※この記事はdbt Advent Calendar 2024の13日目です。今年お世話になったCosmosについて書きました。
Cosmosは、dbtをAirflow上で効率的に運用するためのサードパーティパッケージです。モデルを個別のAirflowタスクに分割することで、柔軟なスケジューリングや失敗時の再実行が可能になります。
ただし、その便利さの一方で、動作が非常に重いという課題があります。BashOperatorを使った場合と比べ、実行速度が大幅に低下し、システムリソースにも高い負荷をかけます。
2024年はCosmosのパフォーマンス改善が大幅に進み、Astronomerの資料[1]によれば、14件の新機能追加によって全体で25%の速度向上が達成されました。が、現場で利用する際には、設定やチューニングが欠かせないと思っています。
本記事では、Cosmosを使うべきシーンと、実践的なパフォーマンスチューニング方法を解説します。
Airflow+dbtの構成ごとの速度比較
Cosmosを利用する際の最大の課題が「実行速度」です。jaffle_shopの6年分データセットを使用し、以下の条件で測定しました。
- 実行環境: AWS MWAA (mw1.small)
- 比較対象: BashOperator、Cosmos v1.3(去年の今頃のバージョン)、Cosmos v1.7(現時点最新)
| 構成 | DAG全体の実行時間(Duration) | BashOperator比 |
|---|---|---|
| BashOperator | 00:44 | - |
| Cosmos v1.3 (ExecutionMode.Virtualenv) | 04:41 | 約6.9倍 |
| Cosmos v1.3 (ExecutionMode.Local) | 04:10 | 約6倍 |
| Cosmos v1.7 (ExecutionMode.Virtualenv) | 05:19 | 約7.7倍 |
| Cosmos v1.7 (ExecutionMode.Local) | 03:53 | 約5.6倍 |
めちゃくちゃ遅いのがわかると思います。
- BashOperatorが最速
- BashOperatorはAirflow内でシンプルなdbt CLIコマンドを実行するだけで、最小限のオーバーヘッドで済みます。
- Cosmosは改善後も依然として低速
- 最新のCosmos (v1.7) では、Localモードで、それなりの速度改善が見られました。それでもBashOperatorに比べて約5.6倍遅い結果となります。
- Virtualenvモードはとくに遅い
- 各タスクごとに仮想環境を立ち上げるため、オーバーヘッドが大きく影響してしまいます。
Cosmosの使いどころ
Cosmosは処理の低速化という課題を抱えていますが、それでも導入を検討する価値があるシーンがあります。最大のメリットは、「失敗したモデルだけを再実行できること」です。
例として、以下のようなジョブを考えます。一部のソースの連携が遅延し、Stagingモデルで組んでいたdbt testが失敗、後続のモデルが実行されませんでした。

このような状況では、遅延したソースの連携が完了したタイミングで、失敗したモデルだけを再実行するのが理想的です。
冪等性のあるジョブの場合
もっとも簡単な解決策は、各モデルの処理を冪等に設計することです。つまり、同じデータを複数回処理しても結果が変わらないようにしておく方法です。
例えば以下のようなアプローチです。
- モデルが新規データのみを処理する設計になっていれば、リトライ時に全体を再実行しても問題ありません。
- delete+insert戦略を用いている場合も、リトライ時に全体を再実行しても問題ありません。ただし、毎回処理をやり直してしまうためコンピューティングの無駄遣いには繋がります。
冪等性がない場合
モデル内で状態を持つ処理(累積計算など)が含まれており、かつ上記の冪等性戦略がとられていない場合では、同じモデルを複数回実行するとデータが重複する可能性があります。
このようなケースでは、Cosmosを使ってAirflow上でモデルを個別のタスクに分割することで、失敗したモデルだけを再実行できます。
つまり、構造的な問題が含まれているdbtプロジェクトを運用するとき、Cosmosを使えばなんとかリカバリーのハンドリングを頑張れるようになります。
パフォーマンスチューニング
チューニングの前提:Cosmosの動作原理
チューニングに関して具体的な解説に入る前に、動作原理を解説します。まずは簡単にAirflowのアーキテクチャを確認します。

公式のArchitecture Overviewより引用[2]
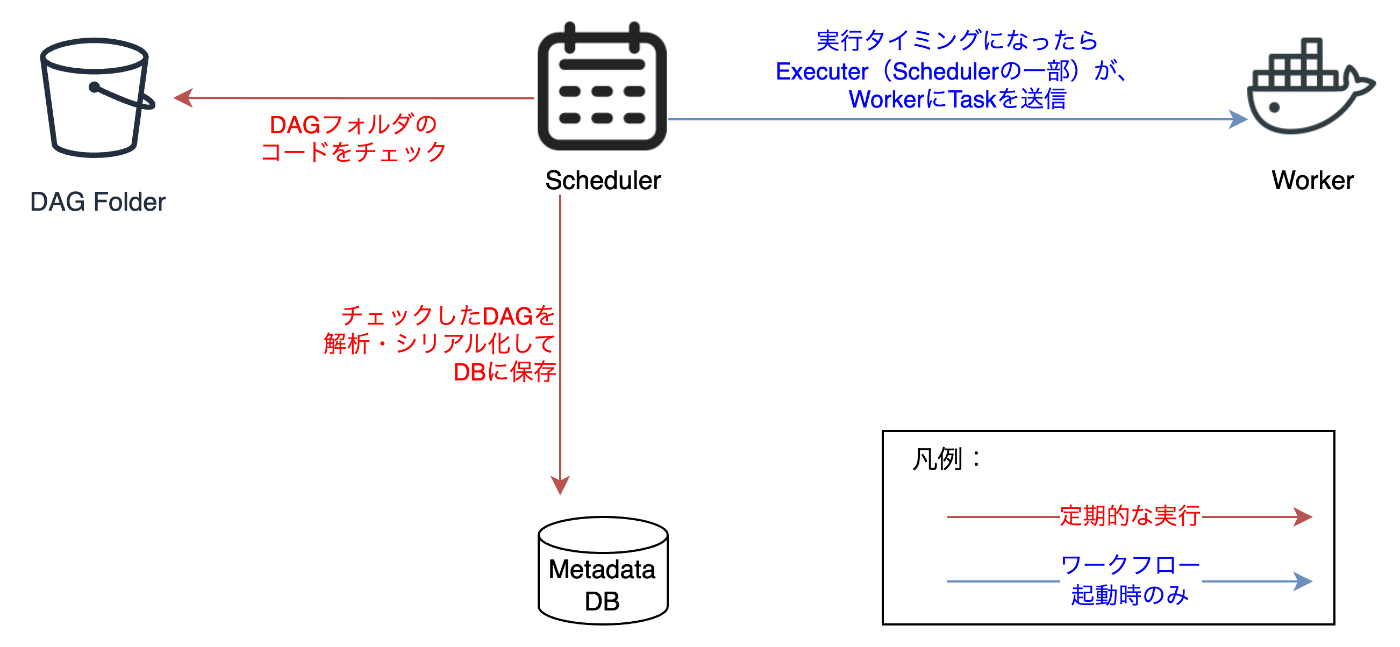
一部を抜き取りわかりやすくしたもの
- Scheduler
- DAGコードを解析し、メタデータDBに保存。
- タスクをスケジュールし、Executor経由でWorkerに送信。
- Worker
- 実際にタスクを実行する環境。
- クラウド環境では、Fargate(MWAA)やKubernetes(k8s)として動作可能。
Cosmosを導入した場合
Cosmosは、SchedulerがDAGコードを解析する段階に介入し、dbtモデルを個別のAirflowタスクに変換します。
- DAGコードの解析
- SchedulerがDAGコードを読み込み、指定されたdbtプロジェクトをパース。
- パース方法は、manifest.jsonの利用やdbt lsコマンド実行など、いくつかのオプションがあります。
- タスクへの変換
- パースされたdbtモデルごとに、対応するオペレータが割り当てられます。
- ローカル環境の場合: DbtSeedLocalOperatorなど。
- Kubernetes環境の場合: DbtSeedKubernetesOperatorなど。
- オプションの追加処理
- snapshotやdocs生成など、追加操作が必要な場合には、該当するオペレータがDAGに追加されます。
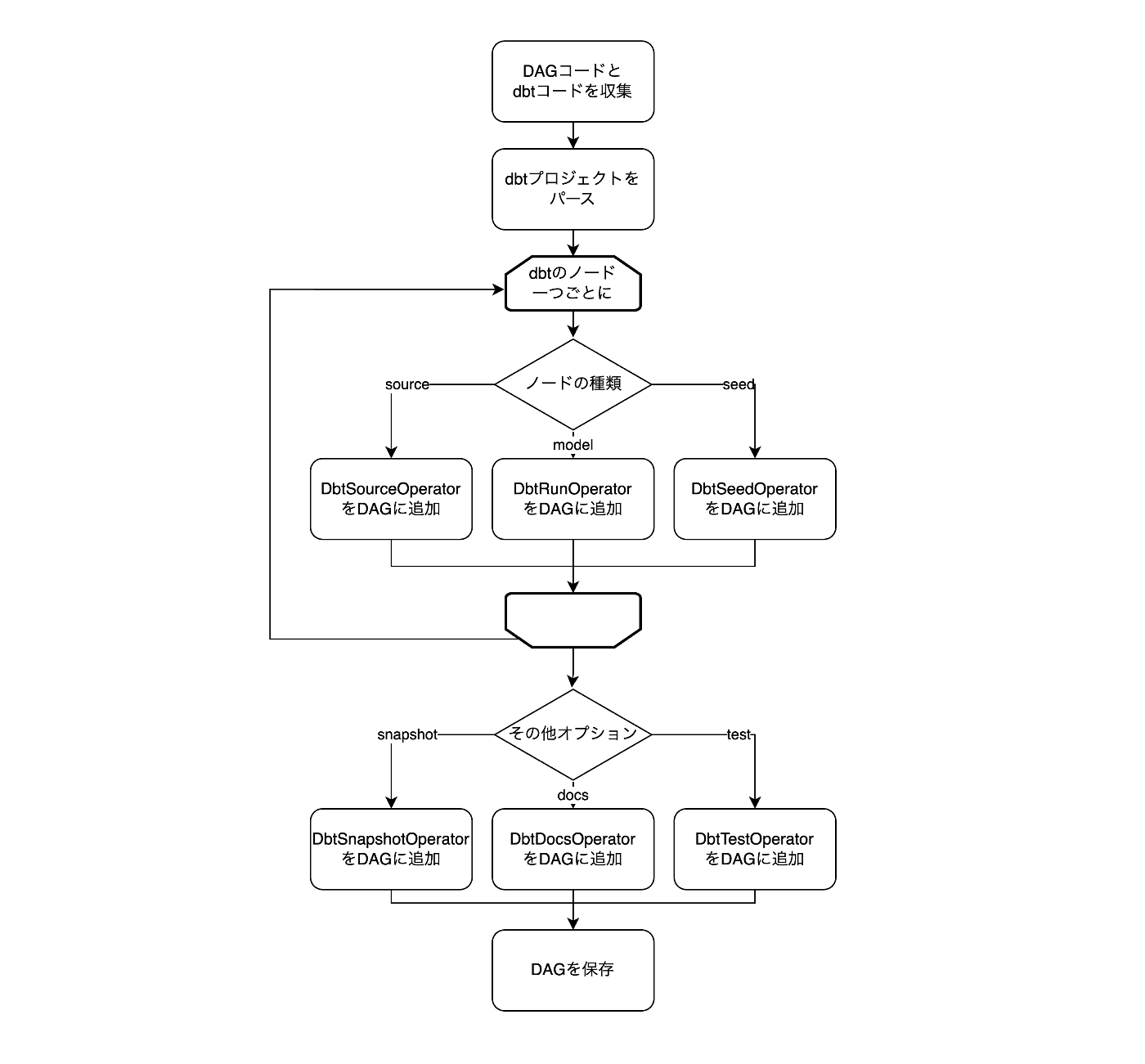
動作イメージ(細かいところは正しくないが、あくまでイメージとして)
パフォーマンスチューニングのポイント
前節のとおり、Cosmosがdbtを実行するのは、実際のタスクの稼働時だけでなく、DAGのパースも含みます。それぞれについてパフォーマンスを考える必要がありそうです。
- DAG解析の効率化
- load_methodオプションを適切に設定し、dbtプロジェクトのパースを最適化。
- 例: DBT_MANIFESTを使用して、manifest.jsonを事前に配置。
- タスク実行の高速化
- 実行モードをLocalに設定し、仮想環境やコンテナの初期化を回避。
- 必要に応じてキャッシュ機能を活用。
DAGのパース
DAGのパースが非効率だと、Schedulerへの負荷につながり、場合によってはスケジューリングの失敗などのクリティカルな問題につながります。定期的な間隔で実行されるDAGのパースは、できるだけ軽量に済むように工夫しましょう。
dbtプロジェクトの解析方法(Parsing Method)
Cosmosがdbtプロジェクトをパースする手法は、RenderConfigのload_methodで制御できます。指定可能な方法は以下の通りです。
| load_method | 特徴 |
|---|---|
| DBT_MANIFEST | あらかじめCIなどでdbt compileを行なっておき、DAGフォルダにmanifest.jsonを配置しておくことで、Cosmosがmanifest.jsonからプロジェクトをパースできるようにします。select/excludeはcosmosのパーサー内の独自処理で行われます。つまり、dbtのselect/excludeロジックとは厳密に動作が一致しないケースがあります(たとえば、デフォルトSelectorは適用されません)。 |
| DBT_LS | Scheduler内部でdbt lsコマンドを実行し、その結果得られたノードをレンダリングします。つまり、DBT_MANIFESTに比べて、より堅牢であることが期待できます。一方で、lsコマンド結果のキャッシュを有効にしない場合には、常にSchedulerのサブプロセスでdbtコマンドが実行されることになるため、サービスに高負荷をかけてしまいます。 |
| DBT_LS_FILE | dbt lsコマンドの実行結果をファイルとして保存しておき、DAGフォルダに格納することで、Cosmosはdbt lsを実行せずにDBT_LS戦略を処理できます。 |
| Custom | Cosmos独自の方法でdbtプロジェクトを展開します。具体的には、dbtプロジェクト内にあるSQL、python、CSVファイルをそれぞれ開き、モデルやseedを収集します。それぞれの手法の中で最も堅牢ではない手法であり、他の戦略のフォールバック先として使用されます。直接の利用は推奨しません。 |
| Automatic | デフォルトの挙動です。manifest.jsonが見つかる場合にはDBT_MANIFESTの戦略でパースし、見つからなければDBT_LSを採用します。dbt lsを実行するための前提も満たしていなければ、Customを採用します。 |
推奨戦略: DBT_MANIFEST
Automaticの既定動作がDBT_MANIFESTであることからもわかるように、Cosmosの推奨はDBT_MANIFESTです。manifest.jsonを事前に公開できるのであれば、この戦略を採用すると良いでしょう。
example = DbtTaskGroup(
project_config=ProjectConfig(
# ProjectConfigでmanifest.jsonのパスを指定
manifest_path=DBT_ROOT_PATH / "jaffle_shop" / "target" / "manifest.json",
project_name="jaffle_shop",
),
render_config=RenderConfig(
# RenderConfigで戦略を固定
load_method=LoadMode.DBT_MANIFEST
),
)
動的にDAGで動かすモデルを変化させたい場合: DBT_LS
動的にselectやexcludeを指定したい場合には、DBT_LSを使用します。ただし、この戦略はdbtコマンド実行時の負荷が高いため、キャッシュを有効にすることを推奨します。Cosmos v1.5以降では、dbt lsコマンドの結果をAirflow Variablesにキャッシュする機能が追加されました。
example = DbtTaskGroup(
project_config=ProjectConfig(
dbt_project_path="/path/to/dbt/project",
project_name="jaffle_shop",
),
render_config=RenderConfig(
load_method=LoadMode.DBT_LS
),
)
2. DAGの実行
実行時のdbtの起動方法は、ExecutionConfigのexecution_modeとinvocation_modeで指定できます。
| execution_mode | 特徴 |
|---|---|
| Local | Airflow Workerのローカルにインストールされたdbtを利用して、モデルを実行します。これがすべてのオプションの中で最も高速であり、まずはこのモードの使用を検討することをお勧めします。 |
| Virtualenv | Airflow Workerの中でdbtをインストールしたPython仮想環境を作成し、モデルを仮想環境の中で実行します。仮想環境の生成を伴うため、実行時のオーバーヘッドがより大きくなるため、低速です。 |
| docker | モデル実行用のDockerコンテナを新たに起動します。 |
| kubernetes | モデル実行用のk8s podを新たに起動します。 |
| aws_eks | モデル実行用のk8s podを、EKSのクラスター内で新たに起動します。 |
| azure_container_instance | Azure Container Instancesから起動します。 |
| gcp_cloud_run_job | GCP Cloud Runから起動します。 |
| airflow_async | (現時点ではまだ正式リリースではありません。dbt-bigqueryでのみ利用可能です。)AirflowのDefferable Operatorでdbtを実行します。非常にクエリ時間が長いモデルがあったときに、そのモデルの呼び出し中にワーカーを開放することができるため、ワーカーをより効率的に利用できる可能性があります。 |
多くのオプションが存在しますが、ここでは特にLocalとVirtualenvについて詳しく解説をします。
推奨戦略: Local
基本的な構成
Localモードでは、Workerノードにdbtをインストールする必要があります。ただし、AirflowとdbtのPython依存関係の競合が問題となる場合が多いです。ここが一番のハードルになると思います。
公式ドキュメントに互換性の対応表があるので、参照してください(とはいえ、この表でバツがついていなくても、マイナーバージョンによって対応しないケースが散見されます。実際に試すのをお勧めします)。
Localモードを利用する場合のみ、さらにinvocation_modeを指定して動作を細かく制御できます。DBT_RUNNERの利用を推奨します。
| invocation_mode | 特徴 |
|---|---|
| SUBPROCESS | タスクのプロセスから別のサブプロセスを新たにオープンし、dbt cliを実行することで、モデルの実行を行います。 |
| DBT_RUNNER | dbtのv1.5で追加されたプログラム呼び出しを使用して、dbtを実行します。SUBPROCESSに比べて、プロセス生成のオーバーヘッドがないため、より高速です。 |
キャッシュ
dbtの実行をさらに高速にするため、Cosmosがサポートしているキャッシュがうまく効くように構成する必要があります。
dbtのPartial parseで生成される中間ファイル「partial_parse.msgpack」を、各タスクで再利用できるようにします。
ドキュメントにもあるとおり、RenderConfigのenable_mock_profileをFalseにしてください。
@dag(
schedule="0 7 * * *",
start_date=datetime(2024,11,11),
catchup=False
)
def cosmos_dag():
profile_config = ProfileConfig(
profile_name="default",
target_name="dev",
profile_mapping=SnowflakePrivateKeyPemProfileMapping(
conn_id="snowflake_conn"
)
)
render_config = RenderConfig(
load_method=LoadMode.DBT_MANIFEST,
test_behavior=TestBehavior.AFTER_EACH,
enable_mock_profile=False # partial_parseの有効化
)
execution_config = ExecutionConfig(
execution_mode=ExecutionMode.LOCAL, # Localを指定
invocation_mode=InvocationMode.DBT_RUNNER # DbtRunnerを利用
)
basic_cosmos_dag = DbtTaskGroup(
project_config=ProjectConfig(
DBT_ROOT_PATH / "jaffle-shop",
manifest_path= DBT_ROOT_PATH / "jaffle-shop" / "target" / "manifest.json"
),
operator_args={
"full_refresh": True,
},
render_config=render_config,
profile_config=profile_config,
execution_config=execution_config,
group_id="cosmos_dag_group"
)
basic_cosmos_dag
cosmos_dag()
Virtualenv
インストールしたいAirflow×dbtの組み合わせでローカルインストールに失敗する場合には、Virtualenvや、その他実行モードを利用する必要があります。
Virtualenvではそこまでユーザーが意識的にコントロールする設定はありませんが、内部的な挙動としては生成したvenvのキャッシュについて理解しておくと良さそうです。これによりCosmosの各Taskが都度venvを生成するのではなく、一度ワーカー内部で作られたvenvを、同じワーカーで動作するタスクの範囲では再利用してくれています。
まとめ
- Cosmosを使うと、dbtの実行は非常に遅くなります。
- しかし、モデルが冪等に作れないようなシーンにおいては、運用を楽にするためのツールとして非常に役に立ちます。
- Cosmosを利用するのであれば、できる限り高速に動作するよう、Localモードやキャッシュの有効化を意識しましょう。

Discussion