0. 本記事の内容
扱うこと
- airflowのsnowflake operatorを用いてsnowflakeにデータを取り込む方法
扱わないこと
- snowflakeのcopy intoコマンド等の詳細
- airflowの構築方法
- airflowのconnection設定
1. なぜSnowflake Operator?
Snowflakeへデータを取り込みするには
- fivetran,trocco等のツール
- snowpipe
- snowflake task
等がよく使用されているかと思います。
一方ETL処理にdbtを用いており、そのオーケストレーションにairflowを用いているケースも多いでしょう。ここでデータ取り込みに関して上記の手段よりもairflowにて取り込み処理を行った方が以下のような利点
- UIで成功・終了確認がairflowのUI上ですべてできる
- エラー時の通知機能を使いまわせる
- 同一リポジトリでの開発・デプロイが完結する
があると考え、airflowのsnowflake operatorをデータ取り込みをカッコよくやる方法を検討しました。
2. 取り込み要件
- S3のデータ配置
- ファイルが
バケット/data下にIF名/YYYYMMDD/.*形式で配置される
- ファイルが
- 取り込み処理
- 一度に複数のIFのファイルを取り込むことができる
- 取り込み処理時のS3パス
- 指定がない場合は各IFで最新の日付パス(YYYYMMDD)のデータを取り込むことができる
- 手動で指定する場合は任意の日付パスを取り込むことができる (airflowでは手動でパラメータを渡すことが可能)
3. 実装・処理
3.1 ディレクトリ構成
本記事では以下のようなディレクトリ構成で実装しました。
└── dags
├── etl_dags
│ ├──if_meta_files(各IFの取り込み時の情報を示したjsonファイルを置く)
│ │ ├──raw_customers.json
│ │ └──raw_orders.json
│ ├──src
│ │ └──template
│ │ └── copy_into_fmt.py(snowflake取り込み時のSQLのテンプレート)
│ └── data_load.py (dagファイル)
3.2 処理イメージ・実装
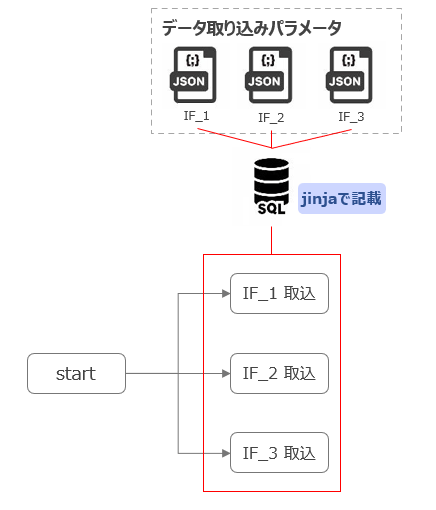
-
dagファイル(data_load.py)において、if_meta_files下にあるjsonファイルを読み出し、1つのjsonファイルにつき、1つのデータ取り込みtaskをfor文で生成します。
-
jsonから読み出した取り込みパラメータ(フォーマット・列など)をjinjaで書かれたテンプレート(copy_into_fmt)にわたし、SQLを生成します。
dagファイルは以下となります。
data_load.py
from datetime import datetime, timedelta
from airflow import DAG
from airflow.models import Variable
from airflow.operators.dummy_operator import DummyOperator
from airflow.providers.snowflake.operators.snowflake import SnowflakeOperator
from etl_dags.src.template.copy_into_fmt import copy_into
import pendulum
import glob
import os
import json
default_args = {
'owner': 'airflow',
'depends_on_past': False,
"provide_context": True,
'start_date': datetime(2023, 7, 27, tzinfo=pendulum.timezone('Asia/Tokyo')),
'retries': 0,
'retry_delay': timedelta(minutes=10),
}
CUR_DIR = os.path.abspath(os.path.dirname(__file__))
TARGET = Variable.get("target")
snowflake_json_files = glob.glob(f"{CUR_DIR}/if_meta_files/load/*.json")
with DAG(
dag_id='data_load',
description='データの取り込み',
default_args=default_args,
schedule_interval=None,
catchup=False,
dagrun_timeout=timedelta(hours=15),
) as dag:
start_task = DummyOperator(
task_id='start_task',
dag=dag
)
for snowflake_json_path in snowflake_json_files:
if_name = os.path.splitext(os.path.basename(snowflake_json_path))[0]
with open(snowflake_json_path, encoding="utf-8") as f:
snowflake_if_meta = json.load(f)
snowflake_copy_into = SnowflakeOperator(
task_id=f"load_{if_name}",
sql=copy_into,
role=f"Y_INAOKA_{TARGET}_ADMIN",
warehouse=f"Y_INAOKA_WH_{TARGET}",
schema="RAW",
database=f"Y_INAOKA_DB_{TARGET}",
snowflake_conn_id="snowflake_connection",
params={
"if_name": if_name,
"target": TARGET,
"stage_name": f"y_inaoka_stage_{TARGET}",
"select_col": snowflake_if_meta['select_col'],
"file_format": f"{snowflake_if_meta['file_format']}_{TARGET}",
"extension": snowflake_if_meta['extension']
},
do_xcom_push=False,
)
start_task >> snowflake_copy_into
SQLのテンプレートファイルは以下となります。
copy intoの際にselectで列を記載していますが、S3のファイルからSnowflakeに取り込む際に以下のような処理をする必要がない限り、記載は不要です。
- 列を絞る
- 列順を変える
- S3のパスや取り込み時刻の列を追加する
copy_into_fmt.py
copy_into = """
{% if params.if_name in dag_run.conf.keys() %}
{% for manual_date in dag_run.conf[params.if_name] %}
{% set manual_date = manual_date | string %}
copy into {{ params.if_name }}
from (
select
{% for column_name in params.select_col -%}
{% if not loop.first -%},{% endif %} {{ column_name }}
{% endfor -%}
, current_timestamp(2)
from
@{{ params.stage_name }} (
file_format => {{ params.file_format }}
, pattern => 'data/{{ params.if_name }}/{{ manual_date }}/.*'
)
);
{% endfor %}
{% else %}
list @{{ params.stage_name }}/{{ params.if_name }}/;
set file_path = (
select
'data/{{ params.if_name }}/' || to_varchar(split_part(regexp_replace("name", 's3://'),'/',4)) || '/.*'
from
table(result_scan(last_query_id())) order by 1 desc
limit 1
);
copy into {{ params.if_name }}
from (
select
{% for column_name in params.select_col -%}
{% if not loop.first -%},{% endif %} {{ column_name }}
{% endfor -%}
, current_timestamp(2)
from
@{{ params.stage_name }} (
file_format => {{ params.file_format }}
, pattern => $file_path
)
);
{% endif %}
"""
パラメータのjsonファイルはこちらです。この記事ではjsonで記載しましたが、ymlやcsvでも問題ないかと。
raw_customers.json
{
"if_name":"raw_customers",
"file_format": "y_inaoka_csv_format",
"select_col":[
"$1",
"$2",
"$3",
"$4"
],
"extension":"csv"
}
raw_orders.json
{
"if_name":"raw_orders",
"file_format": "y_inaoka_parquet_format",
"select_col":[
"$1:id::NUMBER",
"$1:user_id::NUMBER",
"$1:order_date::DATE",
"$1:status::TEXT"
],
"extension":"parquet"
}
3.3 airflowのUIから確認
上記のディレクトリ構成でファイルを配置すると、rawテーブルを取り込む2つのtaskが生成されます。
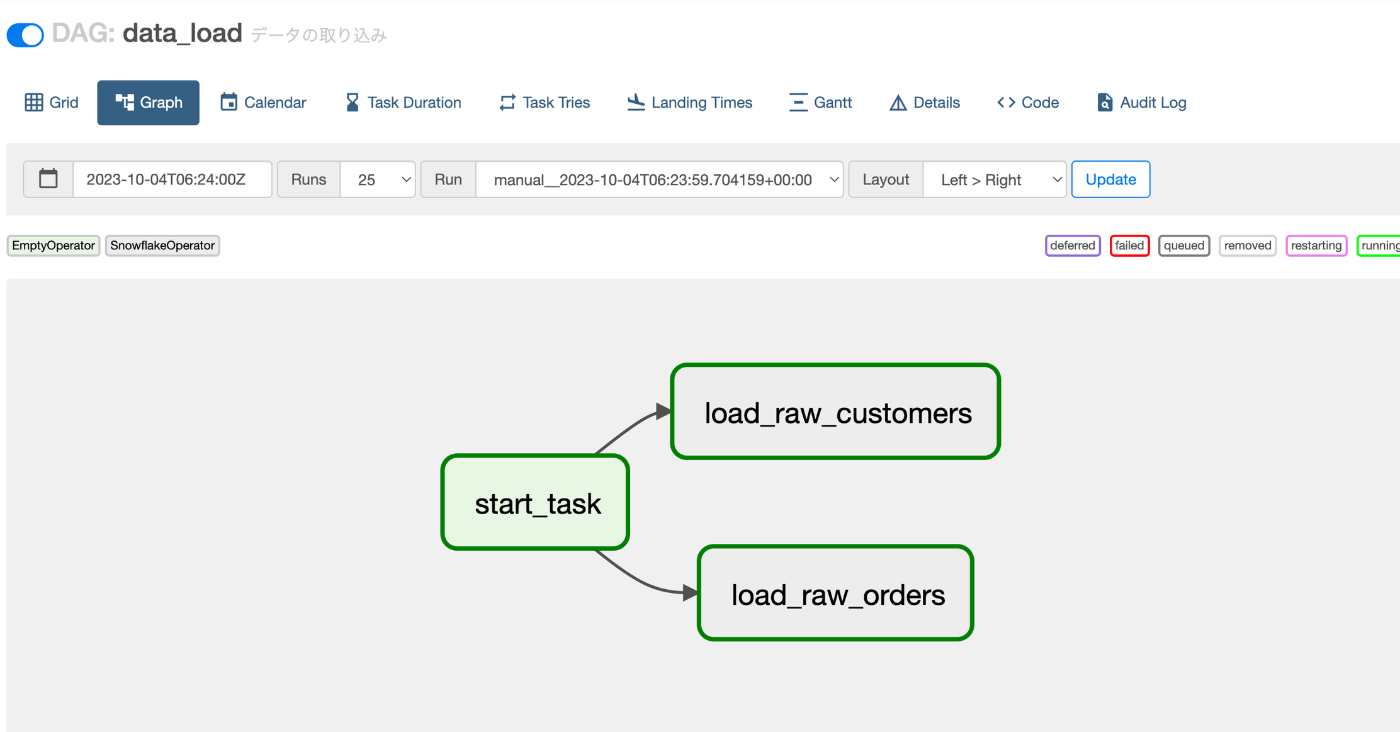
3.4 指定のS3の日付パスがない場合の挙動
S3の日付パスを指定せずに実行した場合、
以下が実際に流れるSQLです。最新日付パスのデータを取り込みを行います。
list @y_inaoka_stage_dev/raw_customers/;
set file_path = (
select
'data/raw_customers/' || to_varchar(split_part(regexp_replace("name", 's3://'),'/',4)) || '/.*'
from
table(result_scan(last_query_id())) order by 1 desc
limit 1
);
copy into raw_customers
from (
select
$1
, $2
, $3
, $4
, current_timestamp(2)
from
@y_inaoka_stage_dev (
file_format => y_inaoka_csv_format_dev
, pattern => $file_path
)
);
3.5 S3の日付パスを指定する場合に流れるSQL
まずairflowのUIのTrigger DAG w/ configより下記のようなパラメータを与えます。
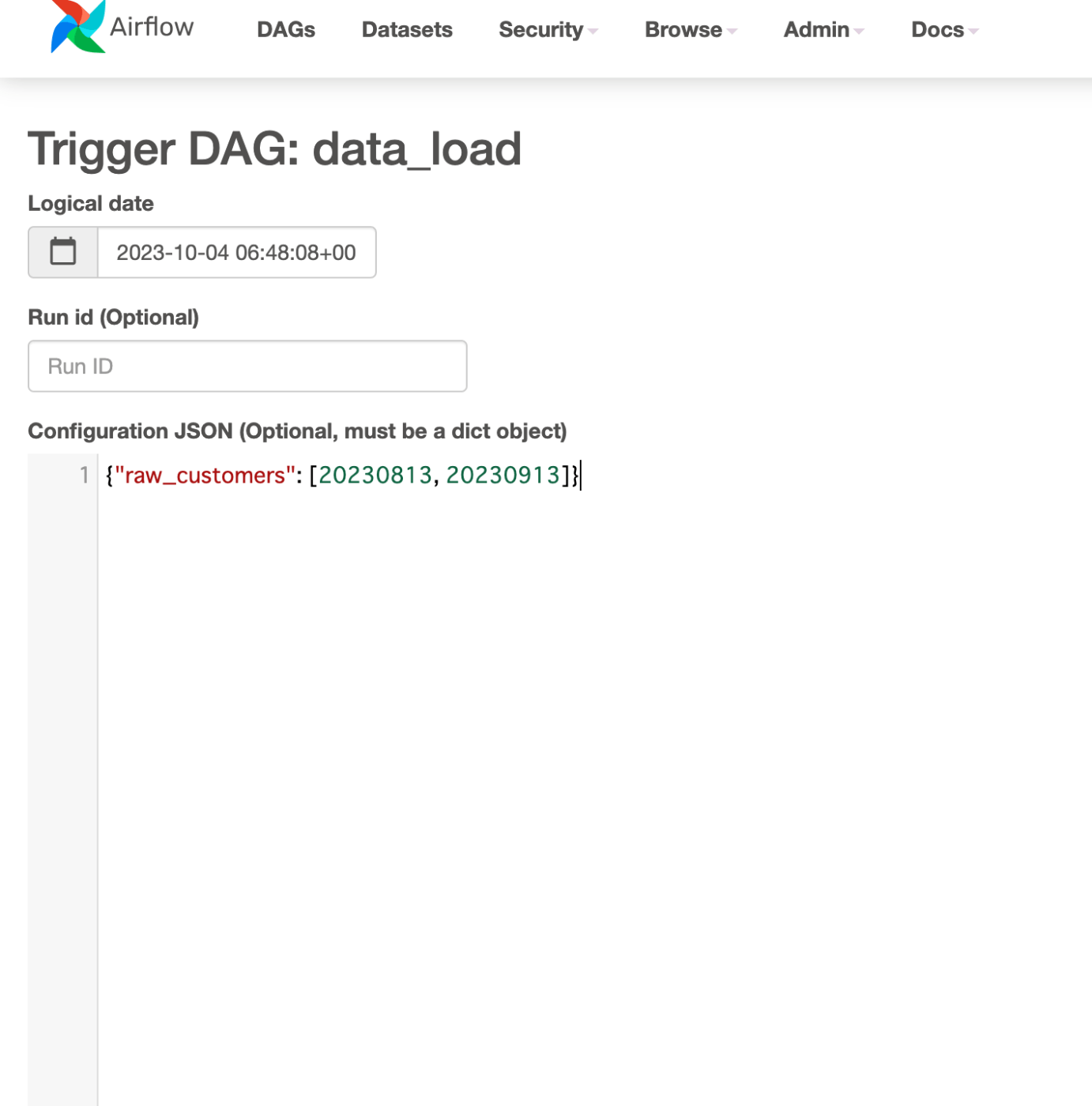
以下が実際に流れるSQLです。複数パスの取り込みを行います。
copy into raw_customers
from (
select
$1
, $2
, $3
, $4
, current_timestamp(2)
from
@y_inaoka_stage_dev (
file_format => y_inaoka_csv_format_dev
, pattern => 'data/raw_customers/20230813/.*'
)
);
copy into raw_customers
from (
select
$1
, $2
, $3
, $4
, current_timestamp(2)
from
@y_inaoka_stage_dev (
file_format => y_inaoka_csv_format_dev
, pattern => 'data/raw_customers/20230913/.*'
)
);
4 実際に作成した感想
実際に作成してみて、以下のようなメリット・デメリットを感じました。総じてメリットの方が多く、うまくいった検証だと感じています。
メリット
- json追加のみで取り込み機能を追加できる
- jsonファイルのパラメータを変えるのみでファイル形式の変更に対応できる
- jsonファイルは規則性があるので設計書などから自動出力するツールを作成することで設計書と一貫性が担保できる
- 手動でパス指定できるので、データ移行時など複数取り込みたいときにも容易に対応できる
デメリット
- snowflakeコンソールからcopy into文やstage上のデータのクエリをしたい場合、一度airflowを実行しrenderされたクエリを得る、もしくは自力で書く手間が発生する
5. 参考

Discussion