DeepSeek-V3 Technical Report
要約
-
モデル概要 :
- 総パラメーター数 671B, トークンごとに 37B のパラメーターが活性化
- 14.8 兆トークンで学習
- Mixture-of-Experts (MoE) アーキテクチャーを採用
- Multi-head Latent Attention (MLA) を使い効率的な推論を実現
-
主な技術的特徴 :
- 補助損失を使わない負荷分散戦略を導入
- マルチトークン予測による学習目標設定
- FP8 混合精度訓練をサポート
- 効率的なパイプラインパラレリズムを実装
-
性能と効率性 :
- オープンソースモデルで最高性能を達成
- GPT-4 や Claude-3.5-Sonnet などの商用モデルと同等の性能
- 学習コストは 2.788M H800 GPU 時間と経済的
- 特にコードと数学関連タスクで高い性能を示す
-
評価結果 :
- MMLU, GPQA, MATH などの多様なベンチマークで高いスコアを達成
- 英語とチャイナ語の両方で優れた性能を示す
- 長文理解や推論タスクでも高い能力を実証
-
技術的な貢献 :
- 効率的な学習フレームワークを開発
- FP8 訓練を大規模モデルへ適用
- 通信オーバーヘッドを最小化
- 効率的な推論戦略を実装
Abstract
主要構成 :
- 671B パラメーターを持つ Mixture-of-Experts (MoE) 言語モデルで各トークンに対して 37B パラメーターを活性化
- Multi-head Latent Attention (MLA) と DeepSeekMoE アーキテクチャーを採用し推論と学習の効率化を実現
技術的特徴 :
- 補助損失を使はない負荷分散戦略
- マルチトークン予測による学習目標
- 14.8T トークンによる事前学習
- Supervised Fine-Tuning と Reinforcement Learning による後処理
性能評価 :
- 他のオープンソースモデルを上回る性能を達成
- GPT-4o や Claude-3.5-Sonnet など主要クローズドソースモデルと同等の性能を実証
学習効率 :
- 完全な学習に必要な H800 GPU 時間は 2.788M
- 学習プロセス全体で安定性を維持しロスの急激な上昇や学習のロールバックを回避

1. Introduction
LLM の進化と現状
- 近年 LLM は急速な進化を遂げ AGI へ向けて進展
- オープンソースモデル (DeepSeek, LlaMa, Qwen, Mistral) がクローズドソースモデルとの差を縮小
- DeepSeek-V3 は 671B パラメーター規模の MoE モデルを実装し各トークンで 37B パラメーターを活性化
アーキテクチャーと効率性
- Multi-head Latent Attention による効率的な推論
- DeepSeekMoE による経済的な学習を実現
- 補助損失を使用しない負荷分散戦略を導入
- マルチトークン予測による性能向上を達成
技術的な最適化
- FP8 混合精度学習
- DualPipe アルゴリズムによるパイプラインパラレリズム効率化
- InfiniBand と NVLink 帯域幅を最大限活用する通信最適化
- テンソルパラレリズムを使はずメモリーフットプリントを最適化
学習プロセス
- 14.8T トークンによる事前学習を実施
- 2 段階のコンテキスト長拡張 (32K → 128K)
- SFT と RL による後処理を実施
- DeepSeek-R1 から推論能力を蒸留
コスト効率
- 1T トークンあたり 180K H800 GPU 時間で学習
- 総コスト 2.788M GPU 時間(約 $5.576M)
- プリトレーニング 2664K, コンテキスト拡張 119K, ポストトレーニング 5K GPU 時間を使用

2. Architecture
- 基本アーキテクチャー
- 効率的な推論のため Multi-head Latent Attention (MLA) を採用
- 経済的な学習のため DeepSeekMoE を実装
- 学習目標
- Multi-Token Prediction (MTP) を導入し評価ベンチマーク性能を向上
- 学習時に複数トークンを予測することで全体性能を改善
- その他
- 基本設定は DeepSeek-V2 の仕様を踏襲
- マイナーな詳細も含め V2 との互換性を維持
2.1. Basic Architecture
基本構造
- Transformer フレームワークをベースに設計
- MLA と DeepSeekMoE を採用し DeepSeek-V2 で実証済の効率性を継承
新機能と改良点
- auxiliary-loss-free ロードバランシング戦略を導入
- ロードバランス確保による性能低下を抑制
- パフォーマンスとバランスの最適化を実現
アーキテクチャーの特徴
- MLA による効率的な推論
- DeepSeekMoE による経済的な学習
- ロードバランス制御による安定性向上
- Figure 2 に示す構造で MLA と DeepSeekMoE を統合

2.1.1. Multi-Head Latent Attention
コアコンセプト
- KV キャッシュ削減のため低ランク共同圧縮を実装
- キーと値の圧縮により推論効率を向上
- 標準的な Multi-Head Attention と同等の性能を維持
技術的特徴
-
圧縮手法
- 圧縮潜在ベクトル
c^{KV} -
KV d_c d_h n_h - RoPE を用いて非結合キーのポジショナル情報を保持
- 圧縮潜在ベクトル
-
クエリー処理
- クエリーも低ランク圧縮を実施
- クエリー圧縮により学習時のアクティベーションメモリーを削減
- RoPE を含む非結合クエリーを生成
- アテンション計算
- 圧縮クエリー、キー、値を組み合わせて最終出力を生成
- Softmax と出力射影を使用
- 標準的なアテンションメカニズムを維持
実装効果
- 青色で示すベクトルのみをキャッシュ
- 推論時の KV キャッシュを大幅に削減
- 標準 MHA と同等の性能を実現
2.1.2. DeepSeekMoE with Auxiliary-Loss-Free Load Balancing
DeepSeekMoE のアーキテクチャーと負荷分散戦略
基本アーキテクチャー
- フィードフォワードネットワークを MoE で実装
- 共有エキスパートと分散エキスパートを区別
- GShard と比較してより細かい粒度のエキスパートを使用
- 8 個の分散エキスパートを各トークンで活性化
負荷分散制御
- バイアス項に基づく補助損失不要の負荷分散を導入
- トークン単位でエキスパートの選択を制御
- バイアス項で上位 K 個のエキスパートを動的に選択
- ゲーティング値は元のアフィニティスコアから計算
補完的なシーケンス単位バランス制御
- シーケンス単位の極端なインバランスを防止
- 非常に小さなバランスファクターでシーケンス単位の損失を設定
- エキスパート選択とゲーティング値の安定性を確保
ノード制限型ルーティング
- 各トークンの送信先ノード数を制限
- アフィニティスコア最大のエキスパートを優先
- 通信コストとメモリー使用量を最適化
特徴
- トークンのドロッピングを回避
- 学習時の負荷分散を維持
- 推論時の負荷分散戦略も実装
この構成により性能低下を抑制しながら効率的な負荷分散を実現
2.2. Multi-Token Prediction
基本コンセプト
- 各位置で複数の将来トークンを予測する学習目標を設定
- 学習信号の密度を向上させデータ効率を改善
- 将来トークン予測のため表現学習を強化
MTP モジュール構造
-
基本構成
- D 個の逐次モジュールで追加のトークンを予測
- 共有埋め込み層を使用
- 共有出力ヘッドを実装
- トランスフォーマーブロックと射影行列を含む
-
予測メカニズム
- 前段の深さ表現と次トークンの埋め込みを組み合わせ
- 完全な因果関係チェーンを各予測深さで維持
- 線形射影による情報統合を実施
学習目標
- 各予測深さでクロスエントロピー損失を計算
- MTP 損失を全深さで平均化
- 重み付け係数
\lambda
推論への応用
- メインモデルの性能向上が主目的
- MTP モジュールは推論時に破棄可能
- Speculative Decoding への応用も可能

3. Infrastructures
3.1. Compute Clusters
ハードウェア構成
- 2048 基の NVIDIA H800 GPU を搭載
- 各ノードに 8 GPU を配置
- ノード内 GPU は NVLink と NVSwitch で接続
- ノード間通信に InfiniBand を使用
ネットワーク特性
- ノード内 : NVSwitch による高速相互接続
- ノード間 : InfiniBand による効率的通信
- GPU 間の高帯域幅通信を実現
インターコネクト構成
- NVLink による同一ノード GPU 間の高速通信
- NVSwitch による柔軟なルーティング
- InfiniBand による大規模分散処理のスケーラビリティー確保
3.2. Training Framework
計算リソース
- 16-way パイプラインパラレリズム (PP)
- 64-way エキスパートパラレリズム (EP) を 8 ノードに分散
- ZeRO-1 データパラレリズム (DP) を採用
エンジニアリング最適化
- DualPipe アルゴリズムによるパイプラインパラレリズム効率化
- パイプラインバブル削減と計算 / 通信フェーズのオーバーラップ実現
- クロスノード全対全通信カーネル効率化
- IB / NVLink 帯域幅を最大活用
- メモリーフットプリント最適化によるテンソルパラレリズム不要化
DualPipe 特性
- 順方向 / 逆方向計算と通信フェーズを重複実行
- 通信オーバーヘッドを最小化
- 安定した計算 / 通信比率を維持
- ファイングレインなエキスパート分散処理を実現
3.2.1. DualPipe and Computation-Communication Overlap
計算通信比率の最適化
- クロスノード専門家パラレリズムによる通信オーバーヘッド
- 計算 / 通信比率を約 1:1 に抑制
- 双方向パイプラインスケジューリングを導入
DualPipe の基本設計
- 順方向 / 逆方向チャンクにおける計算と通信をオーバーラップ
- 各チャンクを 4 コンポーネントに分割
- attention
- all-to-all dispatch
- MLP
- all-to-all combine
- 逆伝播時は入力と重みの逆伝播を分離
オーバーラップ戦略
- GPU SM を計算と通信に適切に割り当て
- all-to-all と PP 通信を完全に隠蔽
- パイプライン両端からマイクロバッチを同時供給
- 通信をバックグラウンドで実行
効率化効果
- パイプラインバブルを削減
- 計算 / 通信比率を維持しながらスケーリング可能
- ファイングレインな専門家分散を実現
- 通信オーバーヘッドをほぼゼロに抑制



3.2.2. Efficient Implementation of Cross-Node All-to-All Communication
帯域幅最適化
- IB 帯域幅 50 GB/s に対し NVLink は 160 GB/s を実現
- トークンあたり最大 4 ノードに送信を制限し IB トラフィックを削減
- 同一ノードインデックス GPU へ IB 経由で送信し NVLink で転送
実装詳細
- 20 SM を 10 通信チャネルに分割
- ワープ スペシャライゼーション技術を活用
- 通信タスクに応じた動的ワープ割り当てを実施
通信フロー
-
ディスパッチプロセス
- IB 送信
- IB から NVLink へのフォワーディング
- NVLink 受信
-
コンバインプロセス
- NVLink 送信
- NVLink から IB へのフォワーディングと集約
- IB 受信と集約
最適化手法
- カスタム PTX 命令を使用
- 通信チャンク サイズの自動調整
- L2 キャッシュ使用率と SM 干渉を最小化
- 計算ストリームとのオーバーラップを実現
3.2.3. Extremely Memory Saving with Minimal Overhead
メモリー削減手法
- RMSNorm と MLA アップ射影を逆伝播時に再計算
- EMA パラメーターを CPU メモリーに保存し非同期更新
- マルチトークン予測用の埋め込みと出力ヘッドを物理的に共有
RMSNorm 再計算
- 出力アクティベーション永続保存を不要化
- 最小限のオーバーヘッドでメモリー使用量を削減
- アクティベーション保存コストを大幅に抑制
EMA 管理
- モデル パラメーターの指数移動平均を CPU で管理
- 学習率低下後の性能評価を早期推定
- メモリーとタイム オーバーヘッドを回避
埋め込み最適化
- DualPipe により浅層と深層を同一 PP ランクに配置
- MTP モジュールとメインモデル間でパラメーター共有
- 勾配の物理的共有によりメモリー効率を向上
3.3. FP8 Training
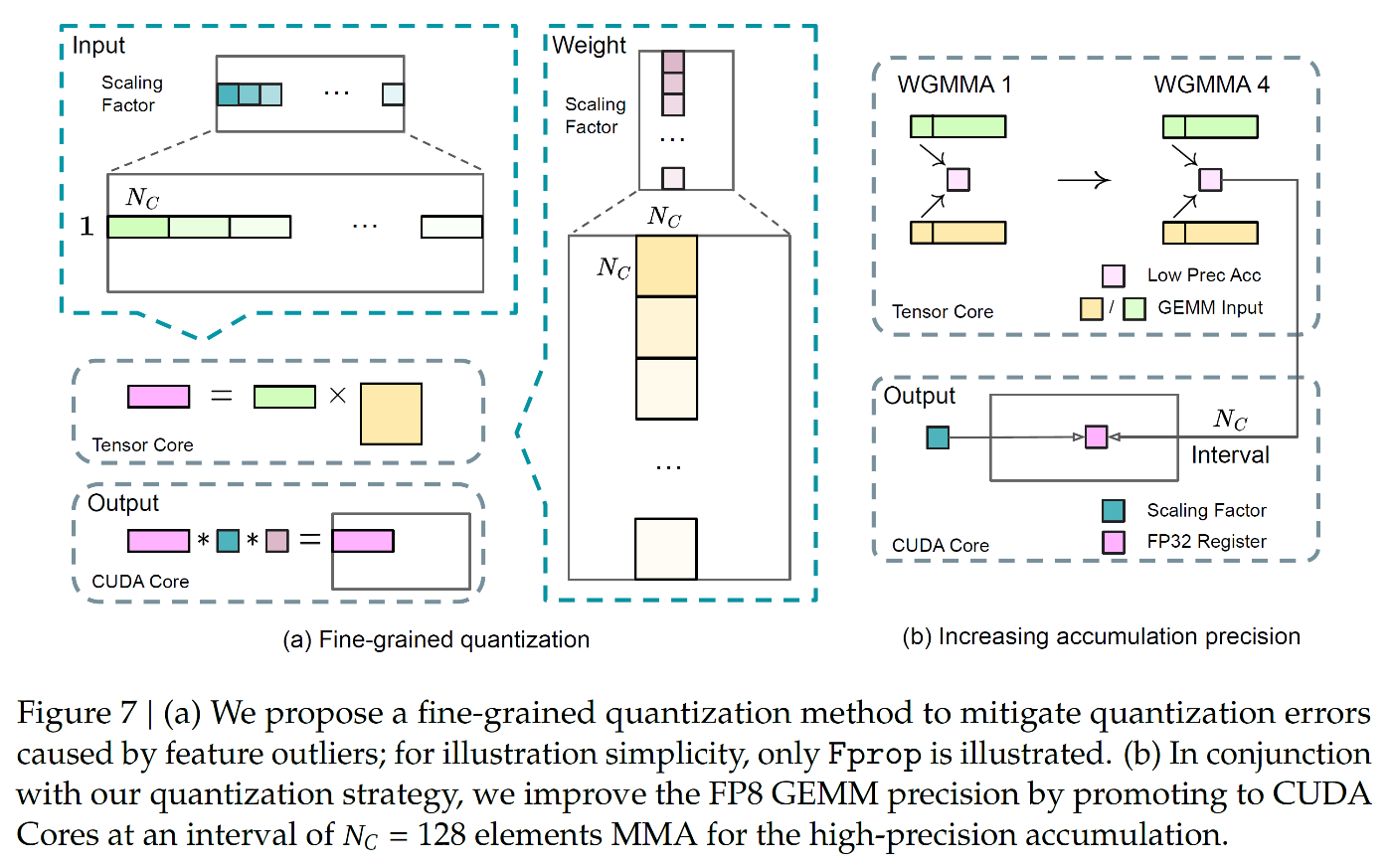
主要アプローチ
- FP8 データ形式による細粒度混合精度フレームワークを実装
- アクティベーション、重み、勾配における外れ値に対処
- タイル単位 (1 × Nc) またはブロック単位 (Nc × Nc) のグループ化戦略を導入
技術的改善点
- 高精度アキュムレーションプロセスによるデクアンタイゼーションオーバーヘッドを軽減
- FP8 GEMM の精度向上を実現
- アクティベーションを FP8 でキャッシュおよびディスパッチ
- オプティマイザー状態を BF16 で保存
評価結果
- DeepSeek-V2-Lite および V2 スケールで約 1T トークンの学習を実施
- BF16 ベースラインと比較し相対損失誤差を 0.25% 未満に抑制
- 学習のランダム性許容範囲内で安定した性能を実現
3.3.1. Mixed Precision Framework
コア GEMM 実装
- FP8 入力から BF16 / FP32 出力を生成
- 線形演算子の 3 種 GEMM を FP8 に対応
- Fprop(順伝播)
- Dgrad(アクティベーション逆伝播)
- Wgrad(重み逆伝播)
- 演算速度を BF16 比で理論上 2 倍に向上
高精度処理適用範囲
- 埋め込みモジュール
- 出力ヘッド
- MoE ゲーティングモジュール
- 正規化オペレーター
- アテンションオペレーター
メモリー最適化
- マスターウェイトは高精度保持
- 重み勾配は高精度で管理
- オプティマイザー状態も高精度維持
- DP ランク間のシャーディングでメモリーオーバーヘッドを低減

3.3.2. Improved Precision from Quantization and Multiplication
きめ細かな量子化
- FP8 フォーマットのダイナミックレンジ制限に対処
- アウトライアーによる精度劣化を防止
- 1×128 タイル単位でアクティベーションを量子化
- 128×128 ブロック単位で重みを量子化
精度向上戦略
- GEMM 内部次元に沿った量子化グループ単位でスケーリングを実施
- 標準 FP8 GEMM では直接サポートしない機能を実装
- FP32 アキュムレーションと組み合わせ効率化
アキュムレーション精度改善
- テンソルコア上での FP8 GEMM は約 14 ビット精度に制限
- バッチサイズとモデル幅増加時に影響が顕著化
- CUDA コアへのプロモーション戦略を採用
- 128 要素間隔で FP32 レジスタへコピー
- オーバーヘッドを最小限に抑制しながら高精度計算を実現
Mantissa 優先戦略
- E4M3 フォーマットを全テンソルに適用
- タイル / ブロック単位スケーリングでダイナミックレンジを確保
- グループ化要素間でエクスポーネントビットを効果的に共有
オンライン量子化
- タイル / ブロックごとに最大絶対値を即時計算
- スケーリング係数をオンラインで導出
- FP8 フォーマットへ直接量子化を実施
3.3.3. Low-Precision Storage and Communication
オプティマイザー状態管理
- AdamW オプティマイザーの 1/2 次モーメントを FP32 から BF16 に変更
- マスターウェイトと勾配は FP32 保持で数値安定性を確保
- バッチサイズ累積用勾配も FP32 維持
アクティベーション管理
- Wgrad 演算を FP8 で実行し Linear オペレータ逆伝播用のアクティベーションを FP8 キャッシュ
- アテンション後の Linear 入力に E5M6 フォーマットを適用
- SwiGLU オペレータ入力を FP8 キャッシュし逆伝播時に出力を再計算
通信帯域幅最適化
- MoE アップ射影前のアクティベーションを FP8 に量子化
- MoE ダウン射影前の勾配を FP8 に量子化
- スケーリング係数を 2 のべき乗に制限
- forward/backward combine は BF16 維持でクリティカルパスの精度を確保
3.4. Inference and Deployment
システム構成
- H800 クラスター上に展開
- ノード内 GPU は NVLink で接続
- クラスター全体を InfiniBand で相互接続
デプロイメント戦略
- プリフィリングとデコーディングを分離
- オンラインサービス SLO を保証
- 高スループットを同時実現
3.4.1. Prefilling
最小デプロイメントユニット
- 4 ノード 32 GPU で構成
- アテンション部分は TP4 + SP + DP8 を実装
- MoE 部分は EP32 を採用
- 浅層の Dense MLP は TP1 で通信を削減
ロードバランシング
- GPU 間トークン処理数の均等化を実現
- 冗長エキスパートを導入し高負荷エキスパートを複製
- 10 分間隔で統計情報に基づき調整
- ノード内 GPU 間で通信オーバーヘッドを最小化
エキスパート配置
- 各 GPU は通常 8 エキスパートをホスト
- 追加で 1 個の冗長エキスパートを配置
- プリフィリング時は 32 冗長エキスパートを使用
動的冗長化戦略
- 各 GPU で 16 エキスパートをホスト
- 各推論ステップで 9 エキスパートを活性化
- レイヤー単位で最適ルーティングを計算
- 計算オーバーヘッドは無視可能レベルに抑制
3.4.2. Decoding
デプロイ構成
- 最小単位は 40 ノード 320 GPU
- アテンション部: TP4 + SP + DP80
- MoE 部: EP320 実装
- 各 GPU は 1 エキスパートを担当
- 64 GPU で冗長 / 共有エキスパートをホスト
通信最適化
- dispatch / combine は IB 経由で直接 P2P 転送
- IBGDA テクノロジーでレイテンシーを最小化
- 通信効率を向上
負荷分散制御
- エキスパート負荷を定期的にモニタリング
- 統計情報に基づき冗長エキスパートを決定
- GPU 単一エキスパート構成で再配置は不要
- 動的冗長化を検討中
スループット向上
- マイクロバッチ処理を並列実行
- アテンション計算と dispatch / MoE / combine を重複実行
- 少数 SM でエキスパート処理を実行しアテンション性能を維持
3.5. Suggestions on Hardware Design
3.5.1. Communication Hardware
現状の課題
- 計算と通信のオーバーラップにより通信帯域幅への依存を軽減
- 通信実装が SM に依存し計算リソースを圧迫
- H800 GPU の 132 SM から 20 SM を通信用に割り当て
- テンソルコアが通信中に未使用
主要な通信タスク
- IB と NVLink 間のデータフォワーディング
- 同一ノード内の複数 GPU 宛て IB トラフィック集約
- RDMA バッファーと入出力バッファー間のデータ転送
- all-to-all combine の演算処理
- IB / NVLink ドメイン間のメモリーレイアウト制御
提案アーキテクチャー
- GPU コプロセッサーまたはネットワークコプロセッサーを開発
- NVIDIA SHARP に類似した機能を実装
- IB と NVLink のネットワークを計算ユニットから統合
- read / write / multicast / reduce を単純プリミティブにより実装
3.5.2. Compute Hardware
テンソルコアの FP8 GEMM 精度向上
- 現状は固定小数点アキュムレーションを使用
- マンティッサ乗算を最大エクスポーネントに基づきシフト
- 14 ビット精度の制限が存在
- 32 回の FP8 × FP8 乗算には 34 ビット精度が必要
- 完全精度アキュムレーションの実装を推奨
タイル / ブロック単位量子化サポート
- 現行 GPU は テンソル単位量子化のみ対応
- Nc 間隔で結果を CUDA コアにコピーし精度低下
- テンソルコアでのグループスケーリング実装を提案
- アキュムレーションと量子化を一括処理
オンライン量子化対応
- 現行実装でオンライン量子化の効率的サポートが困難
- HBM から BF16 値の読み出しと FP8 への変換で冗長
- FP8 キャストと TMA アクセスの融合を提案
- ワープレベルキャスト命令によるスピードアップを実現
トランスポーズ GEMM 最適化
- 現アーキテクチャーは行列転置との融合が非効率
- 1 x 128 FP8 タイルから 128 x 1 タイルへの変換が必要
- 共有メモリーからの直接転置読み出しを提案
- FP8 フォーマット変換と TMA アクセスの統合化を推奨
4. Pre-Training
4.1. Data Construction
DeepSeek-V3 のデータ構築手法を技術的に整理
データセット改善
- DeepSeek-V2 と較べて数学とプログラミングサンプル比率を向上
- 英語およびチャイナ語以外の多言語カバレッジを拡大
- データ処理パイプラインを最適化し冗長性を最小化
- コーパス多様性を維持しつつ重複を削減
FIM 戦略実装
- DeepSeekCoder-V2 での実績を応用
- トークン予測能力を維持しつつコンテキスト予測を強化
- PSM フレームワークを使用し以下のフォーマットを採用
\texttt{<|fim\_begin|>} \ f_{\text{pre}} \texttt{<|fim\_hole|>} \ f_{\text{suf}} \texttt{<|fim\_end|>} \ f_{\text{middle}} \texttt{<|eos\_token|>} - 文書レベルで 0.1 の割合で FIM 戦略を適用
トークナイザー最適化
- 128K トークン語彙で Byte-level BPE を実装
- 多言語圧縮効率向上のため前処理を最適化
- 句読点と改行を組み合わせたトークンを導入
- トークン境界バイアス対策として分割比率を動的調整
結果として 14.8T の高品質かつ多様なトークンを構築
4.2. Hyper-Parameters
モデルハイパーパラメーター
- トランスフォーマー層 : 61
- 隠れ次元 : 7168
- パラメーター初期化 : 標準偏差 0.006
- MLA ヘッド数
n_h - ヘッド次元
d_h - KV 圧縮次元
d_c - クエリー圧縮次元
d'_c - 非結合ヘッド次元
d^R_h
MoE 構成
- 最初の 3 層を除き全 FFN を MoE 化
- 1 共有エキスパート + 256 分散エキスパート
- エキスパート中間次元 : 2048
- トークンあたり 8 エキスパート活性化
- 最大 4 ノードへ送信制限
学習設定
- AdamW オプティマイザー (
\beta_1 \beta_2 - weight_decay = 0.1
- 最大シーケンス長 : 4K
- 14.8T トークンで事前学習
- バッチサイズ : 3072 から 15360 へ段階的に増加
- バイアス更新速度
\gamma - MTP 損失重み
\lambda
4.3. Long Context Extension
コンテキスト長拡張の実装内容
YaRN による拡張手法
- 事前学習後のモデルに YaRN を適用
- 2 段階のトレーニングフェーズを実装
- 4K から 32K、その後 128K へ拡張
- 非結合キー
k^R_t
パラメーター設定
- スケール
s = 40 \alpha = 1 \beta = 32 - スケーリング係数
\sqrt{t} = 0.1 \ln s + 1
フェーズ別構成
第 1 フェーズ
- シーケンス長: 32K
- バッチサイズ: 1920
- 学習率:
7.3 \times 10^{-6}
第 2 フェーズ
- シーケンス長: 128K
- バッチサイズ: 480
- 学習率:
7.3 \times 10^{-6}
拡張後の性能
- 128K 長入力を安定処理
- NIAH テストで堅牢な性能を実証
- スーパーバイズドファインチューニング後も性能維持

4.4. Evaluations
4.4.1. Evaluation Benchmarks
多肢選択データセット
- MMLU, MMLU-Redux, MMLU-Pro, MMMLU
- C-Eval, CMMLU(チャイナ語)
- 教育および専門知識評価用
言語理解・推論セット
- HellaSwag, PIQA, ARC
- BigBench Hard (BBH)
- 基本的言語理解力を評価
質問応答セット
- TriviaQA, NaturalQuestions(クローズドブック形式)
- DROP, C3, CMRC(読解)
- CLUEWSC, WinoGrande(照応解析)
特定ドメイン評価
- Pile(言語モデリング)
- CCPM(チャイナ語理解・文化)
- GSM8K, MATH, MGSM, CMath(数学)
- HumanEval, LiveCodeBench-Base, MBPP, CRUXEval(コード)
- AGIEval(標準試験、英語・チャイナ語)
評価方式
- パープレキシティー評価 : HellaSwag, PIQA 等
- 生成ベース評価 : TriviaQA, DROP 等
- Pile-test は BPB メトリックで評価しトークナイザー間の公平性を確保
4.4.2. Evaluation Results
オープンソースモデル比較
- DeepSeek-V2 Base を大幅に上回る性能を達成
- Qwen2.5 72B Base および LLaMA-3.1 405B Base を多数ベンチマークで凌駕
- 特に MATH-500 で優れた結果を示し o1-preview を上回る性能
英語ベンチマーク分析
- MMLU シリーズで一貫した優位性を確保
- DROP など長文理解タスクでトップクラスの結果
- LiveCodeBench など競技プログラミングタスクで高スコア達成
チャイナ語評価性能
- C-Eval および CMMLU で高精度を維持
- Qwen2.5 72B と同等レベルのチャイナ理解力を実証
- CCPM で優れた文化理解能力を提示
総合評価
- コストパフォーマンスと実用性を両立
- 主要クローズドソースモデルと互角性能を確保
- 特に数学とコードタスクで卓越した結果を示す

4.5. Discussion
4.5.1. Ablation Studies for Multi-Token Prediction
MTP アブレーション研究
検証モデル構成
- スモールスケール : 15.7B パラメーター、1.33T トークン
- ラージスケール : 228.7B パラメーター、540B トークン
性能評価結果
- MMLU : ベース 50.0 → MTP 53.3(スモール)、67.5 → 66.6(ラージ)
- HumanEval : ベース 20.7 → MTP 26.8(スモール)、44.5 → 53.7(ラージ)
- GSM8K : ベース 25.4 → MTP 31.4(スモール)、72.3 → 74.0(ラージ)
- MATH : ベース 10.7 → MTP 12.6(スモール)、38.6 → 39.8(ラージ)
実装効果
- 両スケールで一貫した性能向上を確認
- コーディングタスクで顕著な改善を実現
- 数学系タスクで安定した精度向上を達成
- 推論時のメインモデル性能も向上
MTP モジュールは推論時に破棄可能でオーバーヘッドが無く性能改善を実現

4.5.2. Ablation Studies for the Auxiliary-Loss-Free Balancing Strategy
検証モデル構造
- 小規模モデル : 15.7B パラメーター / 1.33T トークン
- 大規模モデル : 228.7B パラメーター / 578B トークン
評価性能比較 (補助損失ベース vs 補助損失フリー)
Pile-test
- 小規模 : 0.727 → 0.724
- 大規模 : 0.656 → 0.652
GPQA
- 小規模 : 37.3 → 39.3
- 大規模 : 66.7 → 67.9
HumanEval
- 小規模 : 22.0 → 22.6
- 大規模 : 40.2 → 46.3
実装効果
- 補助損失フリー戦略で一貫した性能向上を確認
- コード生成タスクで顕著な改善
- 数学関連タスクで安定した精度向上を達成
- 大規模モデルでより効果的な性能改善を実現
実装最適化
- バッチ単位の負荷分散で効率的なバランシングを実現
- メモリー使用量を最小限に抑制
- 学習プロセス全体で安定性を維持
- 推論時のパフォーマンス低下を防止

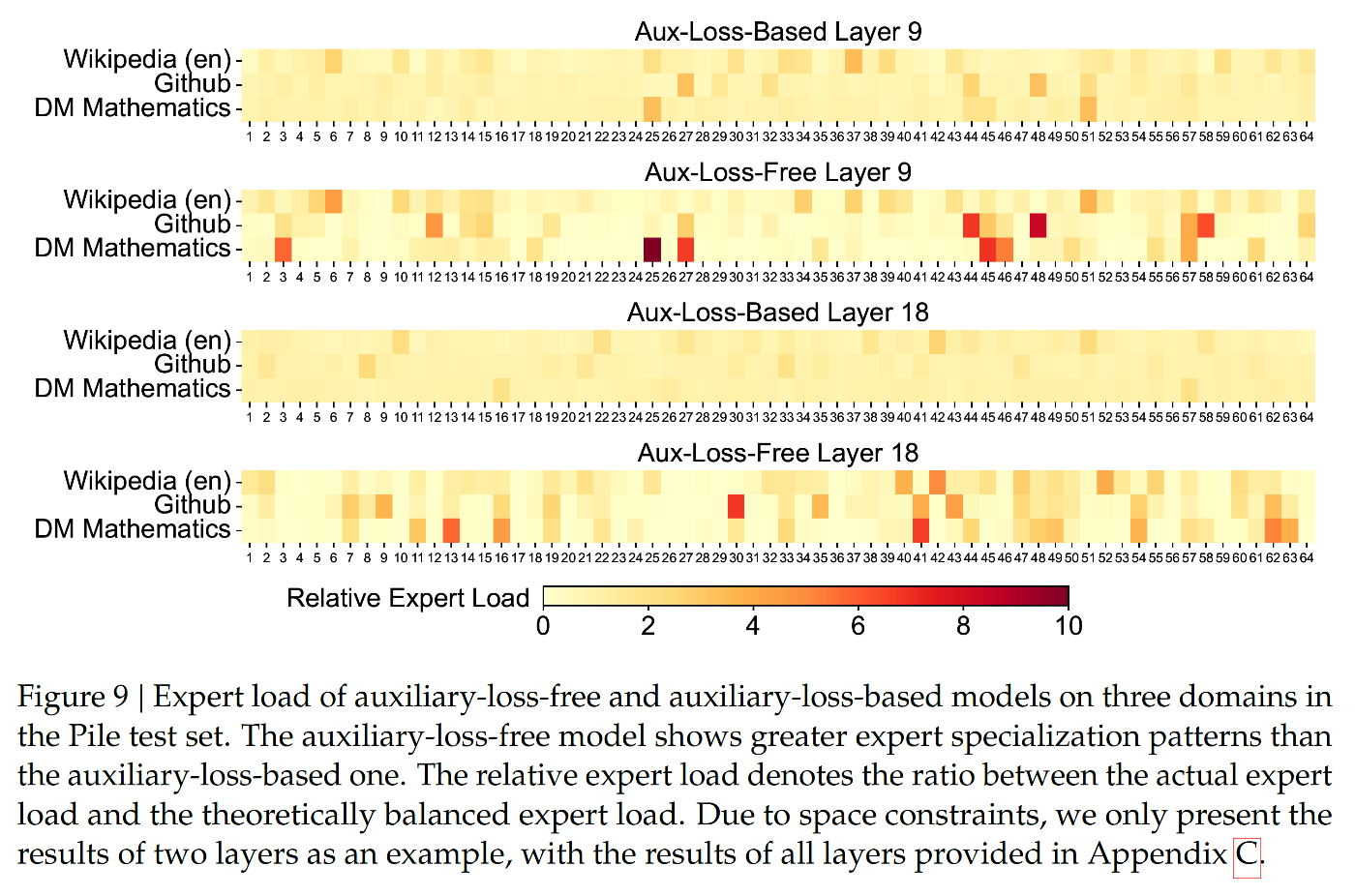
4.5.3. Batch-Wise Load Balance VS. Sequence-Wise Load Balance
主要な差異
- バッチ単位はより柔軟なドメイン特化を実現
- シーケンス単位は各シーケンス内で強制的なバランスを要求
- エキスパート特化パターンはバッチ単位で優位性を示す
実験結果
- 16B モデルで Pile テストセット評価を実施
- 補助損失フリーモデルが高いエキスパート特化度を達成
- シーケンス単位検証では 2.258 の検証損失を記録
- バッチ単位 / 補助損失フリーで 2.253 まで損失を改善
効率化効果
- バッチ単位制御で高い柔軟性を維持
- 大規模エキスパートパラレリズムでシーケンスインバランスを緩和
- 推論時は冗長エキスパート配置で負荷分散を最適化
- ドメインシフトによる負荷変動を効果的に制御
5. Post-Training
5.1. Supervised Fine-Tuning
データ作成
- 150 万インスタンスを複数ドメインで構築
- 各ドメインに最適化した生成手法を適用
- DeepSeek-R1 モデルで推論データを生成
推論データ最適化
- R1 生成データは高精度だが冗長性が課題
- フォーマッティングと長さを制御
- レギュラー形式の推論データとバランスを調整
サンプル生成プロセス
- 各インスタンス 2 種類の SFT サンプルを生成
-
<problem, original response>形式 -
<system prompt, problem, R1 response>形式
-
プロンプト設計
- システムプロンプトに検証と振り返りメカニズムを組込
- 温度パラメーター制御で R1 / オリジナルパターンを融合
- RL ステップで推論パターンを統合
データ品質制御
- リジェクションサンプリングで高品質データを選別
- エキスパートモデルをデータ生成ソースとして活用
- DeepSeek-R1 の強みを保持しつつ簡潔な応答を実現
5.2. Reinforcement Learning
5.2.1. Reward Model
RM(報酬モデル)の構成を 2 タイプで実装
ルールベース RM
- 確定的な結果を持つ質問に適用
- 数学問題は指定フォーマット内で結果を検証
- LeetCode 問題はコンパイラーでテストケース評価
- ルールベースバリデーションで高信頼性を確保
モデルベース RM
- グラウンドトゥルース付き自由形式回答を評価
- 創造的タスクは質問と回答ベースで評価を実施
- チェーンオブソート型の選好データで訓練
- 最終報酬と推論過程を含めた学習データを構築
- 特定タスクの報酬ハッキングリスクを軽減
評価プロセス
- SFT チェックポイントから報酬モデルを訓練
- 投票技術により評価の堅牢性を向上
- オープンエンド質問に自己フィードバックを提供
- アライメントプロセスの効果と安定性を強化
5.2.2. Group Relative Policy Optimization
基本アーキテクチャー
- クリティックモデルを使わずグループスコアでベースラインを推定
- 各質問 q に対し古いポリシーモデルからグループ出力を生成
- ポリシーモデルを最適化目標で更新
最適化目標 : 式 (26)
KL 距離計算
アドバンテージ計算
実装特性
- コーディング、数学、ライティング、ロールプレイなど多様なプロンプトを統合
- 人間嗜好へのアラインメントを強化
- ベンチマーク性能を向上
- SFT データが限定的なシナリオで特に効果を発揮
5.3. Evaluations
5.3.1. Evaluation Settings
追加ベンチマーク
- IFEval : インストラクションフォロー評価
- FRAMES : 100K トークン文脈の分析
- LongBench v2 : 長文文脈理解力測定
- GPQA, SimpleQA, C-SimpleQA : 事実関連知識評価
- SWE-Bench Verified : ソフトウェアエンジニアリング能力測定
- LiveCodeBench : 8-24 月のコードコンペティション問題
プログラミング評価
- HumanEval-Mul : 8 種プログラミング言語対応
- LiveCodeBench : CoT / 非 CoT 手法で評価
- Codeforces : 競合比率による評価
- SWE-Bench : エージェントレスフレームワークで検証
- Aider : diff フォーマットで評価
数学系評価
- AIME, CNMO 2024 : 温度 0.7 で 16 回平均を測定
- MATH-500 : グリーディーデコーディングを適用
共通設定
- 最大出力トークン : 8192
- 少数サンプルデータセット : 複数温度設定での平均値を使用
- simple-evals フレームワークのプロンプト採用
- Zero-Eval プロンプトを MMLU-Redux にゼロショット適用
5.3.2. Standard Evaluation
MMLU 関連評価
- MMLU で 88.5 を達成し全オープンソースモデルを凌駕
- MMLU-Pro で 75.9 を記録
- GPQA で 59.1 を達成し GPT-4o に次ぐ性能を示す
言語理解評価
- 長文理解タスク DROP で 91.6 F1 スコアを達成
- FRAMES で GPT-4o に次ぐパフォーマンスを実証
- LongBench v2 で最高性能を実現
コード・数学性能
- SWE-Bench Verified で Claude-Sonnet-3.5 に次ぐ結果
- HumanEval や LiveCodeBench で最高性能を達成
- MATH-500 で non-o1-like モデル中最高スコアを記録
英中バイリンガル性能
- SimpleQA で GPT-4o と Claude-Sonnet に次ぐ結果
- C-SimpleQA で全モデル中最高性能を達成
- C-Eval と CMMLU で安定したチャイナ語処理能力を実証

5.3.3. Open-Ended Evaluation
Arena-Hard 評価
- GPT-4-Turbo-1106 をジャッジに使用
- ベースライン GPT-4-0314 に対し 86% の勝率を達成
- Claude-Sonnet-3.5-1022 と同等レベルを実証
- オープンソース初の 85% スコア超えを達成
AlpacaEval 2.0 性能
- クローズドソースモデル含め全モデルを上回る結果
- ライティングタスクで高水準な性能を示す
- 質問応答で高い応答品質を実現
- DeepSeek-V2.5-0905 から 20% の性能向上を達成
評価特性
- 複雑なプロンプト処理で高い柔軟性を実証
- コードとデバッグタスクで安定した処理を実現
- オープンソース / クローズドソース間の性能差を縮小
- 単純タスクから複雑タスクまで一貫した性能を維持

5.3.4. DeepSeek-V3 as a Generative Reward Model
RewardBench による評価結果を機能別に整理
判断能力評価
- Chat スコア : 96.9
- Chat-Hard スコア : 79.8
- Safety スコア : 87.0
- Reasoning スコア : 84.3
- 平均スコア : 87.0
投票メカニズム強化
- 6 票メジョリティ採用で平均 89.6 に向上
- Chat-Hard : 79.8 → 82.6 に改善
- Safety : 87.0 → 89.5 に上昇
- Reasoning : 84.3 → 89.2 に改善
比較性能
- GPT-4o 0513 / 0806 / 1120 と同等以上
- Claude-3.5-sonnet 0620 / 1022 シリーズと競合可能
- 投票システム導入で総合評価トップクラスを実現
アライメントプロセス
- オープンエンド質問への自己フィードバック機能を実装
- 判断精度と応答品質を同時に最適化
- 投票システムによりアライメント効果を増強

5.4. Discussion
5.4.1. Distillation from DeepSeek-R1
DeepSeek-R1 蒸留結果を要素別に整理
ベースライン比較
- LiveCodeBench : Pass@1 31.1 から 37.4 に改善
- MATH-500 : Pass@1 74.6 から 83.2 へ向上
- ベースラインレスポンス長 : 718 文字
- R1 蒸留後レスポンス長 : 783 文字
トレードオフ分析
- 高精度化に伴いレスポンス長が増加
- MATH-500 では約 2 倍の長さに拡大
- 計算効率とモデル精度間のバランスを最適化
- DeepSeek-V3 で最適な蒸留設定を採用
蒸留効果
- 数学とコードドメインで有効性を実証
- 長文 CoT 蒸留が複雑推論タスクで効果的
- 認知タスク全般への応用可能性を示唆
- 他ドメインへの展開も検討中

5.4.2. Self-Rewarding
RL による自己報酬戦略
外部検証可能タスク
- コード / 数学系タスクはツールで検証可能
- テストケースとコンパイル結果から報酬を決定
- 高い RL 効果を確認
一般タスク対応
- Constitutional AI アプローチを導入
- DeepSeek-V3 投票評価を報酬源として活用
- 追加情報による憲法的方向への最適化を実現
フィードバック メカニズム
- LLM による非構造化情報の報酬変換を実装
- 多様なシナリオに対応可能な報酬生成を実現
- LLM の自己改善プロセスを確立
今後の展開
- 一般シナリオ向けスケーラブルな報酬手法を模索
- 報酬生成と モデル改善の効率化を検討
- 汎用性と再現性の向上を目指す
5.4.3. Multi-Token Prediction Evaluation
MTP 評価結果
予測パフォーマンス
- 2 トークン先予測に焦点を設定
- 受理率は 85% から 90% を達成
- 予測精度はトピック間で一貫した安定性を維持
- 1.8 倍の TPS (Tokens Per Second) を実現
精度・効率評価
- 各生成トピックで高い受理率を達成
- デコーディングスピード向上に貢献
- 推論時オーバーヘッド無しで性能改善
- Speculative デコーディングへの適用性を確認
実装効果
- 予測深度を効率的に制御
- アテンション計算とのバランスを最適化
- メモリー使用効率を維持
- 推論パイプラインの高速化を実現
6. Conclusion, Limitations, and Future Directions
モデル概要
- 671B パラメーターの MoE モデルを構築
- 各トークンで 37B パラメーターを活性化
- 14.8T トークンで事前学習を実施
- MLA と DeepSeekMoE アーキテクチャーを採用
主要成果
- FP8 学習フレームワークを大規模モデルに初適用
- クロスノード MoE 学習の通信ボトルネックを解消
- 計算通信オーバーラップによる効率化を実現
- コスト効率に優れた学習プロセスを確立
制限事項
- 効率的推論のため大規模デプロイメントユニットが必要
- 小規模チーム向け展開が課題
- DeepSeek-V2 比 2 倍の生成速度だが改善余地はある
今後の研究方向
-
アーキテクチャー
- 学習推論効率向上
- 無限コンテキスト長対応
- トランスフォーマー構造による制限を突破
-
データ処理
- データ品質と量を最適化
- 追加学習信号を導入
- 多次元スケーリングを探求
-
思考能力
- 推論長と深さを拡張
- モデル知能指数向上
- 問題解決能力強化
-
評価手法
- 多面的評価手法開発
- ベンチマーク最適化を防止
- 基礎的評価指標を確立
Discussion