1. はじめに
マスタデータの履歴保持が目的でdbt snapshotを使っている方も多いのではないでしょうか?自力でslowly changing dimension2を実装するのも大変なのでdbt snapshot機能を重宝させていただいています。本記事では私がdbt snapshotを使う中でハマったことを2点紹介していきます。
2. ハマり事例
2.1 主キーnullは埋めるor除くべき
はい、当たり前のことを言っています。主キーとは
「データを一意に特定できる、非nullのカラム」
という認識があるかと思われます。一方いままで源泉システム都合やETL処理を経た結果、主キーが存在しないデータ、言い換えるとユニークを特定するカラムにnullがあるデータに出くわすことがありました。このようなデータに対してdbt snapshotを実行すると、その場ではエラーにならないものの予期しない結果を生み出します。
以下の例で見てみます。
品目コード、品目タイプコードの複合主キーとし、2行目の品目タイプコードがnullとなっているデータに対してsnapshotをとってみます。
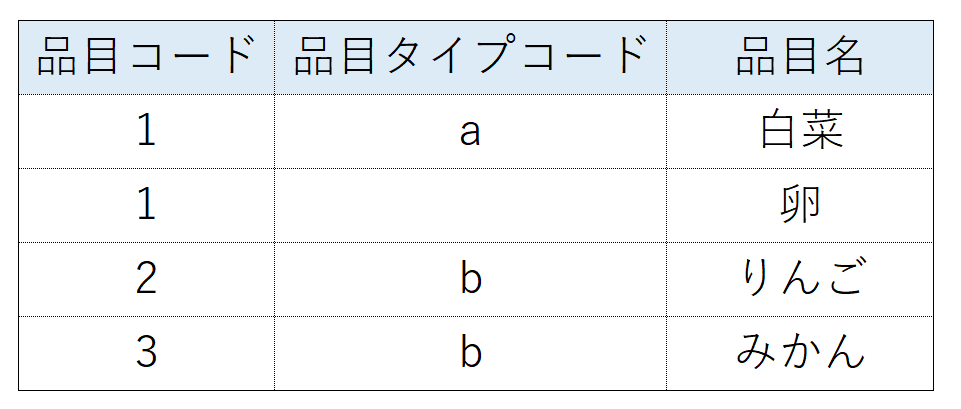
dbt snapshotを実行します。
{% snapshot m_item_snapshot %}
{{
config (
unique_key = "item_code||'-'||item_type_code",
target_schema = "public",
strategy = 'check',
check_cols = ['item_type_code','item_name'],
invalidate_hard_deletes=True
)
}}
select
*
from
{{ source('test_data','raw_m_item') }}
{% endsnapshot %}
※このような事例は複合主キーを想定する際に生じやすいと思い、複合主キーでのコードを乗せていますが、単一の主キーの場合でも同様です。
結果を確認します。

2回目dbt snapshotを同じクエリで実行し、結果を確認します。

値は変わってないものの、元の行のdbt_valid_toが埋まり、次の行が差し込まれる形になりました。。snapshotを実行している際にmerge intoの前にtemporalyテーブルを作成しますが、以下の挙動をしています。
- dbt_unique_keyがnullとなる
temporalyテーブル内の2つ目のcteのsnapshotted_dataで文字結合でdbt_unique_keyを出していますが、片方がnullのため結果がnullとなります。
snapshotted_data as (
select *,
item_code||'-'||item_type_code as dbt_unique_key
from "Y_INAOKA_DB"."PUBLIC"."M_ITEM_SNAPSHOT"
where dbt_valid_to is null
),
- insert対象になる
insertionというinsert対象の行を算出するcteで, where文の1つ目の条件(dbt_unique_keyがnull)の条件に合致し、insert対象になります。
insertions as (
select
'insert' as dbt_change_type,
source_data.*
from insertions_source_data as source_data
left outer join snapshotted_data on snapshotted_data.dbt_unique_key = source_data.dbt_unique_key
where snapshotted_data.dbt_unique_key is null
or (
snapshotted_data.dbt_unique_key is not null
and (
(snapshotted_data."ITEM_NAME" != source_data."ITEM_NAME"
or
(
((snapshotted_data."ITEM_NAME" is null) and not (source_data."ITEM_NAME" is null))
or
((not snapshotted_data."ITEM_NAME" is null) and (source_data."ITEM_NAME" is null))
))
)
)
),
dbt_valid_from,toが各行で異なるため、後続のjoinではバグは生まれませんが、毎度実行するたびに意図しない行、不要な行が増えていくのはいい気がしません。
そのため一意に特定できるカラムにnullが存在しうる場合にsnapshotを用いる場合には、該当行を何かしらの値でうめる、もしくはwhereでnullのある行を除外して実行しましょう。
2.2 全行取り込みのマスタに対してsnapshotを実行する際、最新部分のみに絞る必要あり
全行取り込みとは、データを差分ではなく全行Rawテーブルに取り込んで積み上げていることを指しています。エラー時の解析のためにS3に置かれたデータをRawテーブルに全行取り込んでいる方も多いのではないでしょうか。
以下はS3に置かれた2023/10/25のデータと2023/11/25のデータの両方をRawテーブルに取り込んでいる例になります。
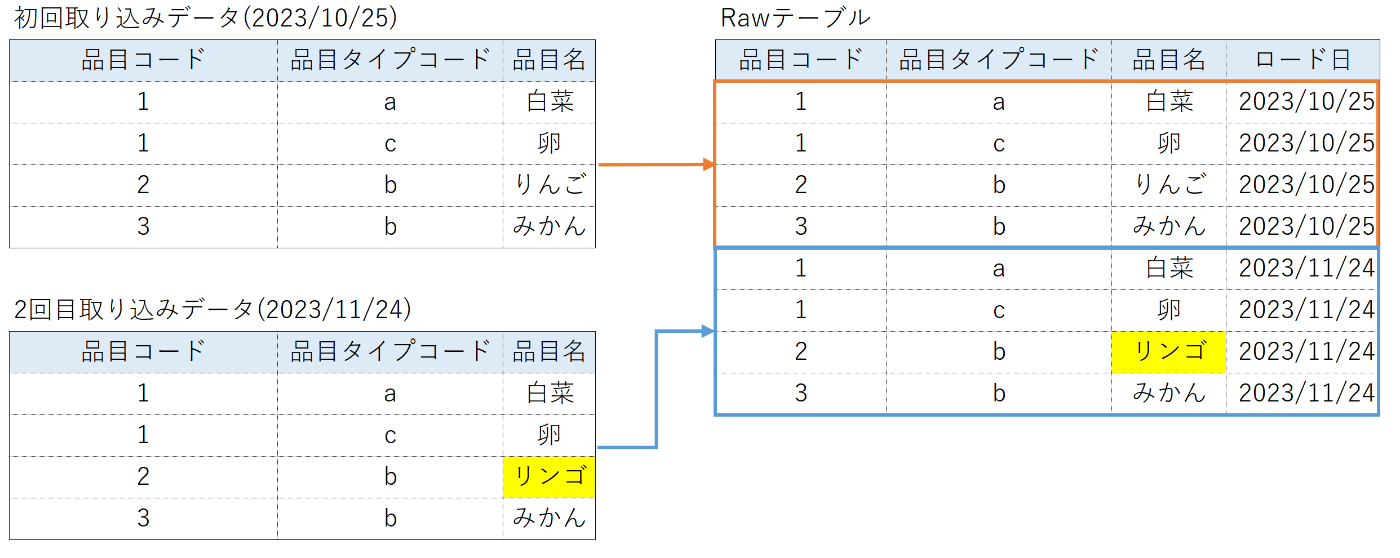
こちらのデータに対して履歴管理を行いたく、dbt snapshotを用いていました。
初回に入れているデータ、そして2回目の連携データを用いて開発していてもエラーが出なかったものの、3回目の連携時にエラーが発生しました。
下記のクエリでwhere文がない状態で実行しており、2回目の連携まで意図したテーブルが作成されますが、3回目の連携後のsnapshot実行でmerge intoの際に失敗してしまいました。理由としては、2.1節の事例で紹介したinsertionsというcteでinsert対象が2行がなってしまい、重複が発生したからです。
実際、データが積みあがった際にRawデータの最新ロード断面と履歴保持テーブルの有効部分(dbt_valid_to is null)を比べるため、select * from だけではなく最新ロード断面を取得するようなwhere文が必要でした。
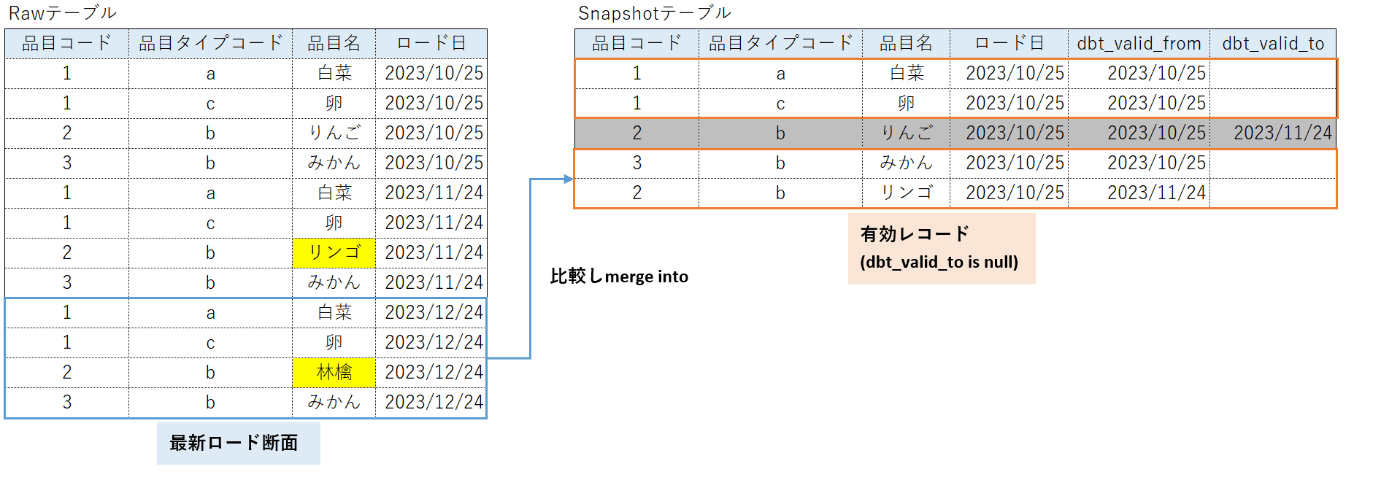
以下のようなクエリで実行すると、意図した履歴保持テーブルが作成されます。
{% snapshot m_item_snapshot %}
{{
config (
unique_key = "item_code||'-'||item_type_code",
target_schema = "public",
strategy = 'check',
check_cols = ['item_name'],
invalidate_hard_deletes=True
)
}}
select
*
from
{{ source('test_data','raw_m_item') }}
where
load_time = (
select
max(load_time)
from
{{ source('test_data','raw_m_item') }}
)
{% endsnapshot %}
連携されるデータに物理削除が存在しない場合は、where文ではなくquailify句を用いると1行で書けます。
3 終わりに
いかがだったでしょうか。本記事ではdbt snapshotでハマったことを2点紹介しました。(当たり前だよ!と言われるかもしれませんが...) dbtのmodelやseedと比べてやや裏が見えにくい機能ですので、皆さんも何かハマった事例がありましたらブログ等で紹介していただけると幸いです。

Discussion