はじめに
SPCS で JupyterLab 環境を構築した際、ハマったこと・気になったことなどの備忘録的なものです。
前提:作ったもの
SPCS関連オブジェクト
- アカウントレベルオブジェクト
- Security integration(サービスに Snowflake OAuth 認証でアクセスできるようにする)
- Anaconda アクセス用 Integration
- コンピューティングプール
- ロール
- SPCS開発ロール(SPCS関連オブジェクトを作成可能な権限を持つ)
- SPCS参照ロール(SPCS関連オブジェクトを使用可能な権限を持つ)
- Anaconda アクセス用 Integration 使用可能ロール
- スキーマレベルオブジェクト
- イメージリポジトリ
- ステージ
- サービス
ロール
アクセスロール
-
SPCS_SERVICE_CREATE_ROLE... SPCS 関連オブジェクトを作成可能 -
SPCS_SERVICE_USAGE_ROLE... SPCS 関連オブジェクトを使用可能 -
ANACONDA_EGRESS_ACCESS_USAGE_ROLE... Anaconda アクセス用 Integration を使用可能
アクセスロールと権限一覧
| ロール | 対象リソース | 権限 |
|---|---|---|
| SPCS_SERVICE_USAGE_ROLE | DATABASE | USAGE |
| SPCS_SERVICE_USAGE_ROLE | SCHEMA | USAGE |
| SPCS_SERVICE_USAGE_ROLE | SCHEMA | USAGE ON FUTURE SERVICES |
| SPCS_SERVICE_USAGE_ROLE | SCHEMA | READ,WRITE ON FUTURE STAGES [1] |
| SPCS_SERVICE_CREATE_ROLE | SCHEMA | CREATE SERVICE |
| SPCS_SERVICE_CREATE_ROLE | ACCOUNT | BIND SERVICE ENDPOINT |
| SPCS_SERVICE_CREATE_ROLE | ACCOUNT | EXECUTE TASK [2] |
| SPCS_SERVICE_CREATE_ROLE | IMAGE REPOSITORY | OWNERSHIP |
| SPCS_SERVICE_CREATE_ROLE | COMPUTE POOL | OWNERSHIP |
| ANACONDA_EGRESS_ACCESS_USAGE_ROLE | INTEGRATION (EXTERNAL ACCESS INTEGRATION) | USAGE |
ファンクショナルロール
-
DEVELOPER_ROLE... 開発者ロール。SPCS 環境を構築する人のロール -
ANALYST_ROLE... 分析者ロール。SPCS 環境を使用する人のロール
grant 関係図
閲覧検証用ユーザー
-
SPCS_DEV_USER.... 開発ユーザー -
SPCS_READ_USER.... 分析ユーザー。SPCS 閲覧のみ可能
grant 関係図
その他
- Jupyter Notebook 用 Docker image
構築
作業手順
まずはロールやらコンピューティングプールやらサービスやらをモリモリ作っていきます。
特に見どころはないです
use role accountadmin;
-- 構築実施ユーザー
set user_name='SPCS_DEV_USER';
-- 検証ユーザー
set test_user_name='SPCS_READ_USER';
-- SQCSコンピューティングプール名
set jupyter_compute_pool='SNOWFLAKE_COMPUTE_POOL';
-- 作業用DB名
set jupyter_db='M_KAJIYA_DB';
-- 作業用Schema名
set jupyter_schema='M_KAJIYA_DB.SPCS';
-- 作業用warehouse名
set jupyter_warehouse='M_KAJIYA_WH';
-- Snowflake OAuth security integration
set jupyter_security_integration='JUPYTER_SECURITY_INTEGRATION';
-- イメージリポジトリ名
set jupyter_repository='JUPYTER_IMAGE_REPOSITORY';
-- サービス名
set jupyter_service='JUPYTER_SERVICE';
-- サービス作成権限
set service_create_role='SPCS_SERVICE_CREATE_ROLE';
-- サービス利用権限
set service_usage_role='SPCS_SERVICE_USAGE_ROLE';
-- Anaconda にアクセス可能な integration 利用可能
set anaconda_egress_access_usage_role='ANACONDA_EGRESS_ACCESS_USAGE_ROLE';
-- 検証用ユーザーを作成
create user identifier($test_user_name)
password = 'paaaaaaaaasword';
-- 構築対象環境
use role sysadmin;
create database if not exists identifier($jupyter_db);
use database identifier($jupyter_db);
create schema if not exists identifier($jupyter_schema);
use schema identifier($jupyter_schema);
-- 権限付与
-- ※この辺りは Terraform でも対応してます。v1.6.3 で確認
create role identifier($service_usage_role);
create role identifier($service_create_role);
create role identifier(anaconda_egress_access_usage_role);
GRANT USAGE ON DATABASE identifier($jupyter_db) TO ROLE identifier($service_usage_role);
GRANT USAGE ON SCHEMA identifier($jupyter_schema) TO ROLE identifier($service_usage_role);
GRANT WRITE, READ ON FUTURE SERVICES IN SCHEMA identifier($jupyter_schema) TO ROLE identifier($service_usage_role);
GRANT WRITE, READ ON FUTURE STAGES IN SCHEMA identifier($jupyter_schema) TO ROLE identifier($service_usage_role);
GRANT CREATE SERVICE ON SCHEMA identifier($jupyter_schema) TO ROLE identifier($service_create_role);
GRANT ROLE identifier($service_usage_role) TO ROLE identifier($service_create_role);
GRANT ROLE identifier($service_usage_role) TO ROLE "ANALYST_ROLE";
GRANT ROLE identifier($service_create_role) TO ROLE "DEVELOPER_ROLE";
-- SYSADMIN でやること
use role sysadmin;
-- Jupyter 用データ置き場
CREATE OR REPLACE STAGE jupyter_stage
ENCRYPTION = (type = 'SNOWFLAKE_SSE')
DIRECTORY = ( ENABLE = true )
COMMENT = 'for Jupyter'
;
-- SYSADMIN でやること 終わり
use role accountadmin;
-- 構築対象環境に対する権限
-- よくある権限設計であれば SPCS にあるテーブルを SELECT 可能な Access role とか作っているところだが、ここは検証のため、直でつける
grant select on future schema in identifier($jupyter_schema) to role ANALYST_ROLE;
-- ウェアハウスについても同様
grant usage on warehouse identifier($jupyter_warehouse) to role ANALYST_ROLE;
-- よくある権限設計であれば SPCS にテーブルを CREATE 可能な Access role とか作っているところだが、ここは検証のため、直でつける
grant create table on schema identifier($jupyter_schema) to role DEVELOPER_ROLE;
-- 開発ユーザー、参照ユーザーに、Functional role付与
GRANT ROLE ANALYST_ROLE TO USER identifier($test_user_name);
GRANT ROLE DEVELOPER_ROLE TO USER identifier($user_name);
-- SPCSコンピューティングプール 最小構成(必要に応じて調整)
CREATE COMPUTE POOL identifier($jupyter_compute_pool)
MIN_NODES = 1
MAX_NODES = 1
INSTANCE_FAMILY = CPU_X64_XS;
-- DESCRIBE COMPUTE POOL SNOWFLAKE_COMPUTE_POOL;
GRANT ALL ON COMPUTE POOL identifier($jupyter_compute_pool)
TO ROLE accountadmin;
GRANT OWNERSHIP ON COMPUTE POOL identifier($jupyter_compute_pool)
TO ROLE identifier($service_create_role)
COPY CURRENT GRANTS
;
-- イメージリポジトリを作成
CREATE OR REPLACE IMAGE REPOSITORY identifier($jupyter_repository);
-- READ,WRITE では image が 403 になってしまうため、OWNERSHIP 付与
GRANT OWNERSHIP ON IMAGE REPOSITORY identifier($jupyter_repository)
TO ROLE identifier($service_create_role)
COPY CURRENT GRANTS
;
-- パブリック エンドポイントをサポートするサービスを作成可能にする
GRANT BIND SERVICE ENDPOINT ON ACCOUNT
TO ROLE identifier($service_create_role);
-- Services に対する将来の権限
GRANT USAGE ON FUTURE SERVICES IN SCHEMA identifier($jupyter_schema) TO ROLE identifier($service_usage_role);
-- conda package repository へのアクセス
CREATE OR REPLACE NETWORK RULE anaconda_egress_access
MODE = EGRESS
TYPE = HOST_PORT
VALUE_LIST = ('repo.anaconda.com')
COMMENT = 'repo.anaconda.com への Egress アクセスを許可'
;
-- CREATE EXTERNAL ACCESS INTEGRATION のための権限付与
GRANT USAGE ON NETWORK RULE anaconda_egress_access TO ROLE ACCOUNTADMIN;
CREATE EXTERNAL ACCESS INTEGRATION ANACONDA_EGRESS_ACCESS_INTEGRATION
ALLOWED_NETWORK_RULES = (anaconda_egress_access)
ENABLED = true;
-- `GRANT USAGE ON INTEGRATION` の付与
GRANT USAGE ON INTEGRATION ANACONDA_EGRESS_ACCESS_INTEGRATION TO ROLE identifier(anaconda_egress_access_usage_role);
ここで Docker 操作へ。コマンドラインで実行。
docker login <your-account>.registry.snowflakecomputing.com/m_kajiya_db/spcs/jupyter_image_repository -u SPCS_DEV_USER
# パスワードを入力
BASE_IMAGE=jupyter/minimal-notebook:x86_64-ubuntu-22.04
docker pull ${BASE_IMAGE}
docker tag ${BASE_IMAGE} <your-account>.registry.snowflakecomputing.com/m_kajiya_db/spcs/jupyter_image_repository/${BASE_IMAGE}
docker push <your-account>.registry.snowflakecomputing.com/m_kajiya_db/spcs/jupyter_image_repository/${BASE_IMAGE}
再び Snowflake へ。
-- サービス作成と起動
use role DEVELOPER_ROLE;
-- SnowSQL でなければ、Snowsight or Classic UIからステージにアップロード
PUT file://jupyterlab_spec.yaml @jupyter_stage
AUTO_COMPRESS = FALSE
OVERWRITE = TRUE
;
CREATE SERVICE jupyterlab_service
IN COMPUTE POOL identifier($handson_jupyterlab_spcs_compute_pool)
FROM @jupyter_stage
SPECIFICATION_FILE='jupyterlab_spec.yaml'
EXTERNAL_ACCESS_INTEGRATIONS = (ANACONDA_EGRESS_ACCESS_INTEGRATION)
MIN_INSTANCES = 1
MAX_INSTANCES = 1
;
動作確認
特段何もないので省略
- JupyterLab にアクセス可能(開発ユーザーも分析ユーザーも)
- Anaconda パッケージリポジトリからパッケージをインストール可能
- Python(Snowpark)コードを実行可能
- Snowflake に接続し、クエリを実行、結果を取得可能
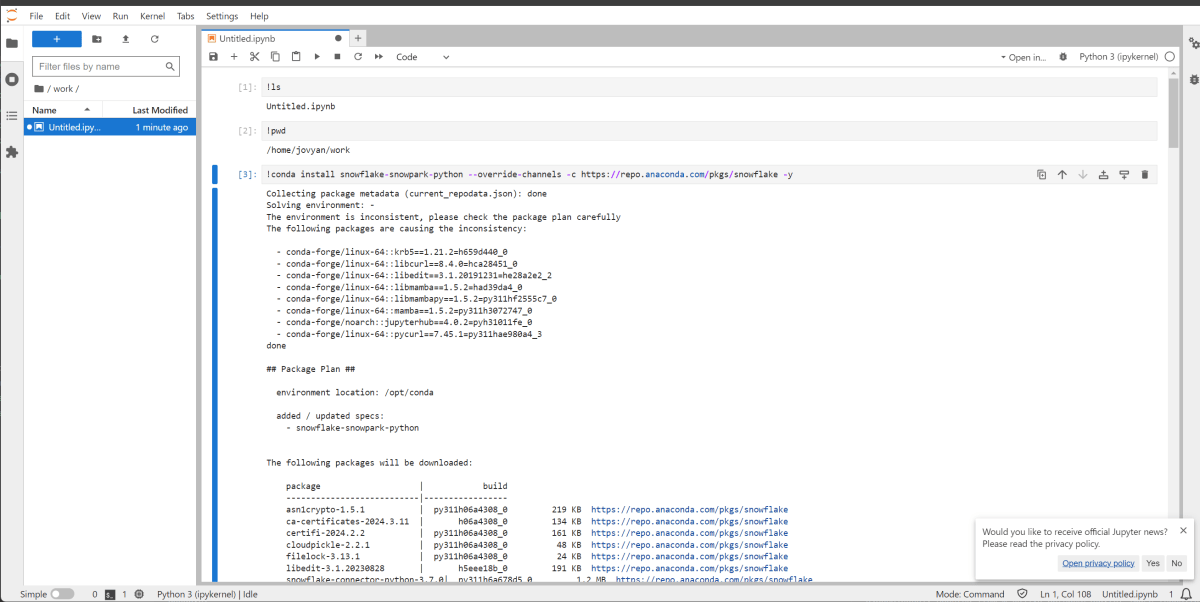
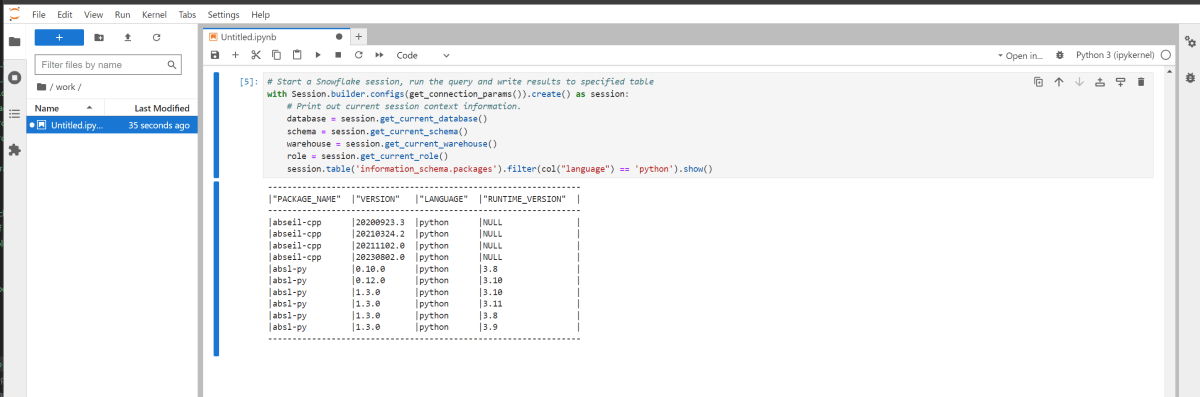
ハマったこと・気になったことなど
docker push と認証について
- MFAが有効化されているユーザーが、Snowflake イメージリポジトリにpushすると、(当然だが)MFAの認証が必要になる
- すると、並列アップロードの数だけ認証が飛んでくる(体感、もっと飛んできてる感じがある)
- push の後、Snowflake にブラウザでサインインしようとすると、Duo Security が登録されていないというメッセージが出ることがある。しかし、Snowflake で
desc userしてMFA設定を確認すると、MFAが有効になったまま。 - そして、キーペア認証など、MFA不要の方法だと、普通に認証が通ったりする
- 認証が大量に飛んだ結果、Duo側でロックがかかってしまっている??でも、それなら違うメッセージになるはずだよな~

追記
こちらの Knowledge base 記事に回避策が書かれていました!(Hiyama さんありがとうございます!!)
SnowCLI に、現在の接続に基づいてレジストリ認証トークンを取得するコマンド snow spcs image-registry token があります。これを使ってトークンを取得、docker login コマンドに渡すのがよさそうです。
コマンド例)
snow spcs image-registry token \
--connection <config.tomlに記載しているコネクション名> \
--format=JSON | \
docker login <your-account>.registry.snowflakecomputing.com \
--username 0sessiontoken \
--password-stdin
節約のために
サービスとコンピュートプール、つけっぱなしだと当然コンピューティングコストがかかる。なので、作業をしない時間帯はサービスとコンピュートプールを止める。コストはちりつも。
最小のコンピュートプール CPU_X64_XS で概算すると、だいたいこんな感じ。
- つけっぱなしの場合
-
0.110.06(クレジット)※1 * 24(時間) * 30(日) * 2.85~5.7(ドル/クレジット)※2 * 150(円/ドル) = 18,468 ~ 36,936(円)
-
- 業務時間外停止の場合
- 例えば業務時間が平日 10:00-19:00 だとして、19:00-翌10:00 はコンピュートプールを停止する場合
-
0.110.06(クレジット)※1 * 10 (時間) * 20(日) * 2.85~5.7(ドル/クレジット)※2 * 150(円/ドル) = 5,130 ~ 10,260 (円)
※1 2024/8/1、SPCSがGAになると同時に、コンピューティングプールのコストを50%削減したとのお知らせがありました
※2 https://www.snowflake.com/en/data-cloud/pricing-options/
というわけで、自動停止と自動再開[3]を仕込みます。
ストアド
use role sysadmin;
CREATE OR REPLACE PROCEDURE CHANGE_SERVICE_STATUS(service VARCHAR, status VARCHAR)
RETURNS OBJECT NOT NULL
LANGUAGE SQL
EXECUTE AS CALLER -- AS OWNER だと、「Stored procedure execution error: Unsupported statement type 'DESCRIBE COMPUTE_POOL'.」などでエラー cf. https://docs.snowflake.com/developer-guide/stored-procedure/stored-procedures-rights#show-and-describe-commands
AS
/**
指定したサービスの状態を変更(SUSPEND / RESUME)する
@param service VARCHAR 対象サービス名
@param status VARCHAR 対象サービスをこの状態に変更する。RESUME または SUSPEND を指定
@return object status
Examples:
-- サービス 「jupyterlab_service」を起動
CALL CHANGE_SERVICE_STATUS(service=>'jupyterlab_service', status=>'RESUME');
-- サービス 「jupyterlab_service」を停止
CALL CHANGE_SERVICE_STATUS(service=>'jupyterlab_service', status=>'SUSPEND');
*/
DECLARE
-- compute pool の状態
-- - サービスを RESUME にするとき、コンピュートプールが SUSPENDED であれば起動
-- - サービスを SUSPEND にするとき、コンピュートプールが ACTIVE であれば停止
-- - ACTIVE、SUSPENDED 以外は変更しない。AUTO_RESUME / AUTO_SUSPEND_SECS を適宜設定してください
compute_state VARCHAR;
status_exception EXCEPTION (-20001, 'status is not "RESUME" or "SUSPEND".');
res_desc_service RESULTSET;
res_desc_pool RESULTSET;
BEGIN
LET upper_status := UPPER(status);
CASE (upper_status)
WHEN 'RESUME' THEN
compute_state := 'SUSPENDED';
WHEN 'SUSPEND' THEN
compute_state := 'ACTIVE';
ELSE
RAISE status_exception;
END;
res_desc_service := (EXECUTE IMMEDIATE 'DESC SERVICE ' || service);
LET cur_desc_service CURSOR FOR res_desc_service;
-- 対象サービス、サービスが使用しているコンピュートプールのステータス変更
FOR c IN cur_desc_service DO
-- コンピュートプールの操作(必要な時だけ)
res_desc_pool := (EXECUTE IMMEDIATE 'DESC COMPUTE POOL ' || c."compute_pool");
LET cur_desc_service CURSOR FOR res_desc_pool;
FOR d IN cur_desc_service DO
IF (d."state" = compute_state) then
EXECUTE IMMEDIATE 'ALTER COMPUTE POOL ' || c."compute_pool" || ' ' || status;
END IF;
END FOR;
-- サービスの操作
EXECUTE IMMEDIATE 'ALTER SERVICE ' || c."name" || ' ' || status;
END FOR;
RETURN OBJECT_CONSTRUCT('STATUS', 'Succeeded');
EXCEPTION
WHEN OTHER THEN
RETURN OBJECT_CONSTRUCT(
'STATUS', 'Exception Occurred',
'SQLCODE', sqlcode,
'SQLERRM', sqlerrm,
'SQLSTATE', sqlstate
);
END
;
grant ownership on procedure change_service_status(VARCHAR, VARCHAR) to role kajiya_developer_role;
ストアドを定期実行していく。
-- タスク化する
use role ACCOUNTADMIN;
create or replace task suspend_jupyter
SCHEDULE = 'USING CRON 0 19 * * MON-FRI Asia/Tokyo'
WAREHOUSE = 'M_KAJIYA_WH'
AS
call change_service_status(service=>'jupyterlab_service', status=>'SUSPEND')
;
grant ownership on task suspend_jupyter to role DEVELOPER_ROLE;
alter task suspend_jupyter resume;
create or replace task resume_jupyter
SCHEDULE = 'USING CRON 0 10 * * MON-FRI Asia/Tokyo'
WAREHOUSE = 'M_KAJIYA_WH'
AS
change_service_status(service=>'jupyterlab_service', status=>'RESUME')
;
grant ownership on task resume_jupyter to role DEVELOPER_ROLE;
alter task resume_jupyter resume;
仕込んだのち、コンピュートプールの履歴を見てみましょう。
select top 10 *
from SNOWFLAKE.ACCOUNT_USAGE.SNOWPARK_CONTAINER_SERVICES_HISTORY
order by START_TIME desc;
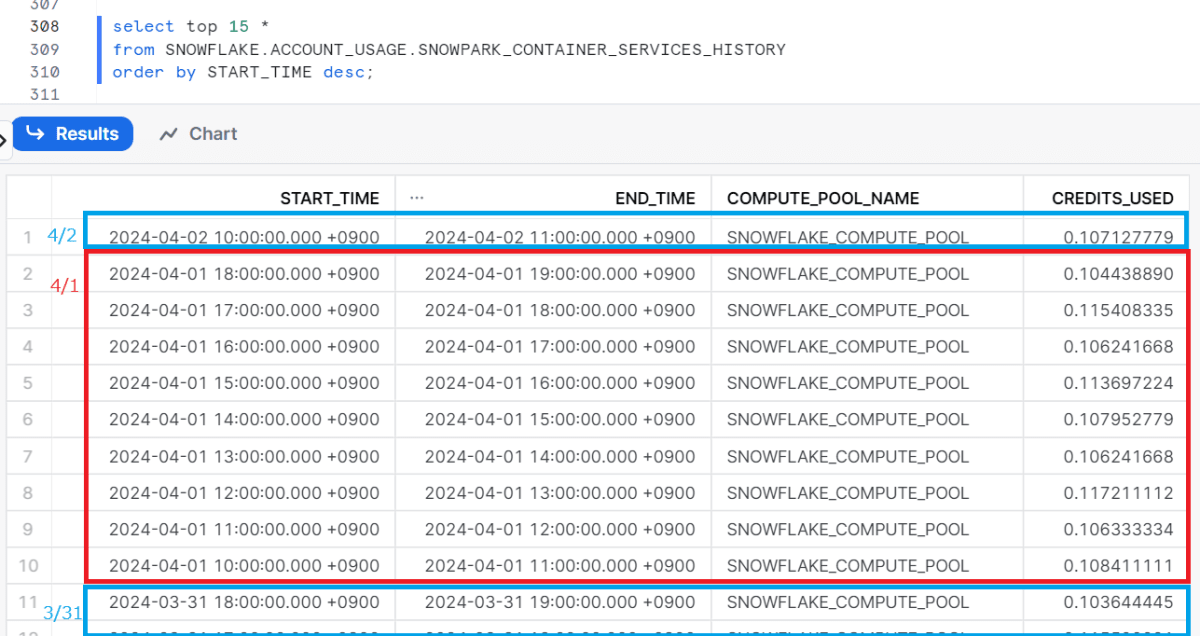
よさそうですね。
サービスロールについて
When you create a service, Snowflake also creates a “service user” specific to that service. When the service runs a query, it runs the query as the service user. What the service user can do is determined by the service role.
つまり、サービスから Snowflake にアクセスするとき、Snowflake が提供する OAuth を利用すると、ロールはサービスの OWNER になる。
たとえば、次のようなロール構成をしていて、開発用ロールでサービス作成すると、サービスロールは開発用ロールになる:
ACCOUNTADMIN or SYSADMIN
├───開発用 Functional ロール
│ └─── 分析者用ロールに付けてない権限をもつロール(CREATE xxx など)
└───分析者用 Functional ロール
- ACCOUNTADMIN(or SYSADMIN) でサービスを作ると、本来分析者用ロールしか使えないはずのユーザーも ACCOUNTADMIN(or SYSADMIN) が使えてしまう
- 権限設計で、過剰な権限を与えないようにしている意味が無くなる。。。
- OAuth を使わなければいいんですが、使おうと思えば使えるものを使わない、は無理がある。善意はセキュリティを担保しない
- 「サービス作成可能ロール」<-「サービス利用可能ロール」(できるだけ余計な権限が間に入らない)という関係にするか、「サービス作成可能ロール」=「サービス利用可能ロール」にするのかなあ。。 。
コンピュートプールのオプション について
- AUTO_SUSPEND_SECS のデフォが 3600(秒) 、ウェアハウスの AUTO_SUSPEND のデフォ(600)よりだいぶ長い
- 「サービスが停止していても、1時間はコンピュートがつけっぱなしになる」という意味
- 立てるサービスによるけど、サービスが停止したあとにユーザーが使うことはまずない、使い時間が決まっているようなサービスのコンピュートプールは AUTO_SUSPEND_SECS=60 くらいにしておく?(検討中)
サービスのオプションについて
- AUTO_RESUME=TRUE だと、サービス停止している状態でURLにアクセスすると自動再起動する。(コンピュートプールもサービスも起動)
- 厳密にするなら AUTO_RESUME=FALSE にするんだろうが。。。
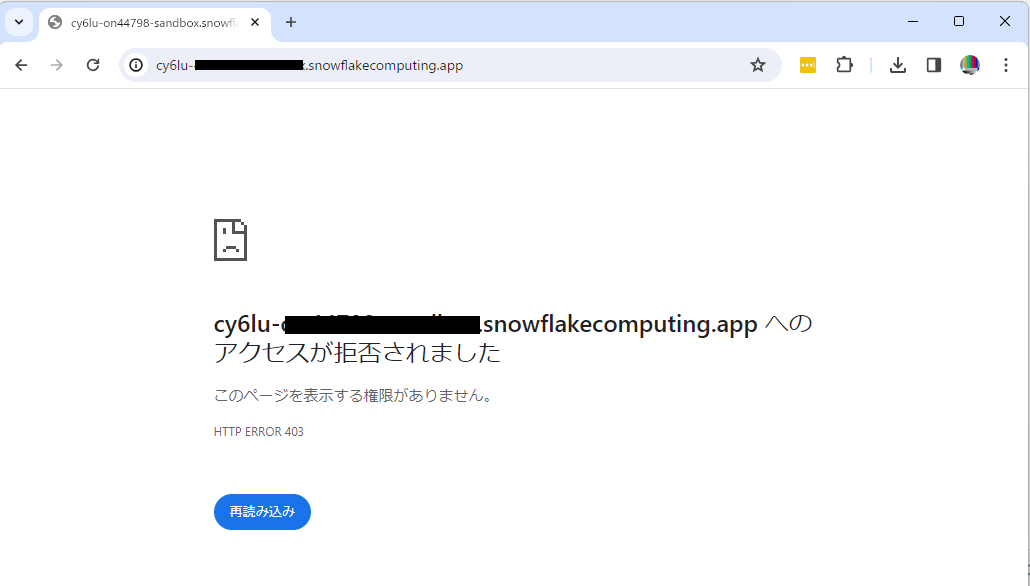
- 自動再起動するんだけど、サービス再起動+コンピュートプール再起動 の途中でアクセスすると、下の画像の画面になってしまう。何が発生しているかわからないので、ちょい不安なやつ...
- 時間が経ってコンピュートプールが起動すれば解決するものなので、SPCS で作った環境を他者に提供する場合は「5分ほど待って再アクセスしてください。時間をおいても Jupyter 環境にアクセスできない場合はご連絡ください」などのアナウンスを添えたほうが優しい気がする
Jupyter Notebook / JupyterLab に特有なこと
- Jupyter Notebook または JupyterLab の場合、複数人で1つのサービスを使っていると、再開時に開きなおすファイルやフォルダが他人と共有されてしまう(他人が開いたノートブックが開かれてしまう)
- 各人に個別の Jupyter サービス立てるのが良さそう。コンピュートプールのスペックが変わらなければ、かかる料金は変わらない
- 1人では気にならないけど、人数がある程度増えたら、ノード増の検討が必要そう
おわりに
他、新たにハマりどころや気づいたことがあれば、随時更新予定です。

Discussion
Jupyter NotebookのURLを知るには、
use schema <HOGE>;
SHOW SERVICES;
で
show endpoints in service JUPYTERLAB_SERVICE;
ingress_urlとして
s22qu-??????.snowflakecomputing.app
なので、
アクセスする際は、https://s22qu-?????.snowflakecomputing.app にアクセス
DUOの認証がいっぱい飛んでくる対策としては
alter user gtashiro set MINS_TO_BYPASS_MFA = 10;
で、一時的に、MFAを無効化(バイパス化)すると、DUO地獄を避けられます!
無効化してよいのであれば、無効化するのは手ですね!