Large Language Diffusion Models
要約
この論文は Large Language Diffusion Models (LLaDA) を提案し、従来の自己回帰モデル (ARM) に代わる新しい言語モデルのアプローチを示している
主な特徴 :
- マスク拡散モデルをベースにトークンの段階的なマスキングと予測を行う
- 8B パラメーターまでスケールし LLaMA3 8B と同等の性能を達成
- トレーニングは事前学習と教師あり微調整 (SFT) の 2 段階で構成
- 2.3 兆トークンで事前学習を実施し 450 万ペアのデータで SFT を実施
評価結果 :
- 一般タスク、数学、コード生成、チャイナ語理解など多岐に亘るベンチマークで検証
- in-context learning や instruction following などの重要な LLM 機能を実現
- 特に reversal curse の克服において優位性を示し GPT-4o を上回る性能を達成
技術的な特徴 :
- 双方向モデリングにより文脈理解が向上
- サンプリング時に low-confidence remasking や semi-autoregressive remasking を採用
- vanilla Transformer をベースに KV キャッシングを使わない設計を採用
本研究は LLM において ARM が唯一の選択肢ではない事を示し拡散モデルベースのアプローチが有効な代替手段となり得る事を実証した。特に双方向性や reversal reasoning において優位性を持つ事が示された
Abstract
本研究は Autoregressive Model (ARM) に依存しない新しい LLM アーキテクチャーとして LLaDA を提案する
以下が主要な特徴 :
- 事前学習と SFT パラダイムのもと、拡散モデルをベースに開発
- フォワードプロセスでデータをマスキングし、リバースプロセスで予測を行う
- バニラ Transformer を用いてマスクされたトークンを予測
- 尤度最大化に基づく確率的生成アプローチを採用
評価実験では :
- スケーラビリティーの高さを実証
- 自己構築した ARM ベースラインを上回る性能を達成
- 特に LLaDA 8B は LLaMA3 8B と同等の in-context learning 能力を示す
- SFT 後は multi-turn 対話などの instruction following に優れた性能を発揮
- reversal curse を克服し GPT-4o を上回る性能を達成
これらの結果は diffusion モデルが LLM における有効なアプローチとなる事を示す
1. Introduction
大規模言語モデル (LLM) は生成モデリングの枠組みに完全に属する。具体的には KL ダイバージェンスの最小化または尤度最大化を通じて真の分布
現在の主流アプローチは自己回帰モデリング (ARM) に基づき以下の形式でモデル分布を定義する(式 2)
この方式は効果的である事が証明され、現代の LLM の基盤となっている。しかし根本的な疑問が残されている
「自己回帰方式は LLM の知能を実現する唯一の方法なのか?」
著者らは答えは No だと主張する。重要な洞察は :
-
LLM の本質的な性質を支えているのは自己回帰形式ではなく生成モデリングの原理である
-
スケーラビリティーは以下の要素の相互作用による :
- Transformer アーキテクチャー
- モデルとデータのサイズ
- 生成原理がもたらす Fisher 一貫性
-
instruction following や in-context learning は構造的に一貫した言語タスクにおける条件付き生成モデルの本質的な性質である
従って著者らは LLaDA (Large Language Diffusion with mAsking) を提案し、拡散モデルベースの新しいアプローチを提示する。このモデルは :
- マスク拡散モデルを採用
- 事前学習と SFT パラダイムに基づく
- 双方向の依存関係を構築可能
- 尤度の下界を最適化する
これにより LLM の重要な機能を ARM に依存せずに実現する事が出来る

2. Approach
2.1. Probabilistic Formulation
LLaDA は式 (2) の ARM とは異なり、フォワードプロセスとリバースプロセスを通じてモデル分布
フォワードプロセス:
-
x_0 t - 時刻
t \in (0,1) x_t t -
t = 1
リバースプロセス:
-
t - マスク予測器
p_{\theta}(\cdot|x_t) -
x_t - マスクトークンのみに対してクロスエントロピー損失を計算
-
学習目的関数(式 3):
ここで :
-
x_0 -
t [0,1] -
x_t -
\bm{1}[\cdot]
この損失関数は以下の不等式を満たす(式 4):
従って
2.2. Pre-training
LLaDA は以下の特徴を持つ事前学習を実施
アーキテクチャー :
- Transformer ベースのマスク予測器を採用
- 因果マスクを使わず双方向の文脈理解が可能
- 通常の Multi-head アテンションを使用(LLaDA は KV キャッシングと非互換なため)
- 標準的な LLM と同様のアーキテクチャーを採用
モデルサイズ :
- 1B と 8B パラメーターの 2 種類を訓練
- 8B モデルの構成は LLaMA3 8B と同等に設定
- FFN 次元を調整し総パラメーター数を維持
データセット :
- 2.3 兆トークンで訓練
- 一般テキスト、コード、数学、多言語データを含む
- 低品質データはルールベースと LLM ベースのフィルタリングで除去
学習設定 :
- シーケンス長 4096 トークン
- 1% の確率で可変長シーケンス (1-4096) を使用
- AdamW オプティマイザー (weight decay 0.1)
- バッチサイズ 1280(GPU あたり 4)
- Warmup-Stable-Decay スケジューラーを採用
- 最初の 2000 イテレーションで学習率を 0 から 4e-4 まで線形増加
- 1.2T トークン処理後に 1e-4 に減衰
- 最後の 0.3T トークンで 1e-5 まで線形減衰
計算コスト :
- H800 GPU で 0.13 million GPU hours を使用
- 同スケールで同データセットサイズの ARM と同等
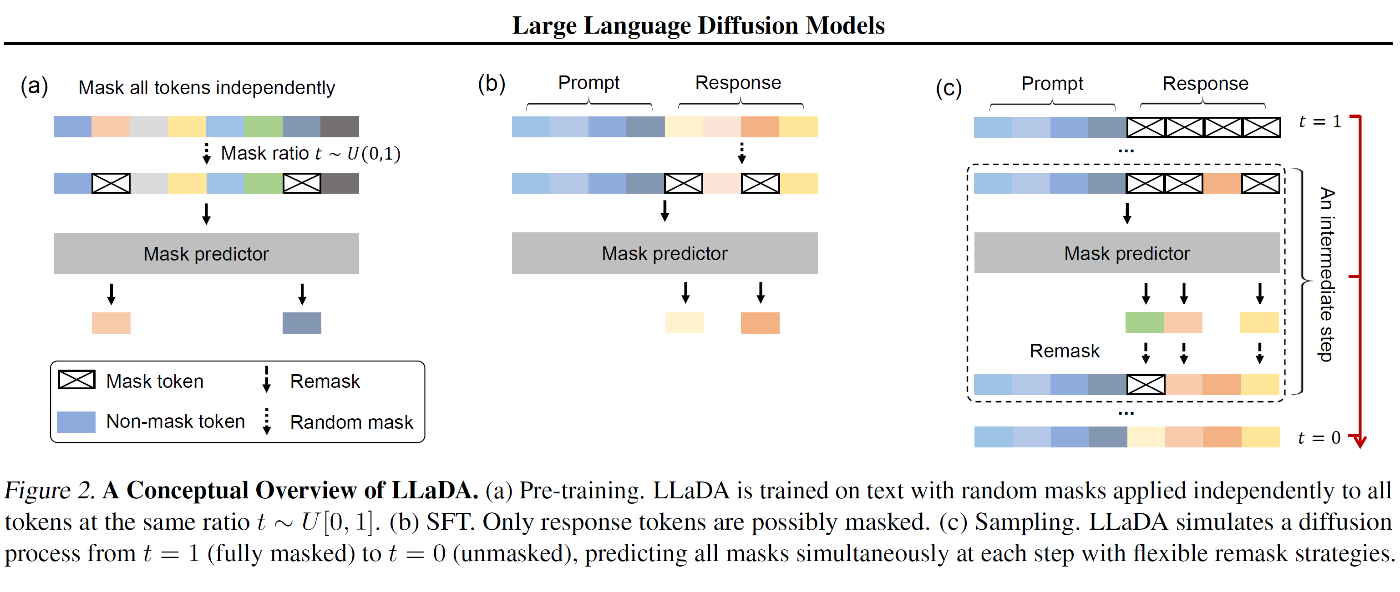
2.3. Supervised Fine-Tuning
LLaDA の Supervised Fine-Tuning (SFT) は以下のアプローチを採用
データ処理 :
- プロンプト-レスポンス ペア
(p_0,\ r_0) - 短いペアには |EOS| トークンを追加しバッチ内の長さを統一
- |EOS| はレスポンスの一部として扱いマスク対象に含める
- 生成時は |EOS| を除去し応答長を自動制御
学習目的 :
- 事前学習モデル
p_{\theta}(x_0) p_{\theta}(r_0|p_0) - プロンプトは不変に保持しレスポンスのみマスク対象とする
損失関数(式 5):
訓練設定 :
- 4.5M ペアのデータセットを使用
- コード、数学、指示応答、構造化データ理解など多様なドメインを含む
- 3 エポックの訓練を実施
- 学習率は 2.5e-5 から開始し最後の 10% で 2.5e-6 まで線形減衰
- weight decay 0.1
- グローバルバッチサイズ 256(GPU あたり 2)
マルチターン対話をデータ変換 :
- n ターンの対話を n 個の単一ターン対話ペアに分割
- 履歴を含むプロンプトと現在のレスポンスをペアとして構成
- このアプローチはパディング戦略と整合性を持つ
2.4. Inference
LLaDA における推論は以下の 2 つのアプローチを提供
サンプリング :
- 完全マスクされた系列から開始し
t = 1 t = 0 - サンプリングステップ数はハイパーパラメーター
- 一様分布のタイムステップを使用
- 生成長は事前に指定する必要がある
中間ステップにおける遷移 :
-
t \in (0,1] s \in [0,t) - マスク予測器がマスクトークンを同時予測
- 予測トークンの
\dfrac{s}{t} r_s - リマスク戦略として以下を検討
- 低信頼度リマスク : 予測信頼度が低いトークンを優先的にマスク
- 半自己回帰リマスク : 系列を左から右へブロック単位で生成
条件付き尤度評価 :
- 式 (5) の上界を直接使用可能
- より低分散な等価形式を採用(式 6):
ここで :
-
l \{1,2,...,L\} -
r_l r_0 l
Unsupervised Classifier-free Guidance も利用可能
3. Experiments
3.1. Scalability of LLaDA on Language Tasks
LLaDA のスケーラビリティー評価について以下の実験を実施
ベースライン比較 :
- 1B スケールで同一アーキテクチャー / データの ARM を構築
- 計算リソース制約により 8B スケールは若干異なるサイズで比較
- 統一的なスケーリング指標として計算コストを使用
評価タスク :
- MMLU, ARC-C, CMMLU, PIQA, GSM8K, HumanEval の 6 タスクを選定
- 各タスクで異なる計算量に対するパフォーマンスを測定
実験結果 :
- LLaDA は ARM と同等のスケーリング傾向を示す
- MMLU と GSM8K では ARM を上回るスケーラビリティーを実現
- PIQA では初期で性能差があるものの大規模化で差が縮小
- 外れ値の影響を考慮し定量的なスケーリング曲線のフィッティングは回避
先行研究との比較 :
- Nie et al. (2024) では MDM は ARM の 16 倍の計算量を要求
- 本研究では下流タスクで競争力のあるスケーリングを実証
- スケーリング範囲を
10^{20} \sim 10^{23}

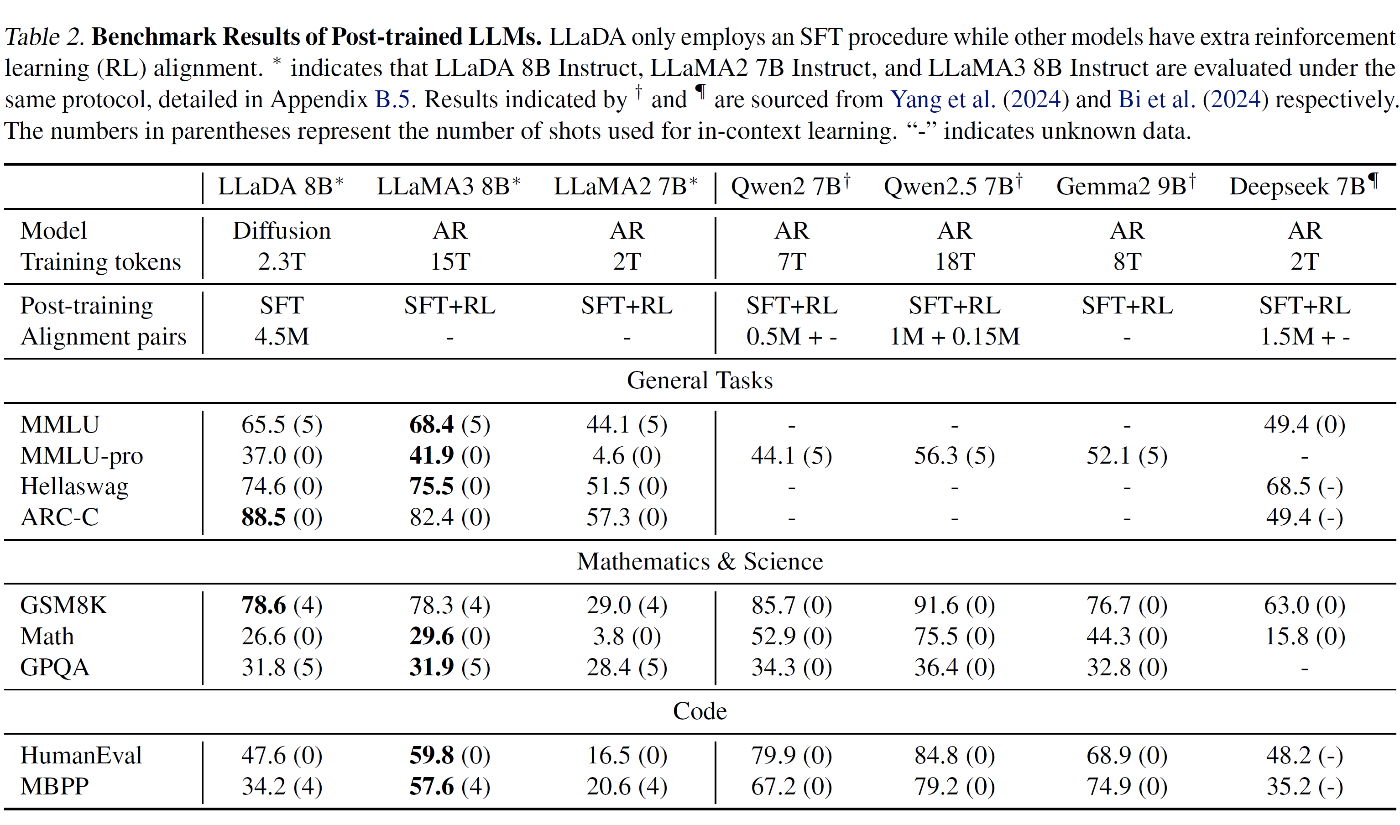
3.2. Benchmark Results
LLaDA 8B のベンチマーク評価結果を以下に示す
事前学習モデルの評価 :
- LLaMA2 7B をほぼ全タスクで上回り LLaMA3 8B と競争力ある性能を達成
- 数学とチャイナ語タスクで特に優位性を示す
- データ漏洩を防ぐため GSM8K を詳細分析し優位性を検証
- データ品質と分布の違いにより一部タスクでは劣る
SFT 後の評価 :
- 大部分のタスクでパフォーマンスが向上
- MMLU など一部メトリクスで低下が見られ SFT データ品質に起因する可能性
- 強化学習による Alignment を未実施のため LLaMA3 8B Instruct には若干劣る
- instruction following で高い能力を示す
評価プロトコル :
- 15 種の標準ベンチマークを使用
- 一般タスク、数学、コード生成、チャイナ語理解を網羅
- 同等規模の既存 LLM と同一条件で比較を実施
- 代表的な LLM を同一実装で再評価し公平な比較を実現

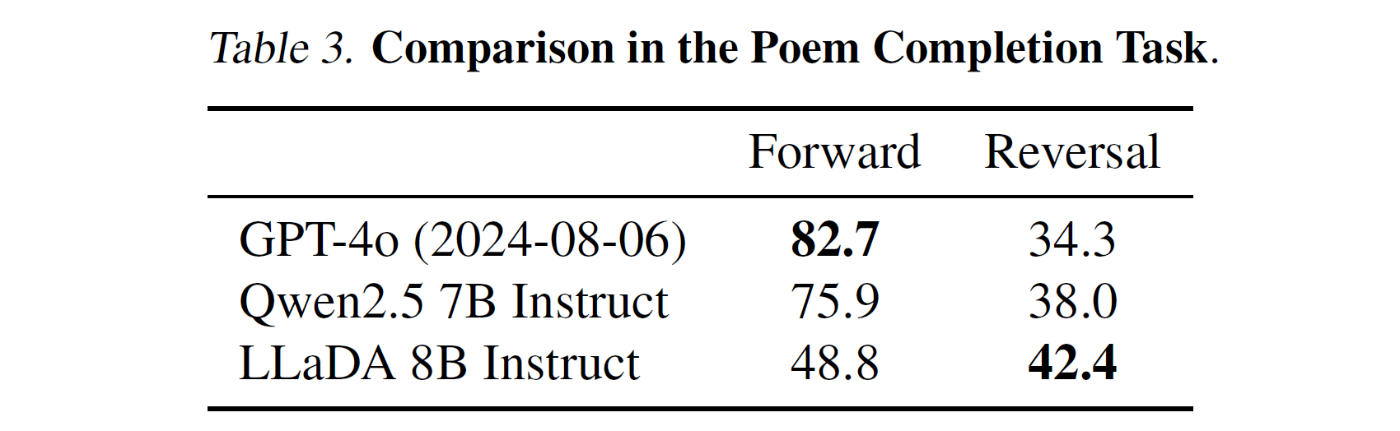
3.3. Reversal Reasoning and Analyses
LLaDA の Reversal 推論能力について以下の評価を実施
検証手法 :
- Allen-Zhu & Li (2023) のプロトコルに基づく評価
- 496 個の著名なチャイナ語詩のペアを使用
- Forward タスク : 次の行を生成
- Reversal タスク : 前の行を生成
- GSM8K 形式に準拠した評価方式を採用
実験結果 :
- Forward 生成 : GPT-4o 82.7%, Qwen2.5 7B 75.9%, LLaDA 8B 48.8%
- Reversal 生成 : GPT-4o 34.3%, Qwen2.5 7B 38.0%, LLaDA 8B 42.4%
- LLaDA は方向による性能差が最小であり Reversal Curse を効果的に克服
- 大規模なデータセットと計算リソースを活用した ARM は Forward で優位
- Reversal タスクでは LLaDA が両モデルを大幅に上回る性能を達成
技術的特徴 :
- トークンを均一に扱い方向性バイアスを排除
- 詳細な理論的背景は Appendix A.2 に記載
- リマスク戦略とサンプリングステップの影響は Appendix B.3, B.6 で分析
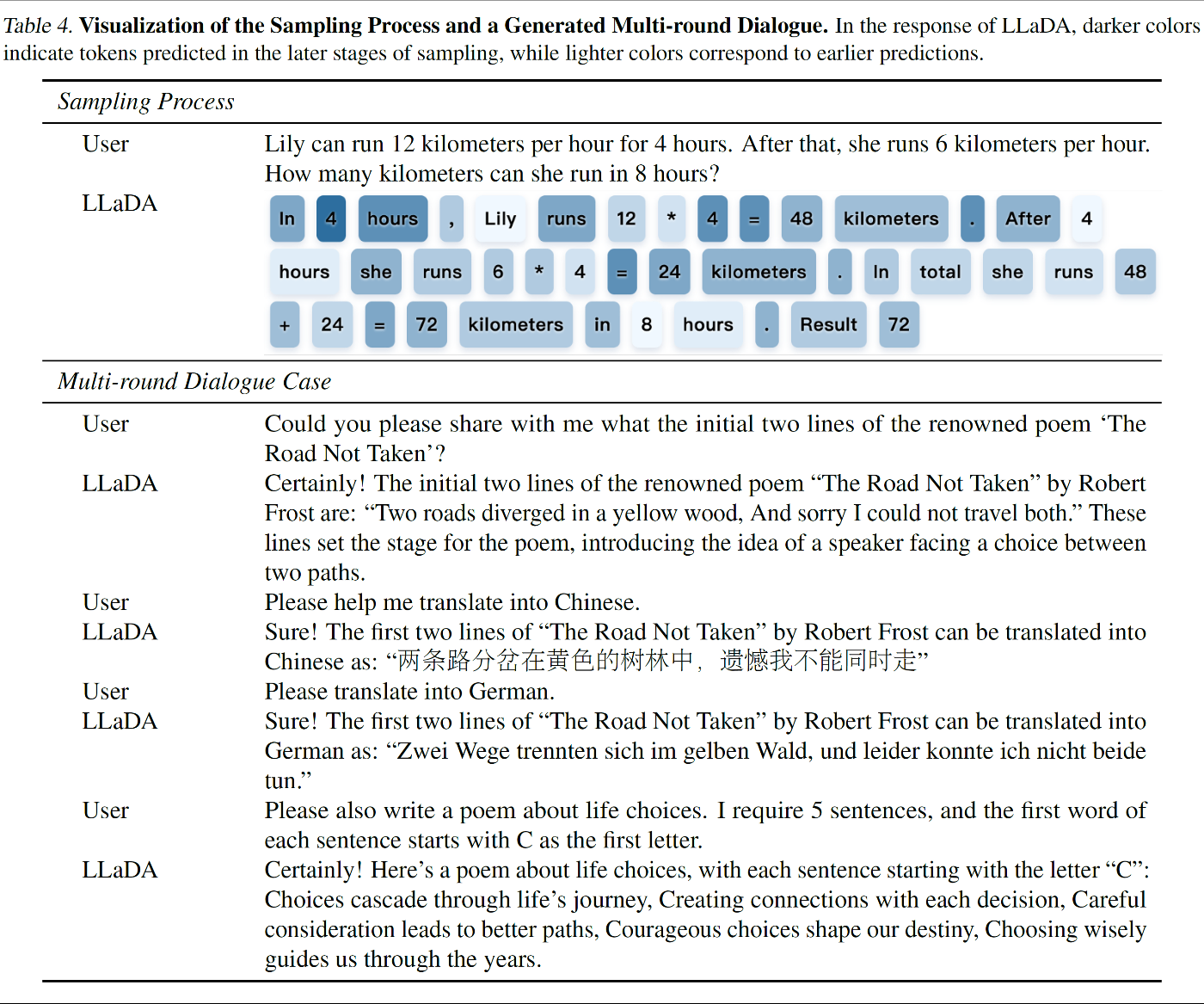
3.4. Case Studies
LLaDA 8B Instruct のケーススタディーを以下に示す
テキスト生成機能 :
- 非自己回帰方式による一貫性のある流暢なテキスト生成を実証
- マルチターン対話で文脈理解と適切な応答生成を確認
- 複数言語に対応した対話能力を実現
検証項目 :
- セミオートレグレッシブ・リマスキングを用いたテキスト生成プロセス
- 文脈を保持したマルチターン対話の生成品質
- 多言語対話における応答一貫性
評価結果 :
- 非自己回帰モデルで初めて効果的なチャット機能を実装
- 複数ターンにわたる文脈理解と応答生成を確認
- 言語横断的な対話能力を検証
追加事例 :
- リマスキング戦略の詳細分析を Appendix B.9 に記載
- 推論タスクにおけるケーススタディーを補足資料で提示
4. Related Work
テキストデータに対する拡散モデルのアプローチは以下 3 種に分類される
連続化アプローチ :
- テキストデータを連続空間に変換
- 標準的な拡散モデルを適用
- 1B パラメーターモデルで ARM の 64 倍の計算コストが必要
- スケーラビリティーに課題
離散分布アプローチ :
- 離散分布のパラメーターを連続値としてモデル化
- バリアントとして前方・後方の新しいダイナミクスを採用
- データ分布のパープレキシティーを ARM と同等以上に改善
マスク拡散アプローチ :
- 離散拡散の特殊ケースとしてマスク拡散を採用
- Lou et al. (2023) が GPT-2 スケールでの有効性を実証
- Ou et al. (2024) が理論的基盤を確立
- Nie et al. (2024) が Question Answering への応用を検証
- Gong et al. (2024) が ARM の微調整に MDM を活用
本研究の特徴 :
- 8B パラメーターへのスケーリングを実現
- スクラッチからの学習で LLaMA 3 と同等の性能を達成
- Chang et al. (2022, 2023) の画像生成研究と並行した知見を提供
5. Conclusion and Discussion
LLaDA の主要な研究成果を以下にまとめる
主要な貢献 :
- 拡散モデルを基盤とする新しい言語モデリングアプローチを確立
- スケーラビリティーと in-context learning の能力を実証
- instruction following で従来の LLM と同等の性能を達成
- 双方向モデリングと堅牢性で ARM の制約を克服
現状の制約 :
- 計算リソース制約により ARM との直接比較は 1023 FLOP 未満に限定
- 専用のアテンションメカニズムや位置エンコーディングは未実装
- システムレベルのアーキテクチャー最適化は未実施
- 推論時のガイダンスメカニズムは初期段階
- 強化学習による alignment は未実施
今後の展望 :
- より大規模なモデルへのスケーリング
- マルチモーダルデータ処理への応用
- プロンプトチューニング手法の体系的研究
- エージェントベースシステムへの統合
- O1-like システムに向けたポストトレーニング手法の開発
研究の意義 :
- 自己回帰モデリングの優位性に対する再考を促進
- 確率的パラダイムの新たな可能性を提示
- 言語モデルの制約克服に向けた新しい方向性を提案
Impact Statement
LLaDA の研究がもたらすインパクトを以下に示す
主要な貢献 :
- LLM における自己回帰モデリングの支配的地位への問題提起
- 拡散ベースの代替アプローチによる新しい可能性の提示
- 自然言語処理分野における確率的パラダイムの多様化を促進
潜在的な懸念事項 :
- 大規模トレーニングによる環境負荷
- 有害またはミスリーディングなコンテンツ生成の可能性
- トレーニングデータに含まれるバイアスの増幅リスク
社会的影響 :
- 会話型 AI システムへの応用
- コード生成タスクへの展開
- 複雑な推論タスクへの適用
これらの課題に対し、以下のアプローチが必要
対応策 :
- 環境負荷の定量的評価と削減
- コンテンツ生成の品質管理メカニズム導入
- データセットのバイアス検出と緩和手法の開発
開発・展開における責任ある取り組みが拡散ベース言語モデルの健全な発展に不可欠
A. Formulation of Masked Diffusion Models
A.1. Training
マスク拡散モデル (MDM) の学習プロセスを以下に示す
フォワードプロセス定式化 :
- 時刻
t \in [0,1] \{x_t\} - 全トークンの確率的マスキングを導入
- 条件付き分布を全因子化形式で記述(式 7):
マスキング確率設定(式 8):
リバースプロセス構成 :
- 時刻
s t
条件付き分布の詳細定義(式 10):
時間非依存パラメータ化(式 11):
損失関数定義(式 12):
理論的保証 :
- モデル分布の負の対数尤度に対する上界を確立(式 13):
実装アプローチ :
- マスク予測器をバニラ Transformer で構築
- マスクトークンの同時予測を実現
- リバースプロセスでモデル分布を定義
A.2. Inference
MDM における推論の 2 つの等価な定式化を説明
クロスエントロピー損失の等価形式(式 14):
ここで :
-
l \{1,2,...,L\} -
x_l x_0 l
分散に関する考察 :
- 式 (12) では
x_t t - フォワードプロセスのランダム性により実際のマスク数は変動
- 式 (14) では
x_l l/L - 経験的に式 (12) は 1000 以上、式 (14) は 128 のモンテカルロ推定で安定化
条件付き生成への拡張 :
- 式 (14) から式 (6) への直接的な拡張が可能
- データ分布に依存する理論的分析は今後の課題
Any-order オートレグレッシブモデルとの関連 :
- すべての順序
\pi
- マスクトークンを用いた欠損変数表現
- 式 (12) との等価性を理論的に証明可能
- 双方向推論能力の理論的根拠を提供
Unsupervised Classifier-free Guidance:
- 修正マスク予測器(式 16):
-
m p_0 -
w
A.3. Algorithms
LLaDA のアルゴリズムを以下にまとめる
Algorithm 1 : Pre-training
- マスク予測器
p_\theta p_{data} - 1% の確率でシーケンス長を
U[1,4096] - フォワードプロセスでトークンをマスク化
- クロスエントロピー損失を計算し最適化

Algorithm 2 : Supervised Fine-Tuning
- プロンプト-レスポンスペアを使用
- レスポンス部分のみをマスク化
- 条件付き生成のための損失関数を最適化
- 収束までトレーニングを継続

Algorithm 3 : 条件付き対数尤度評価
- モンテカルロ推定回数
n_{mc} - シーケンス長
L - マスクトークンに対する対数尤度を計算
- 複数回の推定値を平均化

Algorithm 4 : リバースプロセス
- 完全マスク系列から開始
- グリーディーサンプリングでマスクを予測
- 線形スケジュールで確率的リマスキング
-
t = 0

Algorithm 5 : 低信頼度リマスキング
- 予測信頼度に基づきトークンを選択
- 最低信頼度トークンをリマスク
- ブロック単位の生成に対応
- セミオートレグレッシブな生成を実現

追加機能 :
- Anonymous (2025) のアプローチを参考にした実装
- 学習目的やネットワーク アーキテクチャーは独自設計
- 双方向 Transformer を採用し因果マスクは不使用

B. Experiments
B.1. Details of SFT Data
LLaDA の Supervised Fine-Tuning (SFT) データ処理の詳細を示す
シーケンス長の動的管理 :
- 短いペアに |EOS| トークンを付加しバッチ内長を統一
- |EOS| トークンはレスポンス部としてマスク対象に含める
- 生成時は |EOS| トークンを除去し応答長を自動制御
マルチターン対話の変換 :
- n ターン対話
(p_0^0, r_0^0, p_0^1, r_0^1, ..., p_0^{n-1}, r_0^{n-1}) (p_0^0, r_0^0) (p_0^0r_0^0p_0^1, r_0^1) (p_0^0r_0^0p_0^1r_0^1...p_0^{n-1}, r_0^{n-1}) - ランダムに 1 つを選択
利点 :
- マルチターン対話能力の獲得
- パディング戦略との整合性を確保
- 応答長の柔軟な制御が可能
これらの処理により SFT データの効率的な利用とモデルの対話能力向上を実現
B.2. Architectures and Scaling Experiments
LLaDA のアーキテクチャーとスケーリング実験の詳細を示す
実験設定 :
- 1.5B パラメーターの ARM と MDM を同一アーキテクチャーで構築
- MDM を 8B パラメーターまでスケール
- 計算リソース制約により 7B の ARM をベースラインとして使用
モデルアーキテクチャー :
- LLaMA スタイルの Transformer を採用
- RMSNorm による学習安定化
- SwiGLU アクティベーション関数
- RoPE ポジショナル エンコーディング
設定の違い :
- 標準的な Multi-head アテンションを使用
- KV キャッシングと非互換のため Value ヘッド数を変更
- FFN 次元を調整し総パラメーター数を維持
- トークナイザーは独自のデータセットに適応
学習コスト計算 :
- 6ND フォーミュラを採用
- N は非埋め込みパラメーター数
- D は総トレーニングトークン数
このアプローチにより :
- 効率的なスケーリング実験を実現
- ARM との公平な比較を可能に
- アーキテクチャー効果の分離評価を実施

B.3. Details and Ablation on Remasking
インストラクトモデルのリマスク戦略とアブレーションスタディについて説明
ベースモデルの制約 :
- |EOS| トークンは訓練データに含まれない
- 低信頼度リマスク戦略で安定した結果を生成
- セミオートレグレッシブリマスクは効果が限定的
インストラクトモデルの対応 :
- 多数の |EOS| トークンが訓練データに存在
- 低信頼度リマスクだけでは |EOS| の過剰生成が発生
- 生成長を複数ブロックに分割し left-to-right で処理
アブレーション結果(GSM8K 精度):
-
ベースモデル
- ランダムリマスク : 52.3
- 低信頼度リマスク : 64.7
- 低信頼度 + セミオートレグレッシブ : 64.4
-
インストラクトモデル
- ランダムリマスク : 72.0
- 低信頼度リマスク : 12.9
- 低信頼度 + セミオートレグレッシブ : 73.8
実験設定 :
- 生成長 : 512 トークン
- サンプリングステップ : 256
- ブロック長 : 32
- GSM8K 精度をメトリックとして使用
評価結果 :
- ベースモデルは低信頼度リマスクで性能向上
- インストラクトモデルはハイブリッド戦略が最適
- 各ベンチマークに適したリマスクパラメーターを設定

B.4. Ablation on Generated Length
生成長に関するアブレーション スタディ結果を示す
実験設定 :
- GSM8K をメトリックとして使用
- サンプリング ステップ数は生成長の半分に設定
- 1 ステップで 2 トークンがマスクからテキストに変換
実装詳細 :
- LLaDA 8B Base: 低信頼度リマスク戦略 (Algorithm 5)
- LLaDA 8B Instruct: ブロック長 32 のセミオートレグレッシブ サンプリング
生成長と精度の相関 :
| 生成長 | Base モデル | Instruct モデル |
|---|---|---|
| 256 | 62.5 | 75.3 |
| 512 | 64.7 | 73.8 |
| 1024 | 65.9 | 75.3 |
分析結果 :
- Base モデルは生成長増加で若干の性能向上
- Instruct モデルは生成長に対し安定した性能を維持
- 両モデルともハイパーパラメーターに対する高い堅牢性を確認
この結果から生成長は重要な設計要素ではないと結論付けられる

B.5. Standard Benchmarks and Evaluation
LLaDA の標準ベンチマーク評価について以下に示す
評価カテゴリー :
- 一般タスク : MMLU, BBH, ARC-C, Hellaswag, TruthfulQA, WinoGrande, PIQA
- 数学・科学 : GSM8K, Math, GPQA
- コード生成 : HumanEval, HumanEval-FIM, MBPP
- チャイナ語理解 : CMMLU, C-Eval
評価プロトコル :
- 条件付き尤度推定と条件付き生成を使用
- lm-evaluation-harness フレームワークを採用
- 内部ライブラリーで特殊メトリック(HumanEval-FIM など)を評価
Base モデル評価設定 :
- 条件付き尤度推定 : MMLU, CMMLU, C-Eval, ARC-C, Hellaswag, TruthfulQA, WinoGrande, PIQA, GPQA
- 条件付き生成 : その他全タスク
- モンテカルロ推定 : 単一トークン予測は 1 回、その他は 128 回
- ガイダンス スケール : {0, 0.5, 1, 1.5, 2} から最適値を選択
Instruct モデル評価設定 :
- 全タスクで条件付き生成を使用
- サンプリング ステップは応答長と同一
- 計算コスト制約によりガイダンスは不使用
このアプローチにより包括的かつ公平な性能評価を実現
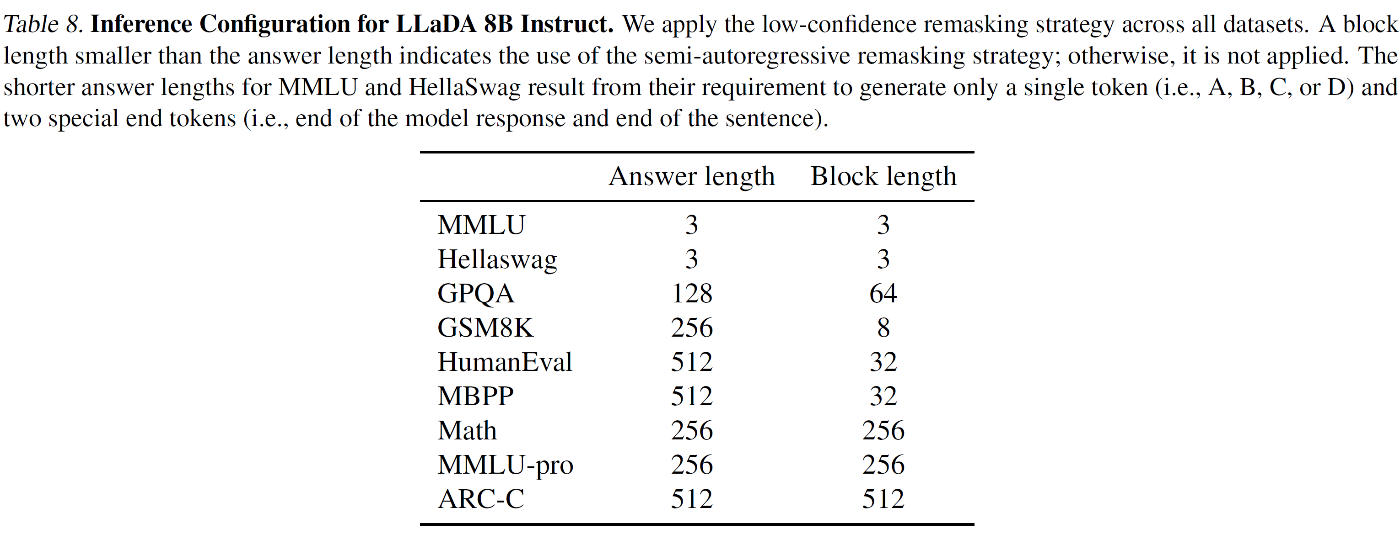
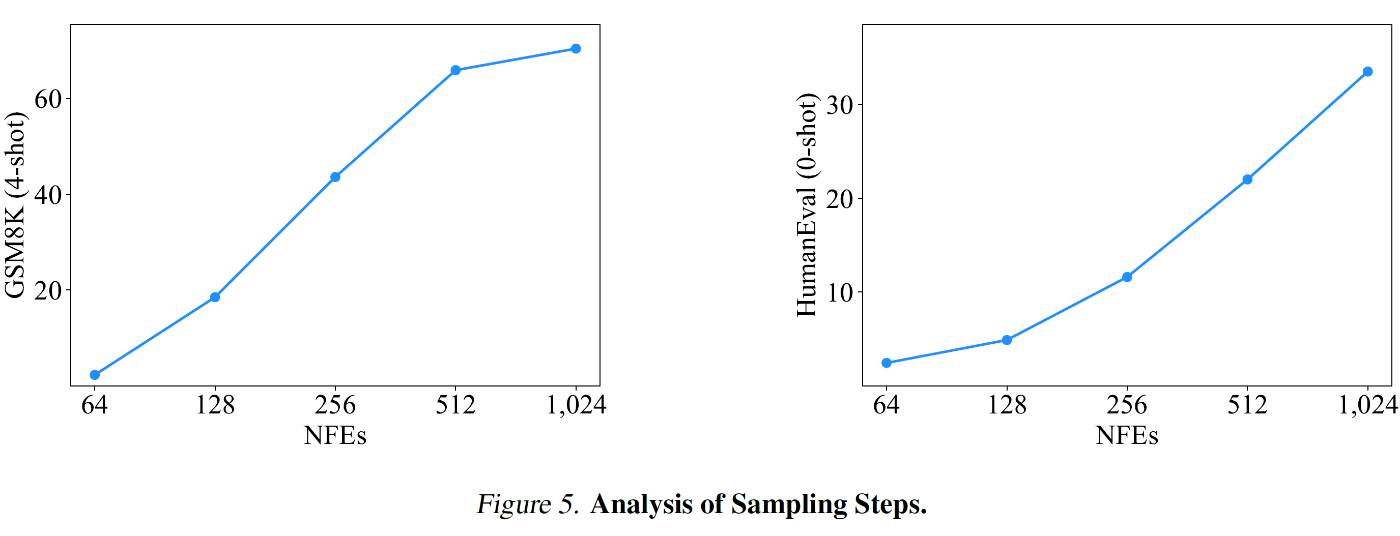
B.6. Analysis of Sampling Steps
サンプリングステップの影響を LLaDA 8B Base モデルで分析
実験設定 :
- 評価タスク : GSM8K と HumanEval
- 生成長 : 1024 トークンに固定
- サンプリングステップ数 : 64 から 1024 まで変化
結果 :
- GSM8K 精度 : サンプリングステップ増加に応じて単調に向上
- HumanEval : ステップ数増加で緩やかな性能改善
- 両タスクとも応答長と同数のステップで最高性能を達成
分析 :
- ステップ数は生成品質に直接影響
- 計算コストとのトレードオフが存在
- タスク特性により最適ステップ数が異なる
この分析から品質と効率性のバランスを考慮したステップ数設定が重要と判明
B.7. Evaluation on iGSM Dataset
iGSM データセットを使用した追加評価を実施
データセット特性 :
- 無限生成可能な GSM8K 形式データ
- パラメーターによる問題難易度制御(解法ステップ数)
- "#### $answer" で終わる形式を採用
- mod 5 アルゴリズムシステムを使用
評価プロトコル :
- 4-6 ステップ問題を各 100 問生成
- システムプロンプトと 4-shot 質問応答ペアを提供
- GSM8K 形式に準拠した評価方式を採用
評価結果 :
| ステップ数 | LLaMA3 8B Base | LLaDA 8B Base |
|---|---|---|
| 4 ステップ | 38.0 | 64.0 |
| 5 ステップ | 35.0 | 41.0 |
| 6 ステップ | 34.0 | 44.0 |
分析 :
- LLaDA Base は LLaMA3 を一貫して上回る性能を示す
- 難易度増加に対する堅牢性を確認
- Table 1 の GSM8K 評価結果と整合性を維持
B.8. Poem Completion Tasks
詩の補完タスクのサンプルを以下に示す
Example 1 :
- Prompt : 窈窕淑女の次の句は何か?
- Answer : 君子好逑
Example 2 :
- Prompt : 不拘一格降人才の前の句は何か?
- Answer : 我勧天公重抖擻
このタスクセットは :
- チャイナ古典詩の前後の句の関係性を評価
- Forward(次の句を生成)と Reversal(前の句を生成)の両方向を検証
- パフォーマンスの方向性依存度を測定
- モデルの双方向理解能力を評価
評価アプローチ :
- 496 個の著名な詩のペアを使用
- プロンプトは直接的な質問形式を採用
- 単一の句の生成を要求
- 生成結果は厳密なマッチングで評価
このデータセットは LLM の Reversal Curse 克服能力の検証に有効なベンチマークを提供
B.9. More Case Studies
LLaDA 8B Instruct の追加ケーススタディーを以下に分類して提示
サンプリングプロセスを可視化 :
- セミオートレグレッシブ・リマスキングによるテキスト生成プロセス
- サンプリングの各ステージにおけるトークン予測を色の濃淡で表現
- 生成テキストの段階的な構築過程を詳細に分析
マルチターン対話のデモ :
- ランダム・リマスキング戦略を採用
- 対話の文脈維持能力を確認
- 複数ターンにわたる一貫性を検証
- トークン予測の時系列変化を可視化
追加事例の分析 :
- シングルターン対話の生成品質
- マルチターン対話の文脈理解
- GPT-4o が失敗する詩の reversal 補完タスクにおける成功例
この追加分析により :
- リマスキング戦略の効果を定性的に評価
- 対話システムとしての能力を実証
- Reversal Curse 克服の具体例を提示
Discussion