整理
パラメータ θ に関する勾配式 (5)
統一的パラダイムのトレーニング手法に対する勾配を以下の式で表現 :
構成要素:
-
\mathcal D -
GC_{\mathcal A} -
\pi_{rf} -
\pi_\theta -
q -
o -
t
3 つの主要コンポーネント
-
データソース
\mathcal D - トレーニングデータ分布を決定
- サンプリング戦略に影響
-
リワード関数
\pi_{rf} - トレーニング信号のソース
- 品質評価の基準を提供
-
アルゴリズム
\mathcal A - データとリワード信号を処理
- 勾配係数
GC - ペナルティーまたは強化の度合いを制御
代表的手法の位置付け
- SFT : 人手選択データで微調整
- RFT : SFT モデルからサンプル生成し正解出力で学習
- DPO : SFT モデルから生成した出力を選好学習で改善
- PPO / GRPO : リアルタイムポリシーから生成した出力で強化学習



5.2.2. Why RL Works?
実験内容
- SFT データのサブセットで RL を実施
- Pass@K と Maj@K で評価
- SFT / RL モデルのパフォーマンスを比較
主要な発見
- RL は Maj@K を向上させるが Pass@K は改善せず
- TopK からの正解抽出能力が向上
- 基本的な能力向上よりも出力分布の頑健性に貢献
理論的解釈
- Wang et al. (2023a) が指摘する SFT モデル推論タスクでミスアライメントを確認
- Song et al. (2023), Yuan et al. (2023b) 提案の選好アラインメント戦略と整合性
結論
- RL は出力分布の調整により性能を向上
- 基礎的能力の向上ではなく正解パターン強化に寄与
- 選好アラインメントと同様のメカニズムで機能

5.2.3. How to Achieve More Effective RL?
RL 高効率化への 3 つのアプローチ
- データソース最適化
- SFT クエリーと naive なサンプリング以外を検討
- 分布外 (OOD) クエリープロンプトへ展開
- Tree-search ベース高度サンプリング手法
- 効率的推論手法による探索性能向上
- アルゴリズム改良
- リワード信号完全依存から脱却
- ノイズを含むリワード信号への耐性獲得
- PRM800K データセットでも 20% のエラーが存在
- Weak-to-Strong アライメント手法による根本的改善
- リワード関数の発展
- 汎化性能向上 : OOD クエリーと高度サンプリング対応
- 不確実性を反映 : 弱リワードモデルと橋渡し
- プロセス報酬モデル : 細粒度トレーニング信号を提供
- リワードモデル信頼性とアルゴリズム改善による相乗効果
6. Conclusion, Limitation, and Future Work
主な成果
- オープンソース LLM で MATH ベンチマーク最高性能を達成
- Common Crawl から 120B トークン規模の高品質数学コーパスを構築
- GRPO による効率的な強化学習フレームワークを確立
- 少ないメモリー消費で数学的推論能力を向上
技術的制約
- 幾何学と定理証明タスクのパフォーマンスが課題
- 三角形や楕円関係の問題で弱点を露呈
- プリトレーニングとファインチューニングのデータ選択バイアス
- モデルスケールによる few-shot 能力の制限
今後の展開
- データ選択パイプラインの改良により高品質コーパスを拡充
- 5.2.3 で提案した強化学習の効率化手法を実装
- 幾何学的推論能力の向上に向けたデータ収集を強化
- より大規模なモデルでの few-shot 性能向上を検討
Discussion