レコメンドシステム—— 再ランキング(Reranking)
シリーズの目次
レコメンドシステムのシリーズをここにまとめています。
はじめに
ランキングシステムにおいて、類似コンテンツ(同一トピックやタグを共有するもの)は、ランキングモデルから近似したスコアが付与され、結果として検索結果内で近接して表示されることが一般的です。このような生のソート結果をそのままユーザーに提示すると、類似したコンテンツが連続して表示されることにより、ユーザーの視覚的な疲労を引き起こし、全体的なユーザーエクスペリエンスを著しく低下させる可能性があります。
このような課題に対処するため、ランキング結果に対してリランク(再ランキング)処理を実施することが不可欠となります。
ユーザーエクスペリエンス
順番をシャッフル
同一カテゴリー、同一作成者、類似したサムネイル画像を持つコンテンツを適切に分散配置することには、複数の重要な利点があります。まず、ユーザーの視覚的・精神的疲労を軽減し、システムによる過度な個人最適化を防止します。さらに、ユーザーの潜在的な興味・関心を効果的に探索・発見することを可能にします。これらの要素は、優れたユーザーエクスペリエンスの実現と長期的な事業目標の達成において極めて重要な役割を果たします。
コンテンツの分散処理は、次のように定義できます:順序付けられたアイテムシーケンスを入力とし、各アイテムが持つ特定の属性(分散すべき特徴)に基づいて、類似属性を持つアイテム同士が適切な距離を保って配置されるよう再編成された新しいシーケンスを出力します。
一般的に、分散処理はルールベースで実装されます。このアプローチはシンプルで制御が容易である一方、アイテム属性の種類が多岐にわたり、頻繁な更新が必要となるため、スケーラビリティに課題を抱えることがあります。
ルールベースのシャッフル手法には、主に以下の3つのアプローチがあります:
-
バケット分割法:異なる属性値を持つアイテムを個別のバケットに振り分け、各バケットから順次アイテムを抽出する手法です。実装が容易で効果的なシャッフルが可能である一方、結果セットの末尾に特定の属性を持つアイテムが集中しやすいという課題があります。また、元の順序から大きく逸脱する可能性が高く、重要な評価指標の低下を招くリスクがあります。さらに、複数属性の組み合わせへの対応が困難で、拡張性に制限があります。
-
重み付け分配法:各アイテムにスコアを付与し、以下の数式に基づいて再配置を行います:
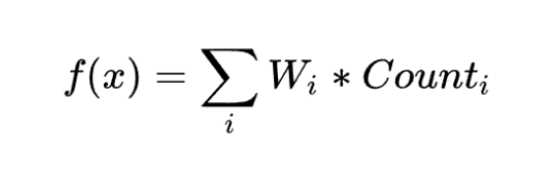
ここで、
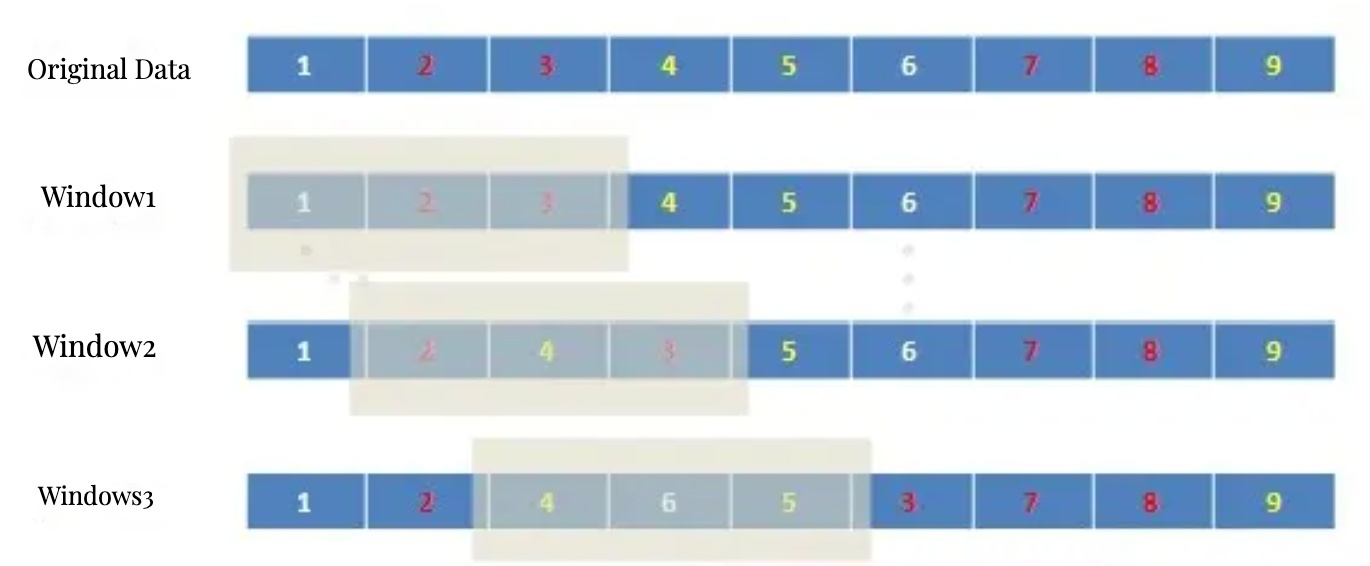
- スライディングウィンドウ法:設定可能な長さのウィンドウ(セッション)内で、同一属性の出現回数が閾値を超えた場合、後続シーケンス内の条件適合アイテムと位置を交換する手法です。この手法の特徴は、局所的な最適化のみを行うため計算コストが低く、かつ元の順序関係を大きく崩すことなく適度な分散を実現できる点にあります。
優先度の調整
優先度を持つ
コンテンツ配信において、特定のアイテムの露出優先度を戦略的に制御することが重要です。具体的には、以下のようなアイテムに対して、表示順位における優先度を付与することが可能です:
- 新着コンテンツ
- 高い人気や注目度を獲得しているアイテム
- インフルエンサーや著名クリエイターによる新規投稿
- プロモーション対象のコンテンツ
- トレンドに合致するアイテム
ウエイトの調整
ビジネス要件の変化や市場動向に応じて、コンテンツ表示順位のリアルタイムな調整が必要となる場面が頻繁に発生します。例えば、特定カテゴリーのコンテンツの露出を一時的に強化したい場合や、シーズナルコンテンツの表示優先度を時期に応じて変更する必要がある場合などが挙げられます。
最も一般的に採用されているアプローチは、ルールベースの調整方式です。この方式では、ソート済みの結果セットに対して、予め定義された属性ルールに合致するアイテムのスコアを増加させることで、それらの表示順位を向上させます。この手法は以下のような特徴を持ちます:
利点:
- 実装が容易で直感的
- リアルタイムな調整が可能
- システム負荷が低い
- 結果の予測・制御が容易
課題:
- 調整の粒度が粗く、精緻な制御が困難
- ユーザー個別の最適化が限定的
- 複雑な条件への対応が困難
これらの課題に対処するため、より高度なアプローチとして、機械学習ベースのアルゴリズムやリアルタイムデータ分析の導入を検討する価値があります。これにより:
- ユーザーの興味・関心に基づく動的な優先度調整
- 行動履歴や文脈情報を考慮した細やかな表示制御
- A/Bテストに基づく効果検証と継続的な改善
といった、より洗練された優先度制御メカニズムを実現できる可能性があります。
データサイエンス君のAI教材シリーズ(未経験OK)
教材のターゲット層:
- 初心者: Pythonとデータ分析の基本を学びたい人
- 中級者: より高度な分析手法や機械学習を習得したい人
- レコメンド(推薦)エンジニア: レコメンデーションエンジンを作り、キャリアアップを目指したい人
AI領域に携わりたい方はぜひ!
datasciencekunのAI教材シリーズ
LINE公式アカウント
データサイエンス君のLINE公式アカウント友達募集中!
今登録すれば、下記の内容をプレゼントします!
- 特典資料:AI教材の一部を無料でお送りします!
- 専門家との相談:メッセージでデータサイエンス領域の不明点が相談できます!
一人で学ぶより、仲間と一緒に成長しませんか?
今すぐ友達登録して、データサイエンスの旅を始めましょう!
LINE公式アカウント:https://line.me/R/ti/p/@datasciencekun?from=page&accountId=datasciencekun

Discussion