SPCS(Snowpark Container Services)でコンテナをお試し移管してみた
はじめに
SPCSが遂に東京リージョンでもPuPrされましたね。
Available regions
これをきっかけに、SPCSのチュートリアルを行ったり自前のコンテナをSPCSに移管したりしてみました。
今回は、SPCSや移管をどう行ったかについて書いていきます。
想定読者
SPCSについてまだよくわからない人
SPCSにコンテナを移管する例が知りたい人
SPCSについて
SPCSとは
SPCS(Snowpark Container Services)とは、Snowflakeが提供するフルマネージドコンテナサービスです。
SPCSはSnowflakeと統合されており、以下のことが行えます。
- Snowflakeに接続し、SQLを実行
- Snowflakeステージへのファイルアクセス
また、Dockerを使用してSnowflakeにプッシュできるため、簡単にデプロイできます。
SPCSの起動方法
SPCSには以下2つの起動方法があり、用途によって使い分けることができます。
-
サービス
サービスとしてコンテナを起動した場合、明示的に終了させない限り起動しつづけます。
サービスはエンドポイントを構成でき、Snowflake外部からの通信やサービス同士の通信が可能です。
その為、Webサーバーとして使いたい場合などにはサービスを使用します。
また、何らかの理由でエラー・中断が発生した場合でも、Snowflakeがコンテナを再起動しサービスが中断されないように動作します。 -
ジョブ
ジョブとしてコンテナを起動した場合、コンテナの処理が完了すると終了します。
イメージとしては、ストアドプロシージャのようなもので短期的な処理に使用します。
イメージリポジトリ
コンテナイメージを保存するためのリポジトリです。
アカウントに対し複数作成することができます。
作成したリポジトリに対して、ローカルからコンテナイメージをプッシュし、
SPCS上で使用するということが可能になります。
コンピューティングプール
コンピューティングプールとは、1つ以上の仮想マシンノードの集合体です。
サービスやジョブはコンピューティングプールを使って実行されるため、
SPCSでは予め作成しておく必要があります。
コンピューティングプールは以下の内容で構成されています。
- プロビジョニングする仮想マシンのタイプ
仮想マシンには、大きく分けてCPUとGPUがあり、
その中でもvCPU・メモリ・ストレージ容量も様々です。
コストを重視するのであればCPUを、
機械学習の様な高負荷な処理をするのであればGPUといった具合に、
ユースケースによって選択できます。 - コンピューティングプールの最小・最大ノード数
コンピューティングプールにはオートスケーリングが備わっており、
負荷によってノード数が変化します。その変化幅を設定します。
チュートリアル
チュートリアルでは、以下のことについて学べます。
- SPCSを利用するための準備・設定
- サービスの作成
- ジョブの作成
また、高度なチュートリアルが別枠で提供されています。 上記では、サービス間通信について学ぶことが出来ます。
チュートリアルでは、コンテナを動作させるためのコードも提供されています。
コードの見直しフェーズで、各コードの動作について詳しく説明されているため、
理解しやすい内容となっています。
SPCSへの移管
移管するコンテナ
- 不定期かつ必要に応じてローカルで動作するもの
- Snowflakeからデータを取得し、データを解析・加工したものを出力する
移管した理由
コンテナとSnowflake間のデータのやり取りを最適化するため。
移管前の状態
移管前では、ローカル・AWS・Snowflakeの3つの環境を使用していました。

このコンテナが作られた時、既にSnowflakeへデータを登録するLambdaやStepfunctionsが存在していたので、コンテナ内でSnowflakeへのデータ登録処理は行わずLambda等を流用していました。
その為、ローカルからS3へのファイル配置が手動だったり、Stepfunctionsの起動が手動だったりと良い状態とは言えませんでした。
移管後
移管後では、ローカル及びAWS環境が不要となりました。
(SPCSにコンテナをプッシュする場合、ローカルの環境構築は必要)

結果、手動部分が大きく改善されました。
また、Snowflakeだけで完結するようになり、データの取得や登録処理がキレイになりました。
移管でやったこと
1.SPCS環境の準備
まず、SPCS用の環境を作成しました。
内容はチュートリアルの通りにsnowsightで作成しました。
結果、以下のリソースが作成されます。
- ロール
- データベース
- スキーマ
- ウェアハウス
- コンピューティングプール
- イメージリポジトリ
- ステージ
2.リソースの修正
次に各リソースの修正です。
何をどうSPCS用に修正すればよいのか情報もなくわからなかったので、
とりあえずチュートリアルにあるソースを参考にしました。
-
Dockerfile
ベースイメージをSPCS用に修正する必要があるかと思いましたが、
変更しなくても問題ありませんでした。 -
requirements.txt
そのままでOK。 -
コンテナ内のpyファイル
このコンテナではpythonを動作させていました。
移管に伴って、python用SnowflakeコネクタからSnowparkを使用するようにしました。
これは、チュートリアルのソースでSnowparkが使用されていたこと、
直近チーム内でSnowparkを使用するようにしようとしていたことから変更しました。 -
Snowflakeへの接続情報
移管前はSnowflake接続情報を設定ファイルに外だししており、
動作時に設定ファイルを読み込んで接続情報を取得するようにしていました。
SPCSでは、Snowflakeがうまいことしてくれて環境変数から接続情報を取得出来ます。
その為、設定ファイルの読み込みをやめて、コンテナ内から接続するように修正しました。
Connecting to Snowflake from inside a container
公式チュートリアル2では、以下の様に使用されています。
main.py file
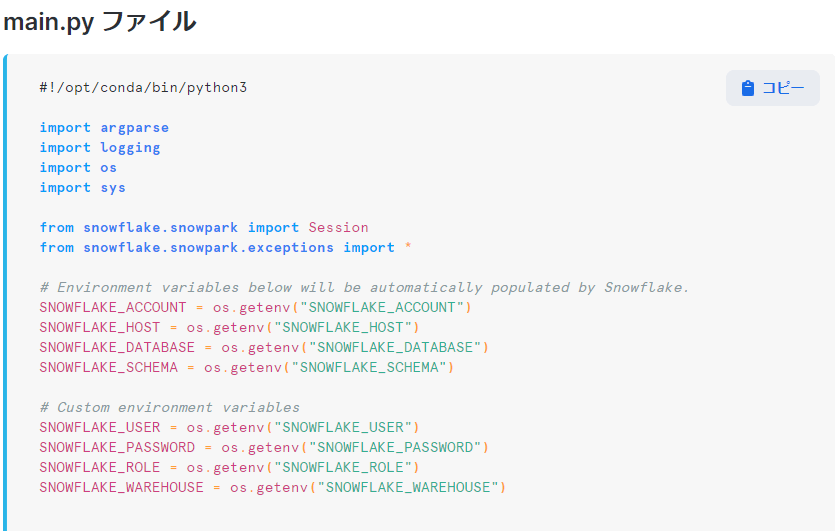
また、仕様ファイル(spec.yamlファイル)に環境変数を指定していた場合は、その値がオーバーライドされる為、任意の値に変更することもできます。
containers.env field
3.リソースの作成
既存になく、新たに作成するものです。
- 仕様ファイル
Service specification reference
SPCSで必要なファイルです。
このファイルにコンテナの情報・引数・環境変数・エンドポイント等、
様々な情報を必要に応じて記載します。
作成した仕様ファイルは、SPCS用に作成したステージにアップロードして使います。
今回は、コンテナイメージの情報と環境変数の指定を行っています。(下記内容は一例です)
spec:
container:
- name: main
image: /test_db/test_schema/test_repository/image_name:test
env:
SNOWFLAKE_WAREHOUSE: test_warehouse
4.リソースのビルド&アップロード
リソースの作成・修正が完了したら、SPCSで使用できるようにします。
基本的に、dockerコマンドを使用して作業します。
ここもチュートリアルに則って行っています。
# docker build
docker build --rm --platform linux/amd64 -t <repository_url>/<image_name> .
# docker login
docker login <registry_hostname> -u <username>
# docker push
docker push <repository_url>/<image_name>
仕様ファイルについては、snowsightからアップロードします。
アップロード先は、SPCS環境準備で作成したステージです。
5.サービスの作成
最後に、サービスを作成しました。
これでローカルで動作していたコンテナが、Snowflake上で動作するようになりました。
-- サービスの作成
CREATE SERVICE <service_name>
IN COMPUTE POOL <compute_pool_name>
FROM @<stage_name>
SPECIFICATION_FILE='<spec.yaml_name>';
サービスを停止する場合には、ALTER SERVICEを使用して停止できます。
ex. ローカルテスト
SPCSを動作させてどうなるかを試しながらやっていたのですが、
SPCSが動作しない・中断もできないといった事象が発生しました。
なので、コンテナの問題なのかSPCSの問題なのかを切り分けるために、ローカルテストを行いました。
ローカルテストといっても、特別なことを行うわけではなく
docker runコマンドを使ってコンテナを実行し正常終了するかを確認しました。
仕様ファイルで環境変数を使用している場合や、アカウント情報が必要な場合は
それらを引数として渡せばOKです。
docker build --rm -t image_name:local .
docker run --rm -e SNOWFLAKE_ACCOUNT=<SNOWFLAKE_ACCOUNT> -e SNOWFLAKE_HOST=<SNOWFLAKE_HOST> image_name:local
チュートリアルにおいても、ローカルテストについて記載されています。
移管してよかった点
-
コンテナ利用者のコンテナ動作環境構築が不要になった
まず、このコンテナはコンテナ開発者=利用者ではありませんでした。
その為、移管前は開発者・利用者問わずローカルでのコンテナ動作環境を構築する必要がありました。
しかし、SPCSへの移管によりSnowsight上で操作できるようになった為、
ローカルでのコンテナ動作環境構築が不要になり、より簡単にコンテナを利用できるようになりました。 -
セキュアになった
ここが一番大きいメリットです。
Snowflakeだけで処理が完結するようになり、データが外部に出なくなったので、
Snowflake+他クラウドサービスの構成よりセキュアになりました。
環境からデータを外に出さないでほしいといった要件に対応できるようになるので、そういったケースに当てはまる場合はSPCSが検討できると思います。
また、シークレット情報を持たせておかなくてもSnowflakeに接続できるようになったので、
シークレット情報の管理に頭を悩ませずに済むようになったのも良い点です。
おわりに
あまりコンテナに触れてこなかったこともあり、動作させるまでが非常に大変でしたが、
試行錯誤の末なんとか移管できました。
PuPrなので、まだ未知の部分はありますが、
GAされた際にはフィードバックを経て更に良くなっているのではないでしょうか。
現状Snowflakeを使っていたりコンテナを使っている場合には、使用を検討できるサービスと思うので是非試してみてください。
Discussion