レコメンドシステム—— DIN(Deep Interest Network)によるクリック率予測モデル
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
論文:Deep Interest Network for Click-Through Rate Prediction
はじめに
現在の産業界における広告やレコメンデーションのモデルは、主に「Embedding & MLP」というパラダイムに従っています。このアプローチでは、すべての離散特徴を固定長の低次元密ベクトルに変換する必要があります。
離散特徴には、主に以下の2種類があります:
- 単値特徴:one-hotエンコーディングで処理
- 多値特徴:multi-hotエンコーディングで処理
単値特徴の場合は比較的単純で、直接embeddingベクトルに変換できます。一方、多値特徴(例:ユーザーがクリックした商品シーケンス、カテゴリーシーケンスなど)の場合は、通常以下の手順で処理されます:
- 各アイテムをembeddingベクトルに変換
- sum/average poolingを適用
- 最終的な1つのembeddingベクトルを生成
より高度な実装では、LSTMなどを使用することもありますが、その効果は状況に依存します。

基本概念
DINモデルの重要なブレークスルーは、多値特徴に対する従来のpooling手法の改善にあります。従来の単純なsumやaverageによるpoolingでは、シーケンス内の各アイテムの重要度が同一と仮定されていました。
DINは、より自然な発想に基づいています:CTR予測タスクにおいて、各アイテムの重要度は、そのアイテムと対象広告(商品)との関連性によって決定されるべきという考え方です。
具体例で説明しましょう:
あるユーザーの最近の行動履歴が「水着、スイムキャップ、ポテトチップス、ナッツ、書籍」で、候補広告が「ゴーグル」だとします。この場合、「水着」と「スイムキャップ」は「ゴーグル」との関連性が高く、ユーザーのクリック確率に大きな影響を与えるはずです。
アーキテクチャ

DINのネットワーク構造は、従来のembedding層とMLP(全結合層)の間に、activation unitを追加したものです。モデルの特徴として:
- ユーザーの履歴商品IDは、候補広告の商品IDとのみ相関性を計算
- ユーザーの履歴店舗IDは、候補広告の店舗IDとのみ相関性を計算
Activation Unit の詳細設計
DINの核となるモジュールがActivation Unitです。このモジュールがどのように動作するのか、詳しく見ていきましょう。
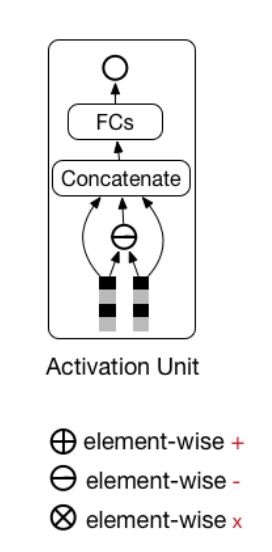
具体的な計算プロセス
ユーザーの行動履歴と候補広告を例に説明します。以下の変数を定義します:
ユーザーの行動履歴:
- 商品IDシーケンス:
ug = [ug_1,ug_2,...,ug_n] - embedding後のベクトル:
uge = [uge_1,uge_2,...,uge_n] - 店舗IDシーケンス:
us = [us_1,us_2,...,us_n] - embedding後のベクトル:
use = [use_1,use_2,...,use_n]
候補広告:
- 商品ID:
ag age - 店舗ID:
as ase
処理ステップ
-
ユーザー行動の商品ベクトルと候補広告商品ベクトルの差分計算:
aug = [age\circleddash uge_1, age\circleddash uge_2,..., age\circleddash uge_n] -
店舗IDについても同様の差分計算:
aus = [ase\circleddash use_1, ase\circleddash use_2,..., ase\circleddash use_n] -
得られた差分ベクトル(
aug, aus uge, use, ag, as
形式的な表現としては以下の数式で表されます:

ここで:
-
V_u u -
V_a a -
V_i i -
w_i i
実際の効果
DINモデルは、ユーザーの履歴アイテムと広告アイテム間のattentionスコアを視覚的に確認できます:

このように、DINはattentionスコアを用いて、各履歴アイテムの候補広告に対する貢献度を柔軟に計算することができます。
適応的正則化手法
KDDバージョンの論文では「Mini-batch Aware Regularization」と呼ばれるこの技術は、過学習を防ぐための重要な手法です。従来のL2正則化を使用しない理由として:
- 計算の複雑さが比較的高い
- 広告/レコメンド領域での過学習の主な原因が、データのロングテール分布にある
一般的な対処法としては、学習前に頻度閾値を設定し、低頻度の特徴値をフィルタリングする方法がありますが、やや硬直的な手法です。
DIN論文では、次のような革新的なアプローチを提案しています。特徴値の出現頻度に応じて、異なる強度の正則化を適用する「Adaptive Regularization Technique」です。

この式において:
-
B -
b -
n_i i -
λ -
I_i j i
これに対して、DIN論文で提案された改良版の式は以下のようになります:

両式の本質的な違いは、
各種正則化手法の比較実験
論文では以下の手法を比較検証しています:
- 正則化なし
- Dropout
- 閾値によるフィルタリング(上位2000万の商品IDのみ使用)
- 従来の正則化
- L2正則化
- 提案手法(Adaptive Regularization)

Dice活性化関数
DINではPReLUを改良した新しい活性化関数「Dice」を提案しています。まず、PReLUの定義を確認しましょう:

ここで
これを等価な形式で書き直すと:

これに対し、Diceの式は以下のようになります:

GAUCによる評価手法
GAUCはDIN論文の重要な貢献の一つで、産業界にも大きな影響を与えています。従来のAUCを各ユーザー次元で細分化したもので、
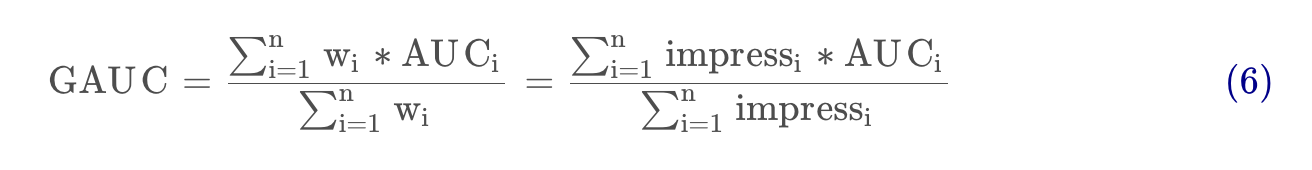
ここで
まとめ
DINモデルの主な革新点は以下の通りです:
- ユーザーの多様な興味を効果的に表現するattentionメカニズム
- 候補広告との関連性に基づく局所的な興味の活性化
- 適応的な正則化手法による過学習の抑制
- より効果的なDice活性化関数の導入
- GAUCという新しい評価指標の提案
これらの工夫により、従来のモデルと比較して有意な性能向上を達成しています。特に、ユーザーの行動履歴データを効果的に活用する点で、実用的な価値が高いモデルとなっています。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion