☕
機械学習で情報を分類する簡単ステップ
問題設定: どのコーヒーが仕事の集中力を上げるのか?
例えば、あなたがコーヒー好きで、どの種類のコーヒーを飲むと仕事の集中力が高まるかを分析したいとします。
そこで、機械学習を使って、コーヒーを「集中力が高まる☕」と「集中力が下がる😪」の 2つのカテゴリに分類するモデル を作成してみましょう!
ステップ 1: データ収集
まずは、1週間にわたって以下のデータを記録します。
✔️ コーヒーの種類(エスプレッソ、カプチーノ、ドリップコーヒーなど)
✔️ 砂糖の量(なし、少なめ、多め)
✔️ 飲んだ時間
✔️ 1時間後の集中度(高い or 低い)
データの例:
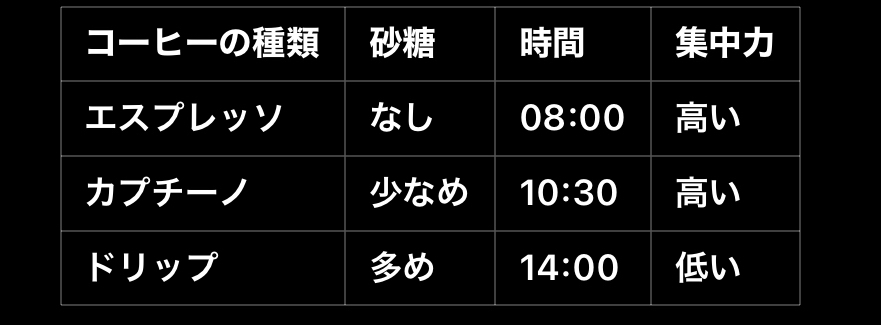
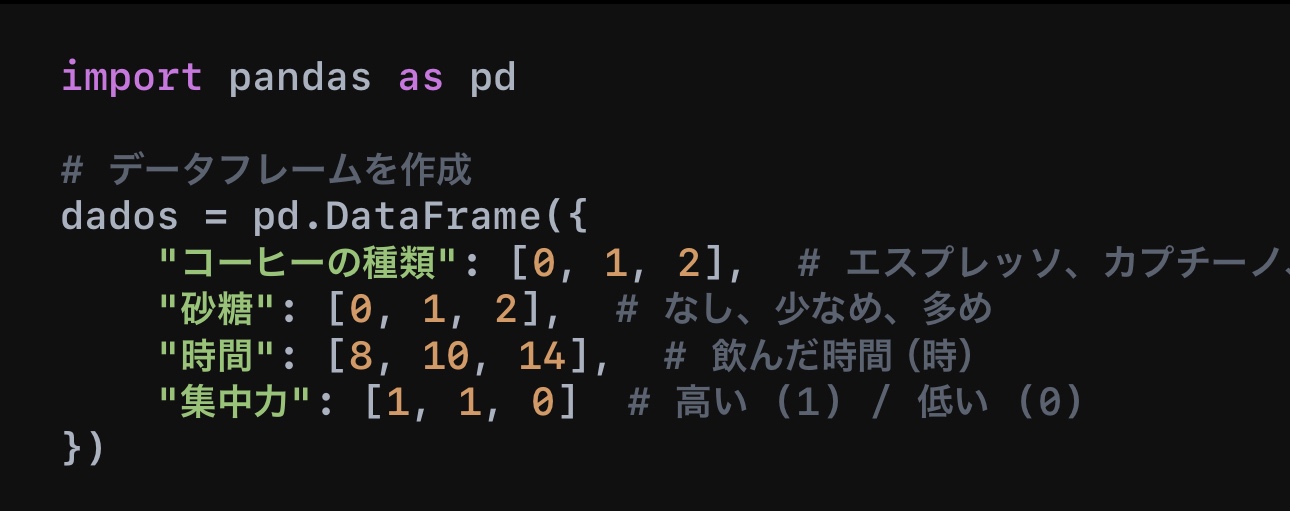
ステップ 2: データの前処理
データをモデルが理解しやすい形式に変換します。
✅ カテゴリを数値化
•エスプレッソ → 0、カプチーノ → 1、ドリップ → 2
•砂糖なし → 0、少なめ → 1、多め → 2
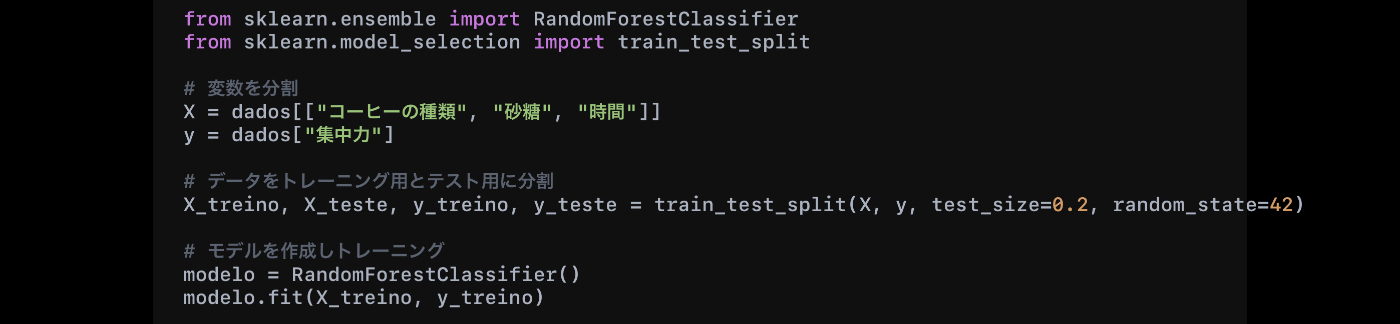
ステップ 3: モデルのトレーニング
次に、分類モデルをトレーニングします。
📌 ランダムフォレストを使用:
ステップ 4: モデルのテスト
モデルが学習できたら、新しいコーヒーのパターンで集中力を予測してみます。
📌 Pythonでの予測:

まとめ
このように、機械学習を使えば、日常のちょっとしたデータから価値ある情報を引き出すことができます!
ビジネスの現場でも、この技術を活用すればデータから意思決定をサポートするシステムが構築できますね!
📢 あなたなら、どんなデータを分類してみたいですか?ぜひコメントで教えてください!
Discussion