オーケストレーションツールのAirflowですが、ついに3.0のメジャーバージョンアップがやってきました!2.0は2020年にリリースされ、実に4年以上の月日をかけて作られたメジャーリリースだそうです。
気になった内容をご紹介します。
アーキテクチャーの変更(Task SDK)
モチベーション
歴史的に、Airflowのタスク実行は比較的信頼できるネットワーク クラスター内での実行とされてきました。つまり、各コンポーネントが相互に同じネットワークの中で通信し合うことで、タスク実行を実現していました。
- ExecutorとAirflow Workers上でタスクを起動するプロセス間のやり取り
- 接続と環境情報のためのワーカーとAirflowメタデータデータベース間のやり取り。
- ハートビート情報などのためのAirflow WorkerとAirflowの残りの部分との間のやり取り。
これは、すべてのAirflowのコンポーネントに関するコードとユーザーが作成したDAGコードが同じコンテナとプロセス内に配置されることで、実現されています。

v2までのアーキテクチャ。DBとWorkerの間で直接通信する。
この構成が、以下のような問題のタネになっていました。
- 依存関係の衝突
- 複数のデータチームが同じAirflow環境を使う時、それぞれのユーザーコードで利用されるライブラリ、Pythonパッケージのバージョンが違い、競合を起こしてしまう。
- 意図せずにAirflowのコアが依存しているパッケージをユーザーコードも参照してしまい、Airflowのバージョンアップと同時に予期しない壊れ方をしてしまう。
- スケーラビリティ
- Airflowのメタデータベースインスタンスがサポートする同時データベース接続数がボトルネックで、タスクインスタンスがスケールできない。
さらに、ネットワーク境界を超えた先での分散オーケストレーションにおいても、大きなハードルとなっていました。
- クラウドにあるAirflowから、社内プロキシの背後にいるオンプレミスで一部のワーカーを動かしたいのに...
- ワーカーがクラウドのメタデータベースやRedisへ接続する必要がある
- セキュリティ上のハードルの他、データベース接続がレイテンシーの障害になる可能性も出てくる
- さらに、ワーカーのメトリクスも収集したい場合、statsdのためにUDPまで穴あけが必要になる
どう変わるのか?
WorkerからAirflowクラスタへの通信がREST APIに一本化されます。これにより、WorkerをAirflowのデプロイメントに含める必要がなくなりました。
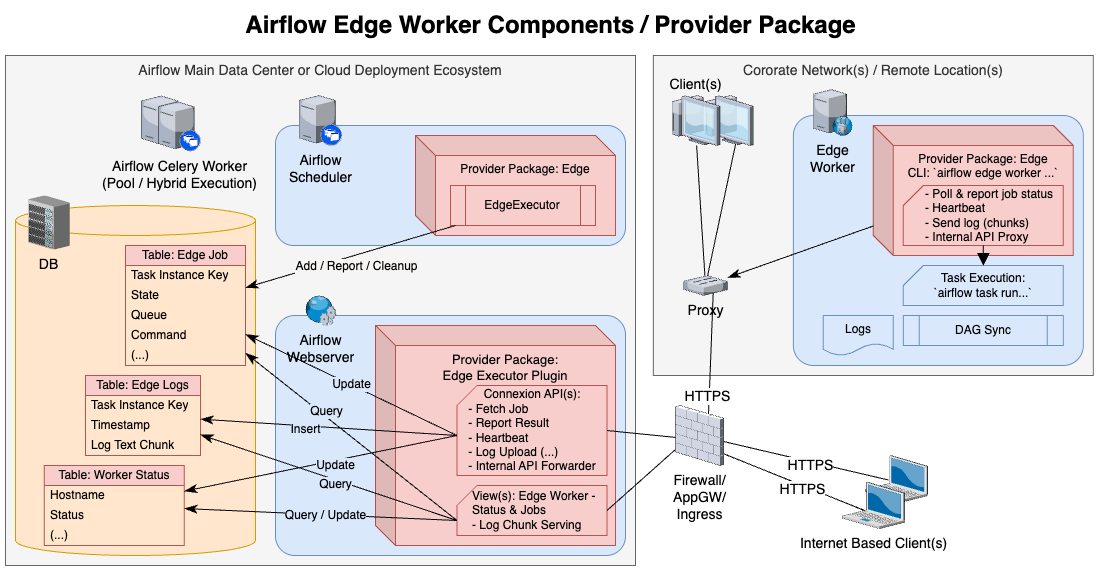
- ワーカーはAirflowデータベースにアクセスできなくなりました。
- ワーカーはAirflow REST APIを介して通信します。
- また、APIのサポートのため、Task SDKが導入されました。コンテナ、エッジ環境、その他のランタイムなどの外部システムでAirflowタスクを実行するための軽量ランタイム環境です。
また、今後のリリースでは以下が予定されています。
- Task SDKは言語非依存になるようデザインされており、Python以外の言語でもTaskを書いてExecutorへ送信できるようになります。
- Golang をはじめとする追加言語の TaskSDK が今後数か月以内にリリースされる予定です。
使ってみる
公式のdocker-compose.ymlが3.0.0で更新されているので、それを使用してローカルで起動します。
書き換えないと動かなかったところ
- バージョンタグが3.0.0で埋まっていなかったので変更
image: ${AIRFLOW_IMAGE_NAME:-apache/airflow:3.0.0}
- 環境変数に以下を指定しました。
AIRFLOW__API_AUTH__JWT_SECRET: 'secret'- これがないと、ワーカーとクラスターの間で認証トークンがずれて、通信に失敗しちゃいました。
% docker compose up -d --build
% docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
243e329e32d2 apache/airflow:3.0.0 "/usr/bin/dumb-init …" 2 hours ago Up 2 hours (healthy) 8080/tcp airflow-airflow-worker-1
f0f04f2606ab apache/airflow:3.0.0 "/usr/bin/dumb-init …" 2 hours ago Up 2 hours (healthy) 8080/tcp airflow-airflow-dag-processor-1
efa27dc98963 apache/airflow:3.0.0 "/usr/bin/dumb-init …" 2 hours ago Up 2 hours (healthy) 8080/tcp airflow-airflow-triggerer-1
7807427045e0 apache/airflow:3.0.0 "/usr/bin/dumb-init …" 2 hours ago Up 2 hours (healthy) 8080/tcp airflow-airflow-scheduler-1
78244a5d4ddf apache/airflow:3.0.0 "/usr/bin/dumb-init …" 2 hours ago Up 2 hours (healthy) 0.0.0.0:8080->8080/tcp airflow-airflow-apiserver-1
591d287ca246 postgres:13 "docker-entrypoint.s…" 2 hours ago Up 2 hours (healthy) 5432/tcp airflow-postgres-1
2e759c8f2d36 redis:7.2-bookworm "docker-entrypoint.s…" 2 hours ago Up 2 hours (healthy) 6379/tcp airflow-redis-1
以前は見られなかったサービスが起動していることに気づきます。
- dag-processor
- 以前はDAGファイルを解析するためのプロセスはSchedulerで実行されていましたが、3.0から切り出されたようです。
- apiserver
- API serverは、新しいAirflowのコアコンポーネントです。これがユーザー インターフェイスのバックエンドや、ワーカーとの通信を行うREST APIを提供します。
- webserver
- UIを提供するためのフロントエンドサーバーです。以前はWebserverが他コンポーネントとの通信を行いロジックを処理していましたが、3.0からはすべてのバックエンドをAPI serverに依存し、ウェブサーバー側ではビジネスロジックを処理しないようになりました。
- scheduler
- これまでに多くの責務を背負っていたSchedulerですが、3.0からはその名の通り、メタデータベースと通信してワークフローをいつ実行するかを決定する役目に集中するようになりました。
データ資産(Asset)
モチベーション
従来のAirflowは、ジョブをタスクの集まりとして解釈し、タスクが作った成果物そのものには注目していません。これがデータエンジニアリング以外の様々なユースケースに使用できる柔軟性を実現し、Airflowを流行らせた一因となっていました。
とはいえ、データパイプラインでは、その成果物であるデータの状態や健全性を担保することが最重要であるため、このタスクセントリックなアプローチにはデメリットがあります。
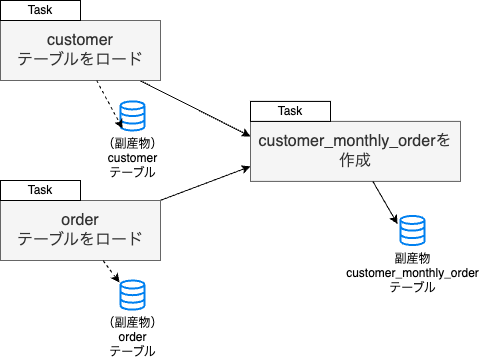
- タスクが成功していたとしても、本当にテーブルが作られているとは限らない
- タスクの依存関係はわかっても、テーブルの依存関係はわからない
2.4で Dataset のしくみが導入され、副産物だったデータに着目したスケジューリングもできるようになっていますが、まだ限界がありました。
- Datasetは、タスクが完了したタイミングで「何かを更新した」というイベントを記録するだけの機構。実際のデータの検査、検証、操作を追加できるような仕組みではなかった。
- ネイティブな外部イベントの統合がなく、イベント駆動型のスケジューリングができない
- パーティショニングなどの考え方を持っておらず、スライス単位の更新・依存を扱えない
- データセットによるスケジューリングでは、論理式(AND/OR)を利用できるが、ユーザーフレンドリーではない
どう変わるのか
データセットが「Asset」という名前に変わります。
- Datasetと異なり、グループの考え方を持ちます。モデル(データを使ってトレーニングしたもの)グループに割り当てるか、データセット(モデルのトレーニング対象、またはモデルを通してデータをフィードすることで得られるもの)グループに割り当てるかを選択できます。
- アセットを定義するためのデコレーターと、それを用いた新しいワークフロー定義の構文が用意されています。
- アセットの変更に基づくスケジューリングができるようになります。
また、今後のリリースでは以下も予定されています。
- アセットパーティショニング。まだWIPであり、どういうものが出てくるのか、正直まだよくわかりませんでした。ご興味があればwikiを参照してください。
使ってみる
以下のようなDAGを組んでみます。

- S3にあるファイルを参照した外部テーブル「STG_CUSTOMER」「STG_ORDER」があります
- 2テーブルから「CUSTOMER_MONTHLY_ORDERS」を集計し、テーブル化します。
参考:SQL
-- S3からデータ取得してテーブル化
create or replace transient table t_kodama_db.airflow_test.stg_customers as (
select
$1 as customer_id,
$2 as customer_name,
$3 as customer_age,
$4 as customer_birthday,
$5 as customer_gender,
$6 as customer_location
from
@tkodama_s3_stage/customers
);
-- S3からデータ取得してテーブル化
create or replace transient table t_kodama_db.airflow_test.stg_orders as (
select
$1 as order_id,
to_timestamp($2) as order_time,
$3 as shop_id,
$4 as customer_id,
$5 as order_amount
from
@tkodama_s3_stage/orders
);
-- 集計テーブル
create or replace transient table t_kodama_db.airflow_test.customer_monthly_orders as (
select
date_trunc(t1.order_time) as month,
t1.customer_id,
sum(t1.order_amount) as order_amount
from t_kodama_db.airflow_test.stg_orders as t1
left join
t_kodama_db.airflow_test.stg_customers as t2
on t1.customer_id = t2.customer_id
group by
month, customer_id
);
従来のタスクセントリックなDAGであれば、以下のような構造になります。
taskflow apiは継続してサポートされており、以前と同じ書き心地です。
from airflow.decorators import dag, task
from airflow.providers.snowflake.hooks.snowflake import SnowflakeHook
from datetime import datetime
# 共通関数: Snowflakeへ接続してSQLファイルを実行
def execute_sql(sql_file: str) -> None:
"""指定したSQLファイルを読み込み、Snowflakeで実行する"""
hook = SnowflakeHook(snowflake_conn_id='snowflake_default')
# SQLファイルはDAGと同じディレクトリの sql フォルダ内に配置
path = f"{__file__.rsplit('/', 1)[0]}/sql/{sql_file}"
with open(path, 'r', encoding='utf-8') as f:
sql = f.read()
hook.run(sql)
# DAG定義
@dag(
dag_id='task_centric_dag',
start_date=datetime(2025, 4, 23),
schedule=None,
catchup=False,
tags=['snowflake', 'taskflow']
)
def task_centric_dag():
# stg_customers を作成
@task
def stg_customers():
execute_sql('stg_customers.sql')
# stg_orders を作成
@task
def stg_orders():
execute_sql('stg_orders.sql')
# customer_monthly_orders を作成
@task
def customer_monthly_orders():
execute_sql('customer_monthly_orders.sql')
# タスクの順序付け
customers = stg_customers()
orders = stg_orders()
# 集計タスクは両方の完了を待つ
customer_monthly_orders().set_upstream([customers, orders])
# DAGをモジュールロード時にロード
dag = task_centric_dag()

ちゃんと実行できました。
これをアセットベースの書き方に変えてみましょう。
@assetデコレーターを使うと、タスクの宣言とその成果物であるアセットの宣言を一度に行うことができます。これを用いて3つのTaskをAssetに置き換えてみます。
from airflow.sdk import asset, Asset
@asset(uri="snowflake://t_kodama_db.airflow_test.stg_customers", schedule="@daily")
def stg_customers():
"""S3からデータ取得してstg_customersテーブルを作成"""
execute_sql("stg_customers.sql")
@asset(uri="snowflake://t_kodama_db.airflow_test.stg_orders", schedule="@daily")
def stg_orders():
"""S3からデータ取得してstg_ordersテーブルを作成"""
execute_sql("stg_orders.sql")
後続のcustomer_monthly_ordersは、stg_モデルの完了後に起動したいです。
この場合、アセットのscheduleに、該当のアセットを仕込むとよさそうです。
@asset(
uri="snowflake://t_kodama_db.airflow_test.customer_monthly_orders",
# ここで依存を指定する。
# @assetを使って作成したアセットは、その関数名がアセットの名前になる。
schedule=[
Asset(name='stg_customers', uri='snowflake://t_kodama_db.airflow_test.stg_customers'),
Asset(name='stg_orders', uri='snowflake://t_kodama_db.airflow_test.stg_orders')
]
)
def customer_monthly_orders():
"""stg_customers と stg_orders の完了後に顧客月次集計テーブルを作成"""
execute_sql("customer_monthly_orders.sql")
完成したコード
from airflow.sdk import asset, Asset
from airflow.providers.snowflake.hooks.snowflake import SnowflakeHook
import os
def execute_sql(sql_file: str) -> None:
"""指定したSQLファイルを読み込み、Snowflakeで実行する"""
hook = SnowflakeHook(snowflake_conn_id="snowflake_default")
path = os.path.join(os.path.dirname(__file__), "sql", sql_file)
with open(path, "r", encoding="utf-8") as f:
sql = f.read()
hook.run(sql)
@asset(uri="snowflake://t_kodama_db.airflow_test.stg_customers", schedule="@daily")
def stg_customers():
"""S3からデータ取得してstg_customersテーブルを作成"""
execute_sql("stg_customers.sql")
@asset(uri="snowflake://t_kodama_db.airflow_test.stg_orders", schedule="@daily")
def stg_orders():
"""S3からデータ取得してstg_ordersテーブルを作成"""
execute_sql("stg_orders.sql")
@asset(
uri="snowflake://t_kodama_db.airflow_test.customer_monthly_orders",
schedule=[
Asset(name='stg_customers', uri='snowflake://t_kodama_db.airflow_test.stg_customers'),
Asset(name='stg_orders', uri='snowflake://t_kodama_db.airflow_test.stg_orders')
]
)
def customer_monthly_orders():
"""stg_customers と stg_orders の完了後に顧客月次集計テーブルを作成"""
execute_sql("customer_monthly_orders.sql")
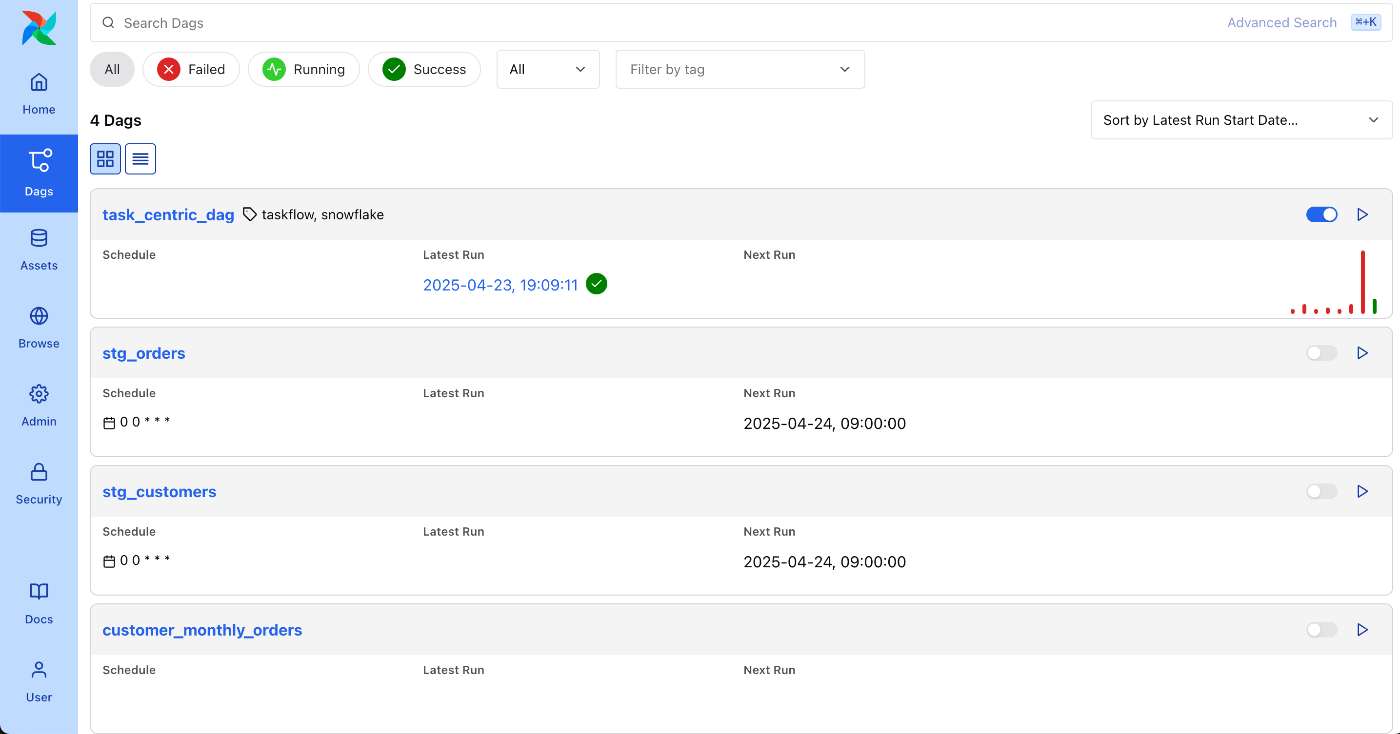
この状態でAirflowのUIを確認すると、
興味深いことに、これだけで3つのDAGが追加されました。
アセットカタログの画面から、customer_monthly_ordersアセットを見てみると、以下のようなリネージが現れます。
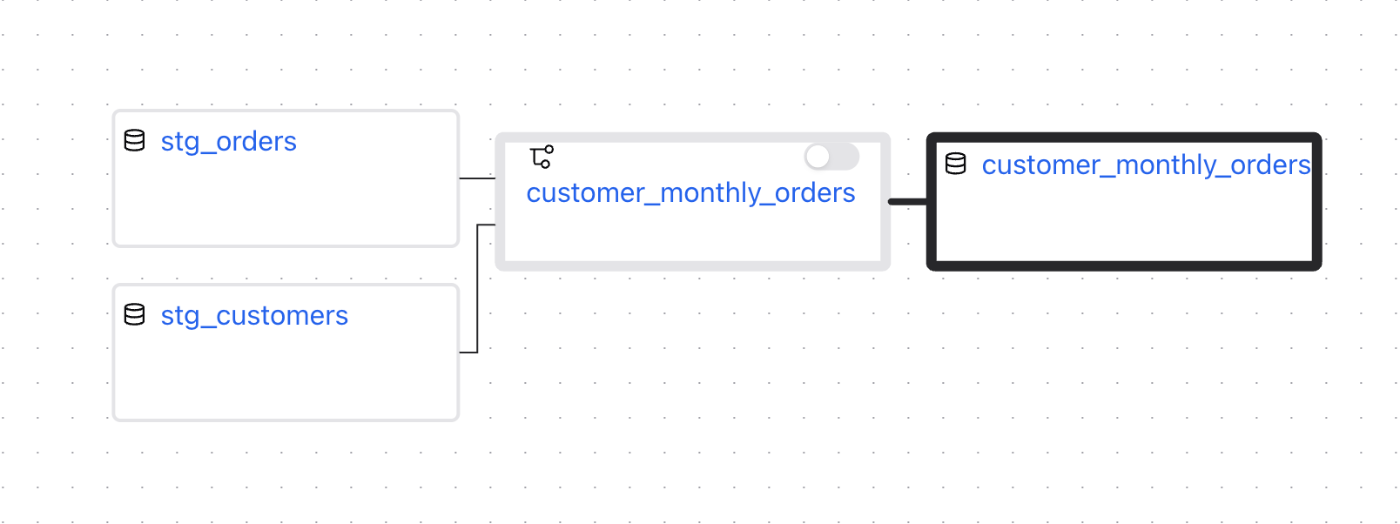
- 上流のアセット2つに対して、DAG「customer_monthly_orders」が依存しています。
- DAG「customer_monthly_orders」に、アセット「customer_monthly_orders」が依存しています。
あくまでもAirflowの実行主体はこれまで通りタスクであり、アセットはその成果物であるという位置付けのようですね。

ちなみに、DAGのリネージにはアセットは出てきませんでした。
マニュアルで実行するには、従来通りDAGを手動で起動する他、アセット画面からも起動することができます。

Create Asset Eventを押下
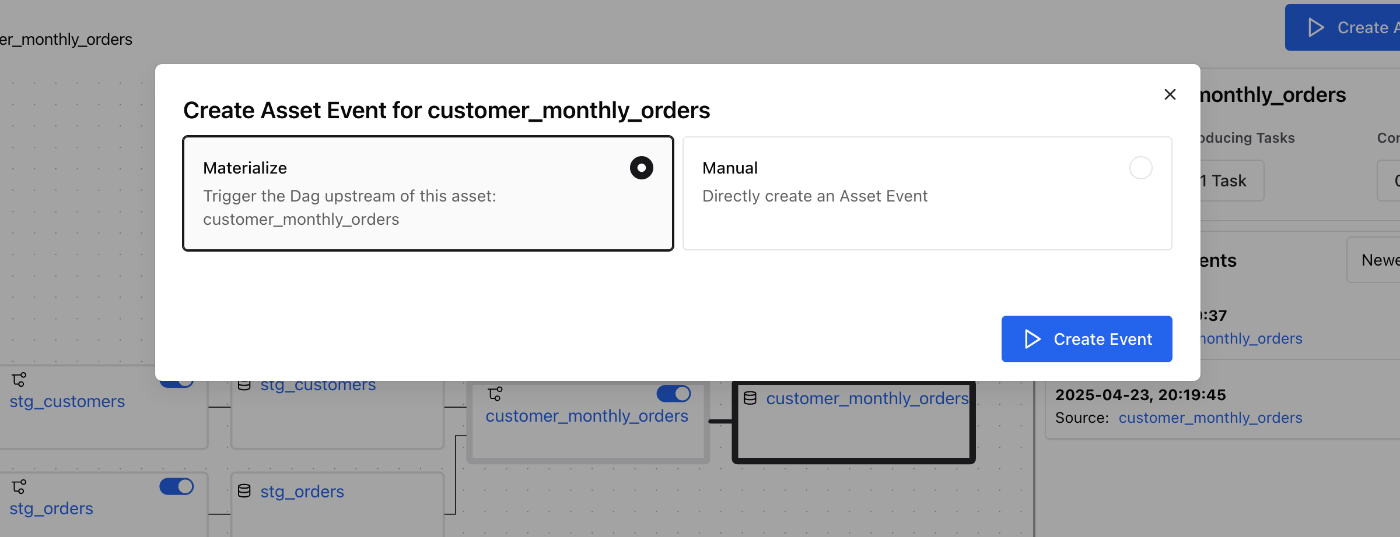
対象のアセットだけのイベントか、Upstreamを含めたすべてのアセットのイベントを発火するか選べます。「Materialize」という呼び方も含めて、このあたりはDagsterと同じですね。
イベント駆動のスケジューリング
アセットの状態変化をトリガーにしたスケジューリングができるようになっています。

https://www.astronomer.io/docs/learn/airflow-event-driven-scheduling
- データの準備が完了したことをメッセージキューに送信
- トリガーがキューをポーリングし、新しいメッセージが見つかればトリガーイベントを発火
- AssetWatcherがトリガーイベントに基づき、アセットイベントを発火
- アセットに関連付けされたタスクが起動
ここではAstronomerのチュートリアルに習ってAmazon SQSをキューに利用します。詳細は割愛しますが、S3に「customers.csv」というファイルが置かれたらキューにイベント発火するようにしておきました。
イベントを受け取るトリガーと、関連するアセットは以下のようになります。
from airflow.sdk import asset, Asset, AssetWatcher
from airflow.providers.common.messaging.triggers.msg_queue import MessageQueueTrigger
# SQSを監視するトリガーを作成
SQS_QUEUE = "https://sqs.ap-northeast-1.amazonaws.com/*****/tkodama-airflow3-test"
trigger = MessageQueueTrigger(queue=SQS_QUEUE)
# トリガーイベントを受けるAssetWatcherと、対応するアセットを定義
customers_csv_asset = Asset(name='customers_csv', uri='s3://tkodama-bucket/airflow-3-test/customers/customers.csv',
watchers=[
AssetWatcher(name="s3_watcher", trigger=trigger)
])
# stg_customerのアセットが、CSVのアセットに依存するように設定
@asset(uri="snowflake://t_kodama_db.airflow_test.stg_customers", schedule=[customers_csv_asset])
def stg_customers():
"""S3からデータ取得してstg_customersテーブルを作成"""
execute_sql("stg_customers.sql")

イベント用のアセットがリネージに追加されました。実際にファイルを置くと、対応するアセットイベントが発火しました!
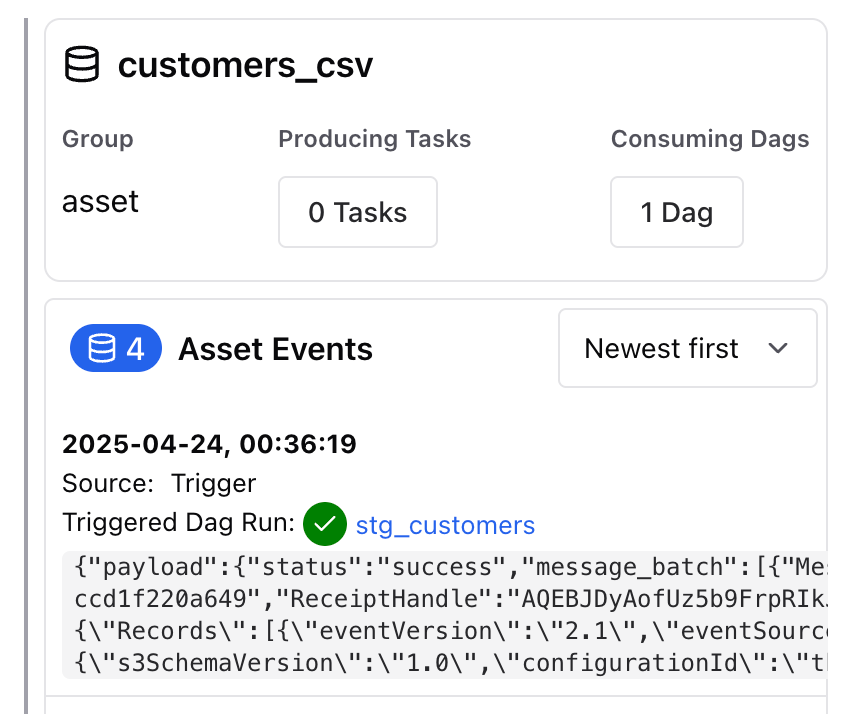
またこれにより、後続のタスクも起動することが確認できました。
UIの変更
モチベーション
Airflowのフロントエンドは2.0で大きく変化しましたが、実態としてはまだ多くの課題を残していたそうです。画面の左上にリフレッシュのトグルがついていて、ログが一定間隔でないと更新されない様子にもどかしさを感じていた人もいるかと思います。
どう変わるのか
Airflow UI 全体が React と FastAPI に基づいて最新化されました。モダンな技術スタックに切り替えることで、開発コミュニティにより多くのフロントエンド開発者が参加してくれることも期待しているそうです。
使ってみる
フロントエンドにはあまり明るくないので、詳しい掘り下げはできないのですが、個人的にはログが見やすくなったのが嬉しいです!
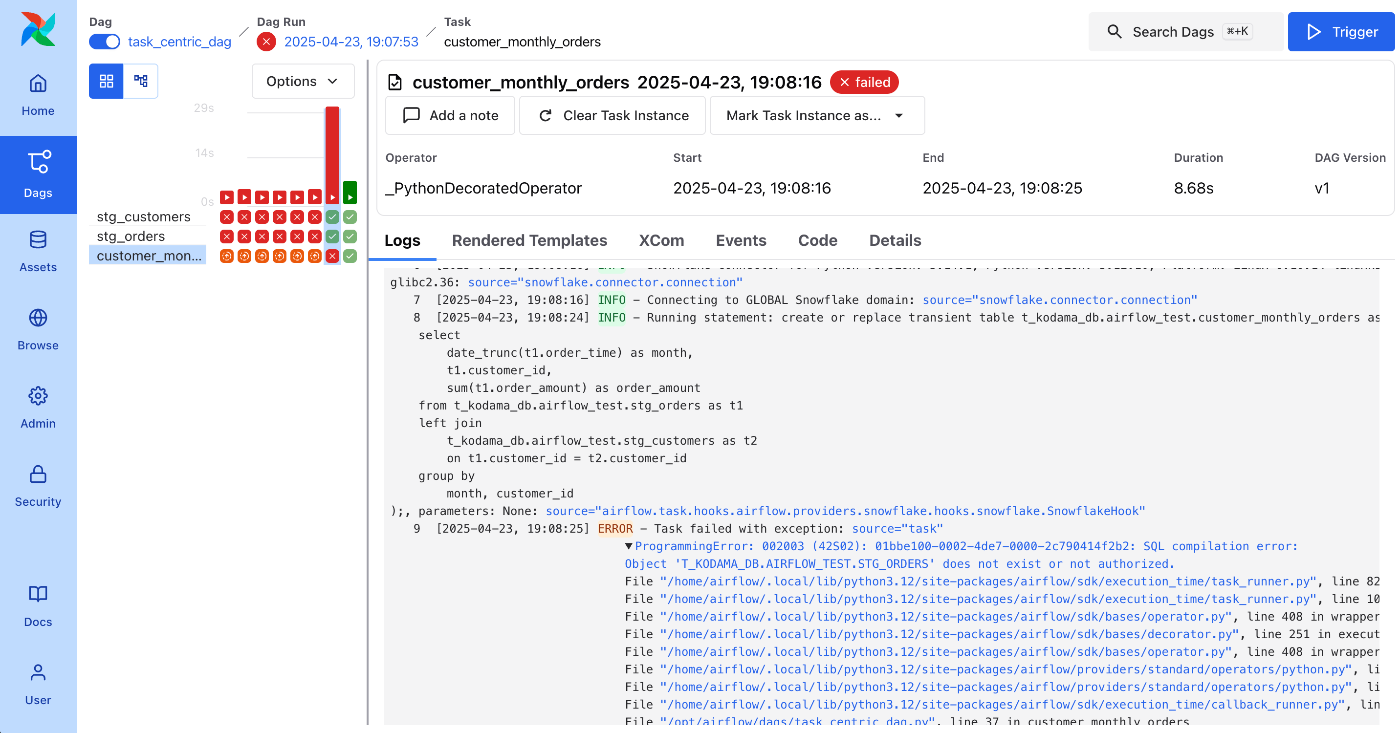
めっちゃ悪戦苦闘していますが、、、エラーログとか見やすくなったと思いませんか?
まとめ
本当はDAGがバージョニングできるようになったことや、RBACの強化といったセキュリティ面でのアップデートなど、他にもたくさん変更があるようなのですが、とりあえず私が気になったポイントを洗ってみました。
全体を通して、Dagsterなどの他製品に比べて弱点になっていた部分を取り返すための土台作りのようなアップデートだったのかなという印象を持ちました。アセット指向も今の書き味だと、まだちょっと物足りない感じはしていますが、今後のアップデートでさらに進化していきそうな期待もあります。
今後がたのしみです!

Discussion